


Introdução
Por conta da velocidade e volume de dados que são produzidos todos os dias à nossa volta, seja em redes sociais, no mundo financeiro ou nos serviços de streaming, surge a demanda de uma área que seja capaz de lidar com esse cenário, que é também conhecido como Big Data.
Nesse momento, passamos a ter a necessidade da Engenharia de Dados como área responsável por cuidar desse fluxo de dados.

O que é Big Data?
O termo Big Data, em português “grande volume de dados”, começou a aparecer quando os métodos tradicionais para armazenamento começaram a não ser tão eficientes nesse novo ambiente que exigia muito mais do que uma ferramenta de armazenamento conseguia suportar.
De forma geral, o Big Data pode ser definido com 3 V’s principais:
- Volume;
- Variedade;
- Velocidade.
1) Volume
Grande quantidade de dados para ser armazenada e processada, com escalas que vão desde terabytes até mesmo zettabytes.
2) Variedade
A variedade de dados é um outro pilar do Big Data, pois, dentro do grande volume de dados, temos diferentes tipos — desde dados estruturados, semi-estruturados a não estruturados.
3) Velocidade
Essa grande quantidade de dados costuma ser gerada num curto espaço de tempo. Um bom exemplo são as redes sociais, onde temos milhares de mensagens e registros em bancos para serem atualizados.
Se você se interessou pelo mundo de Big Data, você pode conhecer mais no artigo Big Data: Entenda mais sobre esse conceito, aqui na Alura.
Sugerimos também o vídeo Big Data com Apache Spark: a história do Big Data, onde o Bruno Raphaell conta um pouco mais sobre o surgimento do Big Data e o desenvolvimento de algumas ferramentas utilizadas na área.

E, para tratar dessa demanda de Big Data, surge a chamada Engenharia de Dados.
O que é Engenharia de Dados?

A história da Engenharia de Dados começou com artigos da Google. O primeiro, publicado em 2003, abordava o Google File System, um sistema de arquivos distribuídos. Logo em seguida, em 2004, foi publicado outro artigo sobre MapReduce, uma técnica de processamento de grandes volumes de dados.
Esses artigos inspiraram engenheiros do Yahoo a criarem, em 2006, o Hadoop, que mostrou-se uma ferramenta muito útil para trabalhar com grandes volumes de dados. A partir disso, surgiu a era da Engenharia de Dados com Big Data.
O desafio de transformar essa grande quantidade e variedade de dados em informações úteis e de qualidade é essencial para o time de dados. Mas, para isso, precisamos criar um ambiente propício para gerar tais informações.
A Engenharia de Dados é a área responsável por desenvolver, implementar e manter esse ambiente, que chamamos de Pipeline. É nele que vamos criar todas as etapas relacionadas ao fluxo de dados, desde a extração, passando pelo armazenamento, até a distribuição dos dados para consumo.
Para saber mais sobre Engenharia de Dados, recomendamos o vídeo abaixo:
O que é engenharia de dados? com David Neves | #HipstersPontoTube - YouTube

Pipeline
O que é Pipeline?
Por conta do alto volume e variedade de dados, precisamos tomar um cuidado maior antes de consumi-los. Para o processamento de dados, passamos a ter um processo, composto de várias etapas, chamado de Pipeline.
Esse processo, ou Pipeline, seria um meio de mover os dados da origem para o destino, por exemplo: extrair dados de várias interfaces diferentes (também API’s) para um Data Warehouse, que é um local onde diversos tipos de bancos de dados são postos de forma consolidada.
Basicamente, as etapas que constituem o processo envolvem:
- Agregação;
- Organização; e
- Movimentação de dados.
Quais elementos compõem um Pipeline?
O Pipeline é composto por três elementos fundamentais:
- Uma ou várias fontes;
- Etapas de processamento; e
- Destino.
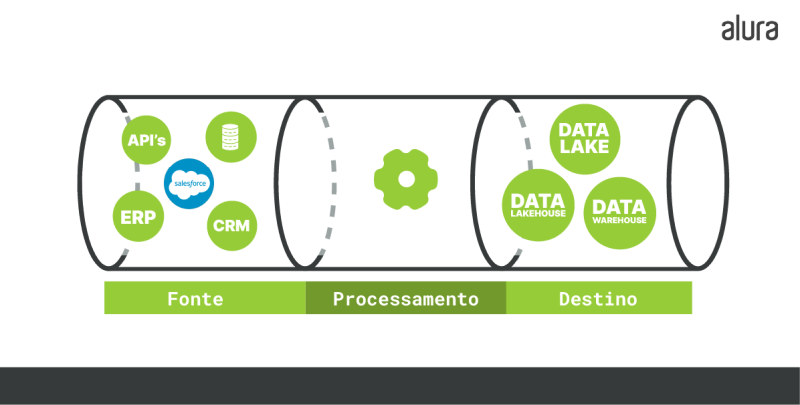
1) Fontes
De onde os dados vêm, podendo vir de mais de uma fonte. São consideradas fontes comuns:
- Sistemas Gerenciadores de Bancos de Dados (SGBDs), como o MySQL;
- Sistemas de Gestão de Relacionamento com o Cliente (CRMs), como Salesforce;
- Sistema Integrado de Gestão Empresarial (ERPs), como a Oracle; e
- Dispositivos de Internet das Coisas (IoT) — até mesmo eles.
2) Etapas de processamento
Após a coleta dos dados recebidos de uma determinada fonte, estes dados passam por algumas etapas de processamento, como:
- Transformação;
- Filtragem;
- Agrupamento; e
- Agregação.
3) Destino
Para onde os dados irão ao fim da etapa de processamento, como um Data Lake ou um Data Warehouse. Caso tenha curiosidade e queira saber mais, você pode entender melhor sobre Data Lakes, no Alura+ O que são Data Lakes?, onde a Millena Gená e o João Miranda explicam o que são esses tipos de destino.

