Data Visualization: gráficos de comparação e distribuição
Comparando dados - Apresentação
Olá! Me chamo Afonso Rios, sou instrutor da Escola de Dados da Alura.
Audiodescrição: Afonso Rios é um homem de pele morena, com cabelos e olhos castanhos escuros. Está com barba baixa e camiseta preta. Ao fundo, há uma parede branca, com detalhes em azul e cinza, além de decorações da Alura e futebol.
O que vamos aprender?
Neste curso, aprenderemos a:
- Explorar as visualizações de dados;
- Criar gráficos, utilizando a linguagem Python.
Para isso, vamos trabalhar com um projeto com duas bases diferentes, ambas focadas na comparação e distribuição dos dados. Os dados com os quais trabalharemos terão diferentes tipos de visualizações, aplicadas segundo os questionamentos trazidos durante o curso.
Gráficos de comparação
Também aprederemos a criar alguns tipos de gráficos durante esse curso:
- Gráfico de colunas;
- Gráfico de barras;
- Gráfico de colunas empilhadas;
- Gráfico de barras empilhadas;
- Gráfico de linha;
- Gráfico de linhas.
Além dos recursos que nos permitem selecionar um dado ou escolher o tipo de gráfico, também aprenderemos a criar: destaques, textos de explicação, rótulos e enfocar em pontos que o público deve visualizar.
Também iremos trabalhar com diferentes tipos de dados, em valores absolutos e porcentagens. Aprenderemos a manipular gráficos de tempo, destacando pontos de interesse que nos ajudem a entender a tendência dos valores.
Histogramas e gráficos de densidade
- Histograma;
- Gráfico de densidade;
- Boxplot (diagrama de caixa);
- Violinplot;
- Gráfico de dispersão.
Vamos aprender sobre distribuição, entendendo como o dado está sendo apresentado, conforme as medidas. Também vamos conhecer medidas de tendência central.
Além disso, vamos aprender a como destacar e apontar diferentes partes do gráfico para que o público entenda melhor aqueles pontos.
Por fim, estudaremos sobre visualizações com foco em diferentes agrupamentos de dados, por exemplo, cores, escritas ou acercamentos.
Pré-requisitos
São muitas técnicas! Para realizar esse curso, é ideal que você saiba:
- Um pouco da linguagem Python;
- O básico das bibliotecas de visualização: Matplotlib; Seaborn; e Plotly;
- O básico das bibliotecas de manipulação de dados: Pandas e Numpy.
Nos encontramos no próximo vídeo!
Comparando dados - Conhecendo os dados
Antes de começar o nosso projeto, é sempre importante trazer algumas boas práticas para utilizar as visualizações de dados.
Paleta de cores
Uma delas é trabalhar com a paleta de cores que servem para dois princípios:
- Melhorar a acessibilidade: usar tons de cores contrastantes que diminuam a dificuldade de leitura;
- Identidade visual: deixar a visualização mais uniforme.
Além de passar para a pessoa usuária uma informação sobre uma determinada atividade, facilita a compreensão dos dados para pessoas que tenham maior dificuldade de enxergar alguns tons de cores específicos ou até enxergar diferenças entre tons. Por isso, é essencial ter tudo isso agregados a nossa visualização.
Em nosso projeto, vamos utilizar a paleta de cores com alguns tons em azul, cinza e misto que variam do vermelho ao verde.
Nas paletas de tons em azul e cinza, a nomenclatura vai oscilar de 1 a 5. Quanto maior o número de variação, mais claro vai ser o tom.
# Definindo a paleta de cores
AZUL1, AZUL2, AZUL3, AZUL4, AZUL5 = '#03045e', '#0077b6', "#00b4d8", '#90e0ef', '#CDDBF3'
CINZA1, CINZA2, CINZA3, CINZA4, CINZA5 = '#212529', '#495057', '#adb5bd', '#dee2e6', '#f8f9fa'
VERMELHO1, LARANJA1, AMARELO1, VERDE1, VERDE2 = '#e76f51', '#f4a261', '#e9c46a', '#4c956c', '#2a9d8f'
Vamos rodar esse código ("Ctrl + Enter") com a definição das cores que vamos utilizar em todo nosso projeto, tanto nas primeiras quanto nas últimas aulas.
Conhecendo os dados: situação-problema 1
Agora, vamos conhecer os dados com os quais vamos trabalhar. Essa primeira base de dados vai ser utilizada para as três primeiras aulas desse curso. A partir dela, teremos a primeira situação-problema.
