Classificação: melhorando o desempenho com XGBoost
Conhecendo os dados - Apresentação
Olá! Você já ouviu falar sobre a biblioteca XGBoost? Ela se tornou bastante famosa em competições de Machine Learning no Kaggle, porque as pessoas começaram a obter excelentes resultados ao utilizá-la.
Audiodescrição: Valquíria Alencar é uma mulher branca de olhos castanhos. Tem cabelos loiros e lisos abaixo dos ombros. Usa piercing no septo e uma blusa preta com o logotipo da Escola de Dados. Ao fundo, estúdio com iluminação verde.
Este curso é para pessoas que querem aprender como utilizar essa biblioteca para resolver problemas de classificação. Vamos trabalhar com dados da área médica, atuando como cientistas de dados de um grupo de pesquisa que deseja criar um modelo para classificar pacientes como portadores ou não de uma doença cardíaca.
Então, será uma experiência incrível, onde faremos validação cruzada, usaremos técnicas específicas da biblioteca XGBoost, realizaremos ajustes de hiperparâmetros e também trabalharemos com a biblioteca dentro de uma pipeline.
Pré-requisitos
Para que você consiga acompanhar este curso, recomendamos que você tenha:
- Conhecimentos em Python;
- Biblioteca Pandas;
- Classificação, incluindo noções de avaliação de modelos.
Vamos começar esse curso?
Conhecendo os dados - Importando os dados
Um grupo de pesquisa na área médica deseja criar um modelo de Machine Learning que consiga classificar se pacientes têm ou não doença cardíaca. Isso com base em alguns dados demográficos e também resultados de exames médicos que essas pessoas fizeram.
Vamos, então, começar aqui a analisar esses dados?
Primeiro, vamos importá-los entendendo o que temos aqui para depois criar o nosso modelo.
Então, já temos aqui uma URL no Google Colab contendo o endereço do GitHub, onde esse dataset está depositado. Então, vamos executar essa célula aqui com "Shift + Enter".
url = 'https://raw.githubusercontent.com/alura-cursos/classificacao_xgboost/main/Dados/doenca_cardiaca.csv'
E para carregar esse dataset, vamos importar a biblioteca Pandas com o seguinte comando:
import pandas as pd
Vamos executar a célula. Beleza, agora podemos fazer o seguinte, podemos criar uma variável que vamos chamar de df e armazenar esse conjunto de dados dentro dessa variáveldf.
Então, para ler esse arquivo, ele está no formato CSV. Então, vamos colocar aqui pd.read_csv e entre parênteses, vamos passar essa URL que armazenamos os nossos dados aqui em cima. Então, agora executando essa célula com "Shift + Enter".
df = pd.read_csv(url)
Agora, podemos visualizar as cinco primeiras linhas desse conjunto de dados para verificar o que temos ali de informação. Então, podemos digitar aqui df.head(), que é a função para ler as cinco primeiras linhas. Então, abriu, fechou parênteses. E executando, vamos verificar o que temos.
df.head()
| Idade | Sexo | Tipo dor | Pressao arterial | Colesterol | glicemia jejum >120 | Resultados ECG | Frequencia cardiaca max | dor exercicio | Depressão ST | Inclinação ST | Numero vasos fluro | Teste cintilografia | Doenca cardiaca | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 70 | 1 | 4 | 130 | 322 | 0 | 2 | 109 | 0 | 2.4 | 2 | 3 | 3 | Presenca |
| 1 | 67 | 0 | 3 | 115 | 564 | 0 | 2 | 160 | 0 | 1.6 | 2 | 0 | 7 | Ausencia |
| 2 | 57 | 1 | 2 | 124 | 261 | 0 | 0 | 141 | 0 | 0.3 | 1 | 0 | 7 | Presenca |
| 3 | 64 | 1 | 4 | 128 | 263 | 0 | 0 | 105 | 1 | 0.2 | 2 | 1 | 7 | Ausencia |
| 4 | 74 | 0 | 2 | 120 | 269 | 0 | 2 | 121 | 1 | 0.2 | 1 | 1 | 3 | Ausencia |
E vamos analisar o que temos aqui de informação sobre esses pacientes.
Temos na primeira coluna a idade de cada um deles. Temos na segunda coluna o sexo biológico. E aqui nesse caso, quando o valor é igual a 1, é porque é o sexo biológico masculino. E quando é 0, é o sexo biológico feminino.
