


Guia Completo da Linguagem R para iniciantes


Em um mundo cada vez mais orientado por dados, a capacidade de analisar, interpretar e extrair informações valiosas tornou-se uma habilidade essencial.
A linguagem R, com sua ampla gama de ferramentas e recursos, se destaca como uma das principais aliadas para profissionais e entusiastas que desejam mergulhar no universo da análise de dados, estatística e ciência de dados.
Este artigo abrangente servirá como seu guia completo para a linguagem R, desde seus fundamentos até aplicações avançadas.
Exploraremos o que é R, suas diversas aplicações em áreas como data science, machine learning e estatística computacional, além de suas características únicas e vantagens.
Você aprenderá como instalar e começar a programar em R, desde os primeiros passos até a criação de visualizações de dados sofisticadas.
Abordaremos tópicos cruciais como manipulação de dados, estruturas de controle, funções e pacotes essenciais.
Ao final, você estará equipado com o conhecimento necessário para embarcar em sua jornada com a linguagem R e desvendar o poder dos dados.
O que é linguagem R?
R nasceu nos anos 90, na Nova Zelândia, criado por dois caras geniais, Ross Ihaka e Robert Gentleman.
Eles queriam uma linguagem que fosse uma alternativa mais moderna ao S, uma linguagem de programação estatística que já existia. E assim, R veio ao mundo!
Hoje, a linguagem é mantida por um time chamado R Core Group e tem uma comunidade gigantesca de usuários e desenvolvedores ao redor do globo.
A linguagem é voltada, principalmente, para análise estatística, manipulação de dados e visualização gráfica.
Ela se destaca por sua capacidade de lidar com grandes volumes de dados de forma eficiente e por oferecer ferramentas poderosas para construir modelos preditivos e explorar informações de maneira visual.

Para quê serve a linguagem R?
R é uma linguagem extremamente versátil, e que pode ser usada em diferentes áreas. Vamos analisar algumas delas:
Análise Estatística: R é o sonho de qualquer estatístico! Se você precisa fazer análise estatística pesada, como testes de hipóteses, análises de regressão, ou qualquer outra coisa que envolva números e fórmulas complicadas, R é a ferramenta perfeita. Ele tem um monte de funções built-in que facilitam a vida e uma comunidade que não para de criar pacotes novos para deixar tudo ainda mais simples.
Manipulação de Dados: Quando os dados chegam daquele jeitão bagunçado, R entra em cena pra organizar tudo. Com pacotes como dplyr e tidyr, você pode filtrar, agrupar, juntar e transformar dados de um jeito rápido e eficiente. E o melhor: o código fica bonito e fácil de entender, até pra quem não é muito chegado em programação.
Visualização de Dados: Se você precisa criar gráficos bonitos e informativos, R é a escolha certa. O pacote ggplot2 é uma das ferramentas mais poderosas para visualização de dados. Com ele, dá pra fazer gráficos de dispersão, barras, linhas e muito mais, tudo com uma estética de dar inveja. E o legal é que você pode personalizar tudo, do jeito que quiser!
Aprendizado de Máquina: Quer entrar no mundo do machine learning? R também te ajuda nisso! Com pacotes como caret e randomForest, você pode treinar modelos preditivos, validar suas previsões e otimizar seus algoritmos. É como ter uma caixa de ferramentas completa para construir modelos inteligentes e úteis.
Bioinformática: R também é muito usado na área de bioinformática, ajudando a analisar dados genômicos, proteômicos e de outras áreas da biologia. Se você trabalha com dados biológicos, R tem uma vasta gama de pacotes especializados, como Bioconductor, que tornam a análise desses dados muito mais eficiente.
Econometria: Pra galera da economia, R é um grande aliado. Ele facilita a análise de séries temporais, modelos econométricos e outras análises econômicas. Pacotes como quantmod e tseries são essenciais para quem precisa entender tendências econômicas e fazer previsões baseadas em dados históricos.