Recomendamos também o episódio sobre Data Lakes, do nosso podcast Hipster.tech para entender mais da prática e conhecer o caso de uso do Banco PAN:

O que faz uma pessoa Engenheira de Dados?
A pessoa engenheira de dados pode assumir diversas responsabilidades dependendo do contexto em que a empresa atua. Por ser uma nova área e estar em constante evolução, temos algumas possibilidades para a pessoa responsável pela Engenharia de Dados.
Geralmente, a pessoa engenheira dados é quem assume o papel de ser a responsável por integrar, consolidar, limpar e estruturar os dados para uso em futuras análises.
As suas principais atuações dentro de uma organização são:
- Tornar os dados facilmente acessíveis para outros profissionais de dados;
- Trazer melhorias para todo o ecossistema de Big Data;
- Cuidar do Pipeline, montar e manter o ciclo de vida dos dados, que é o principal motivador para as futuras tomadas de decisões;
- Incentivar a cultura de dados dentro da empresa (cultura Data Driven). Caso você queira saber mais sobre Data Driven, recomendamos o seguinte vídeo:
Ciclo de vida, profissionais de Dados e Data Driven Decision | Universo Data Science #02

No fim das contas, a pessoa engenheira de dados está buscando sempre facilitar a busca, a utilização e/ou o consumo dos dados, além de melhorar sua qualidade.
Aqui na Alura também temos o artigo da Maria Gabriela, falando sobre O que faz uma pessoa Engenheira de Dados?
Engenharia e Linhagem de Dados
Conversamos com o time da Alvin sobre os desafios de time de dados em suas rotinas de trabalho, principalmente em relação a linhagem de dados (ou Data Lineage), que é toda a jornada que os dados fazem entre múltiplas ferramentas.

