

Na era digital, as empresas enfrentam volumes de dados crescentes provenientes de diversas fontes, como transações de e-commerce, logs de servidores, redes sociais e dispositivos IoT.
Para tomar decisões mais ágeis e precisas, é essencial processar e analisar esses dados em tempo real, integrando-os em um Data Lake centralizado.
Nesse contexto, AWS Kinesis se destaca como uma solução robusta para ingestão de dados em tempo real, permitindo a coleta, o processamento e a análise contínua de dados em movimento.
O que é AWS Kinesis?
AWS Kinesis é uma plataforma de streaming de dados que oferece uma solução escalável e resiliente para ingestão de dados em tempo real.
Com serviços como Kinesis Data Streams, Kinesis Data Firehose e Kinesis Data Analytics, as empresas podem capturar, processar e carregar dados diretamente no Data Lake, garantindo latência mínima e alta disponibilidade.
Essa abordagem permite a análise contínua e em tempo real, melhorando a capacidade de resposta e a tomada de decisão.
A ingestão de dados em tempo real com AWS Kinesis baseia-se em conceitos de processamento de fluxo (stream processing) e arquiteturas orientadas a eventos.

Diferença entre ingestão batch, near real-time e real-time
Antes de falarmos sobre o AWS Kinesis, precisamos entender sobre os principais tipos de ingestão de dados e quando utilizá-los, pois esse é um aspecto crucial na Engenharia de Dados.
Podemos realizar a ingestão de dados de três diferentes maneiras: em lote (batch), quase em tempo real (near real-time) e em tempo real (real-time).
Na ingestão de dados em lote (batch), os dados são coletados e processados em intervalos regulares.
Esse método é útil quando a latência não é um fator crítico e grandes volumes de dados precisam ser processados de uma vez.
Um exemplo de serviço AWS que suporta ingestão de dados em lote é o AWS Glue, que oferece serviços de ETL (extração, transformação e carregamento) para mover dados entre diferentes fontes e destinos em intervalos programados.
A ingestão de dados quase em tempo real (near real-time) reduz a latência, processando dados com uma pequena defasagem de tempo.
Esse método é adequado para aplicações que exigem atualizações frequentes mas podem tolerar pequenos atrasos.
O Amazon Kinesis Data Firehose é um serviço AWS que permite a entrega contínua de dados para destinos como Amazon S3, Redshift e Elasticsearch, com uma latência de minutos.
Por fim, a ingestão de dados em tempo real (real-time) processa os dados à medida que eles são gerados, com latência mínima.
Esse método é essencial para aplicações que necessitam de respostas imediatas a eventos, como detecção de fraudes ou monitoramento de sistemas.
O Amazon Kinesis Data Streams é um serviço AWS que facilita a captura e o processamento de grandes volumes de dados em tempo real, permitindo que as aplicações analisem e respondam instantaneamente às mudanças nos dados.
Arquiteturas Orientadas a Eventos
Arquiteturas orientadas a eventos são um estilo de arquitetura onde sistemas são compostos por produtores e consumidores de eventos.
As principais características dessas arquiteturas incluem o desacoplamento, que permite que produtores e consumidores operem de forma independente, e a reatividade, proporcionando uma resposta em tempo real a eventos.
Além disso, essas arquiteturas facilitam a escalabilidade, distribuindo e escalando componentes de forma eficiente, e oferecem flexibilidade, permitindo a adição de novas funcionalidades sem a necessidade de alterar o sistema existente.
A capacidade de reagir em tempo real a eventos é crucial para aplicações que exigem respostas imediatas, como monitoramento de sistemas e detecção de anomalias.
A flexibilidade dessas arquiteturas também permite integrar novos serviços e adaptar-se rapidamente a mudanças nos requisitos do negócio.
Finalmente, a escalabilidade intrínseca das arquiteturas orientadas a eventos garante que os sistemas possam lidar eficientemente com grandes volumes de dados e tráfego, distribuindo a carga de forma otimizada e evitando gargalos.
