Estruturas de dados: uma introdução


Introdução
As estruturas de dados, junto com o estudo de algoritmos, fazem parte dos fundamentos da programação e muito se lê/ouve sobre a importância do estudo destes temas. Neste artigo, vamos abordar as estruturas de dados do início: o que são, alguns exemplos e por que são importantes.

O que são dados?
Os dados (e seus diversos tipos) são os blocos básicos da programação. Eles representam uma unidade ou um elemento de informação que pode ser acessado através de um identificador - por exemplo, uma variável.
A maior parte das linguagens de programação trabalha com variações baseadas nos quatro tipos primitivos abaixo:
- INT ou número inteiro: valores numéricos inteiros (positivos ou negativos);
- FLOAT ou o chamado “ponto flutuante”: valores numéricos com casas após a vírgula (positivos ou negativos);
- BOOLEAN ou booleanos: representado apenas por dois valores, “verdadeiro” e “falso”. Também chamados de operadores lógicos;
- TEXT: sequências ou cadeias de caracteres, utilizados para manipular textos e/ou outros tipos de dados não numéricos ou booleanos, como hashes de criptografia.
O JavaScript, por exemplo, tem como tipos primitivos embutidos na estrutura básica da linguagem: number, string, boolean e symbol (de “nome simbólico”, usado entre outras coisas para criar propriedades únicas em objetos). Já o C# (C-Sharp) trabalha com uma quantidade maior de tipos primitivos, de acordo com o espaço de memória que será ocupado pela variável: Boolean, Byte, SByte, Int16, UInt16, Int32, UInt32, Int64, UInt64, IntPtr, UIntPtr, Char, Double e Single. O C, por sua vez, não tem um tipo próprio de dado booleano; false é representado pelo número 0 e qualquer outro algarismo representa true. Outras linguagens podem trabalhar com outras variações.
O que são estruturas de dados?
Em computação, normalmente utilizamos os dados de forma conjunta. A forma como estes dados serão agregados e organizados depende muito de como serão utilizados e processados, levando-se em consideração, por exemplo, a eficiência para buscas, o volume dos dados trabalhados, a complexidade da implementação e a forma como os dados se relacionam. Estas diversas formas de organização são as chamadas estruturas de dados.
Podemos afirmar que um programa é composto de algoritmos e estruturas de dados, que juntos fazem com que o programa funcione como deve.
Cada estrutura de dados tem um conjunto de métodos próprios para realizar operações como:
- Inserir ou excluir elementos;
- Buscar e localizar elementos;
- Ordenar (classificar) elementos de acordo com alguma ordem especificada.
Características das estruturas de dados
As estruturas de dados podem ser:
- lineares (ex. arrays) ou não lineares (ex. grafos);
- homogêneas (todos os dados que compõe a estrutura são do mesmo tipo) ou heterogêneas (podem conter dados de vários tipos);
- estáticas (têm tamanho/capacidade de memória fixa) ou dinâmicas (podem expandir).
Veremos a seguir uma lista e descrição de algumas estruturas.
Array
Também chamado de vetor, matriz ou arranjo, o array é a mais comum das estruturas de dados e normalmente é a primeira que estudamos.
Um array é uma lista ordenada de valores:
const listaNumeros = [4, 6, 2, 77, 1, 0];
const listaFrutas = ["banana", "maçã", "pera"];Por ordenada, entenda-se aqui uma lista onde os valores sempre são acessados na mesma ordem. Ou seja, a não ser que seja utilizada alguma função ou método para alterar a ordem, o primeiro elemento do array listaNumeros sempre será 4, e o último, 0.
Normalmente trabalha-se com apenas um tipo de dado por array; embora o JavaScript permita a declaração de arrays de mais de um tipo de dado, por exemplo ["banana", 5, true], isso não acontece na maior parte das linguagens de programação.
Por ser uma estrutura de dados básica e muitíssimo utilizada, a linguagens de programação costumam já ter este tipo implementado, com métodos nativos para criação e manipulação de arrays. No caso do JavaScript, você pode consultar os métodos e construtores de array no MDN.