Na terceira coluna, temos o tipo de dor. Então, eles criaram uma escala que está indo de 1 até 4, que indica o tipo de dor no peito que essa pessoa está sentindo, que é algo que é característico de quem tem uma doença cardíaca. Em seguida, temos a pressão arterial de cada pessoa. Então, começamos aqueles exames médicos que comentei. Temos essa pressão arterial. Também temos o colesterol. Como está o nível de colesterol ali no sangue da pessoa.
Também temos o resultado da glicemia em jejum maior que 120. O que isso quer dizer? Quando está marcado com 0, é porque o valor da glicemia ali, da glicose em jejum da pessoa, não está maior que 120. E quando está maior que 120, o valor na tabela vai ser 1.
Temos depois, os resultados de eletrocardiograma. Então, é muito comum quando a pessoa tem ali a suspeita de uma doença cardíaca, fazer esse tipo de exame para analisar como estão os batimentos cardíacos.
Depois, temos os resultados de ECG, que temos os valores numéricos. Temos também a frequência cardíaca máxima de cada pessoa. E também temos uma coluna sobre dor no exercício. Nesse caso, essa pessoa fez o exercício e se ela sentiu dor, vai ter um valor igual a 1 atribuído nessa coluna. E se o valor for igual a 0, é porque a pessoa não teve dor no exercício.
Temos alguns resultados aqui de depressão ST e inclinação ST, que também são dados de eletrocardiogramas. Então, são resultados específicos para esse tipo de exame. Temos, então, valores numéricos para isso.
Também temos o resultado de número vasos fluro. Isso aqui, nesse caso, é um teste que é feito para verificar a coloração de vasos sanguíneos. É um exame específico para fazer isso. Temos valores numéricos também, como é possível observar. E temos aqui, por exemplo, um tal de teste de cintilografia, que também é um teste específico para verificar como estão os músculos do coração, onde temos também alguns valores numéricos.
E, por fim, temos a nossa coluna alvo, que é o nosso target, que é a doença cardíaca. Então, quando está marcado "Presença", é porque a pessoa tem doença cardíaca. Quando está marcado "Ausência", é porque a pessoa não tem.
Conseguimos, então, verificar tudo o que temos nesse data frame de informações sobre esses pacientes.
Próximos passos
E aí, você pode estar pensando: "Mas não sou da área médica, não entendo muito disso, dessas variáveis que vamos trabalhar agora".
O que tenho para te falar em relação a data science é que precisamos entender o negócio, o contexto do nosso negócio. Então, é importante, mesmo que não seja a sua área de atuação, dar uma estudada no que é cada uma dessas coisas e ver se isso tem a ver com a nossa variável alvo, que é a doença cardíaca.
Será que essas variáveis são explicativas e servem realmente para classificar uma pessoa com presença ou ausência dessa doença?
No próximo vídeo, vamos explorar com mais calma esses dados e entender mais algumas coisas em relação a essas variáveis!
Conhecendo os dados - Explorando os dados
Carregamos os dados no vídeo anterior, agora chegou o momento de explorá-los mais a fundo. Podemos começar usando um método chamado info para verificar informações mais detalhadas sobre as colunas que temos no DataFrame.
Na próxima linha, vamos digitar df.info(), abrindo e fechando parênteses e, ao executar, vamos verificar as nossas informações.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 270 entries, 0 to 269
Data columns (total 14 columns):
# Column Non-Null Count Dtype 0 Idade 270 non-null int64 1 Sexo 270 non-null int64 2 Tipo dor 270 non-null int64 3 Pressao arterial 270 non-null int64 4 Colesterol 270 non-null int64 5 Glicemia jejum >120 270 non-null int64 6 Resultados ECG 270 non-null int64 7 Frequencia cardiaca max 270 non-null int64 8 Dor exercicio 270 non-null int64 9 Depressao ST 270 non-null float64 10 Inclinacao ST 270 non-null int64 11 Numero vasos fluro 270 non-null int64 12 Teste cintilografia 270 non-null int64 13 Doenca cardiaca 270 non-null object dtypes: float64(1), int64(12), object(1)
memory usage: 29.7+ KB
Com mais detalhes agora em mãos, podemos ver que temos 270 linhas e 14 colunas. Observamos para cada coluna que não temos dados nulos, não sendo necessário fazer nenhuma modificação para o modelo de Machine Learning; já está tudo correto em relação aos dados nulos.
Quanto ao tipo dos dados, temos idade, sexo, tipo de dor, pressão arterial, colesterol, glicemia, os resultados do eletrocardiograma, a frequência cardíaca, dor no exercício, todos são do tipo inteiro.