Como funciona o AWS Kinesis?
O AWS Kinesis funciona criando streams de dados onde informações são enviadas de diversas fontes, como logs de servidores, dispositivos IoT ou interações de usuários.
Cada stream é dividido em shards, que são unidades paralelas de capacidade que permitem a leitura e gravação simultâneas de dados, assegurando escalabilidade e alta disponibilidade.
Os dados são produzidos por produtores e enviados para os shards do Kinesis Data Streams.
Esses dados são então consumidos por aplicativos que podem ser executados em instâncias do Amazon EC2, AWS Lambda ou serviços como Kinesis Data Analytics.
Esses consumidores podem ler e processar os dados em tempo real, aplicando transformações, análises e outras operações necessárias.
Para entregar os dados processados a destinos finais, o Kinesis Data Firehose é utilizado. Ele entrega os dados a repositórios como Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, entre outros.
O Firehose pode realizar transformações de dados básicas antes da entrega, como conversões de formato e compressão.
Já o Kinesis Data Analytics permite que você analise os dados em tempo real usando SQL, facilitando a detecção de padrões e a geração de insights imediatos.
A integração com outros serviços AWS, como CloudWatch para monitoramento e gerenciamento de logs, e IAM para controle de acesso, assegura uma gestão abrangente e segura dos dados.
Aplicação no Contexto de Data Lake
Podemos usar o processamento de dados em tempo real em um Data Lake capturando, processando e enviando dados continuamente para um armazenamento centralizado.
Essa abordagem permite que um Data Lake faça a ingestão de grandes volumes de dados em tempo real, mantendo-os disponíveis para análises posteriores e integrando-os com outros sistemas de análise e processamento para obter insights valiosos.
Exemplo de Arquitetura near real-time de Data Lake utilizando AWS Kinesis
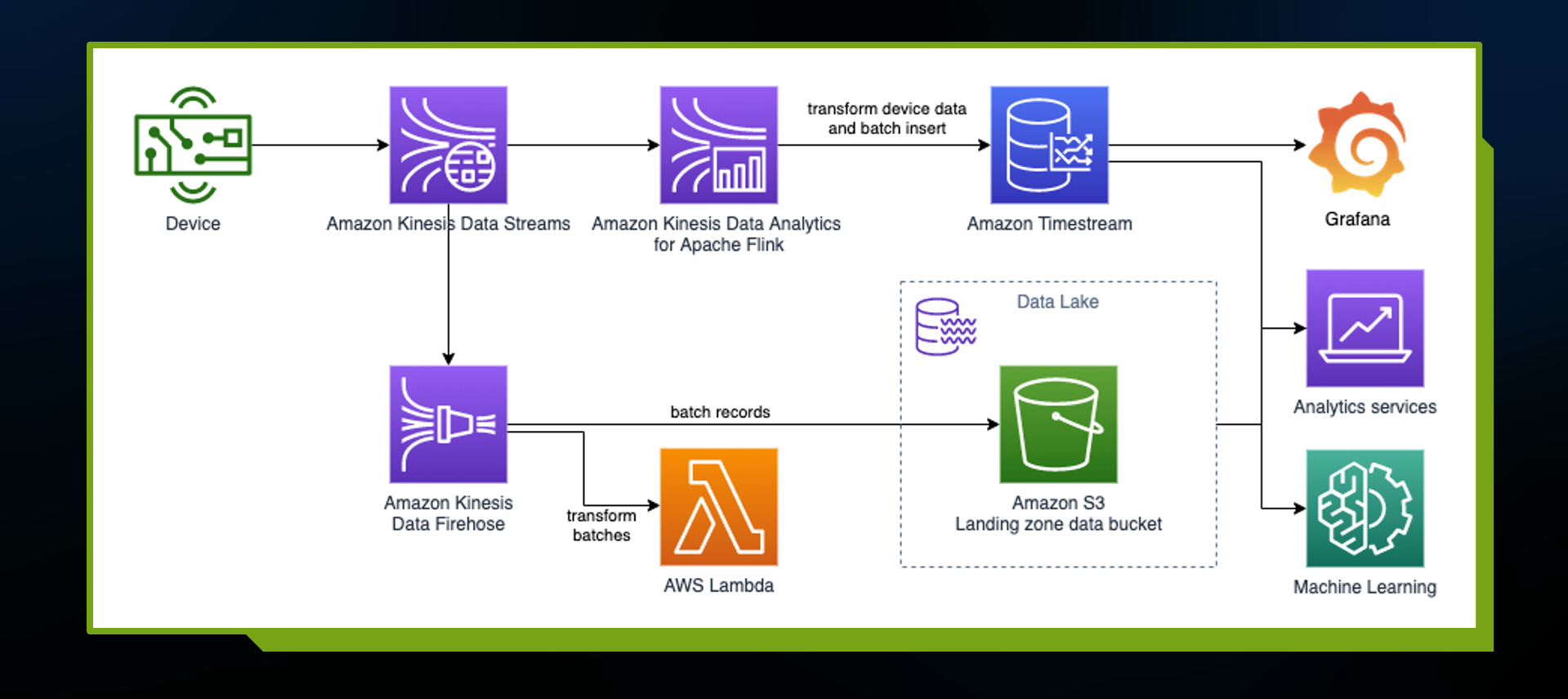
Neste desenho é apresentado um exemplo de arquitetura para ingestão e consumo dos dados brutos utilizando alguns serviços da AWS, mas há diversas formas de combinar os serviços AWS, a depender do objetivo de sua utilização.
Abaixo temos o detalhe de cada um dos componentes:
- Primeiro temos o Device à esquerda representando um dispositivo IoT;
- Depois vem o AWS Kinesis Data Streams para fazer o streaming e captura dos dados;
- Ao lado direito temos o AWS Kinesis Data Analytics for Apache Flink que faz a transformação e agregação dos dados de streaming quase em tempo real;
- Os dados do dispositivo são transformados e armazenados no AWS Timestream que é um banco de dados de séries temporais para ingestão de dados em grandes escaladas;
- Ao lado temos o ícone do Grafana para monitorar métricas, os Analytics services para fazer análises e Machine Learning para fazer modelos;
- Abaixo temos o AWS Kinesis Data Firehose para fornecer dados para outros serviços utilizarem;
- Ao lado temos o AWS Lambda para fazer a transformação dos dados;
- No próximo ícone temos o Data Lake com o AWS S3 Landing zone data bucket, armazenando os dados.
Prós e Contras do AWS Kinesis
Vamos entender as vantagens e desvantagens do AWS Kinesis:
Prós
Essas são as principais vantagens do AWS Kinesis:
- Escalabilidade: Kinesis pode lidar com grandes volumes de dados, escalando automaticamente conforme necessário.
- Baixa Latência: Permite a ingestão e processamento de dados em tempo real com latência mínima.
- Integração: Facilita a integração com outros serviços AWS, como S3, Redshift e Elasticsearch.
- Resiliência: Projetado para alta disponibilidade e durabilidade dos dados.
Contras
E essas são as principais desvantagens:
- Complexidade: A configuração e gerenciamento de shards e streams podem ser complexos.
- Custo: Os custos podem aumentar significativamente com grandes volumes de dados e alta taxa de ingestão.
- Curva de Aprendizado: Requer conhecimento específico e experiência com AWS para configurar e otimizar corretamente.
Conclusão
AWS Kinesis é uma ferramenta poderosa e versátil para a ingestão de dados em tempo real no contexto de Engenharia de Dados.
Sua capacidade de capturar, processar e entregar dados em movimento com baixa latência e alta escalabilidade o torna ideal para integrar dados em um Data Lake.
Apesar da complexidade e dos custos potenciais, seus benefícios em termos de velocidade, integração e análise em tempo real são inegáveis, permitindo que empresas respondam rapidamente a mudanças e obtenham insights valiosos de seus dados.
