Quais as diferenças entre Python 2 e Python 3?

Introdução: quais as diferenças entre Python 2 e Python 3?
Antes de se iniciar no Python, surge sempre a dúvida - qual versão da linguagem devo aprender? Talvez mais difícil que esta é a dúvida que vem de quem já programa em Python - devo fazer meus programas em qual versão do Python?
Tratando de algumas outras linguagens de programação, esta dúvida pode parecer menos usual, porque o que funciona em uma versão geralmente funciona também na próxima.
O ponto é que as duas maiores versões major do Python (2 e 3, as únicas em uso) têm diferenças cruciais. O Python 3 não é retrocompatível, e isso acaba trazendo algumas confusões e dúvidas para nós desenvolvedores. É a versão que utilizamos no formação de Python da Alura.
Mas o que essa "retroincompatibilidade" significa? Basicamente, indica que código escrito em Python 2 pode não funcionar rodando no interpretador do Python 3.
O Python 3 foi lançado no final de 2008, pouco mais de 8 anos depois do Python 2, e veio com intenções claras - retificar as falhas de design que a linguagem trazia.
Mas e aí? Sabendo disso, o que a gente faz? Temos agora um dilema, o que aprender? E, ainda, o que usar? Nesse post vamos tentar debater isso, apresentando pontos explicativos das diferenças entre as versões e argumentando em prol de um código mais pythônico.

Principais diferenças entre Python 2 e Python 3
Antes de tudo, precisamos entender de fato o que muda de uma versão para outra. Assim, deixamos um índice separando cada tópico, para facilitar a leitura do post.
- Diferenças entre as duas versões
- A decisão
- Conclusão
Mudanças sutis
As primeiras diferenças entre as duas versões em uso do Python são simples e, ao mesmo tempo, muito problemáticas.
O primeiro exemplo é o clássico da confusão já discutida por nós, a diferença das funções raw_input() e input(), que, para um desenvolvedor desatento com a mudança de versão, pode até causar um problema de segurança grave.
Além deste, temos os casos da função print() e do tipo file. No Python 2, print não é uma função, mas sim uma declaração, ou, tecnicamente, um statement. Assim, podíamos usá-la dessa forma, sem os parênteses:
print ‘Olá, mundo!’E tudo funcionaria bem! No Python 3, entretanto, o print() vira de fato uma função, necessitando os parênteses para ser chamada. Vamos ver o que acontece quando tentamos usar o print como usávamos no Python 2:

Uma exceção nos indicando a falta dos parênteses! Felizmente, essa questão é muito simples de ser resolvida, porque statements também funcionam com parênteses. Dessa forma, podemos fazer isso:
print(‘Olá, mundo!’)Que é válido tanto no Python 2 quanto no Python 3.
Por último, mas não menos importante, temos o construtor file, conhecido no Python 2 com seu uso para abrir arquivos quaisquer. No Python 3, esse construtor foi simplesmente removido. A recomendação que fica é, portanto, usar a função open(), independente da versão do Python, justamente por questões de compatibilidade.
Programação preguiçosa
Já vimos o que são iteradores no Python e como eles podem ser vantajosos quando comparados a listas comuns. Assumindo isso, os desenvolvedores do Python e a própria comunidade começaram a dar maior suporte e preferência nativa aos iteradores do que às listas.
Apresentamos alguns exemplos disso quando falamos sobre programação funcional em Python, com a alteração das funções map() e filter() para retornarem iteradores em vez de listas. O que mais temos além disso?
Como outro exemplo interessante, que pode causar confusão para desenvolvedores acostumados com uma dessas duas versões do Python, temos a função range().
No Python 2, a função range() retorna uma lista representando uma progressão aritmética. Assim, ela era claramente limitada, por questões da memória do computador. Vamos testá-la:

Além dela, tínhamos a classe xrange(), que fazia o mesmo, mas de maneira preguiçosa, isto é, um valor por vez.
No Python 3, o tipo xrange() foi renomeado para range() e o comportamento original da função range() perdeu sua função nativa própria (podendo ser facilmente simulado com list(range())):

