Conhecendo os geradores no Python
Onde eu trabalho, temos um programa em cada computador da empresa que registra em um arquivo as datas e os horários em que o computador foi ligado. O arquivo, de nome registros.txt, é organizado dessa forma:
07/04/2018 11:00
07/04/2018 17:05
08/04/2018 13:23
09/04/2018 12:30
...Com o tempo, percebemos que seria mais vantajoso para a empresa, que tem sede em outros países, se mantivéssemos o padrão internacional ANSI na formatação das datas. Decidimos, assim, fazer essa mudança.
Resolvi usar o Python para essa mudança de formatação. Assim, precisamos converter cada entrada do registro de string para o tipo datetime.
Já sabemos como fazer isso para uma string única, utilizando o método strptime() do datetime:
from datetime import datetime
data_hora_em_texto = ‘07/04/2018 11:00’
data_hora = datetime.strptime(data_hora_em_texto, ‘%d/%m/%Y %H:%M’)
print(data_hora)Assim temos o resultado:
2018-04-07 11:00:00Certo, mas e agora que temos linhas e linhas de strings como essa? Conhecemos as compreensões de lista, que poderiam resolver isso facilmente, mas também sabemos que elas não podem evitar os problemas de memória que podem surgir ao se ler um arquivo muito grande de uma vez.
Assim, uma outra ideia poderia ser usar a função map(), outra conhecida nossa. Usando essa função com o lambda, poderíamos fazer algo como o seguinte:
from datetime import datetime
registros = open(‘registros.txt’, ‘r’)
datas_e_horarios = map(lambda data_hora: datetime.strptime(data_hora,
‘%d/%m/%Y %H:%M’), registros)
print(next(datas_e_horarios))E o resultado:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib64/python3.6/_strptime.py", line 565, in _strptime_datetime
tt, fraction = _strptime(data_string, format)
File "/usr/lib64/python3.6/_strptime.py", line 365, in _strptime
data_string[found.end():])
ValueError: unconverted data remains:Opa, uma exceção! O ValueError indica que ainda há conteúdo na string da data que não é coberto pela formatação que passamos. Isso é porque cada linha de nosso arquivo termina com uma quebra de linha, ou seja, com um \n Vamos adicionar esse caractere na formatação:
datas_e_horarios = map(lambda data_hora: datetime.strptime(data_hora,
‘%d/%m/%Y %H:%M\n’), registros)
for data_hora in datas_e_horarios:
print(data_hora)E dessa vez:
2018-04-07 11:00:00
2018-04-07 17:05:00
2018-04-08 13:23:00
2018-04-09 12:30:00
...Agora sim, conseguimos! Mas repare a complexidade dessa única linha que escrevemos.
Já vimos que ambas, a função map() e a expressão lambda, já não são consideradas muito pythônicas. Dessa forma, com uma linha comprida e legibilidade complicada, temos um código que na certa pode ser melhorado. Mas como?
Conhecendo os geradores
Uma abordagem ideal seria juntar os benefícios de memória de um iterador com a praticidade que o Python nos disponibiliza com outras ferramentas.
No Python, temos uma feature especial que facilita (e muito!) a criação de objetos iteradores - os geradores.