Qual a importância da Engenharia de Dados?
Um bom exemplo do impacto da Engenharia de Dados é nos ramos de administração e marketing de uma empresa. Principalmente em empresas que contém uma pluralidade de perfil de clientes, entender como o comportamento do consumidor pode trazer grandes benefícios para o futuro da empresa é um passo importante.
Por isso, empresas de streaming de mídia como a Netflix, por exemplo, investem constantemente em engenheiros para construir pipelines eficientes e disponibilizar dados com maior qualidade para as demais áreas de dados.
Hoje, para existir como negócio, é preciso ter um ritmo acelerado para acompanhar as mudanças do mundo atual, do surgimento de novas tecnologias e ferramentas à forma como as pessoas interagem com elas, então, se faz importante acompanhar estas mudanças.
Como um exemplo, podemos citar o caso da Serasa Experian, no nosso podcast do Hipsters.tech, onde as pessoas responsáveis pela área de engenharia de dados comentam um pouco sobre:
- O processo para realizar extração de dados da Web;
- Os desafios ao lidar com sites não padronizados;
- Além das tecnologias utilizadas.
Engenharia de dados na Serasa Experian – Hipsters On The Road #37
Habilidades da pessoa Engenheira de Dados
As habilidades de uma pessoa Engenheira de Dados estão diretamente envolvidas com as suas responsabilidades. Como as áreas de dados precisam conversar entre si, é importante saber qual a melhor forma de fornecer os dados para as demais áreas, e, para isso, necessitamos desenvolver soft skills, as habilidades pessoais ou comportamentais.
Além disso, é essencial para este profissional ter conhecimentos de ferramentas fundamentais, para trabalhar melhorando: custo, agilidade, escalabilidade, simplicidade e reuso.
Soft Skills (Habilidades comportamentais)
Em toda empresa, ter funcionários que sabem trabalhar bem em equipe e transmitir as informações para as outras equipes é mais que essencial, e na Engenharia de Dados não seria diferente. São necessárias algumas soft skills como:
- Comunicação;
- Storytelling;
- Colaboração;
- Adaptabilidade.
1) Comunicação
Ter uma comunicação assertiva e não violenta pode definir o sucesso do projeto e evitar conflitos futuros, por isso é sempre importante manter o alinhamento entre os times.
2) Storytelling
Transmitir o conteúdo de maneira que facilite o entendimento de forma envolvente, contar uma história de um case ou exemplo e apresentar dados. Essa habilidade irá ajudar você a compartilhar melhor as suas ideias.
3) Colaboração
Ter proatividade e se mostrar uma pessoa disposta a ajudar contribui para um bom ambiente de trabalho.
4) Adaptabilidade
Ser flexível para novas ideias e ferramentas pode ser interessante, pensando em um ambiente que está em constante evolução.
Aqui na Alura, nós temos o artigo Soft Skills mais importantes para a Área de Dados, que detalha um pouco mais sobre essa e outras habilidades comportamentais.
Hard Skills (Habilidades técnicas)
Em quesitos técnicos, uma pessoa Engenheira de Dados precisa criar boas pipelines, arquitetar sistemas distribuídos, saber combinar fontes de dados e criar arquitetura de soluções. E para isso, utilizar diversas ferramentas, como:
- Hadoop;
- Apache Spark;
- Apache Airflow;
- Python;
- Scala e Java;
- SQL;
- NoSQL;
- Git;
- Cloud Computing (AWS, Azure e Google Cloud).
1) Hadoop
É uma estrutura que permite o processamento distribuído de grandes conjuntos de dados em clusters de computadores usando modelos de programação simples.
2) Apache Spark
Um framework para computação distribuída, que é utilizado para executar projetos de Engenharia de Dados, Data Science e Machine Learning em apenas um computador ou em um cluster.
3) Apache Airflow
Ferramenta usada para controle de fluxo de trabalho, essencial para construção de pipelines de dados, através de instruções de sequenciamento definidas com bloco de tarefas chamado DAGs.
- Para aprender como utilizar essa ferramenta, em um processo de ETL, recomendamos a Formação de Airflow.
4) Python
Muitas bibliotecas e APIs que são utilizadas na Engenharia de Dados são feitas em Python. E por esse motivo o Python pode ser considerado uma ponte entre Engenharia de Dados e Ciência de Dados.

5) Scala e Java
Conhecer mais de uma linguagem de programação orientada a objetos também é importante. O Apache Spark, por exemplo, foi feito em Scala e executa virtualmente uma máquina virtual Java.

6) SQL
SQL (Structured Query Language - linguagem de consulta estruturada) é uma das ferramentas mais utilizadas para fazer consultas em banco de dados relacionais de diversos tamanhos e até mesmo em Data Warehouses.
- Caso queira aprender mais sobre SQL, o artigo SQL: Comandos básicos pode te ajudar a dar seus primeiros passos.
7) NoSQL
Utilizamos o NoSQL para lidar com dados não estruturados ou semiestruturados. A maneira que será manipulado o banco de dados NoSQL dependerá do tipo de banco e cada um desses bancos possui sua própria estrutura ou linguagem de consulta. Um dos bancos orientado a documentos mais utilizado no mercado é o MongoDB.
- Na Formação MongoDB, você irá aprender a trabalhar com esse banco de dados.

8) Git
É um sistema de controle de versão distribuído distribuído e amplamente adotado. É utilizado para manter o histórico dos arquivos e códigos, dando a possibilidade de recuperação de estados anteriores.

Git e GitHub para sobrevivência:

9) Cloud Computing (AWS, Azure e Google Cloud)
Esta habilidade envolve trabalhar com várias plataformas para deploy de software e também manutenção de armazenamento em nuvem, algo essencial nos dias atuais.