Uma rede de lojas de departamentos que opera em todo o Brasil quer nos passar alguns dados de 2016 a 2019 de vendas realizadas em algumas regiões do país.
Esses dados terão divisão entre região, estado, cidade e até tipo de cliente. Porém, vão ser bem resumidos para agilizar a visualização e criação das tabelas e outras ferramentas necessárias para construção dos gráficos.
Primeiro, vamos tentar ler os dados recebidos. Em uma nova célula, vamos criar um import pandas as pd que importa a biblioteca Pandas, utilizada para fazer a manipulação e seleção dos dados.
import pandas as pd
Após rodar esse código, vamos utilizar essa biblioteca para ler os dados do GitHub do curso, cujo link será disponibilizado na atividade "Preparando o Ambiente".
Para ler o nosso relatório, vamos criar uma variável chamada vendas que vai ser igual à função pd.read_csv(). Entre parênteses e aspas duplas, devemos colocar o link do arquivo CSV do relatório de vendas.
Na linha abaixo, colocamos três pontos, os quais chamamos de ellipsis no Python, apenas para pular os dados porque vamos preencher mais códigos no lugar deles.
Mas, já conseguimos ler os dados que temos ao escrever vendas em uma próxima linha e apertar "Shift + Enter".
# Importando o relatório de vendas
vendas = pd.read_csv("https://raw.githubusercontent.com/afonsosr2/dataviz-graficos/master/dados/relatorio_vendas.csv")
...
vendas
Com isso, vamos carregar a nossa base de dados.
| # | data_pedido | data_envio | modo_envio | nome_cliente | segmento_cliente | cidade | estado | regiao | departamento | tipo_produto | preco_base | preco_unit_sem_desc | desconto | preco_unit_venda | quantidade | vendas | lucro |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-11-09 | 2018-11-12 | Econômica | Thiago Silveira | B2C | Ribeirão Preto | São Paulo | Sudeste | Materiais de construção | encanamentos | 409.70 | 445.33 | 0.000 | 445.33 | 2 | 890.66 | 71.26 |
| 1 | 2018-11-09 | 2018-11-12 | Econômica | Thiago Silveira | B2C | Ribeirão Preto | São Paulo | Sudeste | Materiais de construção | ferramentas | 705.10 | 829.53 | 0.000 | 829.53 | 3 | 2488.59 | 373.29 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 8938 | 2016-01-22 | 2016-01-24 | Econômica | Isabel Araújo | B2C | João Pessoa | Paraíba | Nordeste | Materiais de construção | iluminação | 26.29 | 31.79 | 0.100 | 28.61 | 3 | 85.83 | 6.96 |
| 8939 | 2019-05-05 | 2019-05-10 | Econômica | Esther Rodrigues | B2C | Mossoró | Rio Grande do Norte | Nordeste | Jardinagem e paisagismo | mobiliário de exterior | 351.36 | 413.37 | 0.000 | 413.37 | 2 | 826.74 | 124.02 |
A nossa base de dados tem dois tipos de data, data_pedido e data_envio. Também tem modo_envio, nome_cliente e assim sucessivamente. Teremos dados numéricas, categóricos e tempo.
Porém, é muito comum que os dados de modo de tempo não venham com a descrição de tempo quando puxamos os dados para dentro do Python. Eles vêm com modo objeto que seria uma categoria.
Por isso, vamos transformar esses dados em dados de tempo.
Transformando objetos em dados de tempo
Vamos pegar as duas colunas de data_pedido e data_envio e fazer o mesmo processo.
No lugar das ellipsis, vamos informar que a coluna vendas["data_pedido"] é igual à função do Pandas chamada pd.to_datetime().
Vamos passar dois parâmetros para essa função: o tipo da coluna que queremos fazer a transformação para datetime e o formato do tempo em que a coluna está.
Nesse caso, vamos passar vendas["data_pedido"] como primeiro parâmetro. No segundo parâmetro, vamos passar o format igual à formatação atual entre aspas duplas. A formatação será %Y maiúsculo para passar os 4 dígitos do ano, %m minúsculo para passar os 2 dígitos de meses e %d minúsculo para os dois dígitos do dia. Todos separados por hífen.
Vamos fazer o mesmo processo para a coluna data_envio. Por isso, vamos copiar e colar essa linha logo abaixo e substituir data_pedido para data_envio.
