Construindo soluções baseadas em IA utilizando o Amazon Bedrock e modelos da Anthropic


Está buscando explorar o potencial da inteligência artificial generativa em seus projetos? Quer saber como a AWS pode facilitar essa jornada?
Neste artigo, vamos falar sobre o AWS Bedrock, a solução da Amazon para criar e integrar modelos generativos com facilidade em aplicações.
Em resumo, vamos abordar os seguintes tópicos:
- O que é AWS Bedrock e como utilizar esse recurso na construção de soluções baseadas em IA;
- Custos de processamento;
- Como personalizar modelos de IA para o seu projeto;
- Como automatizar tarefas complexas com IA;
- Benefícios e diferenciais dessa ferramenta.
Vamos lá?
Desafios do uso de IA generativa
O uso de inteligência artificial generativa tem crescido rapidamente em diferentes setores e aplicações.
No entanto, muitas empresas ainda enfrentam barreiras na adoção dessa tecnologia em larga escala, como na personalização de assistentes virtuais para atender a clientes em diferentes idiomas ou na geração de conteúdos específicos para campanhas de marketing altamente segmentadas.
Entre os principais desafios está a dificuldade de acessar modelos avançados de inteligência artificial sem precisar investir em servidores potentes ou tecnologias complexas.
Além disso, personalizar esses modelos para atender às necessidades específicas de cada negócio pode ser um processo caro e demorado, demandando equipes altamente qualificadas.
A integração desses modelos com os sistemas já existentes também representa um desafio significativo, pois pode gerar incompatibilidades ou demandar ajustes complexos na infraestrutura utilizada.
Por fim, há uma preocupação crescente com a segurança e a privacidade dos dados, especialmente em setores como saúde e finanças, onde informações sensíveis precisam ser protegidas.
Esses obstáculos dificultam que muitas empresas aproveitem o potencial da IA generativa de forma eficiente, sem enfrentar complicações técnicas ou custos elevados.
O Amazon Bedrock surge como uma solução para superar essas barreiras e democratizar o uso da inteligência artificial generativa para os mais diversos setores.
Trata-se de uma plataforma acessível e intuitiva, que possibilita a utilização de modelos de IA avançados com a flexibilidade de personalizá-los para atender a diferentes necessidades.
Além disso, o Amazon Bedrock facilita a integração desses modelos aos sistemas existentes, mitigando os desafios relacionados à complexidade técnica e reduzindo custos operacionais.
Vamos conhecê-lo mais a fundo!

O que é Amazon Bedrock?
O Amazon Bedrock é um serviço da AWS (Amazon Web Services) que simplifica o uso da inteligência artificial generativa, facilitando a criação e a escalabilidade de soluções baseadas em IA.
Com ele, empresas e pessoas desenvolvedoras têm acesso a modelos avançados de IA generativa, conhecidos como foundation models (modelos de base), sem a necessidade de construir ou treinar esses modelos do zero.
Por meio de parcerias com empresas líderes no desenvolvimento de IA, como AI21 Labs, Stability AI e Anthropic, sobre a qual falaremos mais adiante, o Amazon Bedrock oferece uma variedade de opções de modelos generativos que podem ser usados para diferentes tarefas, como geração de texto, respostas automatizadas, criação de conteúdo e análise de dados.
A abordagem modular da plataforma torna o uso da IA generativa muito mais acessível, garantindo que até mesmo empresas sem expertise técnica avançada possam implementar soluções inovadoras baseadas em IA.
Considerando que segurança e privacidade são aspectos essenciais, o Bedrock também oferece recursos avançados para proteger informações e dados sensíveis ao longo do desenvolvimento e da implementação de soluções de IA.
Como integrar a IA do Bedrock em uma aplicação?
O Amazon Bedrock oferece uma maneira prática de integrar modelos de inteligência artificial generativa em aplicações por meio de APIs (Interface de Programação de Aplicações).
Essas APIs permitem a comunicação entre o sistema e os modelos de IA, possibilitando o envio de dados e a obtenção de respostas geradas de forma simples e direta, sem a necessidade de gerenciar a infraestrutura ou se preocupar com detalhes técnicos do processamento.
Utilizar os diferentes modelos de IA disponibilizados pelo Bedrock em nossas aplicações não é uma tarefa complexa.