Aplicações Acadêmicas: Na academia, R é uma ferramenta indispensável. Pesquisadores e estudantes usam R para conduzir análises complexas, testar hipóteses e criar modelos estatísticos robustos. A capacidade de R de gerar visualizações detalhadas e personalizáveis torna-o ideal para a publicação de estudos e artigos científicos. Além disso, a extensa documentação e a comunidade ativa garantem que novos usuários possam aprender rapidamente e aplicar R em suas pesquisas.
Com todas essas aplicações, R se consolida como uma ferramenta indispensável para cientistas de dados, pesquisadores e analistas em diversas áreas, oferecendo precisão, eficiência e visualizações impactantes para uma ampla gama de necessidades analíticas.
Para conhecermos ainda mais a linguagem e suas aplicações, temos essa entrevista com a Regina Bernal, estatística e professora da FIAP, que abordam a linguagem e suas possibilidades:
Aplicações da linguagem R
Como você viu, a linguagem R tem muitas aplicações. Conheça as principais:
Data Science
R é uma das linguagens favoritas dos cientistas de dados por uma série de razões. Vamos explorar essas razões e como você pode utilizá-lo em suas próprias análises.
Por que R é Popular em Data Science?
Foco em Estatística: R foi desenvolvido por estatísticos para estatísticos, o que significa que é otimizado para análise de dados e estatística. Ele possui uma vasta gama de pacotes que facilitam a realização de análises complexas e detalhadas.
Visualização Poderosa: Com pacotes como ggplot2, R permite criar visualizações de dados sofisticadas e customizáveis. Isso é crucial em Data Science, onde comunicar insights visualmente pode fazer toda a diferença.
Grande Comunidade e Suporte: A comunidade R é uma das mais ativas no campo de Data Science. Isso significa que você terá acesso a uma grande quantidade de recursos, tutoriais e pacotes desenvolvidos por outros cientistas de dados.
Reprodutibilidade: Ferramentas como R Markdown permitem criar relatórios reprodutíveis que combinam código, visualizações e texto explicativo, facilitando a documentação e a partilha de análises.
Principais Tarefas em Data Science com R
- Coleta de Dados: R facilita a coleta de dados de diversas fontes, incluindo APIs, bancos de dados SQL, arquivos CSV, Excel, e até mesmo a web scraping.
# Leitura de um arquivo CSV
dados_csv <- read.csv("caminho/para/seu/arquivo.csv")
# Visualizar os primeiros registros
head(dados_csv)
- Limpeza e Preparação de Dados: Pacotes como dplyr e tidyr são essenciais para transformar dados crus em um formato limpo e utilizável.
library(dplyr)
library(tidyr)
dados <- dados %>%
filter(!is.na(coluna_interessante)) %>%
mutate(nova_coluna = coluna_existente * 2) %>%
spread(key = tipo, value = valor)
- Análise Exploratória de Dados (AED): Usar R para AED é simples e eficiente, permitindo a identificação de padrões, anomalias e hipóteses preliminares.
summary(dados)
ggplot(dados, aes(x = variavel1, y = variavel2)) + geom_point()
- Modelagem e Machine Learning: R possui uma ampla gama de pacotes para machine learning, incluindo caret para treinamento de modelos e xgboost para algoritmos de gradiente boosting.
library(caret)
set.seed(123)
modelo <- train(Target ~ ., data = dados_treino, method = "rf")
previsoes <- predict(modelo, newdata = dados_teste)
- Avaliação de Modelos: Avaliar o desempenho dos modelos é crucial, e R fornece ferramentas robustas para isso.
confusionMatrix(previsoes, dados_teste$Target)
- Visualização de Resultados: Criar gráficos e dashboards interativos para visualizar resultados e insights.
library(shiny)
ui <- fluidPage(
titlePanel("Dashboard Interativo"),
sidebarLayout(
sidebarPanel(
sliderInput("slider", "Selecione um valor:", min = 1, max = 100, value = 50)
),
mainPanel(
plotOutput("plot")
)
)
)
server <- function(input, output) {
output$plot <- renderPlot({
ggplot(dados, aes(x = variavel1, y = variavel2)) +
geom_point() +
xlim(0, input$slider)
})
}
shinyApp(ui = ui, server = server)
Pacotes Essenciais para Data Science com R
Existem diversos pacotes essenciais para trabalhar com R, especialmente nas áreas de análise de dados, visualização, manipulação de dados, estatísticas e machine learning.
Vamos conhecer alguns dos mais importantes.
dplyr: Funções verbosas para manipulação de dados (filtrar, selecionar, agrupar, etc.).