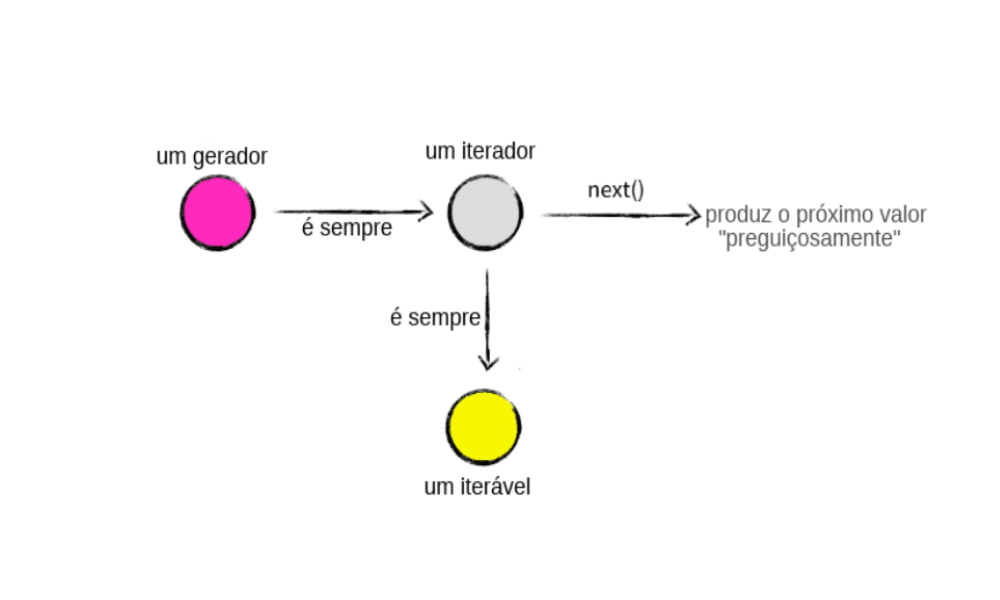
Um gerador é, de fato, um iterador, mas com uma manipulação muito mais facilitada! Ele consegue fazer todo o trabalho que queremos que faça, mas sem precisar de todo o nosso esforço em construir uma classe que implemente __iter__() para ser iterável e enfim __next__() para ser iterador.
Esta imagem complementa a relação apresentada no post sobre iteradores:
Enfim, como criar um gerador?

Funções geradoras e o yield
A maneira tradicional de se criar geradores no Python é através de funções geradoras. Criar uma função geradora é tão simples quanto criar uma função normal:
def cria_gerador():
numero_retorno = 1
yield ‘Retorno número {}’.format(numero_retorno)
numero_retorno += 1
yield ‘Retorno número {}’.format(numero_retorno)
numero_retorno += 1
yield ‘Retorno número {}’.format(numero_retorno)Funções geradoras são como funções comuns no Python, mas que, quando chamadas, retornam um objeto gerador. Em vez da palavra chave return, funções geradoras usam o yield, que indica o retorno do next() do gerador criado.
Assim, a palavra chave yield pode ser usada múltiplas vezes em uma função geradora, para cada vez que o next() for chamado:
gerador = cria_gerador()
print(next(gerador))
print(next(gerador))
print(next(gerador)) E o resultado:
Retorno número 1
Retorno número 2
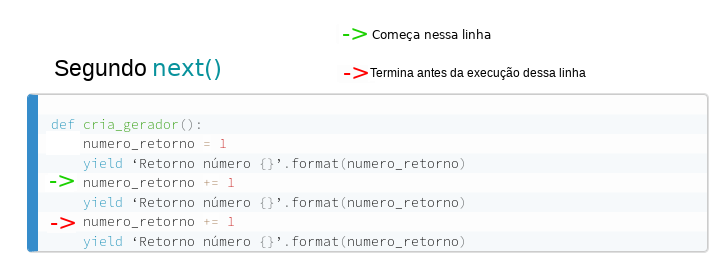
Retorno número 3Certo! O que acontece é que a função next() vai rodar todo o código da função geradora até encontrar um yield. Quando encontra um yield, ela retorna o valor passado para ele e pausa a execução da função.
Mas espera… como assim pausa a execução da função?!
Diferentemente das funções normais, as variáveis locais da função (no caso desse exemplo, a variável numero_retorno) não são apagadas, mas mantidas para a próxima chamada do next(), que continuará a rodar a função no mesmo lugar que tinha parado, para novamente pausar quando atingir o próximo yield.


Vimos que, com funções geradoras, temos um yield para cada retorno. Para nosso caso, precisamos de um retorno para cada data no arquivo, então será que vamos precisar escrever tantos yield assim?
