

Imagine que você está trabalhando em um projeto para prever os preços de imóveis em uma grande cidade, utilizando diversas características como localização, tamanho, número de quartos, entre outros.
Apesar de possuir uma quantidade grande de dados e já ter experimentado diferentes modelos de regressão, você nota que as previsões ainda estão longe do desejado, apresentando um erro significativo.
Modelos simples, como a regressão linear, muitas vezes não conseguem capturar toda a complexidade dos dados, enquanto modelos mais complexos, como as árvores de decisão, podem sofrer com o problema do sobreajuste, resultando em alta variabilidade nas previsões e, consequentemente, em baixa generalização para novos dados.
É nesse cenário desafiador que técnicas avançadas, como o boosting, se destacam como soluções eficazes.
Neste artigo, vamos explorar a técnica de boosting, detalhando uma das bibliotecas mais utilizadas para essa finalidade: a XGBoost.
Fique comigo até o final para descobrirmos como essa técnica funciona, suas vantagens e como a biblioteca XGBoost pode ser aplicada em diversos problemas de aprendizado de máquina! 🚀
Ensemble
Sabe quando você está trabalhando com um conjunto de dados para resolver um problema de regressão, mas a relação entre as variáveis pode não ser linear e pode envolver interações complexas?
Nesse momento é onde as árvores de decisão entram em cena como uma ferramenta valiosa em Machine Learning para resolver problemas de regressão.
Ao construir uma árvore de decisão, o algoritmo pode identificar padrões não lineares nos dados e criar regras simples que capturam as relações entre as variáveis, permitindo previsões mais precisas.
Porém, embora as árvores de decisão sejam uma ferramenta interessante, elas também apresentam algumas limitações.
Uma delas é a propensão ao overfitting (sobreajuste), que ocorre quando o modelo se ajusta muito bem aos dados de treinamento, mas não consegue generalizar bem para novos dados.
Além disso, estamos falando aqui de uma única árvore de decisão para resolver nosso problema. Será que isso é confiável?
Para superar as limitações das árvores de decisão individuais, podemos utilizar uma abordagem conhecida como ensemble, onde a ideia central é combinar vários modelos para obter um desempenho melhor do que qualquer um dos modelos individuais.
Isso é como ter um grupo de especialistas trabalhando juntos para resolver um problema: cada especialista oferece sua perspectiva única, e a combinação de suas ideias leva a uma solução mais abrangente e precisa.
Um exemplo clássico de algoritmo de ensemble é o Random Forest. Com este algoritmo, várias árvores de decisão são construídas de forma aleatória a partir de diferentes subconjuntos dos dados e de um subconjunto aleatório de características.
As previsões dessas várias árvores são então combinadas, normalmente por meio de uma votação para resolver problemas de classificação ou pela média em problemas de regressão.
Esse processo reduz o risco de overfitting, pois mesmo que algumas árvores superajustem os dados de treinamento, outras não passarão por isso, e a combinação das árvores resulta em um modelo mais equilibrado.