tidyverse: Conjunto de pacotes que inclui dplyr, tidyr, ggplot2, e outros, ideal para manipulação e visualização de dados.

caret: Simplifica o processo de treinamento e avaliação de modelos de machine learning.
data.table: Alternativa mais rápida para manipulação de grandes conjuntos de dados.

shiny: Permite criar aplicativos web interativos para visualização e análise de dados.

andomForest: Implementação do algoritmo de floresta aleatória para tarefas de classificação e regressão.

xgboost: Implementação de gradiente boosting eficiente para modelagem preditiva.

ggplot2: Sistema poderoso para criar gráficos e visualizações baseados na gramática dos gráficos.

plotly: Gráficos interativos baseados no ggplot2.

Estes pacotes essenciais cobrem uma ampla gama de funcionalidades necessárias para análise de dados, visualização, modelagem estatística, machine learning, e muito mais.
Familiarizar-se com esses pacotes e suas capacidades permite que você realize tarefas complexas de maneira eficiente.
Casos de Uso Comuns de R em Data Science
A linguagem é amplamente utilizada em Data Science devido à sua versatilidade, capacidade estatística e vasta gama de pacotes especializados.
Alguns casos de uso são:
Análise de Sentimentos: Utilizando pacotes como tm e syuzhet para processar e analisar textos, extraindo sentimentos e tópicos.
Previsão de Séries Temporais: Usando forecast e prophet para modelar e prever dados de séries temporais, como vendas ou dados de tráfego.
Análise de Redes Sociais: Coletando e analisando dados de redes sociais com pacotes como rtweet e igraph, permitindo a visualização de redes de conexões e influências.
Pesquisa Clínica: Analisando dados de estudos clínicos com pacotes como survival para análises de sobrevivência e lme4 para modelos de efeitos mistos.
Com todas essas capacidades, R se estabelece como uma ferramenta indispensável no arsenal de qualquer cientista de dados.
Ele não apenas facilita a análise e modelagem de dados, mas também torna a visualização e a comunicação dos resultados algo prático e eficaz.
Machine Learning
Machine Learning (ML) envolve a construção de algoritmos que permitem aos computadores aprenderem a partir de dados e fazer previsões ou tomar decisões sem serem explicitamente programados para isso.
R é uma ferramenta excelente para ML devido à sua vasta gama de pacotes e bibliotecas que facilitam a implementação de diversos algoritmos de aprendizado.
Preparação de dados
Antes de começar a construir modelos de machine learning, é essencial preparar seus dados adequadamente. Isso inclui a limpeza, transformação, normalização e divisão dos dados em conjuntos de treino e teste.
Carregar pacotes necessários
Carregar os pacotes necessários é o primeiro passo antes de realizar qualquer tarefa de machine learning em R.
Pacotes como dplyr para manipulação de dados, caret para modelagem e avaliação, e ggplot2 para visualização são frequentemente usados.
Carregar esses pacotes no início do seu script garante que todas as ferramentas necessárias estejam disponíveis para o trabalho subsequente.
Carregar dados
Carregar dados é uma etapa fundamental que envolve a importação de dados de várias fontes, como arquivos CSV, bancos de dados, APIs ou outras formas de armazenamento de dados.
Os dados podem ser carregados para dentro do R usando funções de leitura específicas, como read.csv() para arquivos CSV ou readxl para arquivos Excel.
Garantir que os dados sejam carregados corretamente e estejam no formato adequado é essencial para a análise subsequente.
Limpeza e transformação dos dados
A limpeza e a transformação dos dados são processos críticos que garantem que os dados sejam precisos, completos e adequados para análise.
Isso inclui a remoção de valores ausentes, correção de inconsistências, tratamento de outliers e transformação de variáveis.
A criação de novas variáveis derivadas, a conversão de tipos de dados e a aplicação de operações matemáticas também fazem parte dessa etapa.
Dados limpos e transformados corretamente são fundamentais para a construção de modelos precisos e robustos.
Divisão em conjuntos de treino e teste
A divisão dos dados em conjuntos de treino e teste é uma prática padrão em machine learning para avaliar a performance do modelo.
O conjunto de treino é usado para ajustar o modelo, enquanto o conjunto de teste é usado para avaliar a capacidade do modelo de generalizar para novos dados.
Tipicamente, uma divisão comum é 70-80% dos dados para treino e 30-20% para teste. Essa separação permite uma validação mais objetiva da eficácia do modelo, reduzindo o risco de overfitting e garantindo que o modelo tenha uma boa performance em dados não vistos.
Para entender melhor ainda o conceito e suas aplicações temos esse vídeo do Paulo Silveira e do Guilherme Silveira explicando o que é Machine Learning.
Algoritmos de Machine Learning em R