Apenas uma coluna, a de Depressão ST, é do tipo float. Temos o tipo inteiro para a Inclinação ST. Em seguida, temos o número de vasos fluro, teste de cintilografia. Por fim, temos a coluna da doença cardíaca, que é o nosso alvo, como tipo objeto, pois são dados com strings, indicando "presença" ou "ausência".
Conseguimos entender algumas coisas com mais detalhes, mas podemos colocar gráficos para verificar se essas variáveis têm relação com a doença cardíaca.
Entendemos algumas peculiaridades e vamos começar a plotar alguns gráficos para analisar essas variáveis em relação ao nosso target.
Será que há relação da idade com a presença da doença cardíaca? Vamos verificar isso agora.
Para isso, podemos importar a biblioteca Seaborn para criar alguns gráficos:
import seaborn as sns
Após executar essa célula, começaremos a plotar nossos gráficos.
Análise a partir da idade
Podemos começar pela idade e verificar se há alguma correlação com a doença cardíaca. Para isso, podemos criar um gráfico do tipo boxplot, ele consegue verificar como está a distribuição de uma variável numérica. Vamos digitar sns.boxplot e passar as informações que queremos mostrar no gráfico. O nosso X será o nosso alvo, a doença cardíaca, e o Y será a idade, com os dados sendo nosso DataFrame df. Executando, temos o resultado do boxplot.
sns.boxplot(x='Doenca cardiaca', y='Idade', data=df)
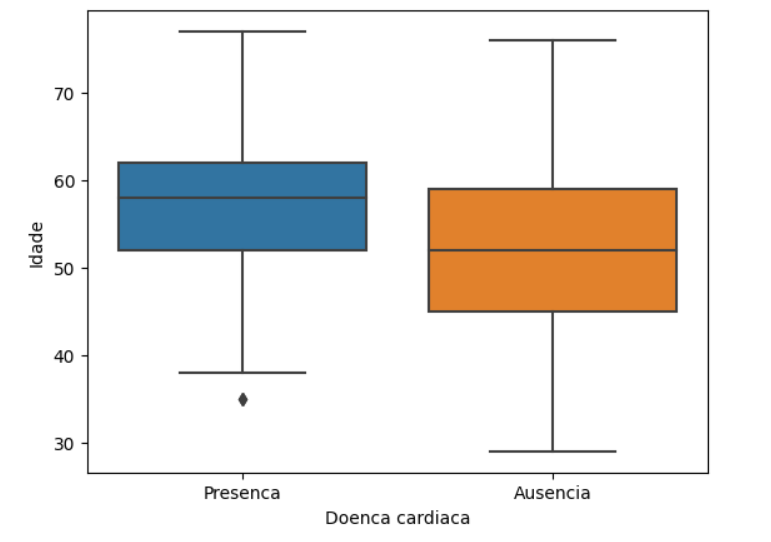
Observamos que a idade mais avançada está associada à presença da doença cardíaca. Note que nosso limite inferior começa perto dos 40 anos de idade e a mediana está próxima dos 60 anos. E o limite superior do bloxpot está passando dos 70 anos.
Na ausência da doença, temos o limite inferior começando antes, em 30 anos de idade. A mediana está um pouco acima dos 50 anos e o último quartil está perto dos 60.
Análise a partir do sexo biológico
Agora, analisando o sexo biológico, podemos plotar um countplot, que consegue contar quantas vezes cada categoria está presente. Com o comando sns.countplot, passamos o sexo como x e a doença cardíaca como hue para separação de cores. Os dados continuam sendo o df.
sns.countplot(x='Sexo', hue='Doenca cardiaca', data=df)
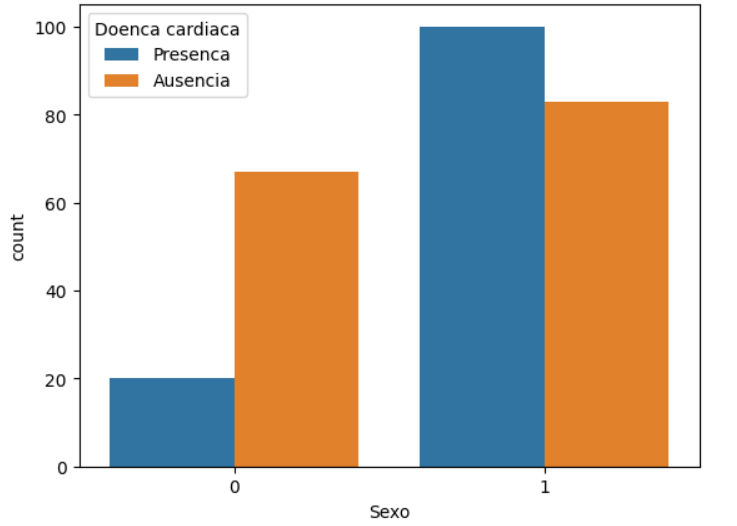
Após executar, vemos no gráfico que, em relação ao sexo feminino, há menos pessoas com a presença da doença e mais pessoas com a ausência da doença. Já no sexo masculino, há mais presença da doença.
