Programação funcional no Python
Criei um sistema para controlar meus gastos mensais, fazendo com que todos os gastos do meu cartão fiquem salvos em um arquivo no meu computador, no caso gastos.txt, dessa forma:
18.90
5.50
19.99
25.00
52.15
200.00
...Depois de um tempo, meu arquivo começou a encher muito e ficar confuso. Percebi que ficaria mais claro se os gastos estivessem formatados de acordo com as normas da moeda brasileira, no padrão R$ 10,00.
Comecei a alterar valor por valor, manualmente, mas já não aguentava mais. O problema é que quando eu resolvi mudar, meu arquivo já estava muito cheio!
Imagine fazer todo esse processo manualmente para uma lista de mais mil registros. Será que não conseguimos automatizar tudo isso?
Já sabemos o que fazer para formatar uma moeda de acordo com o padrão de algum país, mas nesse caso temos um arquivo cheio de valores, não apenas um. O que podemos fazer?
Uma alternativa seria usar nossa conhecida técnica da compreensão de lista. Vamos tentar:
# código omitido
gastos = open(‘gastos.txt’, ‘r’)
gastos_formatados = [locale.currency(gasto) for gasto in gastos]E o retorno:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
MemoryErrorRecebemos uma exceção de tipo MemoryError! Como já sabemos, isso ocorre porque a compreensão de lista tenta armazenar todos os valores na lista ao mesmo tempo, sobrecarregando a memória RAM do nosso computador.
Vimos que esse problema de memória pode ser resolvido com iteradores. Mas a construção de uma classe iteradora é bastante complexa, será que vamos precisar de todo esse trabalho novamente? Não há uma maneira mais sucinta de se conseguir o que queremos?
Considerando nosso problema atual, o ideal seria se conseguíssemos aplicar a função currency() para cada linha do arquivo, mas sem sobrecarregar nossa memória. Como podemos fazer isso?
Utilizando a função map()
Os exemplos que serão apresentados a seguir exigem o uso do Python 3. Caso esteja curioso para entender o motivo, confira a seção Para saber mais (depois de ler o post inteiro, para não tomar spoiler!).
O Python, se aproximando um pouco mais do paradigma de programação funcional, nos provê algumas funções que nos auxiliam na manipulação de iteráveis, baseando-se no uso de iteradores.
A função built-in map() consegue aplicar uma mesma função para todos os elementos de um iterável. Ela vai percorrendo os elementos desse iterável e executando a função para cada um deles.
Queremos que a função currency() seja executada para cada linha de gastos. Vamos tentar usar o map(), que vai receber como parâmetros a função e a leitura do arquivo. Podemos usá-la dessa forma:
# código omitido
gastos = open(‘gastos.txt’, ‘r’)
gastos_formatados = map(locale.currency, gastos)
for gasto in gastos_formatados:
print(gasto)E o resultado:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib64/python3.6/locale.py", line 265, in currency
s = format('%%.%if' % digits, abs(val), grouping, monetary=True)
TypeError: bad operand type for abs(): 'str'Ué, uma exceção! Mas por quê? O que acontece é que o Python, quando lê arquivos, trata automaticamente o conteúdo como string, enquanto a função currency() só aceita tipos numéricos como parâmetro de valor.
Temos que, antes de usar a função currency(), converter todos os valores para float:
# código omitido
gastos = open(‘gastos.txt’, ‘r’)
gastos_float = map(float, gastos)
gastos_formatados = map(locale.currency, gastos_float)
for gasto in gastos_formatados:
print(gasto)Vamos ver o resultado dessa vez:
R$ 18,90
R$ 5,50
R$ 19,99
R$ 25,00
R$ 52,15
R$ 200,00
...Repare que o funcionamento do
map()depende da função passada para ele. Funções como amap(), que tomam outras funções como parâmetro, são chamadas de funções de alta ordem, ou, tecnicamente, _high-order functions_.
Deu certo!

Cuidados com funções de alta ordem
Note que tivemos que usar a função map() duas vezes apenas para isso, o que é um pouco repetitivo. A gente pode tentar juntar tudo em um só map():
gastos_formatados = map(locale.currency(float()), gastos)
for gasto in gastos_formatados:
print(gasto)Vamos ver se dá certo:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object is not callableUé, recebemos uma exceção indicando que objetos de tipo string não podem ser chamados como funções. Mas por quê?
O que acontece é que o primeiro parâmetro do map() deve ser a referência de uma função, não a chamada dela. Se chamamos ela no parâmetro, o retorno dela que será enviado para o map(). O que podemos fazer para executar as duas instruções de uma vez para cada elemento??
Passando nossa própria função para o map()
Sabemos que podemos passar qualquer função para o map(), então uma alternativa seria nós mesmos criarmos nossa própria função que formata a string para float e depois para a moeda brasileira:
# código omitido
def formata_moeda(valor):
return locale.currency(float(valor))
gastos = open(‘gastos.txt’, ‘r’)
gastos_formatados = map(formata_moeda, gastos)E também funciona perfeitamente! Mas não parece um pouco estranho termos que definir uma função tão simples só para isso? Funções tem algumas finalidades claras, como encapsular e reaproveitar código.
Nesse caso, não só não há muita necessidade de encapsular uma só linha, como não vamos usar o mesmo código em nenhum outro lugar! Será que vamos, mesmo assim, precisar criar uma função para cada pequeno comportamento que quisermos usar com o map()?
Funções anônimas com lambda
Temos uma alternativa para esses casos, em que declaramos as funções diretamente no parâmetro que as espera. Essas funções são conhecidas como funções anônimas, porque não possuem um nome e não são reutilizáveis - são acessíveis apenas como parâmetro da função que a recebeu.
No Python, podemos declarar funções anônimas com expressões lambda.
Expressões lambda reduzem a declaração de uma função para uma linha, e podem ser usadas como parâmetro de outras funções, o que é ótimo no nosso caso, com o map. Vamos aplicar o lambda ao nosso código:
# código omitido
gastos = open(‘gastos.txt’, ‘r’)
gastos_formatados = map(lambda valor: locale.currency(float(valor)), gastos)
for gasto in gastos_formatados:
print(gasto)Vamos ver se deu certo:
R$ 18,90
R$ 5,50
R$ 19,99
R$ 25,00
R$ 52,15
R$ 200,00
...Legal, o resultado foi certo como o anterior e ainda conseguimos escrever menos código! Isso foi bom porque não precisamos utilizar esse código em nenhum outro momento no programa, mas é importante notar que o uso de funções anônimas pode ser ruim na parte de reaproveitamento de código.
Mas como funciona essa expressão lambda? Vamos tomar como exemplo uma expressão lambda de uma função que soma dois valores passados como parâmetros, para entendermos melhor a sintaxe:
lambda a, b: a + bA sintaxe de uma expressão lambda é a palavra chave lambda seguida pelos nomes dos parâmetros separados por vírgula (a, b) e dois pontos (:) dividindo os parâmetros da expressão de retorno (a + b).
Funções lambda, diferente de funções normais declaradas com def, são restritas a expressões de uma única linha e omitem a palavra chave return, retornando automaticamente o que é computado na linha.
Como diz a própria documentação do Python, funções lambda, semanticamente, tem apenas a finalidade de simplificar um pouco nosso código. Na computação, temos um termo para esse tipo de coisa - açúcar sintático, ou syntax sugar.
Entretanto, há muitas críticas quanto ao lambda e sua legibilidade, inclusive feitas pelo próprio criador do Python, como veremos no final do texto. Sendo assim, por um lado elas podem diminuir e simplificar nosso código, mas por outro podem acabar, às vezes, se tornando uma complicação no programa.
Além de formatar os valores para moeda brasileira, para maior organização de todos esses dados, decidi dividir melhor os gastos. Quero separar os valores mais baixos, ou seja, menores ou iguais a 20.00. Como podemos fazer isso?
Já vimos que é possível usar a compreensão de lista como forma de filtro, mas isso nos traria de volta o problema da memória. Precisamos, de alguma forma, realizar essa filtragem mantendo um iterador.
Filtrando valores de um iterável com a função filter()
O Python nos disponibiliza outra função útil para nosso caso - a filter(), que retorna um iterador com os elementos que foram filtrados por meio do critério escolhido.
A função filter(), assim como a map() recebe dois parâmetros - a função que dará base ao filtro e o iterável que deverá ser filtrado. Entretanto, diferentemente do map(), a função passada no primeiro parâmetro deverá retornar um boolean, ou seja, True para um valor que deve ser mantido e False para um valor que deve ser descartado.
Como o filter() recebe uma função que retorna um boolean, vamos criá-la então:
def eh_menor_ou_igual_a_vinte(valor):
return float(valor) <= 20.00Certo! Mas espera… uma função só com uma linha para uma operação tão comum em programação básica? Podemos usar o lambda, agora que já conhecemos ele:
gastos = open(‘gastos.txt’, ‘r’)
gastos_baixos = filter(lambda valor: float(valor) <= 20.00, gastos)
for gasto in gastos_baixos:
print(gasto)E o resultado:
18.90
5.50
19.99
...Certo! Para imprimir no formato brasileiro, podemos usar o retorno do filter(), que é um iterador (portanto, um iterável) como parâmetro do map(), que aceita qualquer iterável, dessa forma:
gastos_baixos = filter(lambda valor: float(valor) <= 20.00, gastos)
gastos_baixos_formatados = map(lambda valor: locale.currency(float(valor)), gastos_baixos)
for gasto in gastos_baixos:
print(gasto)E então:
R$ 18,90
R$ 5,50
R$ 19,99
...Conseguimos filtrar os gastos como queríamos!