Regressão Linear: A regressão linear é um dos algoritmos de machine learning mais básicos e amplamente utilizados. É um método estatístico que modela a relação entre uma variável dependente (variável resposta) e uma ou mais variáveis independentes (variáveis preditoras) através de uma linha reta.
Essa técnica pode ser expandida para incluir múltiplas variáveis independentes (regressão linear múltipla) e pode ser combinada com outras técnicas para resolver problemas mais complexos.
Árvores de Decisão: Árvores de decisão são um método popular de machine learning para tarefas de classificação e regressão. Elas funcionam dividindo o conjunto de dados em subconjuntos mais homogêneos com base nos valores das variáveis preditoras.
É uma técnica poderosa e interpretável para classificação e regressão. Em R, o pacote rpart facilita a construção e visualização de árvores de decisão.
A capacidade de visualizar as regras de decisão torna este método especialmente útil para explorar e entender os dados.
Random Forest: Random Forest é um algoritmo de ensemble muito popular que combina várias árvores de decisão para melhorar a precisão e reduzir o overfitting.
Cada árvore no "random forest" é construída a partir de uma amostra diferente do conjunto de dados e, durante a construção, a escolha das variáveis de divisão é feita de forma aleatória.
Ela funciona criando um grande número de árvores de decisão independentes e combinando suas previsões.
Cada árvore é treinada usando uma amostra aleatória dos dados (bootstrap sample) e, em cada nó, uma amostra aleatória de variáveis é considerada para divisão.
A previsão final é feita através da média (para regressão) ou voto majoritário (para classificação) das previsões de todas as árvores.
O pacote randomForest facilita a construção, avaliação e interpretação de modelos de Random Forest.
Gradient Boosting (XGBoost): é uma técnica avançada de machine learning que utiliza o método de boosting para criar um modelo preditivo robusto e eficiente.
Esse pacote funciona construindo uma sequência de árvores de decisão, onde cada árvore tenta corrigir os erros das árvores anteriores, aprimorando gradualmente a precisão do modelo.
XGBoost é particularmente conhecido por sua performance e capacidade de lidar com grandes conjuntos de dados e variáveis complexas.
Em R, o pacote xgboost facilita a implementação dessa técnica, oferecendo funções para ajuste, avaliação e interpretação de modelos de gradient boosting, tornando-se uma escolha popular em competições de machine learning e aplicações industriais.
Support Vector Machines (SVM): O objetivo do SVM é encontrar o hiperplano ótimo que maximiza a margem entre as classes.
Esse hiperplano é definido por vetores de suporte, que são os pontos de dados mais próximos do hiperplano. O SVM pode ser usado para problemas lineares e não lineares, utilizando diferentes kernels (funções de transformação).
O pacote e1071 facilita a construção e avaliação de modelos de SVM com diferentes kernels. A escolha do kernel pode influenciar significativamente a performance do modelo, especialmente em problemas não lineares.
Avaliação de Modelos
Para avaliar a performance dos modelos, usamos métricas apropriadas como acurácia, precisão, recall e a matriz de confusão.
Essas métricas ajudam a quantificar a eficácia do modelo, permitindo identificar áreas onde ele pode estar falhando e ajustá-lo para melhorar suas previsões.
Validação Cruzada
A validação cruzada é uma técnica essencial para avaliar a robustez do modelo e evitar overfitting. Ela divide os dados em múltiplos subconjuntos, treinando e testando o modelo várias vezes para garantir que ele generalize bem para novos dados, proporcionando uma avaliação mais precisa de sua performance.
Automatização de Pipelines de Machine Learning
O pacote caret facilita a criação de pipelines automatizados para pré-processamento, treinamento e avaliação de modelos.
Com caret, é possível integrar diferentes etapas do fluxo de trabalho de machine learning, garantindo eficiência e consistência ao longo do processo de desenvolvimento do modelo.
Implementação de Modelos em Produção
Para implementar modelos de machine learning em produção, R oferece pacotes como plumber para criar APIs que servem modelos preditivos.
Essas APIs permitem que os modelos sejam integrados a aplicações web ou serviços, facilitando o acesso e a utilização dos modelos preditivos em tempo real.
R é uma ferramenta poderosa para machine learning, oferecendo uma vasta gama de pacotes e funcionalidades que cobrem todas as etapas do pipeline de machine learning, desde a preparação dos dados até a avaliação e implementação dos modelos.
Com suas capacidades de visualização avançada e a facilidade de integração com outras linguagens e ferramentas, R se torna uma escolha excelente para cientistas de dados que buscam construir e implementar modelos preditivos robustos e eficientes.
Caso você queira se aprofundar em Machine Learning temos a Formação de Machine Learning aqui na Alura
Estatística Computacional