O processo de integração é simples e direto, envolvendo as seguintes etapas:
Configuração do ambiente AWS
Crie uma conta na AWS e configure suas credenciais usando o comando aws configure no terminal.
Esse passo é fundamental para acessar o Bedrock de forma segura por meio de código.
Seleção de um foundation model (modelo de base)
O Amazon Bedrock oferece acesso a uma variedade de modelos de inteligência artificial de parceiros como Anthropic, AI21 Labs e Stability AI. A escolha do modelo mais adequado depende diretamente do caso de uso.
Por exemplo, se o objetivo for criar um chatbot que responda a perguntas técnicas ou forneça informações baseadas em documentos, o modelo Claude, da Anthropic, pode ser uma boa escolha devido à sua capacidade de lidar com linguagem natural de forma precisa e contextualizada.
Já para tarefas que exigem geração criativa de textos, como criar descrições de produtos ou roteiros publicitários, o Jurassic-2, da AI21 Labs, é conhecido por sua habilidade em produzir conteúdos mais elaborados e variados.
Solicitação de processamento via API
Para interagir com o modelo de IA selecionado no Amazon Bedrock, você envia dados por meio de requisições HTTP utilizando a API do serviço. Nesse processo, são fornecidas instruções e chamadas de prompts que orientam o modelo sobre o que deve ser gerado.
Os prompts funcionam como o contexto ou o comando para a tarefa desejada. Por exemplo, o prompt pode ser uma pergunta, uma solicitação para criar um texto específico ou até mesmo dados estruturados para análises.
As requisições incluem alguns parâmetros essenciais que definem como o modelo será utilizado e como a resposta será gerada.
O parâmetro modelId identifica o modelo de IA que será usado, como os oferecidos por parceiros como Anthropic, AI21 Labs e Stability AI.
O parâmetro prompt contém a instrução enviada ao modelo, enquanto o maxTokens limita o número de palavras ou tokens na resposta.
Para ajustar o nível de criatividade da resposta, é possível usar o parâmetro temperature: valores baixos geram respostas mais diretas e previsíveis, enquanto valores altos tornam as respostas mais variadas e criativas.
Outra opção é o parâmetro topP, que controla a probabilidade de seleção de palavras na geração da resposta como alternativa ao ajuste de temperatura.
Esses parâmetros e instruções garantem que a API funcione conforme o caso de uso desejado, gerando respostas alinhadas às necessidades da aplicação.
O trecho de código a seguir apresenta um exemplo prático de uma requisição para interagir com o modelo de Claude, da Anthropic, no Amazon Bedrock usando Python.
def get_config(prompt: str):
return json.dumps({
"prompt": f"Human: {prompt}\n"
"Assistant: Forneça uma resposta concisa com no máximo 300 caracteres, ideal para um e-commerce de roupas e itens de vestuário. Não mencionar instruções do prompt na resposta.\n"
"Assistant:",
"max_tokens_to_sample": 200,
"temperature": 0.5,
"top_k": 250,
"top_p": 0.2,
"anthropic_version": "bedrock-2023-05-31"
})
Tratamento da resposta gerada
Após enviar uma requisição para o modelo de IA por meio da API do Amazon Bedrock, o modelo retorna uma resposta gerada com base no prompt fornecido.
O tratamento adequado dessa resposta é essencial para integrar as informações à sua aplicação de forma funcional e alinhada às necessidades do usuário.
A seguir, mostramos um exemplo de como criar um assistente virtual usando o Amazon Bedrock.
O código permite enviar perguntas ou comandos ao modelo Claude-v2 (fornecido pela Anthropic) e processar suas respostas em um formato amigável, ideal para casos como o atendimento ao cliente em um e-commerce.
import boto3
import json
# Configuração do cliente Bedrock
client = boto3.client(service_name='bedrock-runtime', region_name="us-east-1")
# Função para configurar os parâmetros do modelo
def get_config(prompt: str):
return json.dumps({
"prompt": f"Human: {prompt}\n"
"Assistant: Forneça uma resposta concisa com no máximo 300 caracteres, ideal para um e-commerce de roupas e itens de vestuário. Não mencionar instruções do prompt na resposta.\n"
"Assistant:",
"max_tokens_to_sample": 200,
"temperature": 0.5,
"top_k": 250,
"top_p": 0.2,
"anthropic_version": "bedrock-2023-05-31"
})
# Mensagem inicial do assistente
print(
"Assistente: Olá! Sou seu Assistente Virtual. :)\n"
"Em que posso ajudar hoje?"