Como começar em Engenharia de dados
A princípio, uma pessoa engenheira de dados precisa entender 3 pilares, podemos iniciar conhecendo um pouco de cada um deles:
- Programação;
- Banco de dados;
- Devops.
Acesse nosso artigo Por onde começar os estudos na área de dados e descubra o Plano de estudos preparado para você.
1) Programação
Além da lógica de programação, ter o conhecimento em Python é um excelente passo para explorar mais seus estudos, tendo em vista que ela é uma das principais linguagens utilizadas dentro das ferramentas da pessoa Engenheira de dados.
Entretanto, quando buscamos algo mais avançado, Java é uma linguagem que tende a ser utilizada para ganho de performance, principalmente para o uso de ferramentas como Apache Spark.
Como desenvolver boas práticas de programação? com Fabio Akita | #HipstersPontoTube

2) Banco de dados
As consultas e requisições em grandes bancos de dados são atividades recorrentes, por se tratar de uma área que lida com uma grande variedade de dados, podendo ser tanto estruturados quanto não estruturados.
Para lidar com estes tipos de dados, o conhecimento na linguagem SQL e saber trabalhar com estruturas NoSQL compõem as habilidades necessárias para o dia a dia de uma pessoa Engenheira de Dados.
3) Devops
Devido ao uso de ferramentas Cloud Computing e da necessidade de entender de versionamento de código. Esse pilar — o DevOps — também é uma área bastante importante, então, buscar conhecimentos em Git, em plataformas como AWS, Google Cloud e Azure, suprem essa necessidade.
O que você precisa saber para começar em DevOps com Leonardo Sartorello | #HipstersPontoTube

Ciência de Dados vs Engenharia de Dados
Quando falamos destas duas áreas, entendemos como duas coisas separadas, diferentes, mas na verdade elas são complementares. A Engenharia de Dados fornece os inputs, ou seja, as entradas de dados utilizados pela Ciência de Dados que, por sua vez, transforma estes dados em informações úteis.
Para termos uma noção do escopo geral da área de dados, a autora e Cientista de Dados Monica Rogati nos propôs um Diagrama da Hierarquia de Necessidades da Ciência de Dados, que podemos ver a seguir:
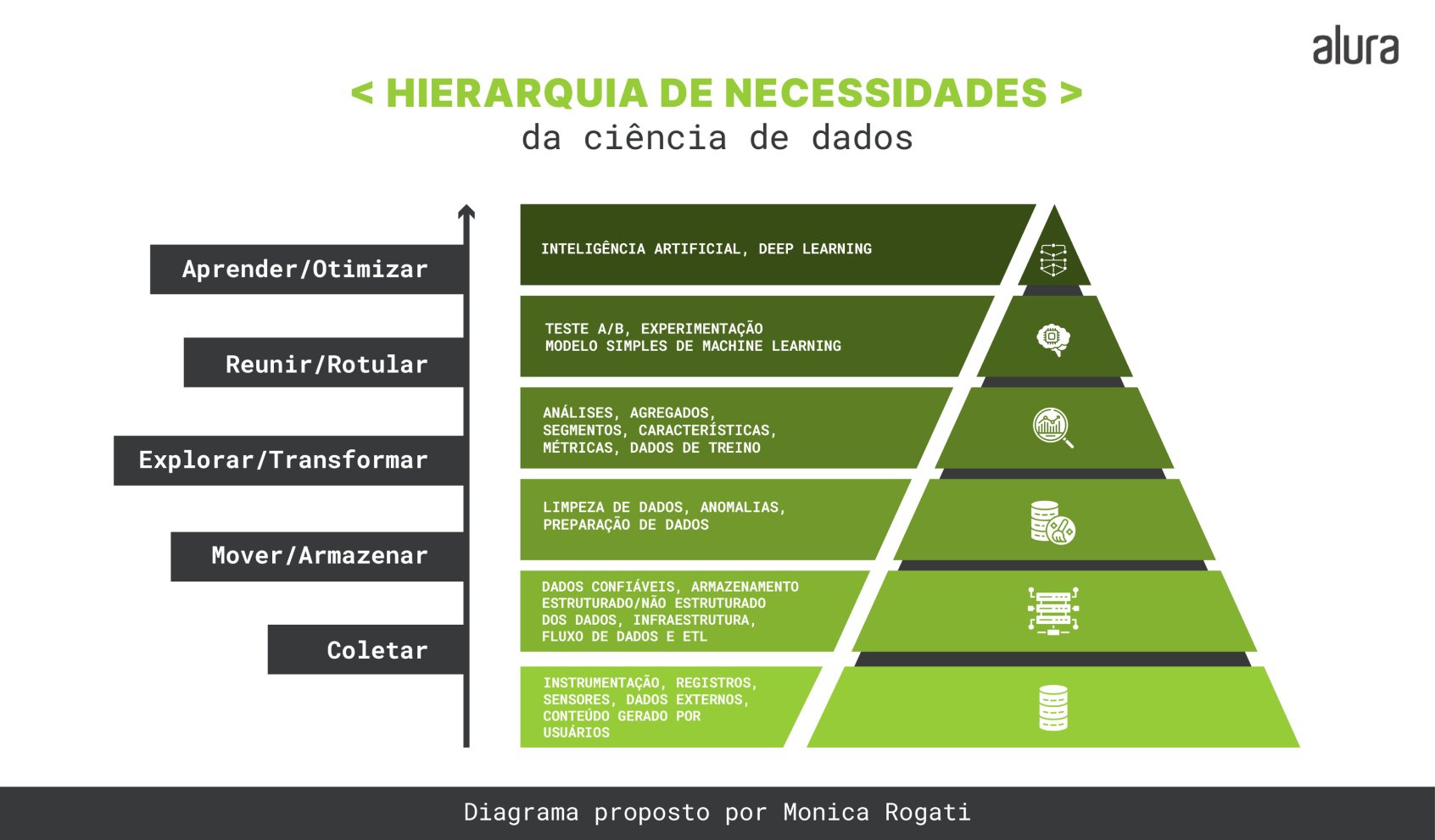
O dia a dia da pessoa Engenheira e Cientista de Dados
No dia a dia da pessoa Cientista de Dados, cerca de 70% a 80% do seu tempo está destinado às camadas da base da pirâmide — coleta de dados, limpeza de dados, processamento de dados — e apenas uma pequena parte do seu tempo é para análise e construção de modelos de Machine Learning.
Se quiser saber mais sobre o que faz uma pessoa que trabalha com ciência de dados, recomendamos o vídeo abaixo:
O que faz uma Cientista de Dados? com Mikaeri Ohana | #HipstersPontoTube - YouTube