A estatística computacional é basicamente a área que mistura estatística e computação para resolver problemas complexos que, na base da caneta e papel, dariam um trabalho gigantesco.
Com a ajuda do R, conseguimos fazer análises estatísticas rapidamente e com um monte de dados de uma vez só.
Monte Carlo Simulations: O Poder dos Computadores
Uma das técnicas mais interessantes que usamos na estatística computacional são as simulações de Monte Carlo.
É como quando você joga muitos dados várias vezes para ver todas as possibilidades e entender a melhor estratégia.
É possível simular milhões de vezes e entender padrões que seriam impossíveis de ver manualmente. É um método poderoso para resolver problemas que envolvem muitas variáveis aleatórias.
Bootstrap: Pegando leve com as amostras
O Bootstrap é outra técnica muito importante que usamos. Imagine que você quer entender uma característica de uma população, mas só tem uma amostra.
Com o Bootstrap, você pega essa amostra e cria várias "amostras falsas" (resampling) para calcular estimativas como média e desvio padrão com mais precisão.
Estatística Descritiva
Estatística descritiva em R é fundamental para a exploração e compreensão inicial de qualquer conjunto de dados.
Utilizando R, podemos calcular medidas de tendência central como média, mediana e moda, além de medidas de dispersão como desvio padrão, variância e intervalo interquartil.
Funções como summary(), mean(), sd(), quantile() e hist() facilitam a obtenção desses insights rapidamente. Visualizações, como histogramas e boxplots, criadas com ggplot2, permitem observar a distribuição dos dados e identificar possíveis outliers.
Em conjunto, essas ferramentas ajudam a sumarizar e interpretar dados de forma clara e concisa, fornecendo uma base sólida para análises mais avançadas.
Por que usar a linguagem R?
Usar a linguagem R tem várias vantagens, especialmente para aqueles que trabalham com estatística, análise de dados e ciência de dados.
Aqui estão algumas razões principais para considerar o uso do R:
Foco em Análise Estatística
R foi desenvolvido especificamente para análise estatística e visualização de dados. Sua sintaxe e funções são otimizadas para realizar tarefas estatísticas de forma eficiente, o que a torna uma escolha natural para estatísticos e analistas de dados.
Visualização de Dados Poderosa
R oferece ferramentas avançadas para visualização de dados. Pacotes como ggplot2 permitem criar gráficos sofisticados e personalizáveis com facilidade.
Isso é crucial para explorar dados e comunicar insights de forma clara e impactante.
Ampla Coleção de Pacotes
O CRAN (Comprehensive R Archive Network) oferece milhares de pacotes que estendem a funcionalidade do R.
Você encontra pacotes para praticamente qualquer tipo de análise estatística ou aprendizado de máquina, o que facilita a implementação de técnicas avançadas sem precisar reinventar a roda.
Forte Comunidade e Suporte
R tem uma comunidade de usuários muito ativa e dedicada. Há uma vasta quantidade de documentação, tutoriais, fóruns, e listas de discussão disponíveis. Isso facilita encontrar ajuda e recursos para aprender e resolver problemas.
Reprodutibilidade
R permite documentar todas as etapas do seu processo de análise, facilitando a reprodução dos resultados.
Isso é essencial em ambientes acadêmicos e de pesquisa, onde a transparência e a verificação de resultados são fundamentais.
Ambiente Interativo
R oferece um ambiente interativo que permite executar comandos e ver resultados imediatos. Isso é ótimo para exploração de dados e desenvolvimento iterativo de análises.
Integração com Outras Ferramentas
R pode ser facilmente integrado com outras linguagens de programação e ferramentas de análise de dados, como Python, SQL, e Hadoop. Isso proporciona flexibilidade e poder ao combinar diferentes tecnologias em um fluxo de trabalho.
Código Aberto e Gratuito
R é software livre e de código aberto, o que significa que é gratuito para usar e pode ser modificado e redistribuído. Isso elimina barreiras de custo e permite uma maior colaboração e inovação na comunidade.
Escalabilidade e Desempenho
Com pacotes como data.table e dplyr, R pode manipular e processar grandes conjuntos de dados de forma eficiente.
Além disso, R pode ser integrado com tecnologias de big data para análise em larga escala.
Flexibilidade
R é extremamente flexível e pode ser usado para uma ampla gama de tarefas, desde análises estatísticas básicas até modelagem avançada e aprendizado de máquina.
R é uma linguagem incrivelmente poderosa e versátil, especialmente adequada para análise de dados e estatísticas.
Suas capacidades gráficas avançadas, vasta coleção de pacotes, forte comunidade, e facilidade de integração com outras ferramentas fazem dela uma escolha excelente para cientistas de dados, estatísticos, e qualquer pessoa que precise realizar análises de dados complexas.
Além disso, ser open source e gratuito aumenta ainda mais sua atratividade. Se quiser se aprofundar, temos essa Formação de estatística com R
Como instalar a linguagem R?
Para começar a usar a linguagem R, você precisará instalar tanto o ambiente de programação R quanto um ambiente de desenvolvimento integrado (IDE), como o RStudio.
Vou te guiar pelo processo de instalação de ambos no Windows, macOS e Linux.
Instalando R
Acesse o site oficial do R e escolha o sistema operacional (SO) que fará o download do pacote. Vamos apresentar o processo com o SO do Windows.
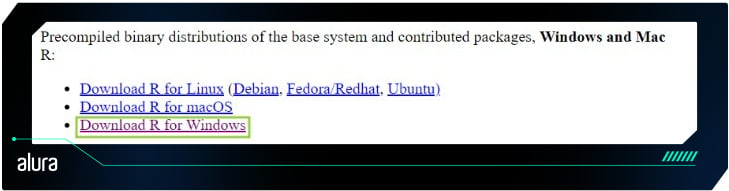
Após escolher o SO, se estiver baixando o R pela primeira vez clique no botão install R for the first time na página que abriu.
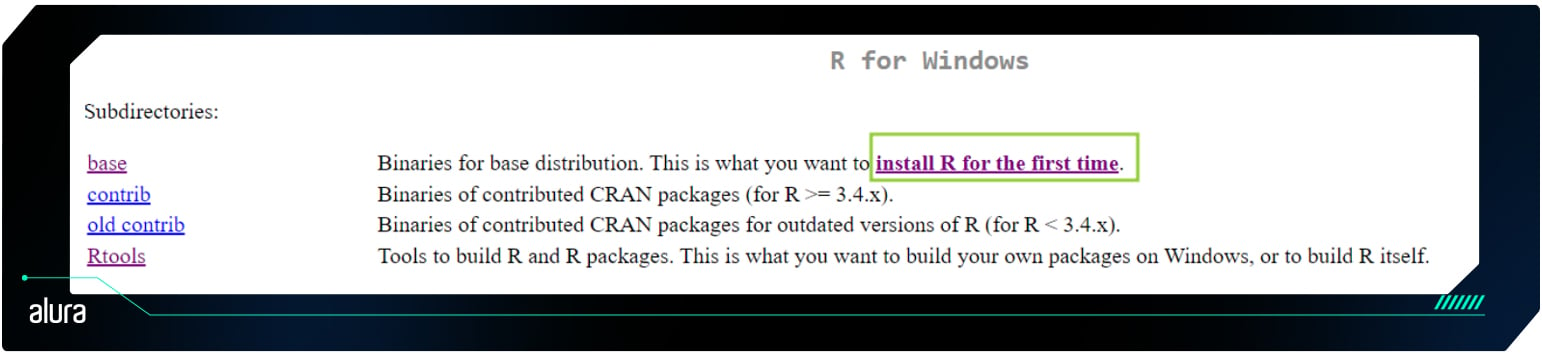
Agora, basta clicar em Download R for Windows para baixar o instalador.