Assim, utilizar métodos de lista com o range() ou assumir uma segurança na memória podem causar problemas na portabilidade do código para cada versão.
Comparação
A maneira clássica de comparação, que já estava sendo mudada no Python a partir da versão 2.1, com a chegada da comparação rica, tem seu estilo delimitado de vez no Python 3, com a remoção da função nativa cmp() e do método especial __cmp__().
Essas antigas funcionalidades eram baseadas no comportamento tradicional de comparação que vemos na maioria das linguagens de programação, como Java, em que se tem três tipos de retorno - -1, 0 e 1, para, respectivamente, um objeto menor, igual, ou maior que outro.
Quanto à comparação rica, ainda tivemos uma mudança importante no Python 3. A documentação dos métodos de comparação rica do Python 2 deixa claro que nenhum operador está ligado a outro. Assim, == não é naturalmente o oposto de !=:

Entretanto, no Python 3 isso é alterado para que o operador != resulte, nativamente, no oposto do operador ==. Dessa forma:

Em relação à comparação, também tivemos outra significativa mudança no Python 3, que acabou com um comportamento estranho que ainda era mantido no Python 2.
Na segunda versão, todos os objetos eram comparáveis ordinalmente entre si. Sim, todos. Isto significa que comparar se uma string é maior que um inteiro, ou que um float é menor que uma lista, tudo isso funcionaria, retornando True ou False dependendo do teste.
Claro, a lógica não era aleatória, o que não significa que era justificável, afinal dá margem para erros do desenvolvedor passarem despercebido.
A primeira regra desse tipo de comparação era que qualquer instância de uma classe definida pelo usuário era sempre menor que qualquer outro objeto nativo. Podemos facilmente testar isso no interpretador do Python:

A segunda regra era que tipos númericos eram sempre menores que os outros objetos. Vamos comprovar com testes:

A última regra principal era que, com objetos de outros tipos (que não criados pelo usuário nem numéricos), a comparação de ordem era alfabética com base nos nomes dos tipos. Dessa forma:

O resultado era True porque esse teste era equivalente a uma comparação de duas strings:

Como isso acaba causando resultados inesperados no código, esse comportamento foi removido do Python 3 e, agora, uma tentativa de comparação ordinal entre dois objetos que não têm uma ordem natural causa uma exceção do tipo TypeError.
Números
Na mudança de versão, tivemos algumas mudanças estruturais em relação aos tipos numéricos. A primeira, em relação aos próprios tipos em si, é a remoção da classe long no Python 3.
No Python 2, o tipo int era limitado, ou seja, tinha um valor máximo que podia chegar. Além desse valor, o tipo já era outro - o long, representado com um L após os dígitos numéricos:
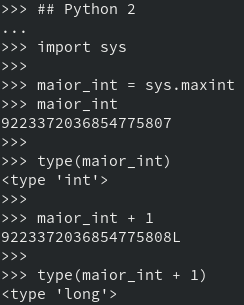
No Python 3 essa diferença, por fim, acaba, unificando os dois tipos em um só - o próprio int. Assim, o int perde seu limite e um número mais longo não é mais identificado com o sufixo L.
Divisão de números inteiros
Em relação aos números ainda temos uma mudança fundamental de ser entendida, pois pode acabar causando sérios problemas no funcionamento de um programa. Essa mudança se dá, mais especificamente, na divisão de números inteiros.
No Python 2, toda divisão envolvendo dois números inteiros resultava em um terceiro número inteiro:

No Python 3, porém, esse comportamento é bastante modificado - toda divisão envolvendo dois números inteiros agora resulta em um número float:

Nas duas versões do Python ainda temos um outro operador, //, que vai seguir o comportamento de divisão do Python 2:

Dessa forma, é recomendado seguir um padrão que funcione da mesma forma nas duas versões do Python, seja com o uso do operador //, resultando em um int, seja com a conversão de um dos inteiros para float, resultando em um float:

Tipos de texto
Uma das mudanças mais importantes na terceira grande versão do Python está nos tipos disponíveis para armazenar "texto".
"Mas por que texto entre aspas?"
Já vamos entender isso!
No Python 2, temos dois tipos principais para armazenamento de texto. O tipo padrão string (str) e o tipo unicode, identificado com o prefixo u antes das aspas:

Isso tudo indica duas coisas fundamentais: a primeira é que o tipo padrão string não suporta caracteres não-ASCII (unicode); a segunda, que não há um tipo próprio para armazenamento de bytes.
Por conta disso, costumava-se dizer, na comunidade Python, que o tipo string armazenava bytes, enquanto o tipo unicode era quem de fato armazenava texto.
Acreditar no potencial da string como texto de fato podia acabar causando problemas nos funcionamentos mais simples de uma aplicação, como é no caso de se imprimir um texto acentuado:
# Arquivo teste.py
print(‘Meu nome não é José’)Ao rodarmos esse arquivo com o interpretador do Python 2, olha o que acontece:
File "teste.py", line 1
SyntaxError: Non-ASCII character '\xc3' in file foo.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for detailsUma exceção indicando que nenhum encoding foi definido. Ou seja, precisamos definir um padrão para codificar as strings no programa que contêm caracteres não-ASCII.
No Python 3, as coisas mudam bastante. O tipo unicode se torna o tipo string (é renomeado para str) e um tipo nativo com o funcionamento da antiga string deixa de existir. Isso acaba permitindo algumas coisas muito interessantes no código, como o uso de caracteres unicode como nome de identificadores:

Note que o uso de caracteres não-ASCII para nomes de identificadores, apesar de ser um comportamento interessante e divertido em alguns casos, não é recomendado se queremos compartilhar nosso programa, por conta do perigo de incompatibilidade com outros sistemas e ambientes.
Além disso, é acrescentado um outro tipo específico para lidar com bytes, a própria classe bytes, representado pelo prefixo b:

Para um desenvolvedor que não conhece essa nova classe bytes, isso pode trazer alguns problemas, como por exemplo na identificação do tipo de um arquivo.
Tomando como exemplo arquivos GIF, que (quase) sempre começam com GIF89a, vamos ver como fica um código de identificação de GIFs que funciona no Python 2, em que abrimos o arquivo como leitura de bytes e checamos o começo:
arquivo = open(‘meu-gif.gif’, ‘rb’)
identificador = arquivo.read(6)
print(identificador == ‘GIF89a’)Quando rodamos o código no interpretador do Python 2:
TrueAgora olha o que acontece quando rodamos o mesmo código no Python 3:
FalseUé! Aí que fica clara a diferença de como o Python 3 lida com bytes, com a nova classe. O que acontece é que estamos comparando o identificador, que é do tipo bytes, por conta da leitura de dados, com uma string, o que vai retornar em False. Se tratarmos essa string como byte, olha como fica:
print(identificador == b’GIF89a’)E agora:
TrueSintaxe
Além das mudanças na estrutura e lógica do código, tivemos algumas significativas mudanças na sintaxe do Python 2 para o Python 3. De algumas coisas adicionadas, outras removidas, vamos focar no que foi alterado.
Tratamento de exceções
Um pouco da sintaxe do tratamento de exceções, mais especificamente com raise e o except, foi alterada. No Python 2, para chamarmos uma exceção com uma determinada mensagem, podemos usar a seguinte sintaxe:

No Python 3, olha o que acontece se tentarmos usar a mesma sintaxe:

Realmente recebemos uma exceção, mas nada a ver com o que tínhamos pedido! Foi um erro de sintaxe, porque essa maneira de usar o raise não é permitida no Python 3. Em vez disso, devemos tratar o tipo da exceção como uma função e passar a mensagem como parâmetro:

E agora sim funciona. Felizmente, essa sintaxe funciona tanto no Python 3 quanto no Python 2, então é recomendável usá-la sempre, independente da versão que estamos usando enquanto programamos, para ampliar a compatibilidade de nosso programa.
Em relação ao except, a mudança também é bastante sutil. No Python 2, podíamos usar a seguinte sintaxe em um bloco try/except:
try:
blablabla
except NameError, erro:
print(erro)Se rodarmos esse código no interpretador do Python 2:
name ‘blablabla’ is not definedCerto! Mas se rodarmos esse código no Python 3, olha o que acontece:
File "testeexcept.py", line 3
except NameError, erro:
^
SyntaxError: invalid syntaxPara o código funcionar no Python 3, devemos usar a palavra chave as:
try:
blablabla
except NameError as erro:
print(erro)E agora:
name ‘blablabla’ is not definedCerto! Esse código, assim como com o do raise, também funciona tanto no Python 3 quanto no Python 2, o que é ótimo para nós, desenvolvedores.
Indentação
O Python, por padrão, já é bastante rigoroso quanto à indentação de nosso código. Não usamos identificadores de começo e fim de blocos de código, como chaves ({}), mas os identificamos através da própria indentação.
Esse detalhe do Python acaba sendo muito vantajoso, por nos incentivar ao uso de boas práticas de design e indentação de código. Além dessa regra de sintaxe obrigatória, temos recomendações em relação a isso especificadas em nosso guia de estilo para código Python, o PEP-8.
O PEP-8 indica que 4 espaços são preferíveis a uma TAB para indentação. No final, é claro, fica a critério do desenvolvedor. Mas, acima de tudo, esse guia nos ensina que o melhor código é o código consistente. Isto é, é melhor só usar TABs para indentar, do que ficar mudando de TABs para espaços.
Quanto a isso, entretanto, não havia restrição alguma no Python 2. Em um mesmo bloco de código, podia-se alterar de TABs para espaços. No Python 3, isso é mudado, e uma inconsistência desse tipo resulta em uma exceção:
TabError: inconsistent use of tabs and spaces in indentationEssas são algumas das principais diferenças entre as duas versões que pode acabar atrapalhando mais um desenvolvedor que não as conhece.
Se quiser ver a lista oficial, o Python apresenta as novidades de cada versão em uma página na documentação. Mas e agora?
Qual versão aprender? (E, ainda, qual versão ensinar?)
Para alguém iniciando agora na linguagem, então, qual versão aprender? Qual versão focar?
É certo que a terceira versão do Python é um avanço da linguagem, tendo surgido para melhorar a versão anterior. Pode-se, é claro, argumentar a favor do Python 2, afinal algumas de suas características eram de fato melhores para certas necessidades. Mesmo assim, é difícil negar o aprimoramento que o Python 3 trouxe.
Além disso, ainda podemos ver o Python 3 como um conserto das falhas do Python 2. Assim, acaba sendo preferível para um iniciante que aprenda direto o Python 3, para não se atrapalhar com as falhas que a segunda versão tinha, evitando confusões de aprender algo já considerado errado e superado.
Apesar disso, é fato que código em Python 2 existe aos montes e continuará existindo por bastante tempo, então é importante que um desenvolvedor Python tenha clareza das principais diferenças entre as duas versões, para saber lidar com ambas à medida que aparecem em sua vida.
E agora, já tendo conhecimento em Python, qual versão eu devo escolher para desenvolver?
Para qual versão programar?
Pensando em qual versão programar, temos que ser realistas e considerar o mercado e o uso de Python que as empresas e os pontos de trabalho fazem atualmente. Uma pesquisa realizada em 2014 destinada para desenvolvedores Python pode nos ajudar a entender a visão que prevalece, ou ao menos prevalecia, há 4 anos.
O recomendado é que se priorize a última versão, quando possível. Sendo assim, se você está começando um projeto pessoal novo, prefira programar pensando no Python 3.
Começar um novo projeto com Python 3 pode evitar possíveis problemas que a versão anterior carrega e que já foram consertados e conseguir maior suporte para próximos avanços, afinal é dito que a partir de 2020 o Python 2 será descontinuado, perdendo grande parte de seu suporte.