Podemos tratar o retorno dentro de um loop que rodará sobre o arquivo, nos devolvendo a conversão de cada linha para datetime, uma por vez:
from datetime import datetime
def cria_gerador_datas(registros):
for data_hora_texto in registros:
data = datetime.strptime(data_hora_texto, ‘%d/%m/%Y %H:%M\n’)
yield data
registros = open(‘registros.txt’, ‘r’)
gerador_datas = cria_gerador_datas(registros)
print(gerador_datas)O que acontece se tentarmos imprimir esse gerador que criamos?
<generator object <genexpr> at 0x7f0b41a76b40>Tudo bem, recebemos a identificação do gerador na memória. Isso é porque um gerador, por ser um iterador, não sabe quais elementos fazem parte dele, isto é, quais valores ele vai gerar, afinal ele computa apenas um valor de cada vez.
Podemos ir passando por cada elemento gerado, através da função next(), ou iterando sobre o gerador com um laço:
for data in gerador_datas:
print(data)Como resultado:
2018-04-07 11:00:00
2018-04-07 17:05:00
2018-04-08 13:23:00
2018-04-09 12:30:00
...Legal! Conseguimos solucionar nosso problema de forma elegante usando geradores. Mas ainda não conseguimos atingir o nível de simplicidade, similar ao que vemos em compreensões de lista… Será que não tem jeito, mesmo?
Substituindo compreensões de lista por expressões geradoras
Uma outra maneira mais enxuta de se criar geradores é através de expressões geradoras. A sintaxe de uma expressão geradora é similar à de uma compreensão de lista. A única diferença fica no uso de parênteses no lugar de colchetes:
from datetime import datetime
registros = open(‘registros.txt’, ‘r’)
gerador_datas = (datetime.strptime(data, ‘%d/%m/%Y %H:%M\n') for data in registros)
for data in gerador_datas:
print(data)E o resultado:
2018-04-07 11:00:00
2018-04-07 17:05:00
2018-04-08 13:23:00
2018-04-09 12:30:00
...Exatamente o mesmo que com a função geradora, mas com uma simplicidade ao nível das compreensões de lista! Um código de fato pythônico.
Expressões geradoras vs Compreensões de lista
Agora que conhecemos as expressões geradoras e vimos como elas são similares às compreensões de lista, como sabemos quando usar cada uma?
Ok, já vimos que se precisarmos poupar memória as expressões geradoras são preferíveis. Mas, ué, não é sempre bom otimizar nosso código? Então por que não usar elas sempre, em vez das compreensões de lista?
O uso das listas traz algumas vantagens necessárias em algumas ocasiões, como por exemplo caso precisemos iterar mais de uma vez sobre seus elementos.
Um gerador produz um valor e depois se desfaz dele, então se precisássemos dele de novo, precisaríamos computá-lo mais uma vez, praticamente tirando seu propósito de preservar memória.
Já uma lista, como guarda todos os elementos juntos de uma vez, não precisa avaliá-los de novo, eles continuarão dentro dela.
Às vezes as listas também são preferíveis por nos disponibilizarem pegar um elemento pelo índice, ou até mesmo sub-listas que cortam a lista principal, dentre outros métodos exclusivos de uma lista.
Um ponto a favor dos geradores muito interessante, entretanto, é a possibilidade de infinitude. Listas são sempre finitas - sempre, pois todos os seus valores são calculados de uma vez.
Se tentássemos criar uma lista infinita, teríamos, naturalmente, um problema de memória. Como o gerador produz um valor por vez, podemos ter um gerador com a capacidade de produzir para sempre.
Para uma simples iteração, não vai haver muita diferença entre um e outro, então escolha o que preferir e, caso encontre algum problema (seja de memória, seja de falta de métodos para solucionar algo), considere trocar para o outro!
Conclusão
Nesse post, aprendemos uma forma muito mais simples de criar nossos próprios iteradores, através de geradores.
Aprendemos, então, a criar nossos geradores tanto com funções geradoras, quanto com expressões geradoras, atingindo uma praticidade desejável!
Além do mais, vimos como os geradores podem ser ótimas alternativas para algumas práticas (como criar iteradores na mão, ou o uso do map()).
Gostou do conteúdo? Geradores são uma técnica para se levar para a vida de um programador Python! Me diga o que achou nos comentários!