Usos
Sendo a mais comum das estruturas, arrays são utilizados em praticamente toda situação que envolva organizar dados de um mesmo tipo; sejam dados recebidos por uma API ou enviados a uma base de dados, ou mesmo passado via parâmetro para uma função ou método. Os arrays também podem ser multidimensionais, sendo utilizados sempre que há necessidade de tabular dados e os arrays de 2 dimensões (matrizes) são utilizados para processamento de imagens.
Pilha
Em um array, é possível utilizar funções próprias para manipular elementos em qualquer posição da lista. Porém, há situações (veremos exemplos mais adiante) onde é desejável mais controle sobre as operações que podem ser feitas na estrutura. Aí entra a implementação de estruturas de dados como a pilha (stack) e a fila (queue).
A pilha é uma estrutura de dados que, assim como o array, é similar a uma lista. O paradigma principal por trás da pilha é o LIFO - Last In, First Out, ou “o último a entrar é o primeiro a sair”, em tradução livre.
Para entendermos melhor o que significa isso, pense em uma pilha de livros ou de pratos. Ao empilharmos livros, por exemplo, o primeiro livro a ser retirado da pilha é obrigatoriamente o último que foi colocado; se tentarmos retirar o último livro da pilha, tudo vai desabar. Ou seja, o último livro a ser empilhado é o primeiro a ser retirado.
Abstraindo este princípio para código, percebe-se que há apenas dois métodos possíveis para manipular os dados de uma pilha: 1) inserir um elemento no topo da pilha e 2) remover um elemento do topo da pilha.
Ao contrário do array, as linguagens de programação normalmente não têm métodos nativos para criação e manipulação de pilhas. Porém, é possível usar métodos de array para a implementação de pilhas.
Usos
O caso de uso mais famoso da pilha é a call stack ou pilha de chamadas de um programa que está sendo executado: a ordem de execução dos processos “chamados” por um programa via funções ou métodos obedece o princípio de pilha.
Outro recurso que utilizamos todos os dias e que utiliza pilhas para funcionar é o mecanismo de “voltar” e “avançar” páginas dos navegadores (representado normalmente por setas para a esquerda e direita). Os endereços visitados vão se empilhando; ao chamarmos a função de “voltar”, o último endereço visitado - ou seja, o que está no topo da pilha - é o primeiro a ser visualizado.
Fila
A fila tem uma estrutura semelhante à pilha, porém com uma diferença conceitual importante: o paradigma por trás da fila é o FIFO - First In, First Out, ou “o primeiro a entrar é o primeiro a sair”, em tradução livre.
Pense em uma fila de bilheteria, por exemplo. A pessoa que chegou antes vai ser atendida (e comprar seu ingresso) antes de quem chegou depois e ficou atrás na fila. A fila como estrutura de dados segue o mesmo princípio.
Sendo assim, também há somente duas formas de se manipular uma fila: 1) Inserir um elemento no final da fila e 2) remover um elemento do início da fila.
Deque
A estrutura de dados deque (abreviação de double-ended queue ou “fila de duas pontas”) é uma variação da fila que aceita inserção e remoção de elementos tanto do início quanto do final da fila.
Podemos comparar, novamente, com uma fila de pessoas em um guichê de atendimento: uma pessoa idosa que chega é atendida antes (ou seja, não pode ser colocada no fim da fila), ao mesmo tempo que uma pessoa que entrou no final da fila pode desistir de esperar e ir embora (nesse caso, não podemos esperar a pessoa chegar na frente da fila para retirá-la de lá).
Uma outra forma de se entender a estrutura deque é como uma junção das estruturas de pilha e fila.
Fila circular
Outra variação da fila é a fila circular (circular queue), onde o último elemento é conectado com o primeiro elemento - como em um círculo:
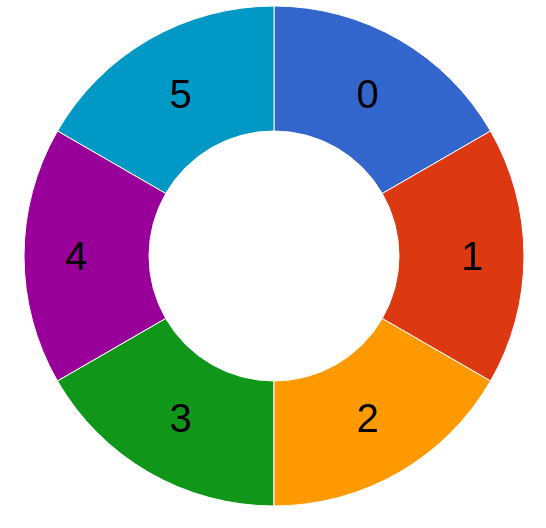
A fila circular busca resolver uma limitação da fila linear, que é lidar com espaços vazios que podem se enfileirar após a retirada de elementos do início da fila.