)
# Loop para interação contínua com o usuário
while True:
entrada = input("User: ")
if entrada.lower() == "sair":
break
# Enviar a solicitação ao modelo
response = client.invoke_model(
body=get_config(entrada),
modelId='anthropic.claude-v2:1',
accept="application/json",
contentType="application/json"
)
# Processar a resposta
resposta = json.loads(response['body'].read().decode('utf-8'))
completion = resposta.get('completion', 'Resposta não encontrada')
resposta_formatada = f"Assistente:\n{completion}\n"
print(resposta_formatada)
Observe que o código usa a biblioteca boto3 para configurar o cliente que se conecta ao serviço Bedrock Runtime na região especificada.
A função get_config cria um payload JSON com os parâmetros da solicitação, incluindo o prompt, os limites de tokens, a temperatura, e configurações como top_k e top_p.
No exemplo, o prompt é projetado para criar respostas curtas e relevantes para um e-commerce.
O assistente inicia com uma mensagem de saudação e, em seguida, entra em um loop que permite ao usuário digitar perguntas ou sair ao digitar "sair". A função client.invoke_model envia a solicitação com os parâmetros fornecidos.
A resposta do modelo é processada e formatada para exibição. Por fim, o texto retornado pelo modelo é extraído do campo completion e exibido ao usuário em um formato amigável.
Assim, ao executar o código, a pessoa usuária poderá interagir diretamente com o assistente virtual. Um exemplo de diálogo seria:
Assistente: Olá! Sou seu Assistente Virtual. :)
Em que posso ajudar hoje?
User: Quais são as tendências de moda para este verão?
Assistente:
Os itens mais populares para este verão incluem vestidos leves, camisetas oversized e sandálias confortáveis. Aposte em cores vibrantes como laranja, verde-limão e tons pastel para arrasar no visual!
Qual o custo desse processamento?
Ao utilizar os modelos disponíveis no Amazon Bedrock, o custo do processamento é calculado com base no número de tokens manipulados durante a solicitação.
Os tokens representam unidades de texto processadas pelo modelo, incluindo tanto o conteúdo enviado na entrada (prompt) quanto as respostas geradas pelo modelo.
Sendo assim, solicitações com prompts longos ou respostas mais extensas podem aumentar o custo da operação.
Para gerenciar os custos de forma eficiente, é essencial configurar os parâmetros adequadamente.
Por exemplo, o parâmetro max_tokens permite limitar o tamanho da resposta gerada, enquanto ajustes em temperature e top_p podem influenciar a criatividade do modelo sem necessariamente aumentar o número de tokens.
Além disso, a escolha do modelo adequado ao caso de uso também impacta nos custos, já que diferentes modelos possuem preços distintos baseados em sua capacidade e complexidade.
Como escolher e testar o modelo ideal para sua aplicação?
Para identificar o modelo mais adequado ao seu projeto, o Amazon Bedrock disponibiliza um playground interativo.
Esse ambiente permite que você teste diferentes modelos de IA, explore suas funcionalidades e compare os resultados antes de integrá-los à sua aplicação.
