LlamaIndex: onde é aplicado


O LlamaIndex é um framework que facilita a integração de modelos de linguagem de grande porte (LLMs) com dados externos, permitindo a construção de soluções personalizadas de IA.
Ele organiza e estrutura o acesso a informações, potencializando a precisão das respostas geradas pelas LLMs..
Se as LLMs são a "mente" que cria respostas, o LlamaIndex seria como um "mapa", ajudando o modelo a encontrar o caminho correto dentro de um grande volume de informações.
Ele indexa dados de diversas fontes – como documentos, bancos de dados ou APIs – permitindo que o modelo de linguagem acesse essas informações de forma rápida e organizada.
Esse framework faz parte de um ecossistema mais amplo, composto também pelo LlamaCloud e pelo LlamaParse, que facilitam todas as etapas de implementação de uma solução de IA.
O LlamaCloud é uma plataforma que oferece infraestrutura escalável e automação em nuvem, enquanto o LlamaParse cuida da ingestão e pré-processamento de dados.
Juntos, esses componentes formam um sistema robusto, desde a ingestão até a entrega de respostas geradas pela IA.
Ao longo deste artigo, vamos explorar sobre as aplicações do LlamaIndex e da interação com esses outros componentes.
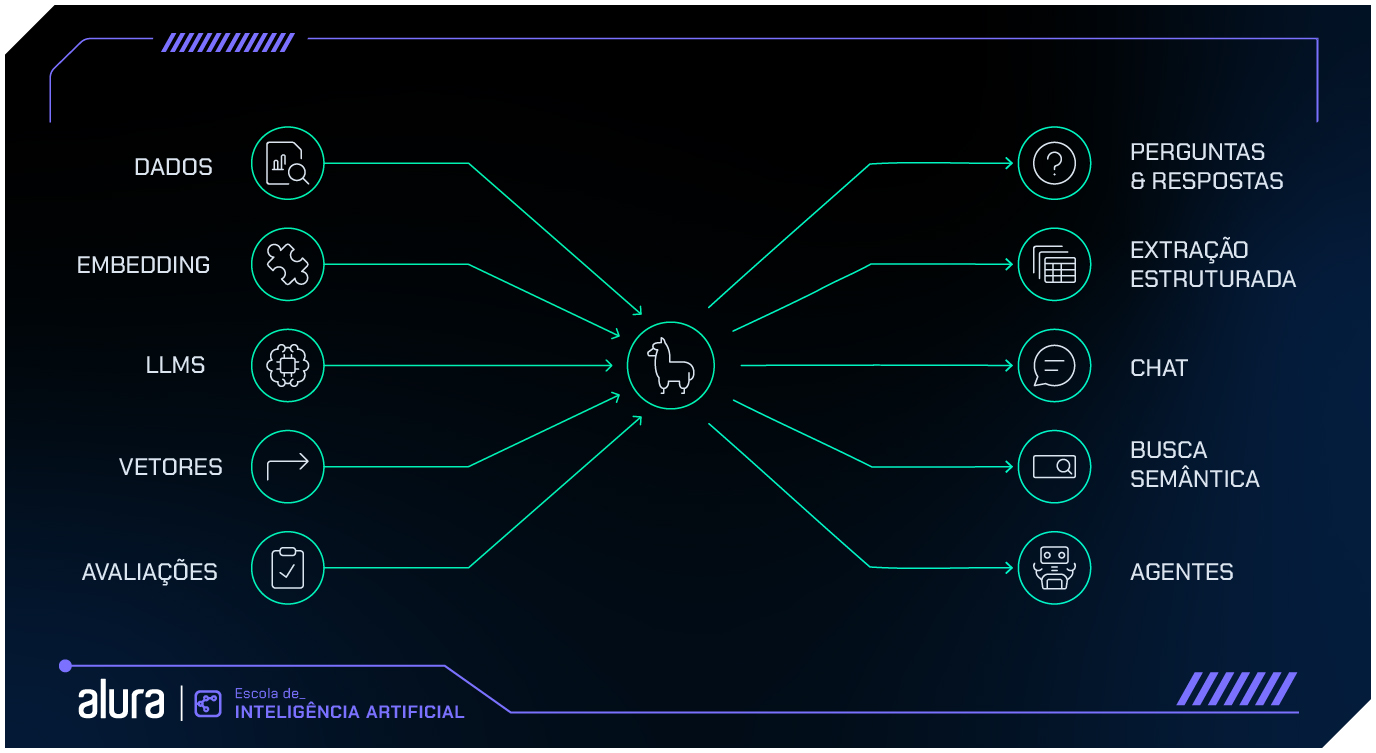
Possibilidades de aplicação do LlamaIndex
Aqui estão alguns exemplos das possibilidades de aplicação prática do LlamaIndez e da interação com esses outros componentes:
Ingestão de dados
A ingestão é o momento de conectar e preparar as fontes de dados que serão consultadas.