Em sequência, execute o instalador e siga as instruções para instalar o R na sua máquina.
Pronto! Após essa 1ª etapa, vamos para a instalação do R Studio.
Instalando RStudio
Acesse o site oficial do R Studio. No início da página, são apresentados os dois passos necessários para utilizar o R Studio: instalar o R (que já fizemos) e instalar o R Studio.
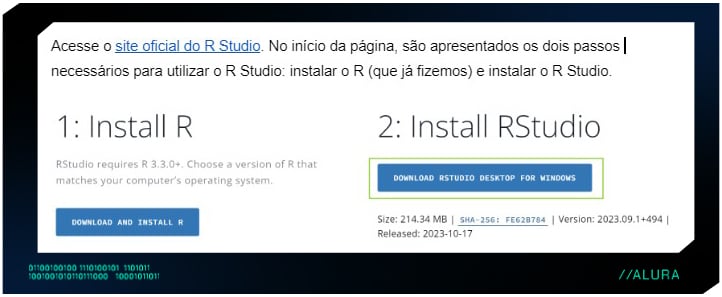
Vamos clicar em Download Rstudio Desktop For Windows para baixar o instalador no Windows. Note que ao descer mais na página do site oficial é possível observar diversos pacotes para diferentes SOs, caso seja o seu caso.
Em sequência, execute o instalador e siga as instruções para instalar o R Studio na sua máquina.
Verificando a Instalação
Para garantir que o R está instalado corretamente, você pode abrir o terminal (ou o Prompt de Comando no Windows) e digitar R. Isso deve iniciar o console do R.
Para verificar a instalação do RStudio, simplesmente abra o RStudio. Você deve ver a interface do RStudio, que inclui o console do R, o editor de scripts, o ambiente de variáveis e outros paineis úteis.
Primeiros Passos com R e RStudio
- Abrir o RStudio: Após a instalação, abra o RStudio.
- Criar um novo script: Vá para File -> New File -> R Script.
- Escrever seu primeiro código: No editor de scripts, escreva um simples código R como:
- Executar o código: Selecione a linha de código e clique no botão "Run" ou pressione Ctrl+Enter (Windows/Linux) ou Cmd+Enter (macOS).
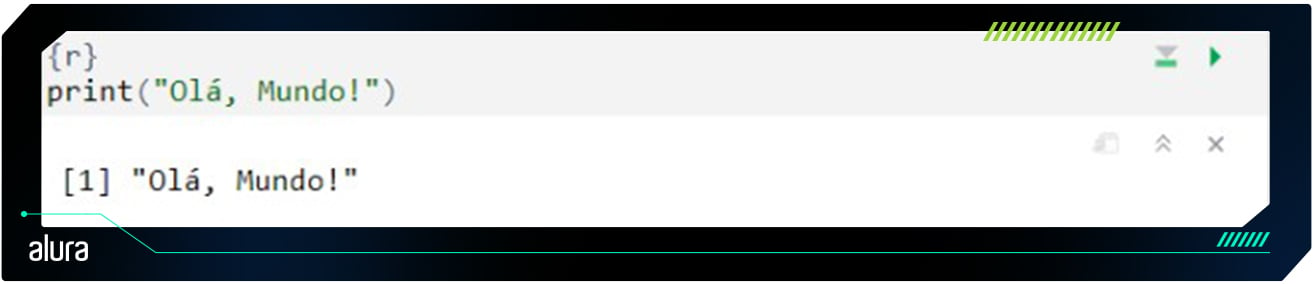
Com isso, você deve ver a mensagem "Olá, Mundo!" impressa no console. Parabéns! Você instalou com sucesso o R e o RStudio e está pronto para começar a explorar o mundo da programação com R.
Como programar na linguagem R
Programar na linguagem R pode ser uma experiência enriquecedora, especialmente se você estiver interessado em análise de dados, estatísticas e visualização de dados.
Vamos estruturar os primeiros passos e conceitos básicos para começar a programar em R.
Primeiro Script em R
Abra o RStudio e crie um novo script R (File -> New File -> R Script). Vamos começar com alguns comandos básicos:
Comentários
Você pode adicionar comentários ao seu código usando o símbolo #.
# Este é um comentário
Variáveis e Tipos de Dados
Vamos declarar algumas variáveis e ver como manipular diferentes tipos de dados.
# Números
x <- 10
y <- 20
# Strings
nome <- "João"
# Vetores
idades <- c(25, 30, 35, 40)
# Matriz
matriz <- matrix(1:9, nrow=3, ncol=3)
# Data frame
dados <- data.frame(
nome = c("Ana", "Bruno", "Carlos"),
idade = c(22, 25, 23),
nota = c(8.5, 9.0, 7.5)
)
# Listas
lista <- list(nome = "Maria", idade = 28, notas = c(9, 8.5, 10))
Funções Básicas
Vamos usar algumas funções básicas para manipulação de dados.
# Calculando a média de um vetor
media_idades <- mean(idades)
# Calculando a soma de um vetor
soma_idades <- sum(idades)
# Visualizando um data frame
print(dados)
# Selecionando uma coluna de um data frame
idades_dados <- dados$idade
# Selecionando uma linha de um data frame
primeiro_aluno <- dados[1,]
Estruturas de Controle
Vamos ver como usar estruturas de controle como if, for e while.
# Estrutura de controle if
nota <- 7.5
if (nota >= 7) {
print("Aprovado")
} else {
print("Reprovado")
}
# Estrutura de controle for
for (i in 1:5) {
print(i)
}
# Estrutura de controle while
contador <- 1
while (contador <= 5) {
print(contador)
contador <- contador + 1
}
Funções em R
Você pode definir suas próprias funções em R.
# Definindo uma função
soma <- function(a, b) {
return(a + b)
}
# Chamando a função
resultado <- soma(5, 3)
print(resultado)
Importando e Exportando Dados
R é muito usado para análise de dados, então importar e exportar dados é fundamental.
# Importando um arquivo CSV
dados <- read.csv("caminho/para/seu/arquivo.csv")
# Exportando um data frame para um arquivo CSV
write.csv(dados, "caminho/para/salvar/seu/arquivo.csv")
Visualização de Dados
Vamos usar o ggplot2, um pacote poderoso para visualização de dados.
# Instalando e carregando o pacote ggplot2
# install.packages("ggplot2")
library(ggplot2)
# Criando um data frame de exemplo
df <- data.frame(
categoria = c("A", "B", "C", "D"),
valor = c(3, 7, 9, 1)
)
# Criando um gráfico de barras
ggplot(df, aes(x = categoria, y = valor)) +
geom_bar(stat = "identity", fill = "skyblue") +
ggtitle("Gráfico de Barras de Exemplo") +
xlab("Categoria") +
ylab("Valor")