# Atualizando as colunas de pedido e envio para o tipo data
vendas = pd.read_csv("https://raw.githubusercontent.com/afonsosr2/dataviz-graficos/master/dados/relatorio_vendas.csv")
vendas["data_pedido"] = pd.to_datetime(vendas["data_pedido"], format="%Y-%m-%d")
vendas["data_envio"] = pd.to_datetime(vendas["data_envio"], format="%Y-%m-%d")
vendas
Ao rodar esse código, o retorno vai ser o mesmo dataframe com 8940 linhas e 17 colunas. Visualmente, os dados de data permaneceram os mesmos. Mas, na verdade, mudaram um pouco.
Para entender essa mudança, vamos verificar os tipos de dados que temos e se temos dados nulos. Em uma nova célula, vamos passar o nome do dataframe vendas seguido do método info() que traz informações básicas sobre os dados.
# Verificando os tipos de dados e se existem dados nulos
vendas.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8940 entries, 0 to 8939
Data columns (total 17 columns):
| Column | Non-Null Count | Dtype |
|---|---|---|
| data_pedido | 8940 non-null | datetime64[ns] |
| data_envio | 8940 non-null | datetime64[ns] |
| modo_envio | 8940 non-null | object |
| nome_cliente | 8940 non-null | object |
| segmento_cliente | 8940 non-null | object |
| cidade | 8940 non-null | object |
| estado | 8940 non-null | object |
| regiao | 8940 non-null | object |
| departamento | 8940 non-null | object |
| tipo_produto | 8940 non-null | object |
| preco_base | 8940 non-null | float64 |
| preco_unit_sem_desc | 8940 non-null | float64 |
| desconto | 8940 non-null | float64 |
| preco_unit_venda | 8940 non-null | float64 |
| quantidade | 8940 non-null | int64 |
| vendas | 8940 non-null | float64 |
| lucro | 8940 non-null | float64 |
dtypes: datetime64ns, float64(6), int64(1), object(8)
Tanto data_pedido quando data_envio estão como datetime64[ns]. Se não tivéssemos feito essa alteração, eles também estariam como tipo object - muito utilizado para dados categóricos, como strings ou strings e números. Além disso, temos alguns dados do tipo float e int.
Outro ponto curioso é que temos 8940 entradas para cada coluna. Essas 17 colunas não tem nenhum valor null. Até porque no nosso curso, não vamos focar no tratamento de dados nulos.
Deixamos os dados prontos para fazer a seleção e criar a visualização que desejamos para aquele tipo de dado.
Questionamentos
Depois de visualizar os dados que temos de maneira rápida, vamos partir para análises baseadas em questionamentos respondidos através desses dados.
- Qual o total de vendas por ano? E qual ano performou melhor em nossa base de dados?
- Qual é o top 7 produtos que mais apresentaram lucros em nosso catálogo durante o período representado?
- Se separarmos o total de vendas por ano por regiões? O que conseguimos observar em nossos dados?
- Qual o modo de envio mais utilizado pelos clientes da loja? É proporcional para B2B e B2C?
- Qual o total de vendas por trimestre do estado de São Paulo?
- Qual o faturamento por trimestre em cada região?
Esses questionamentos podem ser sobre o faturamento de vendas entorno de um ano específico, o top produtos vendidos por aquela empresa e determinado departamento. Também vamos separar alguns desses dados por regiões.
Além disso, falaremos sobre modo de envio e separação de tempos diferentes. Ao invés de anos, que têm uma granularidade menor, vamos trabalhar com dados que tenham maiores divisões de tempo.
Tudo isso vai ser respondido com a criação de visualizações ao longo das três primeiras aulas. Vamos aplicar um tipo de gráfico diferente para cada resposta.
Pronto! Agora que importamos nossos dados e sabemos o que devemos responder, vamos começar a construir nossos gráficos?
Comparando dados - Gráfico de colunas
Dentro do Colab, disponibilizamos uma imagem alguns tipos de gráfico de comparação que podem ser utilizados, dando maior destaque aos gráficos de barras e colunas - os quais vamos explorar dentro dessa aula.