O LlamaIndex, em conjunto com o LlamaParse, é capaz de lidar com dados em diversos formatos, como arquivos PDF, e-mails, entradas de APIs e até dados oriundos de bancos de dados SQL e NoSQL.
O LlamaParse é responsável por extrair, pré-processar e padronizar esses dados, garantindo que estejam prontos para serem indexados, enquanto o LlamaIndex fica com a tarefa de recuperar e organizar as informações.
Indexação
A indexação é o ponto chave do LlamaIndex. É nesse momento que os dados são organizados para garantir consultas velozes e eficazes - na etapa de indexação, o conteúdo é organizado de forma que não precisa ser processado toda vez que uma consulta é feita.
Isso melhora o desempenho e garante uma resposta rápida e precisa.
Tipos de Indexação:
- Indexação Hierárquica: Organiza os dados em estruturas que facilitam a recuperação de informações relacionadas.
- Indexação de Texto Livre: Indexa grandes volumes de texto, permitindo consultas rápidas baseadas em palavras-chave ou contextos.
- Indexação Incremental: Permite a atualização contínua de índices sem a necessidade de uma reindexação completa, ideal para sistemas dinâmicos com informações em constante mudança.
Retrieval-Augmented Generation (RAG)
O método RAG combina a geração de texto por modelos de linguagem com consultas em tempo real a uma base de dados externa.
O LlamaIndex pode ser aplicado nesse contexto e criar um sistema que busque dados relevantes e, ao mesmo tempo, gere respostas baseadas nesses dados.
Por exemplo, no desenvolvimento de um assistente pessoal corporativo, o LlamaIndex pode ser utilizado para buscar informações em documentações internas da empresa e gerar respostas em linguagem natural.
Assim, é possível que um assistente responda perguntas com base em dados atualizados e específicos do contexto da empresa. Isso garante que as respostas serão precisas, além de economizar recursos computacionais (em comparação com fine-tuning).
Fine-Tuning
Embora o método de RAG reduza a necessidade de fine-tuning, há casos em que ajustes específicos no modelo são desejados.
O ajuste fino realiza alterações diretamente nos parâmetros do modelo, com base em novos conjuntos de dados.
Esse processo é custoso, mas traz melhorias significativas no desempenho de um modelo em tarefas específicas.
Agentes
Agentes são sistemas que, com o poder de um modelo de linguagem, podem “tomar decisões” de forma praticamente autônoma.
Com LlamaIndex, podemos criar agentes inteligentes que sejam responsáveis por performar tarefas específicas.
É possível automatizar fluxos de trabalho com os agentes, tendo como base sua base de dados.
Fluxo de Trabalho com Agentes:
- Definição de Tarefas: Um agente recebe uma tarefa ou uma série de ações a serem executadas.
- Consulta ao Índice: O agente consulta o LlamaIndex para acessar informações relevantes.
- Tomada de Decisão: Com base nos dados recuperados, o agente decide qual ação tomar ou qual resposta gerar.
Em um sistema de atendimento ao cliente automatizado, um agente poderia acessar contratos ou históricos de solicitações anteriores, por exemplo, e gerar uma resposta personalizada ou executar ações, como gerar uma fatura ou pedido de reembolso, com base nas informações obtidas.
Integração com LlamaCloud
Todos os processos descritos acima podem estar integrados ao LlamaCloud, uma plataforma de infraestrutura que permite escalabilidade automática e gestão de recursos para os projetos com LlamaIndex.