Executando o Código
No RStudio, você pode executar linhas individuais de código ou blocos de código selecionando-os e pressionando Ctrl + Enter (ou Cmd + Enter no Mac).
Exemplo Completo
Aqui está um exemplo completo que combina muitos dos conceitos trazidos:
Instalando pacotes necessários
install.packages("ggplot2")
install.packages("dplyr")
library(ggplot2)
library(dplyr)
# Dados fictícios
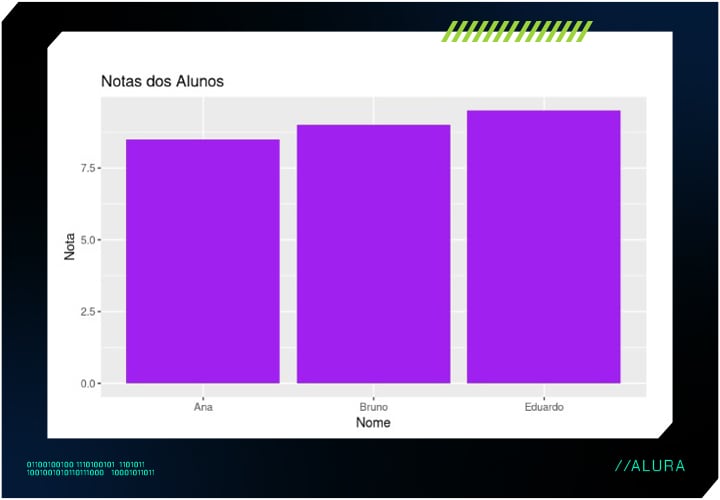
dados <- data.frame(
nome = c("Ana", "Bruno", "Carlos", "Daniela", "Eduardo"),
idade = c(22, 25, 23, 21, 24),
nota = c(8.5, 9.0, 7.5, 8.0, 9.5)
)
# Filtrando dados
dados_filtrados <- filter(dados, nota > 8)
# Calculando média das idades
media_idade <- mean(dados_filtrados$idade)
# Criando um gráfico de barras
ggplot(dados_filtrados, aes(x = nome, y = nota)) +
geom_bar(stat = "identity", fill = "purple") +
ggtitle("Notas dos Alunos") +
xlab("Nome") +
ylab("Nota")
print(paste("Média das idades dos alunos com nota > 8:", media_idade))
Como trabalhar com séries temporais no R?
Trabalhar com séries temporais no R é uma tarefa comum e bem suportada pela linguagem, graças a vários pacotes poderosos. Aqui está um guia passo a passo sobre como começar a trabalhar com séries temporais no R, incluindo como carregar dados, visualizar, decompor, modelar e fazer previsões.
Carregar e Preparar os Dados
Primeiro, é importante carregar um conjunto de dados de séries temporais. Suponha que temos um arquivo CSV com dados de vendas mensais.
Carregar os dados no R envolve a leitura do arquivo e a conversão da coluna de datas para o formato Date.
A preparação dos dados pode incluir a remoção de valores ausentes e a agregação dos dados em intervalos de tempo apropriados.
Criar um Objeto de Série Temporal
Para trabalhar com séries temporais no R, você pode usar a classe ts ou pacotes como xts e zoo para objetos mais complexos.
A criação de um objeto de série temporal é um passo crucial, pois permite que você aplique várias funções de análise e modelagem de séries temporais.
A classe ts é ideal para séries temporais simples com frequências regulares, enquanto xts e zoo oferecem mais flexibilidade para dados irregulares e funcionalidades adicionais.
Análise Exploratória de Séries Temporais
A análise exploratória de séries temporais é essencial para entender as características dos dados, como tendências, sazonalidades e possíveis anomalias.
Visualizar a série temporal com gráficos de linha ajuda a identificar padrões visuais importantes.
A decomposição de séries temporais é uma técnica que separa a série em componentes de tendência, sazonalidade e ruído, facilitando a análise individual de cada componente.
Decomposição de Séries Temporais:
Você pode decompor a série temporal em componentes de tendência, sazonalidade e ruído usando a função decompose. A decomposição ajuda a identificar e separar esses componentes, tornando mais fácil entender a estrutura da série temporal.
A visualização dos componentes decompostos pode revelar padrões subjacentes que não são evidentes na série original.
Visualização de Séries Temporais com ggplot2:
Para uma visualização mais avançada, use o pacote ggplot2. Ele permite criar gráficos sofisticados e personalizados, facilitando a comunicação de insights sobre a série temporal.
A utilização de ggplot2 permite adicionar camadas de dados, customizar eixos, títulos e legendas, e aplicar temas para melhorar a clareza e a estética dos gráficos.