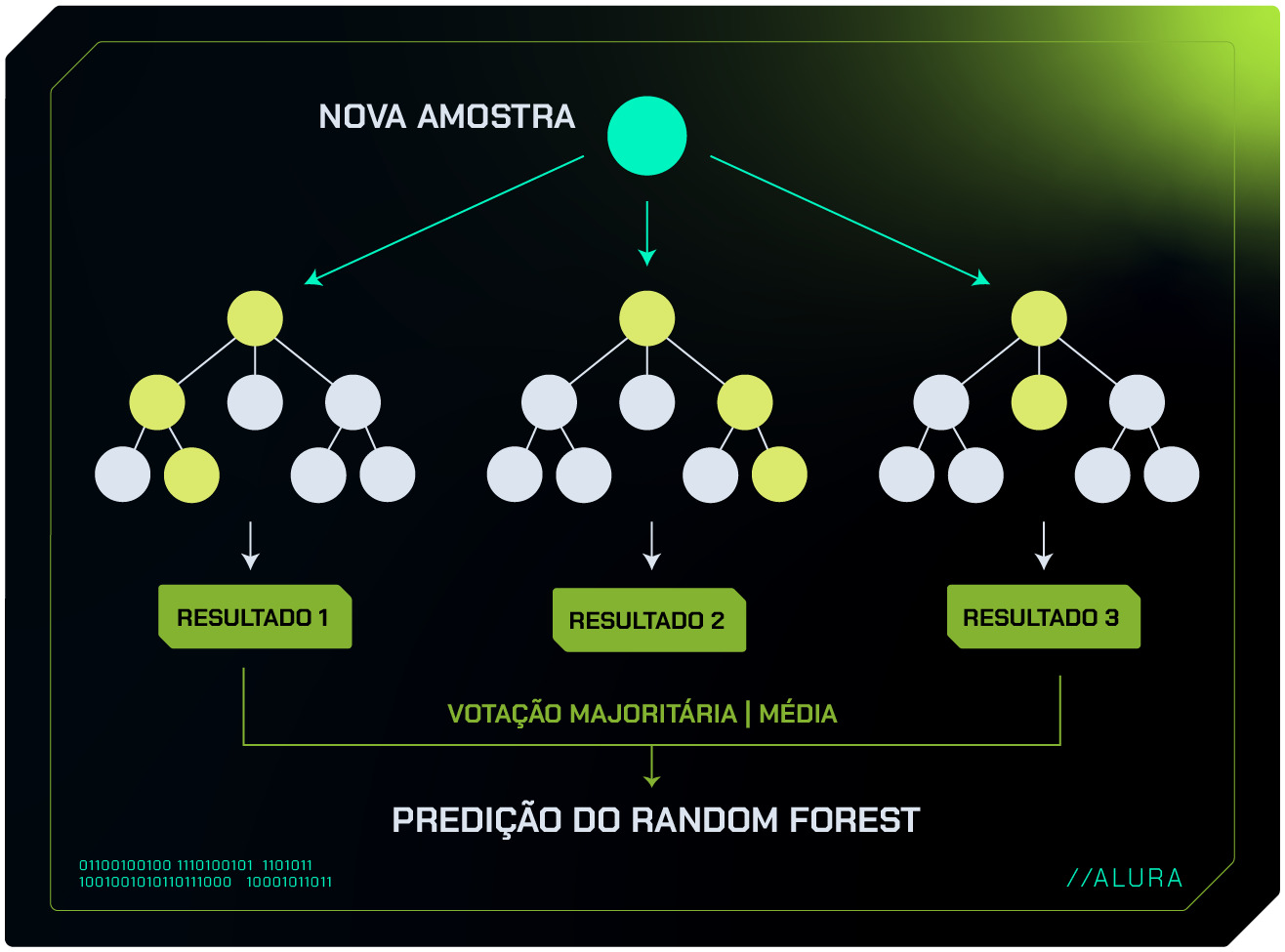
Além disso, dentro do ensemble, existe outro método ainda mais sofisticado que pode ser empregado para alcançar resultados melhores. Vamos explorá-lo em detalhes?

Boosting
Imagine que você tem um grupo de especialistas em previsão de preços de imóveis. Cada especialista faz uma estimativa inicial, mas como todos têm suas limitações, cometem erros.
No entanto, uma técnica entra em ação para melhorar essas previsões sequencialmente.
Após a primeira rodada de previsões, o modelo identifica os erros cometidos pelo primeiro especialista e direciona o segundo especialista para corrigi-los.
Essa correção dos erros continua em cada rodada subsequente, resultando em previsões cada vez mais precisas à medida que os especialistas ajustam e refinam os modelos com base nos erros anteriores.
Essa é a ideia por trás da técnica de boosting, que combina uma série de modelos simples para criar um modelo forte e robusto.