Na Engenharia de Dados, temos a responsabilidade de preparar os dados, desde a coleta até a organização, desenvolvendo e cuidando das arquiteturas necessárias para que se possa processar os dados coletados com uma boa qualidade.
São as pessoas engenheiras de dados que cuidam dos enormes armazenamentos dos dados e fornecem o acesso a eles, para que a pessoa Cientista de Dados, que utiliza conhecimentos de matemática, estatística e ciência da computação, utilize seu tempo para focar nas camadas de cima da pirâmide, ou seja, para criar modelos de Machine Learning e auxiliar em tomadas de decisões, para responder às necessidades de negócio.

Aprenda mais sobre Engenharia de Dados gratuitamente
Acesse gratuitamente as primeiras aulas da Formação Iniciando com Engenharia de Dados, feita pela Escola de Data Science da Alura e continue aprendendo sobre temas como:
- Linux Onboarding: usando a CLI de uma forma rápida e prática
- Linux Onboarding: localizando arquivos e conteúdos
- Python: começando com a linguagem
- Python: avançando na linguagem
- Apache Airflow: orquestrando seu primeiro pipeline de dados
- Apache Beam: Data Pipeline com Python
- PostgreSQL
- PostgreSQL: Views, Sub-Consultas e Funções
- Engenharia de Dados: organizando dados na AWS

Conclusão
Como vimos, a Engenharia de Dados pode ser muito extensa, com diversas responsabilidades e habilidades necessárias. Mas, como pudemos aprender neste artigo, esta área é de grande importância e sempre busca facilitar o dia a dia da equipe de dados, focando na acessibilidade e qualidade dos dados presentes nos Data Lakes e Data Warehouses.
Se você deseja mergulhar na área de Engenharia de Dados, recomendamos a formação Iniciando com Engenharia de Dados, onde você irá construir sua base em Python, continuar seus estudos sobre Big Data e a trabalhar com dados na nuvem.
Seção de Referências
- Diagrama de Hierarquia de Necessidades de Ciência de Dados apresentado por Mônica Rogati;
- Fundamentals of Data Engineering;
- Formação de Engenharia de Dados;
- O que faz uma pessoa Engenheira de Dados?;
Créditos
Escrita:
Produção técnica:
Produção didática:
Designer gráfico:


