


Veja como manipular string no Pandas e veja meios de manipular seu data frame e tratar os dados da forma que precisar.
Imagine uma plataforma de música online chamada Alurafy, que permite tocar músicas, playlists e assinar dois tipos de planos. Os usuários acessam as páginas (URIs) e temos os dados crus em uma tabela com:
- coluna representando o ID do usuário (caso ele/a esteja logado/a)
- coluna com a URI acessada
- coluna com o status de resposta, se foi sucesso (200) ou um erro interno (500):
dados = pd.read_csv("todos_acessos.csv")
dados.head()
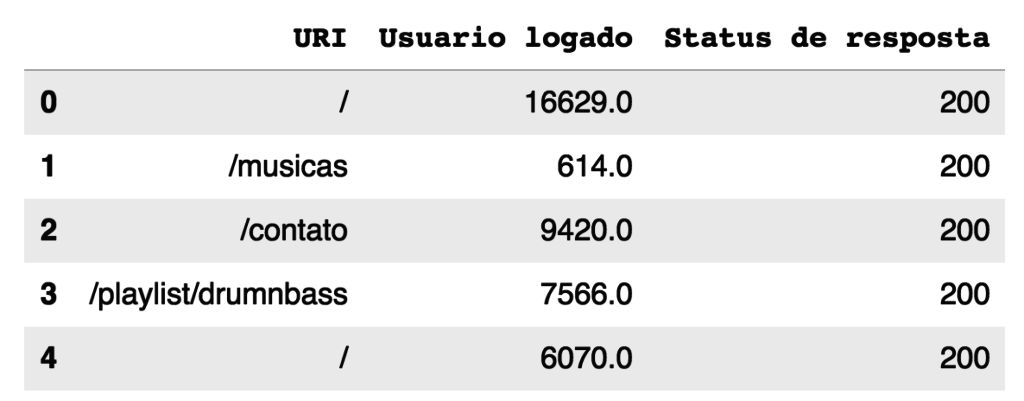