Ao invés de treinar todos os modelos de uma vez, o boosting treina os modelos de forma sequencial. Isso significa que cada novo modelo tenta corrigir os erros cometidos pelos modelos anteriores, como podemos observar na imagem abaixo:
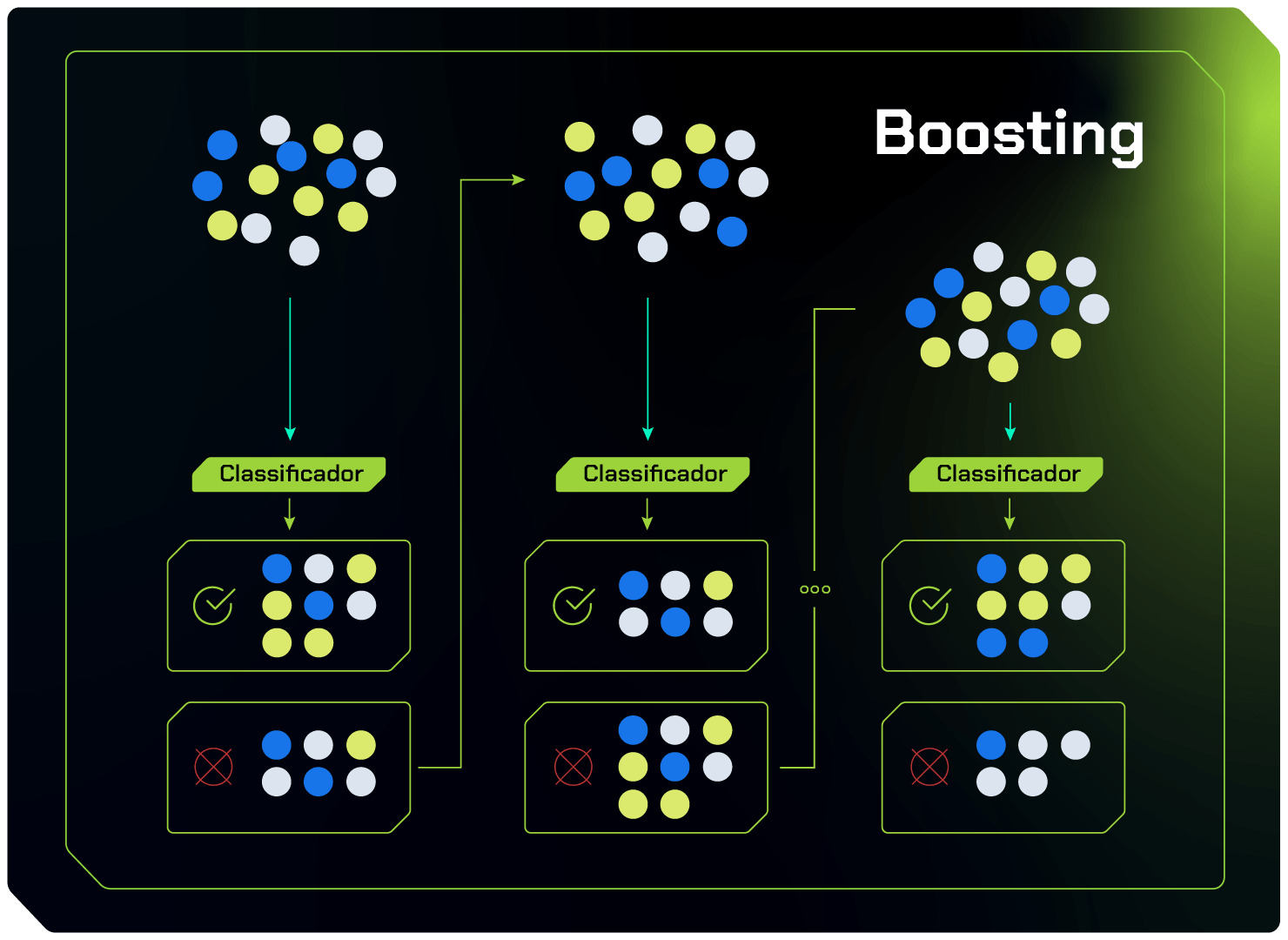
Embora árvores de decisão individualmente sejam modelos preditivos relativamente simples, quando adequadamente "impulsionadas" formam um comitê de decisão robusto.