Também é recomendado que código em Python 2 seja migrado para a terceira versão, e é o que grande parte dos importantes projetos em Python, inicialmente desenvolvidos na segunda versão, estão fazendo, como é o caso do Requests e BeautifulSoup.
Mesmo assim, sabemos que essa migração pode não ser tão simples, tanto no quesito técnico quanto no quesito burocrático - nem sempre uma empresa vai apoiar a migração, que pode trazer certos problemas no começo.
Dessa forma, a manutenção de código em Python 2 às vezes acaba sendo obrigatória e, além disso, pode ser vantajosa para os que já tem uma estabilidade garantida.
De qualquer maneira, geralmente queremos que nosso código seja compatível com o maior número de sistemas possíveis, para alcançar um maior público.
Assim, o ideal seria com que conseguíssemos fazer um código que funcione tanto para Python 2 quanto para Python 3, rodando com sucesso em qualquer um dos interpretadores. Será que conseguimos fazer isso?
Tornando seu programa compatível com as duas versões
Antes de aprendermos como podemos aumentar a disponibilidade de nossos programas, precisamos concluir para quem queremos fazer isso? Afinal esse processo torna-se muito complicado à medida que incluímos mais e mais detalhes, sistemas e versões.
Assim, a própria documentação do Python recomenda que não nos importemos, se possível, com o suporte para qualquer versão do Python abaixo da 2.7. Isso facilita muito a portabilidade de nosso código.
Se isso não for uma opção, temos alguns projetos na comunidade, como o six, que pode nos ajudar a manter um código compatível.
Com isso em mente, trabalharemos daqui pra frente considerando suporte para Python >= 2.7.
Algumas ferramentas, técnicas e práticas podem nos auxiliar bastante na portabilidade de nosso código. Vamos entender e testar algumas delas para podermos decidir quais são as melhores opções.
Escrevendo código compatível com as duas versões
Muitas vezes ainda é perfeitamente possível escrever código que funcione com as duas versões, afinal a mudança não é total.
Para isso, só temos que tomar cuidado com algumas práticas, lembrando sempre de usar, quando possível, uma funcionalidade ou sintaxe que funcione para Python 2 e 3. Um bom exemplo disso é com o print, que no Python 2 também pode ser usado com parênteses.
O problema é que em alguns casos temos problemas realmente incompatíveis, como com o input() e o raw_input(). Como podemos lidar com isso?
Uma abordagem seria checar qual versão do Python está rodando, e podemos fazer isso com o atributo version_info.major do módulo sys:
from sys import version_info
if version_info.major == 3:
nome = input(‘Digite seu nome: ‘)
else:
nome = raw_input(‘Digite seu nome: ‘)Certo, esse código aparentemente funciona. Mas e se o Python 4 for lançado? A versão não será igual a 3 e o programa tentará usar a função raw_input(), que muito provavelmente nem ao menos existirá. É melhor, então, basear nossa checagem na versão 2 do Python:
if version_info.major > 2:
nome = input(‘Digite seu nome: ‘)
else:
nome = raw_input(‘Digite seu nome: ‘)Assim já temos um melhor funcionamento. Mesmo assim, usar checagem de versão em vez de checagem de funcionalidade pode ser um problema, pois as coisas podem mudar e voltar a ser como eram antes de uma versão para outra. Confiar na detecção de versão pode atrapalhar a compatibilidade com mudanças futuras na linguagem.
Além do mais, é muito citada na comunidade Python uma frase de uma das mais importantes programadoras da história - Grace Hooper. A frase pode ser traduzida como "às vezes é mais fácil pedir desculpas do que pedir permissão".
Com essa filosofia em mente, podemos considerar tratar a detecção de funcionalidade com tratamento de exceções no Python:
try:
nome = raw_input(‘Digite seu nome: ‘)
except NameError:
nome = input(‘Digite seu nome: ‘)E agora temos o código ideal para esse tipo de situação!
Conclusão
Nesse post, pudemos ver algumas das principais diferenças entre as versões 2 e 3 do Python, entendendo o porquê dessas diferenças e o que elas afetam.
Além disso, discutimos qual versão devemos priorizar, concluindo que, no geral, Python 3 é preferível daqui pra frente.
Também pudemos trabalhar algumas técnicas para aprimorar a compatibilidade de nosso código, tornando-o usável com as duas versões.
E aí, gostou do conteúdo? Me diga aí qual sua opinião sobre isso e qual versão você costuma usar nos comentários!