Como aprender a linguagem R?
Aprender a linguagem R pode ser uma jornada empolgante, especialmente se você gosta de estatísticas, análise de dados e visualização.
Aqui estão algumas dicas e recursos para você começar e progredir no aprendizado de R:
Passos para Aprender a Linguagem R
Instalar R e RStudio
Antes de começar, você precisará instalar o R e o RStudio, conforme detalhado anteriormente. O RStudio oferece uma interface amigável e facilita o trabalho com R.
Conhecer os Conceitos Básicos
Familiarize-se com a Sintaxe do R:
Entenda como declarar variáveis, funções básicas, estruturas de controle (loops e condicionais) e manipulação de dados.
# Declaração de variáveis
x <- 10
y <- 20
# Operações básicas
z <- x + y
# Estruturas de controle
if (z > 15) {
print("z é maior que 15")
} else {
print("z não é maior que 15")
}
# Loop
for (i in 1:5) {
print(i)
}
Documentação Oficial:
Cursos da Alura da linguagem R
Aqui na Alura temos duas formações sobre R. Nelas você irá encontrar, cursos, vídeos, artigos e podcasts para que você possa aprender, praticar, se desenvolver e aprofundar cada vez mais. São elas:
Você também tem a possibilidade de interagir no fórum dos cursos e no nosso Discord.
Praticar com dados reais
Datasets Públicos:
- Utilize datasets disponíveis no R, como mtcars, iris, ou baixe datasets do Kaggle para praticar.
Projetos Pessoais:
- Crie projetos que interessem a você, como análise de dados financeiros, dados esportivos ou qualquer área que você goste.
Aprender Pacotes Essenciais
dplyr e tidyr
- https://cran.r-project.org/web/packages/dplyr/vignettes/dplyr.html
- https://cran.r-project.org/web/packages/tidyr/vignettes/tidy-data.html
O dplyr é uma ferramenta poderosa para manipulação de dados que oferece uma gramática consistente e intuitiva para transformar dados em R.
A documentação inclui uma introdução ao pacote, explicações detalhadas sobre as funções principais, exemplos de código, e tutoriais sobre como usar dplyr em diversos contextos.
O tidyr é uma ferramenta essencial para a limpeza e estruturação de dados, garantindo que cada coluna representa uma variável, cada linha representa uma observação e cada célula contém um único valor.
A documentação cobre uma variedade de funções úteis para manipulação de dados, incluindo pivotagem (alargamento e alongamento), separação e união de colunas, e mais.
O ggplot2 é um sistema para criar gráficos de forma declarativa, baseado na "Gramática dos Gráficos".
Ele permite que você forneça os dados, mapeie variáveis para estéticas e use primitivas gráficas, cuidando de todos os detalhes visuais para você.
A documentação oferece uma visão abrangente do pacote, incluindo instruções de instalação, tutoriais básicos e avançados, e exemplos de uso.
O pacote caret (Classification and Regression Training) fornece funções para treinamento e plotagem de modelos de classificação e regressão, incluindo ferramentas para pré-processamento de dados, seleção de características e avaliação de modelos.
Participar de Comunidades e Fóruns
Stack Overflow:
- Faça perguntas e veja soluções para problemas comuns: Stack Overflow R
R-bloggers:
- Leia tutoriais e artigos: R-bloggers
GitHub:
- Contribua para projetos open source e veja o código de outros desenvolvedores: GitHub R
Ler livros e referências
Livros sobre linguagem R:
- "R for Data Science" de Hadley Wickham e Garrett Grolemund.
- "Advanced R" de Hadley Wickham.
- "The Art of R Programming" de Norman Matloff.
Praticar Regularmente
A chave para aprender qualquer linguagem de programação é a prática constante. Dedique um tempo diário ou semanal para praticar e experimentar novas técnicas e pacotes.
Desenvolver Projetos Pessoais
Coloque em prática tudo que você aprendeu desenvolvendo seus próprios projetos. Seja uma análise de dados do seu interesse, um pequeno projeto de machine learning ou uma visualização de dados complexa.
Conclusão
R é incrivelmente versátil, sendo a queridinha para análises estatísticas, manipulação de dados e visualização gráfica, especialmente com pacotes como dplyr, ggplot2, e caret.
Quer fazer gráficos bonitos? Aprender machine learning? Trabalhar com bioinformática? R faz tudo isso e mais um pouco!
Sua comunidade ativa e a vasta coleção de pacotes tornam a vida dos cientistas de dados e estatísticos muito mais fácil e divertida. Então, se você trabalha com dados, R é uma ferramenta indispensável no seu kit.