Esse comitê, composto por várias árvores em sequência e ajustadas em conjunto, muitas vezes produz resultados difíceis de superar com outros algoritmos de Machine Learning.
Agora que compreendemos o conceito de boosting e seu funcionamento, que tal explorarmos alguns algoritmos que se baseiam nessa técnica.
Algoritmos de Boosting
Existem vários algoritmos de boosting populares, cada um com suas próprias características e aplicações específicas. Vamos dar uma conferida em alguns deles?
Adaptive boosting ou AdaBoost: É o algoritmo de boosting mais simples e, por isso, um excelente ponto de partida. Ele funciona de forma iterativa, ajustando o peso de cada exemplo no conjunto de treinamento a cada rodada. Exemplos mais difíceis recebem mais peso, forçando o modelo a focar neles e melhorar sua precisão geral.
Gradient Boosting: Possui um algoritmo de otimização para encontrar a direção que mais melhora o modelo a cada iteração. Essa abordagem garante que o modelo aprenda os erros de forma mais eficiente, levando a um desempenho superior em diversos problemas.
XGBoost: É um dos algoritmos de boosting mais populares e poderosos. Ele combina a técnica de Gradient Boosting com várias otimizações, como regularização L1 e L2 e aprendizado em paralelo, o que resulta em um modelo extremamente rápido, preciso e robusto.
A popularidade do XGBoost começou a crescer rapidamente devido à sua capacidade comprovada de produzir resultados melhores em competições de ciência de dados, como as hospedadas no Kaggle.
Os participantes descobriram que o XGBoost frequentemente superava outros algoritmos em termos de precisão e eficiência computacional, tornando-se rapidamente uma escolha preferencial para competições desafiadoras.
Além disso, sua implementação fácil de usar, juntamente com uma comunidade ativa de pessoas desenvolvedoras e usuárias, contribuiu para sua adoção generalizada na indústria de aprendizado de máquina.
E aí, vamos conhecer melhor o XGBoost?😍
XGBoost
XGBoost, abreviação para Extreme Gradient Boosting (Aumento extremo de gradiente), é uma biblioteca que se destaca como uma das abordagens mais utilizadas em aprendizado de máquina.
Desde sua introdução, o XGBoost conquistou uma popularidade significativa devido à sua eficácia em uma variedade de problemas de modelagem, incluindo regressão e classificação.
Essa biblioteca se destaca por utilizar a técnica de Gradient Boosting (Aumento de Gradiente), funcionando como um treinador experiente, guiando as árvores de decisão em direção à melhor solução.
Mas como será que essa técnica funciona?
Para entender como os algoritmos que utilizam esse tal de “aumento de gradiente” conseguem melhorar as previsões, precisamos explorar um conceito fundamental em aprendizado de máquina: o gradiente descendente.

Gradiente descendente
Imagine que você está tentando encontrar o ponto mais baixo em uma montanha usando uma lanterna em uma noite escura. Você começa em um ponto aleatório e dá passos na direção em que o terreno está descendo mais rápido.
Cada passo é cuidadosamente escolhido para garantir que você esteja sempre descendo, e não subindo, até eventualmente chegar ao ponto mais baixo da montanha.
No contexto de aprendizado de máquina, o ponto mais baixo da montanha representa o menor erro possível que nosso modelo pode alcançar. O gradiente descendente é o algoritmo que usamos para encontrar esse ponto mínimo.
Quando treinamos um modelo, nosso objetivo é minimizar a diferença entre as previsões do modelo e os valores reais.
Essa diferença é medida por uma função de perda (ou erro). No caso da regressão, uma função de perda comum é o erro quadrático médio, que calcula a média dos quadrados das diferenças entre as previsões e os valores reais.