Usos
Um uso fácil de lembrar para a fila é justamente a fila de impressão dos sistemas operacionais: o último trabalho de impressão a ser adicionado à fila será o último a ser impresso.
Além disso, as requisições feitas a um servidor também são organizadas em fila para serem respondidas, e quando alternamos entre programas utilizando o atalho alt+tab, o sistema operacional faz o gerenciamento da ordem utilizando o princípio de lista circular.
Lista ligada
Já vimos que a maioria das linguagens de programação têm métodos nativos para a manipulação de arrays, como por exemplo inserir e remover elementos. Além disso, estes métodos fazem uma boa parte do trabalho de ordenar e buscar elementos por nós.
Porém, há três coisas importantes para sabermos sobre arrays: 1) na maior parte das linguagens de programação, os arrays têm tamanho fixo; 2) todos os elementos ocupam espaços sequenciais na memória e 3) inserir ou remover elementos do meio do array não é muito simples, pois exige que esses elementos sejam deslocados. Por exemplo:
// 0 1 2 3
[46, 34, 76, 12]
// removendo 76, o elemento 12 passa a ocupar o índice 2
// 0 1 2
[46, 34, 12]// 0 1 2 3
[46, 34, 76, 12]
// inserindo 25, o elemento 12 passa a ocupar o índice 4
// 0 1 2 3 4
[46, 34, 76, 25, 12]Este trabalho de deslocamento de elementos é feito internamente pelos métodos nativos de array que as linguagens já têm e que utilizamos no dia-a-dia, por isso normalmente não nos preocupamos com isso. Mas ele está na implementação do método feita no código-fonte da linguagem.
Assim como arrays, as listas ligadas também armazenam elementos sequencialmente, porém, ao invés de armazenar os elementos de forma contígua na memória, como nos arrays, as listas ligadas não dependem desse tipo de organização. Elas utilizam ponteiros para unir os elementos, e cada elemento “aponta” para o endereço de memória do próximo da lista, sem que ele precise estar no bloco de memória seguinte.
Dessa forma, ao trabalhar com listas ligadas também não é necessário fazer o deslocamento de elementos ao incluir ou excluir - considerando que, cada vez que esse deslocamento é feito em um array, é necessário reposicionar os elementos em novos espaços de memória. Cada “nó” da lista aponta para o ponteiro de memória onde se encontra o próximo elemento, independente de onde esteja este espaço de memória.

Usos
Lembrando que a lista ligada encadeia elementos apontando para a localização do próximo item na memória, os programas de “álbum de fotos” (visualização de imagens) utilizam a lista ligada para encadear os arquivos de imagens e “chamar” a próxima imagem/voltar para a imagem anterior via setas do teclado ou botões de “anterior” e “próxima”. O mesmo princípio se aplica para playlists de música ou vídeo.
Conjunto
A estrutura de dados conjunto (ou set) é uma lista não ordenada de elementos únicos. Ou seja, não é possível repetir o valor de um elemento dentro de um conjunto.
Por exemplo, é perfeitamente possível criar um array com os seguintes elementos:
const lista = [1, 1, 1, 3, 5, 7, 9];Porém, em um conjunto, não é possível repetir valores, não importa a ordem dos elementos. A maior parte das linguagens de programação mais usadas têm métodos nativos para criação de conjuntos. No caso do JavaScript:
const lista = [1, 1, 1, 3, 5, 7, 9];
const conjunto = new Set(lista);
console.log(conjunto);
// Set(5) { 1, 3, 5, 7, 9 }Usos
Como você pode ter imaginado, a estrutura do conjunto vem da matemática, e também é possível fazer operações como união e intersecção em conjuntos de dados. Um dos usos mais comuns desta estrutura é em bancos de dados SQL.