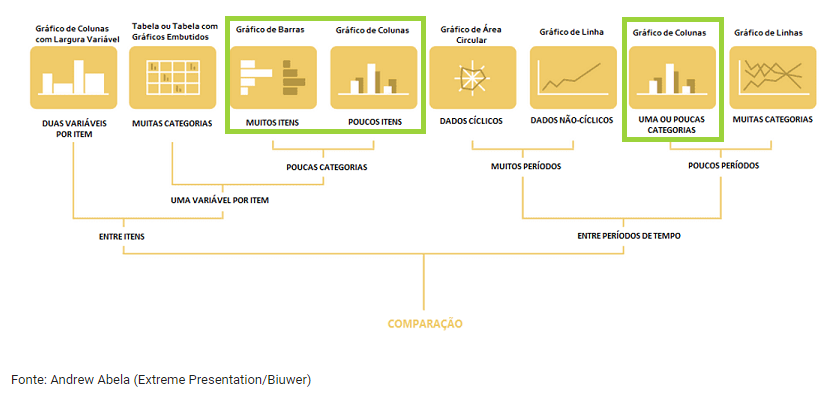
Primeiro, vamos trabalhar com gráficos de colunas para responder o seguinte questionamento ao criar essa visualização:
Qual o total de vendas por ano? E qual ano performou melhor em nossa base de dados?
A primeira pergunta será respondida nesse vídeo e a segunda será em um próximo vídeo.
Total de vendas por ano
A pergunta sobre o total de vendas por ano traz duas variáveis de interesse: total de vendas e anos.
Como queremos comparar diferentes anos, faz sentido usar gráficos de comparação.
Para gráficos de comparação com poucos itens, é ideal utilizar gráficos de colunas.
No nosso caso, são poucos períodos separados, desde 2016 a 2019.
Para criar essa visualização, primeiro vamos tratar o dataframe que importamos anteriormente, trazendo uma pequena tabela com os valores discriminados. Em seguida, vamos criar o gráfico com esses valores que construímos.
Tratando o dataframe
Primeiro, vamos criar um dataframe (df) chamado df_vendas_ano que vai receber uma cópia de vendas. Ou seja, vendas.copy().
O que fizemos? O df principal chamado vendas que contém os dados das vendas da loja de departamentos vai ser copiado para a variável df_vendas_ano.
Dessa forma, as alterações que fizermos em df_vendas_ano não vão acontecer no df original de vendas. Ou seja, criamos uma cópia profunda, separando esses dois dataframes ainda que tenham os mesmos valores.
Para trabalhar com esse df_vendas_ano, não queremos todos os resultados de vendas. Queremos somente as duas variáveis de interesse com as quais queremos trabalhar.
Por isso, vamos fazer uma seleção em que df_vendas_ano vai receber, entre colchetes duplos, a coluna de interesse data_pedido que contém o ano e a coluna de vendas. Ambas separadas por vírgulas e entre aspas duplas.
Lembre-se de colocar o df_vendas_ano em uma nova linha para poder rodar esse célula e visualizar o novo dataframe que terá apenas duas colunas.
# Criando um df com os dados desejados
df_vendas_ano = vendas.copy()
df_vendas_ano = df_vendas_ano[["data_pedido", "vendas"]]
df_vendas_ano
| # | data_pedido | vendas |
|---|---|---|
| 0 | 2018-11-09 | 890.66 |
| 1 | 2018-11-09 | 2488.59 |
| … | … | … |
| 8939 | 2019-05-05 | 826.74 |
Na coluna à esquerda, temos as datas inteiras dos pedidos. E, na coluna à direita, temos as vendas daquela data.
Mas, lembra que queremos o faturamento por ano. Para isso, devemos pegar somente a parte de ano dentro dessa data_pedido e utilizar esse período como a nossa agregação.
Por isso, vamos gerar uma nova coluna onde vamos extrair o ano de data_pedido, que é uma variável do tipo datetime.
Na mesma célula, vamos criar a coluna df_vendas_ano["ano"] que vai receber df_vendas_ano.data_pedido. Além de chamar colunas entre colchetes e aspas, também podemos chamá-las com o ponto.
Vamos acrescentar .dt para informar que vamos utilizar a função do tipo tempo para essa coluna data_pedido. Em seguida, vamos colocar a função do tipo tempo que queremos utilizar, o .year que significa ano em inglês.
Com isso, vamos puxar os anos da nossa coluna de data_pedido.
Feito isso, vamos retirar a coluna data_pedido, porque ela somente servia para a extração de ano. Para isso, vamos usar a função drop().
Na próxima linha, escrevemos df_vendas_ano.drop(). O drop() recebe alguns parâmetros, dentre eles, o labels que são as colunas que queremos retirar. Nesse caso, labels será igual à data_pedido entre aspas.
Outro parâmetro que vamos passar é o axis = 1. No modo padrão de axis = 0, essa função vai tentar eliminar linhas. Mas, com o axis = 1, informamos que queremos retirar uma coluna.