Para finalizar, só me resta uma coisa que eu gostaria de saber - o meu gasto total, ou seja, a soma de todos os meus gastos. Já conhecemos a função sum(), que pode tomar como parâmetro qualquer iterável, então uma alternativa possível seria fazer dessa forma:
gastos = open(‘gastos.txt’, ‘r’)
gastos_float = map(float, gastos)
soma_gastos = sum(gastos_float)E já teríamos um resultado correto. Mas, depois de ver tanta coisa simplificada, fica a dúvida - será que não há uma espécie de syntax sugar para isso, também?
Utilizando a função reduce() para reduzir um iterável a um só valor
No Python, há uma função com abordagem similar às outras duas que vimos, mas que consegue combinar todos os valores de um iterável em um só, de acordo com uma outra função que especificarmos.
Essa função chama-se reduce(), e também recebe como parâmetros uma função e um iterável. Podemos usá-la dessa forma:
from functools import reduce
gastos = open(‘gastos.txt’, ‘r’)
total_gastos = reduce(lambda a, b: float(a) + float(b), gastos)No Python 2,
reduce()é uma função built-in, mas no Python 3 fica no módulofunctools, necessitando umimportpara seu uso.
E teremos um resultado correto da soma de todos os valores!
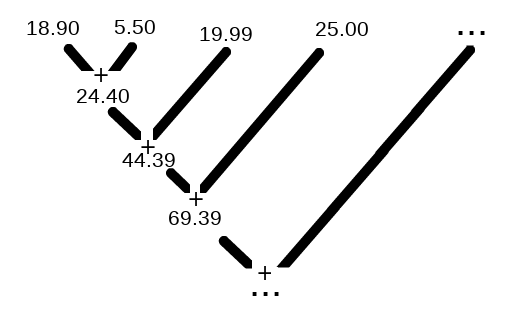
Repare que a função passada como argumento da reduce() deve receber dois parâmetros, em vez de um (como era na map() e filter()). Mas por quê? Afinal, como essa função funciona?
A função reduce() vai executando a função passada usando os valores do iterador de dois em dois. Usando como exemplo a lista de valores que tínhamos desde o início (18.90, 5.50, 19.99, 25.00, …), a seguinte imagem demonstra mais claramente esse funcionamento:

Assim ficamos com um só resultado no final!
Para saber mais
Por que focamos tanto no Python 3 nesse post? Acontece que, no Python 2, as funções que aprendemos nesse post se comportavam de uma forma um pouco diferente. Tanto a map(), quanto a filter() retornavam uma lista, não um iterador, o que manteria nosso problema de memória do começo.
Por conta disso, o criador do Python, Guido van Rossum, havia decidido remover as funções map(), filter(), reduce() e até o lambda na mudança para o Python 3. Quanto ao filter() e ao map(), para ele era muito simples - compreensões de lista eram quase sempre mais claras, além de mais rápidas comparadas a quando essas funções usavam um lambda.
Quanto ao lambda, ele argumentava que havia muita confusão sobre, tendo até uma certa concepção errada na comunidade de que lambda podia fazer coisas que def não podia - o que não é verdade! Além do mais, sem as funções map(), filter() e reduce() não haveria mais muita necessidade de funções anônimas de uma só expressão.
Enfim, sobre a função reduce(), Guido van Rossum explica que seu uso estava ficando complicado demais, sendo, assim, anti-pythônico e de difícil entendimento. Ele ainda cita um dos usos mais comuns dessa função, que é multiplicar todos os números de um iterável, dessa forma, por exemplo:
numeros = [1, 2, 3, 4, 5]
produto = reduce(lambda a, b: a * b, numeros)
print(produto)Para então termos o resultado:
120E, quando fala sobre esse uso, complementa dizendo que preferiria até criar uma função nativa product(), similar à função sum().
Entretanto, depois de muita pressão por certa parte da comunidade, o criador do Python decidiu não remover essas funcionalidades no Python 3. Em vez disso, ele simplesmente fez algumas mudanças, movendo reduce() da biblioteca padrão da linguagem para o módulo functools e fazendo com que map() e filter() retornem um iterador.
Ainda assim, é importante entender que, tanto no Python 2, como no 3, compreensões de lista são geralmente consideradas mais pythônicas que essas outras funções, principalmente por questões de legibilidade. Frente a um problema de memória, ainda podemos optar por funções ou expressões geradoras, também consideradas boas opções.
Conclusão
Nesse post, exploramos mais um pouco do paradigma de programação funcional em Python, com funções que recebem outras funções como argumentos. No caso, aprendemos a utilizar as funções map(), filter() e reduce().
Também aprendemos a criar pequenas funções anônimas com expressões lambda, simplificando, de certa forma, nosso código.
Além disso, discutimos um pouco o significado dessas técnicas no Python, entendendo o porquê da existência de alternativas consideradas melhores que elas.
Gostou de conhecer essa parte do Python? Coloque nos comentários o que você já conhecia e utiliza