Dicionário ou hashmap
Dicionário (também conhecido como mapa, map ou hashmap) é uma estrutura que guarda dados em pares de chave e valor e utiliza estas chaves para encontrar os elementos associados a elas, diferentemente das estruturas que vimos até agora, que trabalham com listas (sequenciais ou não) apenas de valores.
Essa descrição parece muito uma outra estrutura que já conhecemos, o objeto. Mas há várias diferenças entre dicionários/mapas e objetos. Por exemplo, é possível mapear o tamanho de um dicionário (ou seja, a quantidade de pares chave/valor) e os dicionários podem aceitar qualquer tipo de dado como chave (objetos aceitam apenas strings ou symbols). Os dicionários também podem ter performance melhor em buscas e manipulação de dados do que objetos, pois utilizam referências para as chaves - de uma forma similar a ponteiros, as chaves apontam para o endereço de memória de seus valores.
Um aspecto importante sobre dicionários vs objetos: a decisão sobre qual utilizar vai depender muito da linguagem. Cada linguagem implementa seus próprios métodos para criação de instâncias de objetos ou dicionários e para a manipulação dos dados. Por exemplo, dicionários em Python não eram ordenados por padrão até a versão 3.6, já o objeto
Map()em JavaScript é ordenado por padrão; outras linguagens podem ter suporte a dicionários, porém não a objetos.
Usos
O formato chave:valor do dicionário é o mais comum para lidar com dados armazenados em bancos de dados, mas não apenas para isso: o formato é usado sempre que há a necessidade de associar dados e referências para consulta posterior, sejam informações da base de dados de um produto ou mesmo a relação entre o nome de um arquivo e o seu caminho interno na memória do computador, feita pelo sistema operacional.