Experimentando com LlamaIndex no Colab
Agora que entendemos como funciona, que tal uma experiência prática? No Google Colab, podemos testar o LlamaIndex com poucas linhas de código:
Estou utilizando o Colab. Primeiro, vamos fazer a instalação necessária:
!pip install llama_index.llms.groqEntão, importamos o módulo Groq, que é uma plataforma especializada na execução eficiente de modelos de linguagem de grande porte (LLMs).
O Groq otimiza o uso de recursos de hardware, permitindo que modelos de IA funcionem com alta performance, especialmente em tarefas que demandam processamento intensivo, como consultas de linguagem natural.
Este módulo nos permite conectar o LlamaIndex à infraestrutura da Groq, utilizando a chave de API para autenticação e acesso ao modelo específico escolhido para nossas consultas.
from llama_index.llms.groq import GroqAgora, precisamos de uma chave de API que permita utilizar o Llama. Você pode criar uma chave através do site do Groq. Crie sua conta, crie a API Key e copie.
No Colab, para adicionar uma chave de API, clique no ícone de chave que fica no menu lateral esquerdo. Então, dê um nome (aqui utilizei GROQ_API) e, no valor, cole sua chave. É necessário permitir acesso ao notebook.
Para acessar a chave, podemos utilizar o seguinte código:
from google.colab import userdata
GROQ_API = userdata.get('GROQ_API')Legal!
Agora, é necessário definir qual LLM vamos utilizar.
llm = Groq(model='llama3-70b-8192', api_key=GROQ_API)Neste exemplo, segui a indicação da documentação , que utiliza o modelo llama3-70b-8192.
A escolha do modelo depende do seu caso de uso. Modelos menores podem ser suficientes para tarefas simples e consomem menos recursos, enquanto modelos maiores oferecem maior precisão.
Na plataforma Groq, você pode consultar uma lista de outros modelos disponíveis e, dependendo da sua necessidade, optar por outro modelo ajustando o parâmetro model.
Depois dessas pequenas configurações, já podemos fazer uma pergunta para o modelo.
response = llm.complete('Qual é a substância que dá o aroma do alecrim?')
responseCom uma simples iteração, podemos ajustar a formatação da resposta para que a leitura fique mais agradável.
paragrafos = response.text.split("\n\n")
for paragrafo in paragrafos:
print(paragrafo)
print()Temos uma resposta!
Com pouquíssimas linhas de código, fomos capazes de interagir com o Llama e obter uma ótima resposta. Imagina tudo que é possível ao integrar dados externos!

Casos de uso do LlamaIndex
Ao integrar os próprios documentos com o poder de uma LLM e a estrutura do LlamaIndex, as possibilidades de aplicação estão no limite da imaginação.
- Perguntas e respostas: O LlamaIndex é perfeito para sistemas de QA que precisam combinar múltiplas fontes de dados e fornecer respostas precisas. A recuperação de informações é baseada em similaridade semântica, e não apenas em palavras-chave. O sistema entende o contexto da pergunta e retorna as respostas mais relevantes.
- Chatbots inteligentes: Com o LlamaIndex, podemos criar chatbots que acessam dados em tempo real, respondendo com precisão e personalização, sem depender de respostas predefinidas.
- Extração e análise de documentos: Facilita a extração automática de dados relevantes de documentos complexos, como contratos, balanços financeiros e relatórios técnicos. Esses dados podem ser interpretados para gerar insights contextualizados.
- Agentes autônomos: O LlamaIndex também pode ser usado para desenvolver agentes autônomos que realizam tarefas específicas e tomam decisões com base em dados recuperados dinamicamente. Esses agentes podem ser configurados para acessar índices continuamente atualizados e agir de acordo com regras predefinidas.
- Sistemas multimodais: O LlamaIndex pode conectar diferentes tipos de dados — como texto, imagens e vídeos — e integrá-los na mesma consulta, ampliando o escopo de respostas geradas pela LLM.
Conclusão
Viu quanta coisa interessante podemos fazer com essa ferramenta? O LlamaIndex abre uma infinidade de possibilidades para integrar inteligência artificial com dados externos de maneira rápida, eficiente e precisa.
Se você tem curiosidade para entender mais sobre como tudo isso funciona e como pode aplicar essas tecnologias em seus projetos, continue explorando as novidades da área de Inteligência Artificial e se mantenha na vanguarda da tecnologia.