Isso nos faz questionar qual é a relação entre o sexo biológico e a doença cardíaca, algo que já foi estudado em diversos artigos. Inclusive, você pode pesquisar um pouco sobre isso. Vou deixar uma atividade nessa aula com alguns artigos sobre esse tema.
Análise a partir do tipo de dor
Podemos verificar também o tipo de dor com um countplot. Usaremos o seguinte código:
sns.countplot(x='Tipo dor', hue='Doenca cardiaca', data=df)
Ao executar essa célula, teremos:
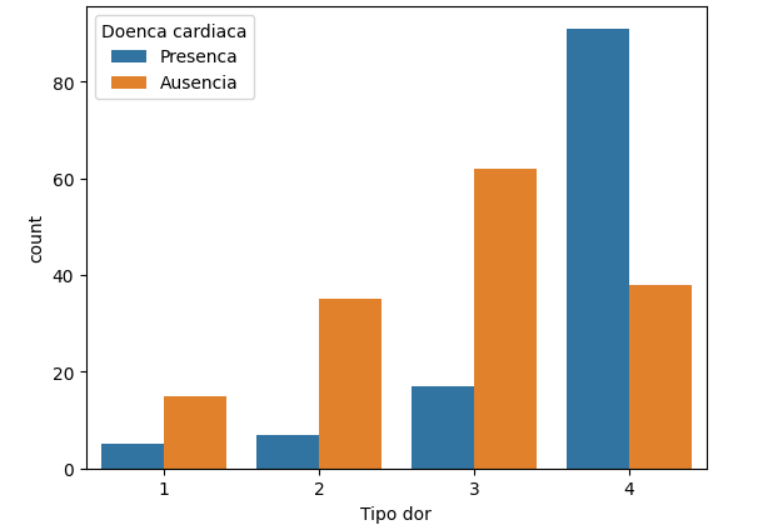
Aqui, notamos que quanto maior o tipo de dor, mais relacionado está com a presença da doença.
Próximos passos
Neste vídeo, analisamos três variáveis. Temos várias outras para analisar, mas não faremos isso nesta aula. Deixo isso como atividade para você analisar essas outras variáveis e entender como estão associadas com a doença cardíaca.
Verificação dos dados da coluna alvo
Para finalizar, vamos verificar se os dados da coluna alvo estão balanceados. Será que vamos ter que fazer um balanceamento para trabalhar com Machine Learning depois?
Vamos verificar isso agora!
Usaremos df['doença_cardíaca'].value_counts() para verificar como está a frequência de cada categoria dentro dela.
df['Doenca cardiaca'].value_counts()
Ausencia 150
Presenca 120
Name: Doenca cardiaca, dtype: int64
Vemos que os dados não estão desbalanceados, com 150 pessoas sem a doença e 120 pessoas com presença da doença.
Não precisaremos trabalhar com balanceamento neste curso, mas precisamos converter a coluna alvo "Doença cardíaca", que está como tipo objeto, para tipo numérico, para o algoritmo XGBoost. O XGBoost precisa que essa coluna também esteja como tipo numérico inteiro.
Faremos isso com a função map(), ela consegue mudar os valores, passando um dicionário entre parentes e chaves com os valores atuais para os valores que queremos.
df['Doenca cardiaca'] = df['Doenca cardiaca'].map({'Presenca': 1, 'Ausencia': 0})
Executando, confirmamos a conversão e agora nosso DataFrame está pronto para começar o Machine Learning.
Espero você na próxima aula, para continuarmos!
Sobre o curso Classificação: melhorando o desempenho com XGBoost
O curso Classificação: melhorando o desempenho com XGBoost possui 122 minutos de vídeos, em um total de 50 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Conhecendo os dados
- Iniciando a classificação
- Realizando a validação cruzada
- Ajustando hiperparâmetros do XGBoost
- Utilizando o XGBoost em pipelines