Por fim, vamos usar o inplace = True. Se não colocamos esse parâmetro, é como se retirássemos a coluna apenas para visualização. Mas, como queremos realmente aplicar essa ação, usamos o inplace = True.
# Gerando uma coluna que represente apenas os anos puxando-os da coluna data pedido
df_vendas_ano["ano"] = df_vendas_ano.data_pedido.dt.year
df_vendas_ano.drop(labels = "data_pedido", axis = 1, inplace = True)
df_vendas_ano
| # | vendas | ano |
|---|---|---|
| 0 | 890.66 | 2018 |
| 1 | 2488.59 | 2018 |
| … | … | … |
| 8939 | 826.74 | 2019 |
Ao rodar essa célula novamente, vamos ter as vendas na coluna da esquerda e o ano das vendas que foram extraídos do data_pedido na coluna da direita.
Porém, temos várias linhas com valores de vendas para o ano de 2018 e outras para 2017. Ainda não temos o dado de total de vendas por ano como gostaríamos.
Para resolver esse problema, vamos utilizar as fórmulas de agrupamento.
Ainda na mesma célula, vamos pegar o df_vendas_ano que vai ser igual à df_vendas_ano e usar uma função chamada .groupby().
O groupby() recebe a coluna que queremos utilizar para agrupar. Como queremos o faturamento por ano, vamos usar a coluna ano como fator de agrupamento. Vamos abrir e fechar colchetes dentro dos parênteses e passar a coluna ano entre aspas.
E como vai ser esse agrupamento? Ele pode ser por média, soma ou outras formas. Nesse caso, vamos fazer por soma, pois queremos saber o total por ano. Por exemplo, vamos somar todos os valores de 2018.
Para isso, passamos a função .aggregate(), ou agg() se preferir. Nele, vamos passar a operação sum entre aspas para sinalizar que queremos realizar uma soma nesse agrupamento.
# Agrupando os dados por ano
df_vendas_ano = df_vendas_ano.groupby(["ano"]).aggregate("sum")
df_vendas_ano
| ano | vendas |
|---|---|
| 2016 | 1402652.33 |
| 2017 | 1489179.52 |
| 2018 | 1884161.41 |
| 2019 | 2305006.29 |
Quando rodamos a célula, o df inteiro foi reduzido a um df que parece uma tabela. Temos os valores de vendas dos anos de 2016 a 2019, separadamente.
Só essa tabela gera uma ótima visualização para saber a diferença de valores entre os anos. Mas, como nosso curso é focado em visualização de gráficos, vamos aprender como construir um gráfico de comparação utilizando esses dados que construímos.
Construindo o gráfico de comparação
Para gerar o gráfico de colunas, vamos escrever em uma nova célula.
Primeiro, vamos usar um import matplotlib.pyplot as plt e import seaborn as sns, pois usaremos duas bibliotecas:
- Matplotlib: responsável por criar a figura, os eixos e alguns elementos visuais;
- Seaborn: responsável pela estilização do nosso gráfico.
# Importando as bibliotecas
import matplotlib.pyplot as plt
import seaborn as sns
Depois de importar as bibliotecas, vamos construir a nossa figura, delimitando o espaço que queremos utilizar. Para isso, vamos criar um objeto fig e ax que vão ser advindos da fórmula do plt.subplots().
Podemos passar alguns parâmetros para o subplots(). Inicialmente, vamos passar somente o figsize igual à (10,4), ou seja, largura de 10 e altura de 4 polegadas.
Vamos criar essa área, passando um objeto figura e um axis para manipulá-las. A figura é essa área onde podemos colocar o gráfico. Uma figura pode ter vários gráficos. É como um canvas. Já o axis é o eixo dos gráficos, ou seja, a área onde vão ser construídos os gráficos.
Além disso, vamos trazer a estilização desse gráfico utilizando o sns.set_theme(). Entre os possíveis parâmetros de set_theme(), vamos utilizar style que vai trazer o estilo que queremos.
Nesse caso, vamos escolher o style="white", mas existem uma série de estilos.
Por isso, é muito importante que você confira a documentação do Seaborn sobre a função set_theme() para entender cada um dos estilos possíveis.
Essa função vai ditar as diferentes formas de exibição do gráfico. Seus parâmetros podem guardar o tamanho de um ticks (rótulo), o formato do texto, a família da fonte, o tamanho do texto, grades, fundos, entre outros.
O estilo white traz uma visualização mais limpa, com o fundo branco, sem grids (grades) e outros elementos que vamos notar durante a construção do gráfico.
# Área do gráfico e tema da visualização
fig, ax = plt.subplots(figsize=(10,4))
sns.set_theme(style="white")
Para conseguirmos construir o gráfico, vamos continuar a escrever na mesma célula.
Logo abaixo, vamos usar o objeto ax passando o sns.barplot(). Como primeiro parâmetro, vamos passar o data igual ao df_vendas_ano.
Também vamos passar o x igual à df_vendas_ano.index. Note que não passamos o nome da coluna e, sim, .index porque, quando fazemos um agrupamento de dados, o fator de agrupamento se torna o índice dos nossos dados. No nosso caso, a coluna ano é esse índice.
Em seguida, vamos passar o parâmetro y que vai ser o eixo vertical. Ele vai ser igual à vendas entre aspas, ou seja, o nosso valor total das vendas.
Por fim, vamos passar um palette que são as cores do nosso gráfico. Inicialmente, vamos usar a cor AZUL2 da nossa paleta de cores, entre colchetes.
O parâmetro pallete serve para passar paletas de cores. Você pode passar uma ou mais. Vamos começar apenas com uma.
# Gerando o gráfico de colunas
ax = sns.barplot(data = df_vendas_ano, x = df_vendas_ano.index, y="vendas", palette = [AZUL2])
Podemos executar a célula inteira para criar o gráfico.
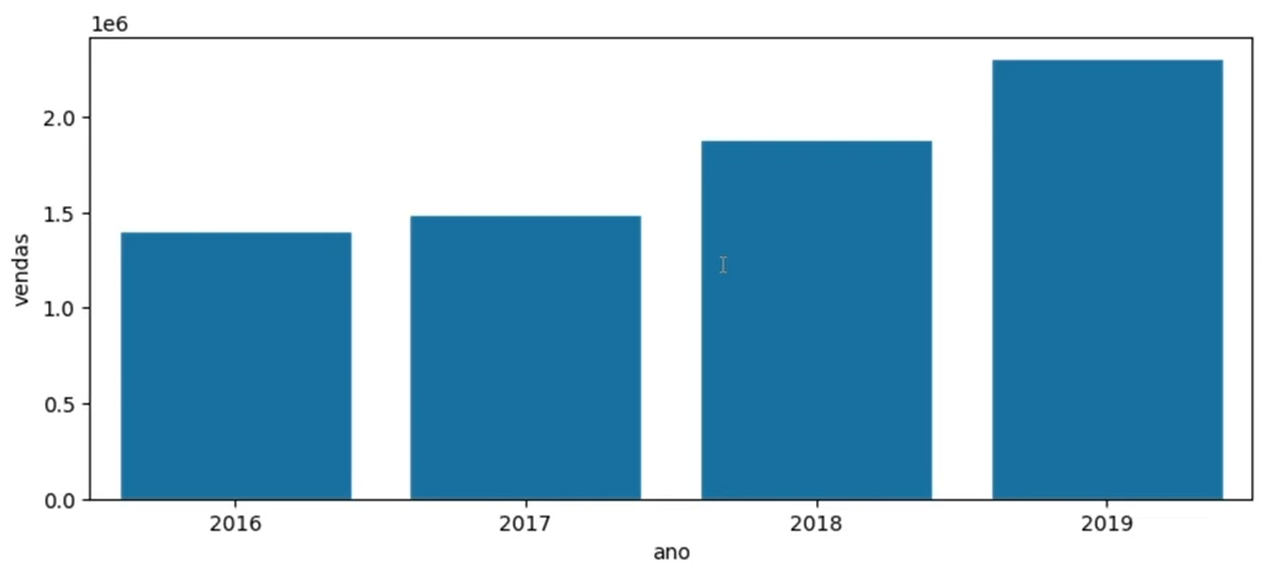
Já conseguimos visualizar a formação do gráfico e podemos perceber algumas informações interessantes. Por exemplo, a cada ano aumenta a quantidade de vendas.
Porém, esse gráfico pode ser melhor estilizado e personalizado. Podemos adicionar um título, tirar a borda, aumentar o tamanho dos rótulos, colocar os valores nas colunas e mais! Mas, vamos deixar essas modificações para o próximo vídeo.
Sobre o curso Data Visualization: gráficos de comparação e distribuição
O curso Data Visualization: gráficos de comparação e distribuição possui 232 minutos de vídeos, em um total de 62 atividades. Gostou? Conheça nossos outros cursos de Data Science em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Comparando dados
- Agrupando dados
- Séries de tempo
- Distribuindo dados
- Explorando padrões nos dados