

Introdução
Comumente realizamos cálculos estatísticos para obter insights durante a análise exploratória dos dados. Para facilitar a nossa vida, podemos recorrer ao uso de diversas ferramentas, tais como o Microsoft Excel e, até mesmo, linguagens de programação como o R, Python e suas bibliotecas.
A biblioteca Pandas é uma delas! Recheada de funções voltadas para todo o tipo de necessidade e incluindo métodos que podem facilitar a nossa vida. No momento de descrever estatisticamente uma base de dados, por exemplo, a função Describe é capaz de gerar estatísticas descritivas através de uma base de dados importada.

Lendo a base de dados
Para entender melhor como funciona essa função, vamos importar a biblioteca Pandas para ler a base de dados de extensão CSV e exibir as 5 primeiras linhas da base utilizando a função head().
Import pandas as pd
dados = pd.read_csv(“dataset-rh.CSV”, sep=”;”)
dados.head()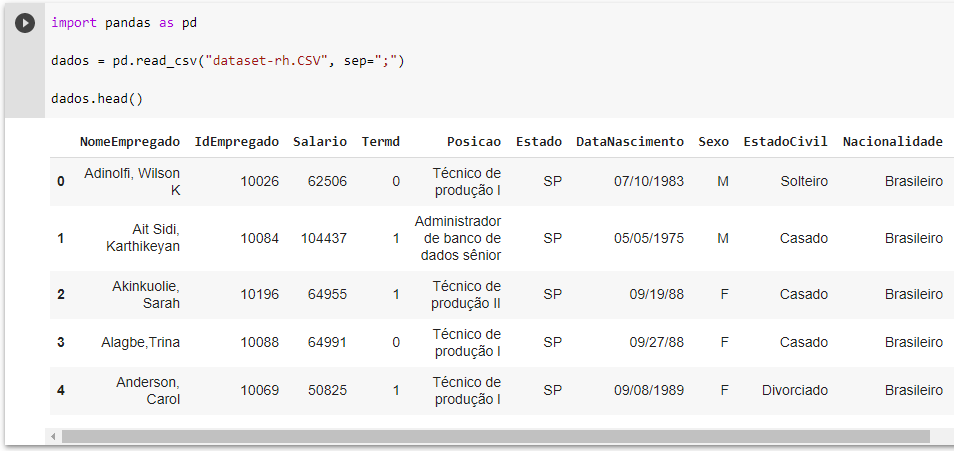
Feito isso, podemos observar que a base importada possui dados categóricos e numéricos. Assim, vamos usar a função describe para entender quais resultados serão retornados.
Dados numéricos
dados.describe()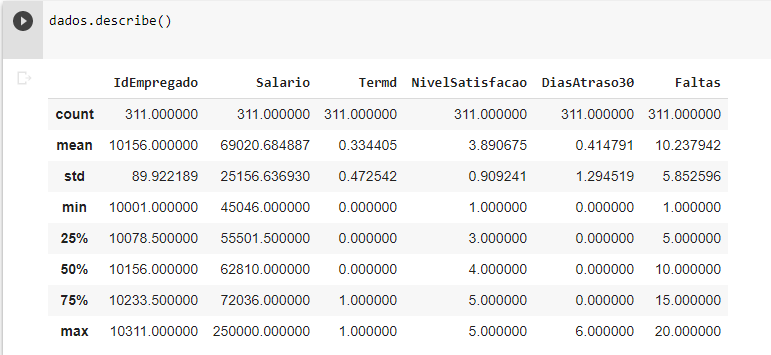
Nota-se que a função describe, por padrão, escolhe apenas os dados numéricos, retornando a contagem de linhas (count), o cálculo da média (mean) e desvio padrão (std) e identifica o valor mínimo (min), os quartis (25%, 50% e 75%) e o valor máximo (max).
Buscando o perfeito entendimento dos resultados, vamos focar na coluna Salario:
- count - Através da contagem de valores, conseguimos entender o tamanho da amostra. Inclusive conseguimos detectar linhas com valores vazios comparando o valor do count entre duas colunas. Imagina que você utilizou a função describe e a coluna ID tem 500 valores, porém a coluna Salario tem 300 valores. Com isso, sabemos que a coluna Salario tem 200 valores vazios e é preciso tratar esses dados.
- mean - Por ser a média aritmética, devemos sempre ficar atentos ao que ela representa, pois o resultado nem sempre refletirá a realidade. Podemos pensar numa amostra do salário mensal de 5 pessoas, sendo que 4 delas recebem 2.000 reais e uma delas recebe 50.000 reais. Ao calcularmos a média simples, encontramos 11.600 reais como resultado, o que não representa a realidade da maioria das pessoas dessa amostra.
- std - O desvio padrão é uma medida de como os dados se dispersam em relação à média, em outras palavras, ele mostra o quanto esses dados estão espalhados. O desvio padrão é a estatística descritiva que nos permite atribuir um número único para essa dispersão em torno da média. Se a distribuição for muito dispersa, podemos calcular a quantos desvios padrão ela está do centro, por exemplo. Em nosso caso, sabemos que aproximadamente 25 mil reais estão variando em torno da média.
- min e max - São os valores que nos auxiliam para identificar a amplitude da amostra. Na coluna Salario temos uma pessoa que recebe o valor de aproximadamente 45 mil (min) e outra que recebe aproximadamente 250 mil, logo a amplitude é igual a diferença entre 250 mil e 45 mil.
- quartis - São os valores que nos mostram de que forma os dados foram distribuídos. Como exemplo, temos o quartil de 50%, definida como mediana, que no caso da coluna Salario mostra que metade dos valores são inferiores a 62 mil e a outra metade é superior a 62 mil.
Dados categóricos
Também é possível obtermos algumas informações das colunas categóricas. Para isso, precisamos selecioná-las para usar a função describe.
dados[[“Estado,”Sexo”]].describe()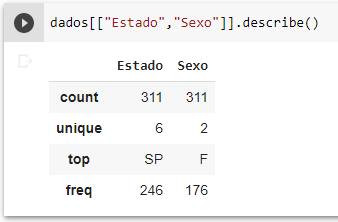
Como os dados das colunas Estado e Sexo são categóricos, a função describe retorna cálculos mais adequados para este tipo de dados, como a contagem de valores distintos (unique), a moda (top) e a frequência da mesma (freq). Por exemplo, a moda SP, que tem uma frequência acima dos 50% de toda a amostra.
Caso tenha interesse em conhecer ainda mais essa função e a sua aplicabilidade, dê uma olhada na documentação.