O gradiente descendente é um método iterativo de otimização que ajusta os parâmetros do modelo para minimizar a função de perda.
Para entendermos direitinho como funciona, vamos separar o processo em alguns passos:
- Inicialização: Começamos com valores iniciais aleatórios para os parâmetros do modelo.
- Cálculo do Gradiente: Calculamos o gradiente da função de perda em relação aos parâmetros. O gradiente é um vetor de derivadas parciais que aponta na direção do maior aumento da função de perda.
- Atualização dos Parâmetros: Atualizamos os parâmetros na direção oposta ao gradiente, ou seja, na direção que reduz a função de perda. A magnitude dessa atualização é controlada por um valor chamado taxa de aprendizado.
- Iterações: Repetimos os passos 2 e 3 até que o modelo convirja para um mínimo local da função de perda.
A figura abaixo mostra quando alcançamos o ponto mínimo:
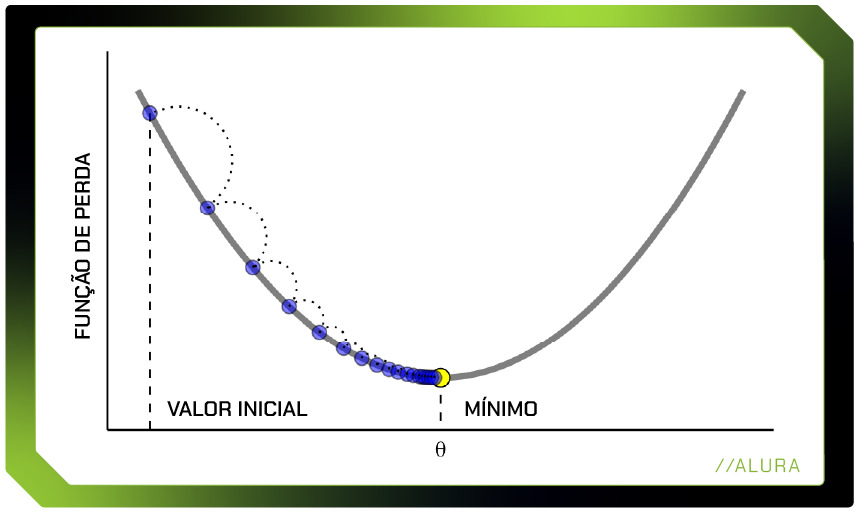
Mas não se assuste com todos esses conceitos matemáticos! Quando você usa um algoritmo de aumento de gradiente para criar um classificador (para categorizar coisas) ou um regressor (para prever um valor numérico), você não precisa se preocupar muito com os detalhes matemáticos complicados.
Ferramentas como a biblioteca XGBoost fazem a maior parte do trabalho pesado, permitindo que você se concentre em ajustar alguns parâmetros para obter o melhor modelo possível para sua tarefa.
Vantagens e aplicações do XGBoost
Talvez você ainda esteja se perguntando: "O que torna o XGBoost tão especial? Por que ele se tornou tão popular?"
Neste sentido, temos alguns pontos a considerar:
- Aprendizagem regularizada: O XGBoost oferece técnicas de regularização integradas, como L1 e L2, para evitar o overfitting. Isso ajuda que seu modelo seja generalizável para novos dados, não apenas para os dados em que foi treinado.
- Poda de árvores: A poda de árvores é usada para controlar a complexidade dos modelos de árvore de decisão, removendo ramos desnecessários que não contribuem significativamente para a precisão. Isso resulta em modelos mais eficientes e menos propensos a erros.
- Tratamento de valores nulos: O tratamento de dados ausentes é facilitado por recursos integrados, que simplificam o processo de pré-processamento durante o treinamento.