Árvore
A árvore é uma estrutura não-sequencial, muito útil para armazenar dados de forma hierárquica e que podem ser acessados de forma rápida.
Pode-se definir árvore como uma coleção de dados representados por nós e arranjados em níveis hierárquicos (ao invés de sequências como as estruturas vistas anteriormente).
Um exemplo de estrutura em árvore são os organogramas de empresas:
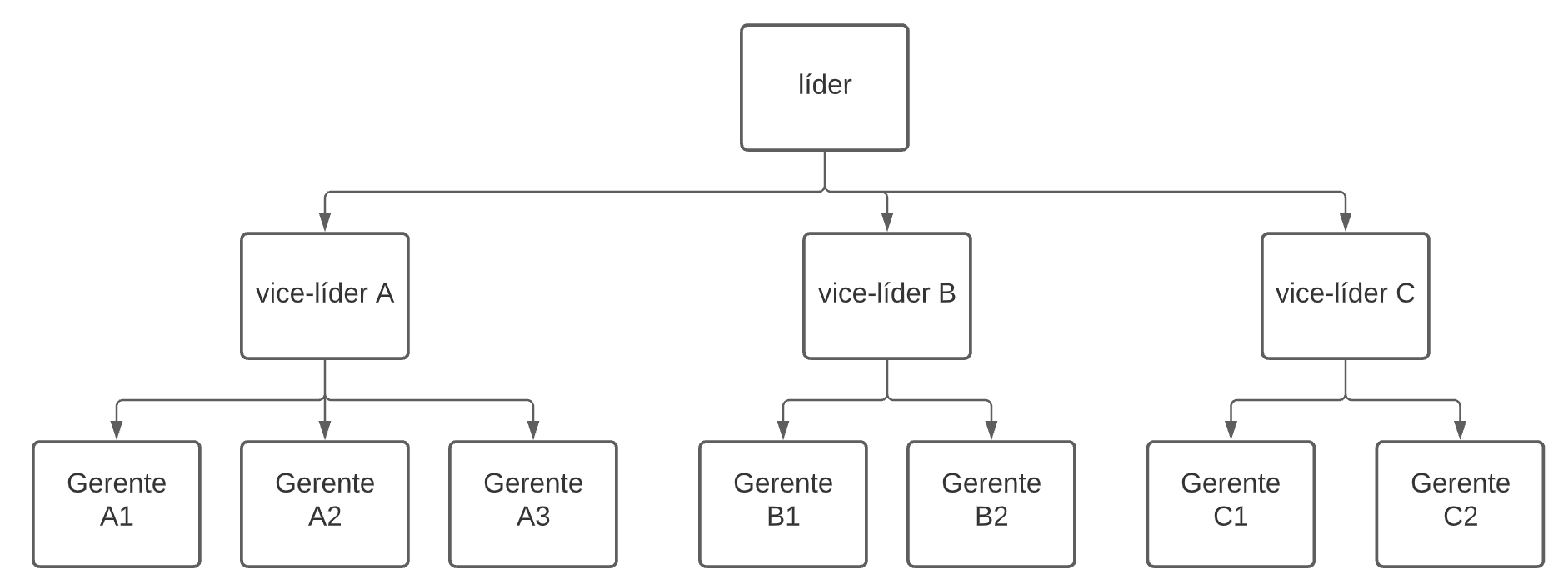
A estrutura mais comum é a árvore binária, que tem no máximo dois nós-filhos a partir do nó inicial (chamado de raiz ou root). Um nó pode ter pais, irmãos e filhos; nós que têm pelo menos um filho são chamados de nós internos, e nós sem filhos são chamados de externos ou folhas:
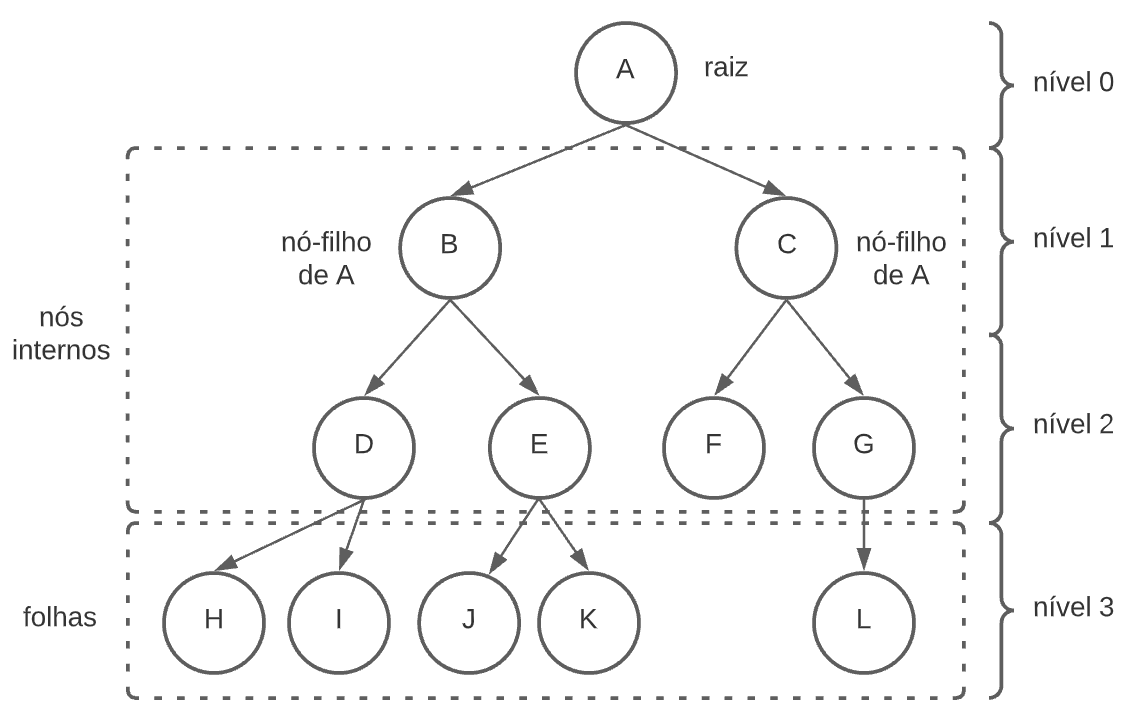
A partir da estrutura de árvore binária (com um nó-filho à esquerda e um à direita da raiz) é possível estruturar a chamada BST, ou árvore de busca binária (binary search tree), que utiliza o princípio do algoritmo de busca binária para estruturar os dados de forma que valores menores estejam à esquerda da raiz e valores maiores à direita. Essa união do algoritmo com a estrutura de dados leva a uma maior eficiência na manipulação de dados, seja para buscar, alterar, incluir ou remover elementos.
Heap binário
O heap binário é um tipo especial de árvore binária, normalmente utilizada em computação para implementar filas de prioridade, pois em um heap pode-se extrair de forma mais eficiente o valor mínimo ou máximo de uma lista. Pode-se traduzir heap, muito livremente, como um “monte” ou “porção” de dados.