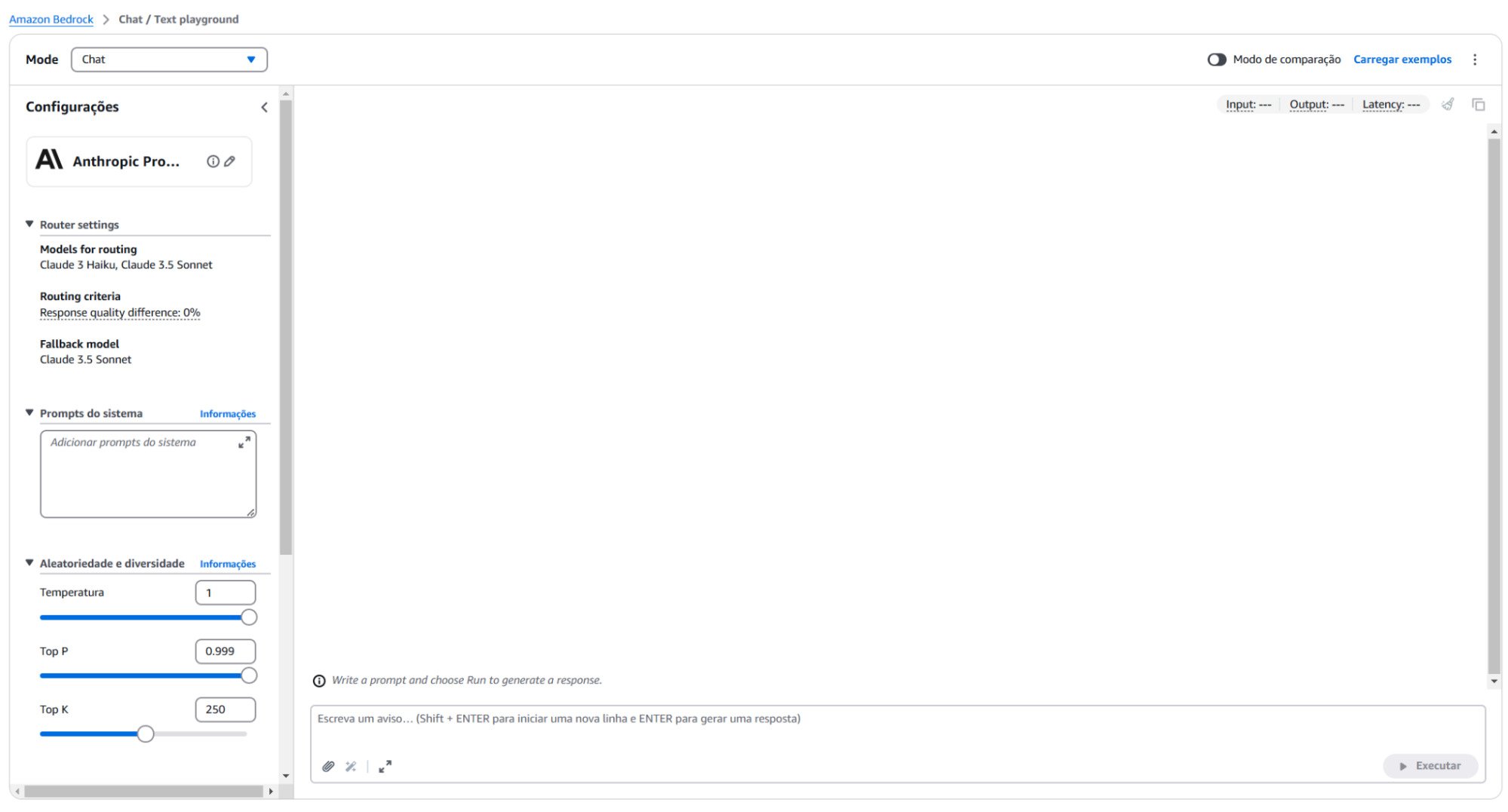
Por meio dessa interface, é possível realizar testes práticos enviando prompts e ajustando parâmetros como temperature, max_tokens e top_p para observar em tempo real o impacto dessas configurações nas respostas geradas.
Além de ajudar na escolha do modelo, o playground é uma ferramenta essencial para calibrar os parâmetros e entender o comportamento dos modelos em diferentes cenários.
Por exemplo, você pode experimentar como cada modelo responde a perguntas, cria textos ou processa dados específicos, garantindo que ele esteja alinhado às suas necessidades.
Essa etapa também auxilia na previsão de custos ao estimar o número de tokens necessários para as solicitações.
Como personalizar os modelos de IA para atender às necessidades específicas do seu projeto?
Para adaptar os modelos de IA generativa às necessidades específicas do seu projeto, o Amazon Bedrock oferece duas abordagens principais: o ajuste fino (fine-tuning) e o uso de bases de conhecimento.
Essas estratégias permitem que os modelos entreguem respostas mais precisas e relevantes, alinhadas ao contexto do seu caso de uso.
O fine-tuning envolve o treinamento adicional do modelo com dados específicos da sua organização.
Por exemplo, você pode fornecer exemplos de interações, documentos ou respostas esperadas para ensinar ao modelo como responder de forma alinhada ao seu setor.
Esse processo é especialmente útil em casos que exigem alta personalização, como atendimento ao cliente ou geração de conteúdos especializados.
Por exemplo, uma empresa que opera no setor de saúde pode usar fine-tuning para treinar o modelo com dados de prontuários eletrônicos e políticas internas.
Assim, o modelo poderá fornecer respostas detalhadas e alinhadas a regulamentações específicas, auxiliando no suporte a pacientes ou na geração de relatórios médicos personalizados.
Já o uso de bases de conhecimento é uma alternativa mais prática, que não requer treinamento adicional.
Nesse caso, você pode integrar documentos ou bancos de dados relevantes, que o modelo acessa em tempo real para enriquecer as respostas.
No caso de um chatbot de suporte técnico, por exemplo, é possível conectar a base de conhecimento do modelo a um repositório de manuais e FAQs da empresa.
Quando um cliente faz uma pergunta sobre como configurar um dispositivo ou solucionar um problema técnico, o modelo consulta essas informações em tempo real, proporcionando respostas precisas e atualizadas sem a necessidade de treinar o modelo para cada novo produto ou atualização de software.
Para isso, uma técnica amplamente utilizada é o RAG (Retrieval-Augmented Generation), que combina o uso de bases de conhecimento com a geração de texto pelos modelos.
No RAG, os dados são convertidos em vetores utilizando modelos de embeddings, armazenados em bases otimizadas para busca, como o Amazon OpenSearch Service.
Quando uma consulta é realizada, o modelo busca as informações mais relevantes nesses vetores e as utiliza como contexto para gerar uma resposta precisa e fundamentada.
Essa abordagem é ideal para cenários em que o conteúdo precisa ser atualizado frequentemente ou quando há necessidade de responder a perguntas específicas sem modificar o modelo base.
Por exemplo, uma aplicação de suporte técnico pode utilizar o RAG para acessar manuais técnicos ou logs de sistemas, garantindo respostas atualizadas e confiáveis, mesmo em casos onde o modelo original não foi treinado nesses dados.
Em termos de custos, o fine-tuning geralmente requer maior investimento inicial, pois envolve o treinamento adicional do modelo, consumindo recursos computacionais significativos.
Caso seja utilizado com uma throughput provisionada, o modelo ajustado pode oferecer desempenho consistente e baixa latência, ideal para aplicações com alta demanda.
No entanto, a throughput provisionada também gera custos contínuos, já que a capacidade é mantida independentemente do volume real de uso, tornando-a menos eficiente para cenários de demanda esporádica.
Por outro lado, o uso de bases de conhecimento personalizadas é mais econômico, pois dispensa o treinamento do modelo e utiliza os dados já disponíveis para enriquecer as respostas em tempo real.
Dessa forma, a escolha entre essas abordagens deve levar em conta não apenas o orçamento disponível, mas também as necessidades de personalização e a frequência de atualização dos dados.
Como automatizar tarefas complexas com IA?
Aí é que entram em campo os Agents!
Agents podem ser definidos como sistemas concebidos para interpretar comandos em linguagem natural e executar tarefas de modo autônomo, combinando raciocínio lógico com acesso a dados e serviços.
Dessa forma, eles atuam como intermediários entre humanos e sistemas tecnológicos, sendo capazes de dividir um problema complexo em etapas, identificar as ações necessárias e realizar essas ações na ordem correta.
Um caso prático de uso de um agent é no gerenciamento do agendamento de atendimentos em uma clínica.
O agent irá acessar informações sobre horários disponíveis, atualizar calendários e confirmar reservas com usuários, tudo de modo automatizado.
Assim, além de automatizar processos repetitivos, os agents contribuem para reduzir erros manuais e melhorar a eficiência operacional.
No Amazon Bedrock, os agents aproveitam os modelos de IA para automatizar tarefas multi-etapas, integrando sistemas e bases de conhecimento empresariais.
Por exemplo, você pode criar um assistente para gerenciar reservas de um restaurante. Esse agent acessa um banco de dados com os menus do restaurante, executa ações como criar ou consultar reservas por meio de funções Lambda conectadas a um DynamoDB, e até solicita informações ao cliente, como o número de pessoas na mesa ou restrições alimentares.