Basicamente todo dataframe possui um conjunto de dados que são strings e muitas vezes não reparamos, que são os nomes das colunas: URI, Usuario logado e Status de resposta:
dados.columns
Resultando em:
Index(['URI', 'Usuario logado', 'Status de resposta'], dtype='object')
Eles são nomes razoavelmente descritivos, mas horríveis para acessar. Por exemplo, não conseguimos acessar:
dados.Usuario logado
Mas somente:
dados['Usuario logado']
Claro, não é uma grande perda. Mas temos maiúsculo e minúsculo misturado, não tem um padrão claro. Que tal padronizar todas essas strings?
Para isso pegamos os nomes das colunas e através do atributo str conseguimos transformar todos em caixa baixa (minúsculo):
dados.columns.str.lower()
Resultando nas colunas em minúsculo:
Index(['uri', 'usuario logado', 'status de resposta'], dtype='object')
Mas os espaços em branco ainda estão lá. Podemos pegar essa série de dados, usar novamente o str e trocar os espaços por underlines:
dados.columns.str.lower().str.replace(' ', '_')
Finalmente com as colunas com os nomes que eu desejava:
Index(['uri', 'usuario_logado', 'status_de_resposta'], dtype='object')
Se atribuirmos os valores dessas colunas a elas mesmas:
dados.columns = dados.columns.str.lower().str.replace(' ', '_')
dados.head()
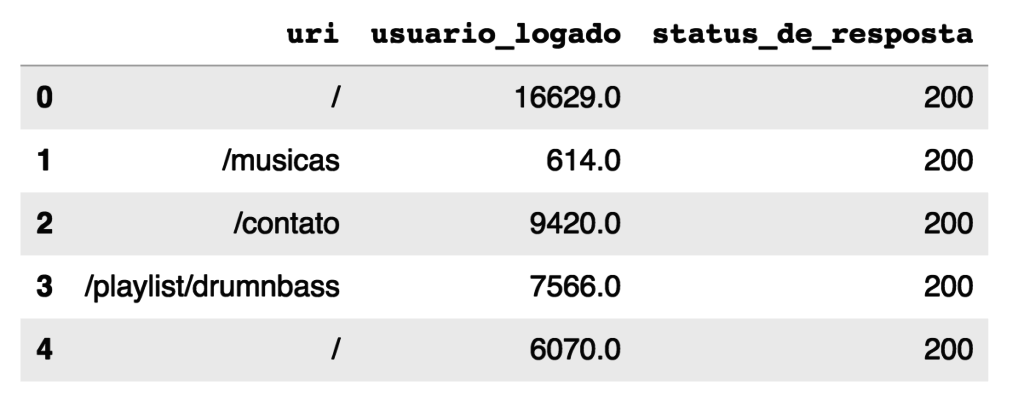
E essa linha de padronização dos nomes das colunas pode ser usado em quase todo projeto logo após importar um csv.
Agora vamos dar uma olhada nas páginas acessadas através de suas URIs:
dados.uri.unique()
array(['/', '/musicas', '/contato', '/playlist/drumnbass',
'/playlist/funk', '/compra/plano_basico', '/playlist/techno',
'/promocao_primeiro_de_abril/compra/plano_basico',
'/compra/plano_avancado', '/playlist/pop', '/playlist/rock',
'/playlist/jazz', '/playlist/classica', '/playlist/kpop'],
dtype=object)
Agora gostaria de criar uma coluna nova indicando se ao acessar aquela página, o usuário estava querendo comprar algo. Isto é, a URI começa com /compra/? Se sim, True, se não False. Para isso temos a função startswith:
dados['comprando'] = dados.uri.str.startswith("/compra")
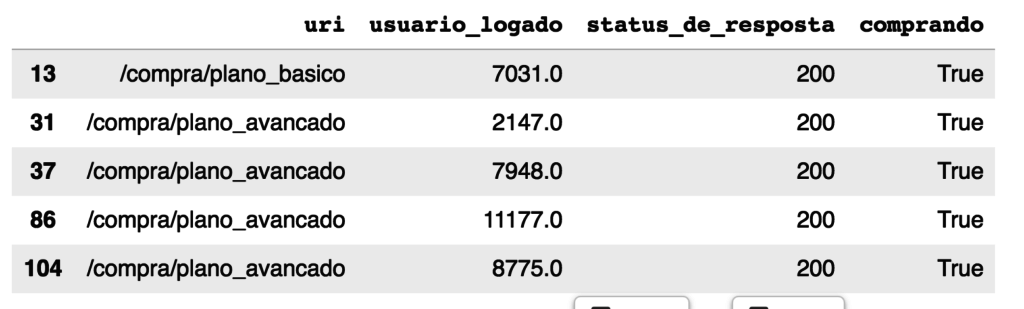
Portanto estamos buscando numa coluna de string/texto pelas linhas que começam com determinado valor. Agora imprimimos com uma query os 5 primeiros elementos que estão com True:
dados.query("comprando==True").head()Resultando em:
Para agrupar e contar o número de páginas de compra versus o número de outras páginas, vamos pegar a coluna comprando e somar seus valores:
dados.comprando.value_counts()E percebemos que temos cerca de 9.5% de acessos as páginas de compras:
False 164295
True 15705
Name: comprando, dtype: int64
Por fim, cometemos um erro. Na verdade existem também as páginas de compra como do dia primeiro de abril em /promocao_primeiro_de_abril/compra/plano_basico. Portanto queremos não só as URIs que começam com /compra/ mas que posseum no meio o trecho /compra. Além da função startswith, str nos permite executar diversas outras funções, como contains:
dados['comprando'] = dados.uri.str.contains("/compra/")
dados.query("comprando==True").head()

Agora sim, criamos a coluna nova de acordo com quaisquer páginas que possuem o trecho /compra/ em sua URI.
Resumindo, sempre que precisar trabalhar com uma coluna do tipo string, para extrair valores dela, fazer transformações de string para string, dê uma olhada na documentação da str para ver se ela já possui o que você deseja fazer. São algumas dezenas de funções.
O notebook com todo o conteúdo desse post pode ser encontrado no github.
Dentra da Alura disponibilizamos diversos cursos de Python, Pandas, Data Science e Machine Learning, onde vamos muito além da manipulação inicial dos dados.