- Facilidade para lidar com variáveis categóricas: Ao contrário de outros algoritmos que exigem que você converta variáveis categóricas em valores numéricos, o XGBoost as trata de forma nativa. Isso significa que você pode alimentar seus dados diretamente no modelo, sem nenhuma etapa de pré-processamento adicional, desde que suas colunas categóricas estejam com o tipo “category” ao invés de “object”.
- Flexibilidade e adaptabilidade: O XGBoost é altamente flexível e pode ser aplicado a uma variedade de problemas de aprendizado supervisionado, incluindo classificação, regressão e ranking. Além disso, ele suporta uma variedade de funções de perda e hiperparâmetros, permitindo que os usuários personalizem o modelo de acordo com as necessidades específicas do problema.
- Eficiência computacional: O XGBoost é otimizado para eficiência computacional, oferecendo suporte à paralelização, tornando-o rápido e escalável mesmo para grandes conjuntos de dados.
Com isso, o XGBoost se destaca como uma biblioteca de Machine Learning de alto desempenho, conquistando popularidade tanto no mundo acadêmico quanto no ambiente corporativo.
O XGBoost tem muitos casos de uso reais em aprendizado de máquina como, por exemplo:
Previsão de horário de chegada: A empresa de transporte Uber já chegou a utilizar o XGBoost para obter previsões precisas do horário de chegada, o que é útil para para calcular tarifas, estimar horários de coleta, combinar passageiros com motoristas, planejar entregas e muito mais.
Se você quiser saber mais sobre essa aplicação pode conferir nos links a seguir:
Productionizing Distributed XGBoost to Train Deep Tree Models with Large Data Sets at Uber
DeepETA: How Uber Predicts Arrival Times Using Deep Learning
Engenharia de recursos hídricos: O XGBoost já foi utilizado para diferentes tarefas na área de hidrologia. Ele ajudou a modelar o comportamento da água, prever a quantidade e qualidade da água, e gerenciar águas subterrâneas. Também foi utilizado para estimar erosão e transporte de sedimentos, modelar reservatórios, canais abertos e prever fluxos de água sob pressão e em estruturas hidráulicas.
Se você quiser saber mais sobre essa aplicação pode conferir no material abaixo:
Diagnóstico médico: Pesquisas têm explorado o uso do algoritmo XGBoost para desenvolver modelos que auxiliem no diagnóstico e detecção de diversas doenças. Artigos científicos abordam a aplicação do XGBoost na predição de hipercalemia em pacientes com doença renal crônica, no diagnóstico da doença de Alzheimer e da doença de Parkinson, entre outras.
Além disso, o XGBoost tem sido amplamente utilizado para resolver uma variedade de problemas em competições de Machine Learning, como: previsão de vendas em lojas, classificação de textos da web, previsão do comportamento do cliente, detecção de movimento, previsão da taxa de cliques em anúncios, classificação de malware, categorização de produtos, previsão de risco e previsão em larga escala da taxa de evasão em cursos online.
Eita! É uma quantidade grande de aplicações, né? Que tal experimentar essa biblioteca nos seus próprios projetos e descobrir como ela pode ser útil pra você? 😀
Conclusão
Neste artigo, nós exploramos em detalhes o conceito de boosting, destacando sua capacidade de combinar modelos simples sequencialmente para criar um modelo forte e robusto, capaz de superar as limitações de modelos individuais.
Especificamente, concentramos nossa atenção na biblioteca XGBoost, uma das abordagens mais populares e poderosas nesse contexto.
Ao compreender a fundo o funcionamento do boosting e suas aplicações, assim como as vantagens e a flexibilidade oferecidas pelo XGBoost, você já pode pensar em começar a explorar e aplicar essa técnica!
E aí, curtiu o artigo? Aqui na Alura temos muitos outros conteúdos para te ajudar a estruturar seus conhecimentos em Machine Learning. Bora mergulhar em tecnologia? Venha estudar com a gente! 🤿
Créditos
- Conteúdo: Valquíria Alencar
- Produção técnica: Rodrigo Dias
- Produção didática: Cláudia Machado
- Designer gráfico: Alysson Manso
