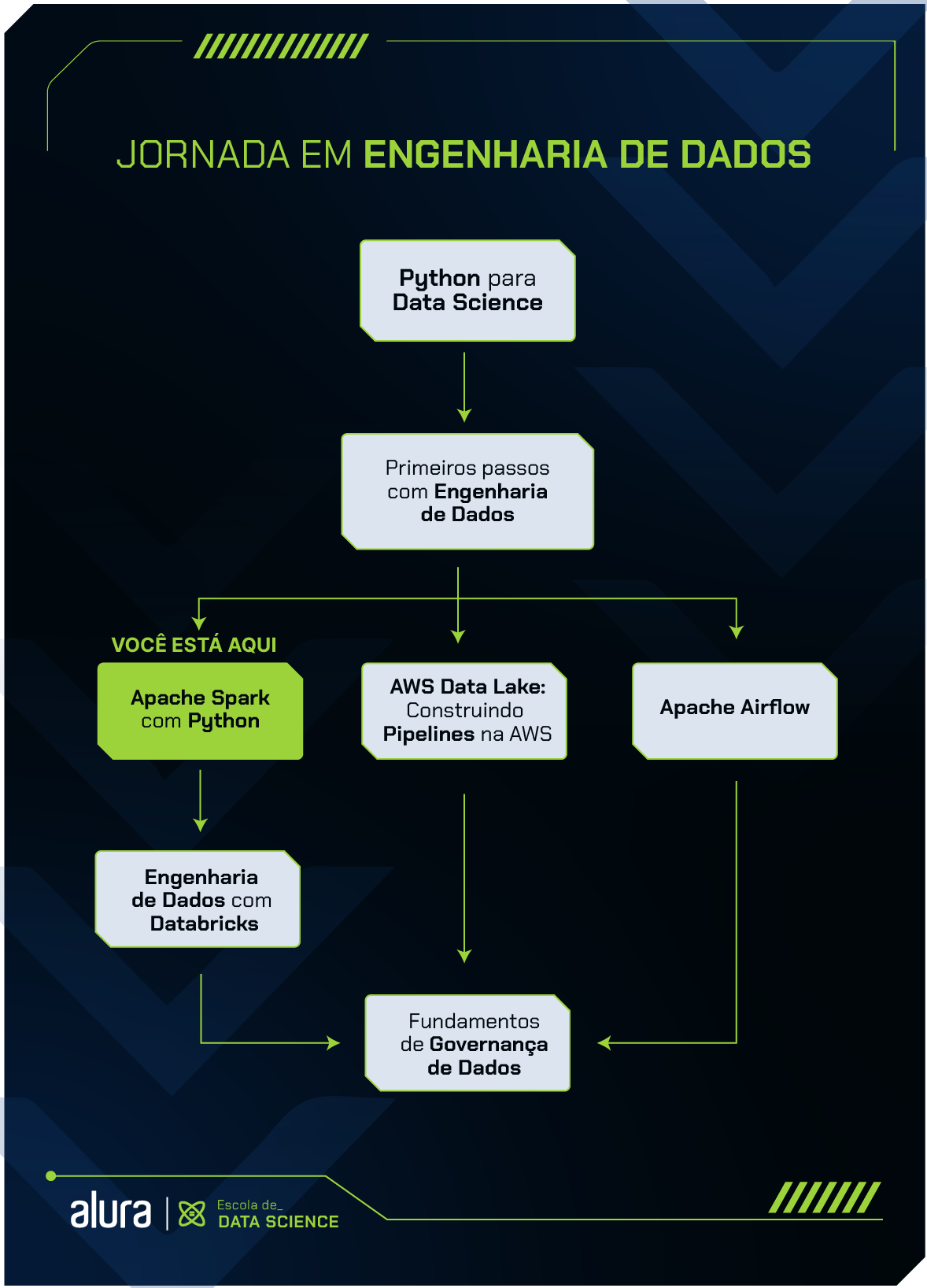
Entre para o universo Big Data e aprenda a criar projetos utilizando o Apache Spark e a linguagem Python!
A formação Apache Spark com Python da Alura tem como objetivo preparar o(a) aluno(a) para trabalhar com Engenharia de Dados, Data Science e Machine Learning em um contexto de Big Data.
Funciona como um guia de aprendizado para auxiliar pessoas interessadas em entrar no mercado de trabalho e também como mecanismo de consulta para profissionais experientes.
O QUE É O APACHE SPARK?
O Apache Spark é um framework para computação distribuída que dá suporte para mais de uma linguagem de programação (Python, SQL, Scala, Java e R). Ele é utilizado para executar Engenharia de Dados, Data Science e Machine Learning em apenas um computador ou em um cluster. É uma ferramenta muito aplicada no contexto Big Data.
O QUE VAMOS APRENDER?
Nessa formação, vamos aprender a lidar com diferentes conjuntos de dados utilizando SQL de duas maneiras. Primeiro, fazendo uso de métodos específicos dos DataFrames Spark e, em um segundo momento, utilizando comandos SQL puros.
Por fim, vamos focar nossos estudos em modelos de Machine Learning com o uso do MLlib do Spark.