Tudo isso é feito de maneira segura e sem necessidade de gerenciar infraestrutura, permitindo que as empresas foquem na entrega de soluções práticas e eficientes.
Qual modelo de IA disponível no Amazon Bedrock é mais adequado para tarefas avançadas?
Entre os modelos disponíveis no Amazon Bedrock, os da Anthropic, como o Claude, destacam-se pelo desempenho em tarefas complexas de processamento de linguagem natural (NLP).
Criados para interações mais seguras e úteis, os modelos da Anthropic são ideais para aplicações que demandam respostas detalhadas, conversas interativas e suporte a múltiplos idiomas.
A Anthropic é uma organização de pesquisa em inteligência artificial dedicada a desenvolver modelos avançados que priorizam segurança, confiabilidade e previsibilidade nas respostas.
Fundada por ex-membros do OpenAI, a Anthropic tem como foco criar sistemas que minimizem riscos, evitando gerar respostas inadequadas ou inconsistentes, especialmente em aplicações críticas como saúde, finanças e atendimento ao cliente.
O Claude é conhecido por sua capacidade de entender instruções complexas, sendo altamente personalizável para diferentes casos de uso.
É possível utilizar suas diferentes versões para construir assistentes virtuais, criar resumos de documentos, gerar conteúdo criativo ou realizar análises baseadas em texto.
Além disso, os modelos da Anthropic no Bedrock são projetados com foco em segurança e alinhamento, voltados a compreender e executar instruções com precisão, sendo, portanto, menos propensos a gerar respostas inadequadas ou fora de contexto, mantendo um alto nível de controle sobre o tipo de saída gerada.
Essa abordagem inclui mecanismos que reduzem a probabilidade de respostas fora de contexto ou potencialmente problemáticas, tornando os modelos ideais para cenários onde segurança e precisão são prioridades.
Tal característica torna esses modelos especialmente adequados para aplicações que envolvem dados sensíveis ou que exigem um alto nível de precisão e confiabilidade nas respostas.
O Amazon Bedrock também integra modelos de código aberto, ampliando as possibilidades de aplicação da IA generativa em diversos contextos.
Entre os destaques estão o Stable Diffusion e o Llama, da Meta. Cada um desses modelos traz vantagens específicas que os tornam ideais para diferentes cenários de uso.
O Stable Diffusion é amplamente utilizado na criação de imagens personalizadas, oferecendo ferramentas poderosas para designers, criadores de conteúdo e empresas que precisam de soluções visuais criativas.
Com sua capacidade de gerar imagens de alta qualidade a partir de descrições textuais, ele é uma escolha versátil para áreas como publicidade, design gráfico e produção de conteúdo visual.
Por se tratar de um modelo de código aberto, o Stable Diffusion permite maior personalização e controle, atendendo a demandas específicas de diferentes negócios.
Já o Llama, desenvolvido pela Meta, é um modelo avançado de linguagem natural que combina alto desempenho com eficiência computacional.
Ele foi projetado para atender a uma ampla gama de tarefas, desde geração de texto e tradução até análise de sentimentos e sumarização de documentos.
Seu diferencial está na flexibilidade e na otimização para uso em cenários que exigem recursos mais econômicos, sem comprometer a qualidade das respostas.
Conclusão
O Amazon Bedrock é uma solução com grande potencial para democratizar o uso da inteligência artificial generativa, permitindo que empresas e organizações de diferentes tamanhos e áreas integrem modelos avançados em suas aplicações de forma simples.
Ao oferecer acesso a uma ampla variedade de modelos, como os da Anthropic, Stability AI e Meta, o Bedrock elimina a complexa necessidade de gerenciamento de infraestrutura, viabilizando o foco em inovação e resultados.
Exploramos como o Bedrock facilita o refinamento de modelos por meio de ajustes finos e do uso de bases de conhecimento, permitindo personalizações que atendem a necessidades específicas de negócios.
Essa abordagem, combinada com ferramentas como o playground para testar e otimizar parâmetros, garante eficiência no desenvolvimento de soluções e controle sobre os custos.
Ao unir segurança, flexibilidade e personalização, o Amazon Bedrock permite que negócios inovem com confiança, acompanhando o ritmo das transformações digitais e mantendo-se competitivos em um mercado em constante evolução.