O heap binário se difere da árvore binária em duas características principais:
- Todos os níveis, com exceção do último, têm filhos tanto na esquerda quanto na direita da raiz. No último nível, os filhos se posicionam o mais à esquerda possível. É o que chamamos de árvore completa.
- pode ser um heap mínimo (min heap), para extrair o menor valor da árvore, ou heap máximo (max heap) para se extrair o maior valor. Todos os nós devem ser ou
>=(no caso do heap máximo) ou<=(no caso do heap mínimo) do que os valores dos nós-filhos.
Usos
A estrutura de árvore tem vários usos diversos, como algoritmos de tomada de decisão em aprendizado de máquina, indexação de bancos de dados, indexação e exibição de arquivos e pastas no explorador de arquivos dos sistemas operacionais, entre vários outros casos.
O heap binário, como já mencionamos, é usado em filas de prioridade (tipo especial de fila onde os elementos são retirados da fila não no padrão FIFO, mas sim organizados por prioridade: mais prioritários no início da fila e menos prioritários no final) e também em um algoritmo de ordenação específico, o heap sort.
Grafo
Outra estrutura não-sequencial, o grafo (graph) é um conjunto de nós (ou vértices), ordenados ou não e ligados por arestas, formando uma estrutura em forma de rede.

O grafo acima pode ser representado da seguinte forma: V = {1, 2, 3, 4, 5, 6} (os vértices ou nós) e E = {(1,2), (2,3), (3,4), (3,6), (4,2), (4,5), (5,1), (5,2), (5,6)} (as arestas ou edges).
Cada um dos vértices do grafo podem representar um tipo de dado ou sua referência. As arestas podem ser não-direcionadas - como no caso acima, onde as arestas não têm uma direção definida - ou direcionadas, como no caso abaixo:
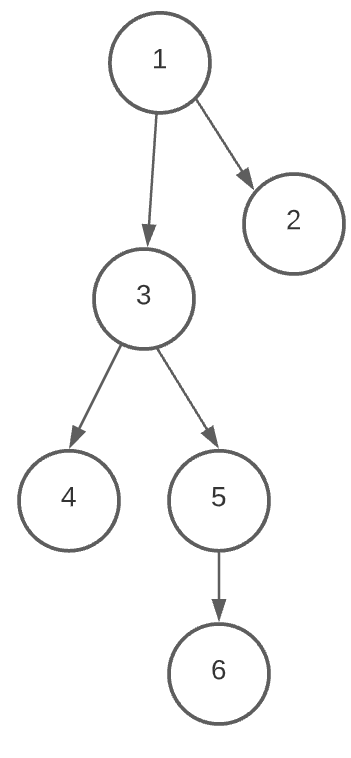
As arestas de um grafo também podem ter um valor (também chamado de peso), que representam custo computacional, capacidade, etc para cada “caminho”.
Usos
As redes sociais utilizam os grafos para manejar a grande quantidade de dados relacionados entre si que recebem a cada instante. O exemplo mais famoso, a linguagem de consulta GraphQL, foi criada pelo Facebook com o intuito de utilizar grafos para acessar e relacionar dados.
Outro uso famoso para os grafos é o sistema de navegação dos aplicativos de mapas/GPS, que utilizam grafos e o algoritmo de caminho mínimo (ou shortest path) para traçar rotas.
Conclusão
Como você pode ter notado, apenas uma de cada estrutura resumida poderia tomar horas e horas de estudo para entendimento completo do paradigma por trás de cada uma e para implementação de cada classe e método necessário. Várias estruturas já têm métodos e bibliotecas próprios implementados nas diversas linguagens de programação mais utilizadas, mas é sempre interessante entender o que acontece “por baixo dos panos”.
O estudo de estruturas de dados, junto com o de algoritmos, é parte essencial dos fundamentos da programação. É interessante combinar o estudo destes temas com a prática “mão na massa” em projetos, para aos poucos agregarmos cada vez mais conhecimento prático e teórico.
Você pode começar aos poucos, estudando a fundo cada uma das estruturas e pesquisando as possíveis implementações na sua linguagem de preferência.
Bons estudos!