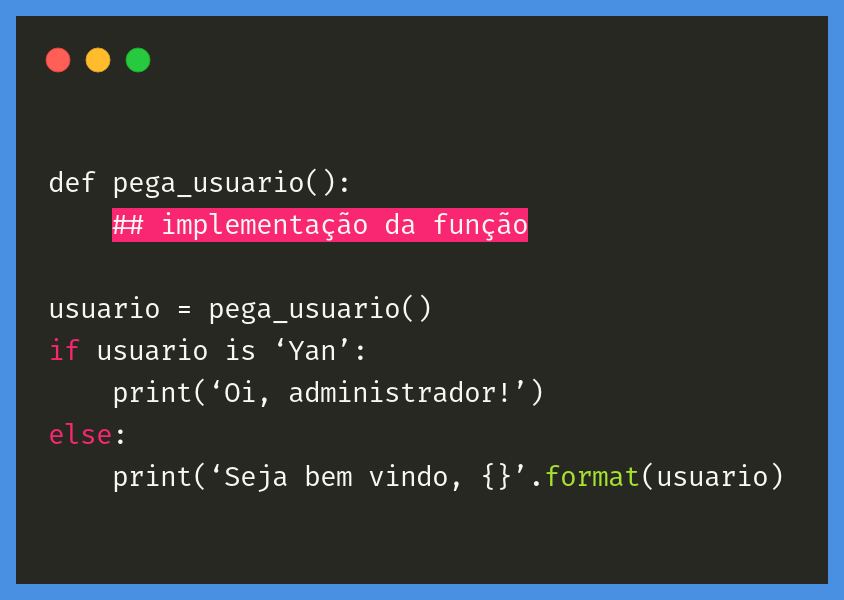


Fiz um programa em Python para ser iniciado sempre que meu computador liga. O programa pega o nome de usuário de quem está usando e retorna uma mensagem de boas vindas.
Caso o usuário seja eu mesmo, que sou o administrador do computador, quero que a mensagem seja diferente. Decidi implementar utilizando um operador que aprendi recentemente - o is:
def pega_usuario():
## implementação da função
usuario = pega_usuario()
if usuario is ‘Yan’:
print(‘Oi, administrador!’)
else:
print(‘Seja bem vindo, {}’.format(usuario)
Loguei no meu computador através do usuário Visitante e:
Seja bem vindo, Visitante
Quando loguei como Yan:
Oi, administrador!
Certo, aparentemente está tudo funcionando! Acontece que eu resolvi mudar o meu login de Yan para Yan Orestes. Alterei meu código:
if usuario is ‘Yan Orestes’:
print(‘Oi, administrador!’)
else:
print(‘Seja bem vindo, {}’.format(usuario)
Fui logar com meu usuário e:
Seja bem vindo, Yan Orestes
Ué! Se o usuário era exatamente o mesmo, por que não deu certo?
is para identidade, == para igualdade
O que acontece é que estamos usando o operador is sem entender de fato como ele funciona! O is compara a identidade do objeto, isto é, o valor de referência de seu endereço na memória, não o valor definido por nós.
Mas espera… já vimos algo assim, não é? O operador == também funciona, a princípio, desta forma, mas seu comportamento pode ser alterado através dos métodos de comparação rica, por exemplo.
Então como podemos alterar o comportamento do is? Bem… na verdade, não podemos. O propósito do is é justamente esse, uma comparação que sempre se baseará na identidade de um objeto, ou seja, se um objeto de fato é (is) o objeto que está sendo comparado.
Quando quisermos comparar um valor (ou qualquer coisa que definirmos) de um objeto, usamos, então, o operador == e os métodos de comparação rica. Quando quisermos comparar a identidade de um objeto, usamos o is.
Mas, se é assim, por que nossa primeira comparação com is (usuario is 'Yan') retornou True?

String interning no Python
Por padrão, no Python (na implementação padrão CPython), cada vez que atribuímos um objeto a uma variável, estamos criando um objeto. Ou seja:
nome = ‘Yan Orestes’
print(nome is ‘Yan Orestes’)
Deve resultar em:
False
Mas vimos que esse resultado esperado não foi obtido com a string ’Yan’. Por quê? Isso é o que chamamos, na computação, de _string interning_.
String interning é uma técnica que força o armazenamento de apenas uma cópia de cada valor de string diferente na memória do computador.
Essa técnica é de muita utilidade para poupar espaço na memória, mas, ao mesmo tempo, pode prolongar o tempo de processamento de algumas operações, já que ao criar uma string,o computador tem de procurar por todas as strings já existentes se uma já tem o valor dessa nova.
O Python suporta essa técnica de string interning através da função intern() (que é built-in no Python 2 e no Python 3 se localiza no módulo sys), mas não a utiliza por padrão nas operações de strings. Entretanto, há algumas exceções em que essa técnica é usada nativamente pela linguagem.
Um exemplo é com strings de apenas um caractere, que sempre passam por esse processo:
a = ‘y’
print(a is ‘y’)
E o resultado:
True
No nosso caso, com a string ’Yan’, o que acontece é que as strings que se pareçam com identificadores Python, isto é, contenham apenas letras normais (a-z A-Z), números (0-9) e underlines (_), passam automaticamente pela técnica de string interning.
Por isso o teste com a string ’Yan’ teve um resultado diferente de com a string ’Yan Orestes’, que contém um espaço em branco. Olha como seria se não tivesse esse espaço:
usuario = ‘YanOrestes’
print(usuario is ‘YanOrestes’)
Como resultado:
True
Peculiaridades com números inteiros
O Python nos traz um comportamento parecido ao do string interning automático quando lidamos com números inteiros. Vamos fazer alguns testes:
a = -6
print(‘-6 -> {}’.format(a is -6))
b = -5
print(‘-5 -> {}’.format(b is -5))
c = 256
print(‘256 -> {}’.format(c is 256))
d = 257
print(‘257 -> {}’.format(d is 257))
Como resultado, temos:
-6 -> False
-5 -> True
256 -> True
257 -> False
Dessa vez, o resultado é porque, na implementação em C do Python, os inteiros entre -5 e 256 são armazenados em uma array. Assim, quando criamos um int nesse alcance recebemos de volta uma referência para o int já criado na array, em vez de criarmos um novo objeto.
Relações entre == e is
Depois de tantos testes e explicações, entendemos que o fato de == resultar em True para determinadas variáveis não significa que is também retornará o mesmo. Mas como funciona na relação inversa?
Intuitivamente, podemos pensar que todos as operações com is que retornam True também retornam True com ==, afinal se uma variável é outra variável, elas devem ter o mesmo valor (além da mesma identidade).
Em geral, essa ideia está correta, mas não é uma regra, como nos mostra o próprio Python com o valor NaN (Not a Number, não é um número) de tipo float:
a = float(‘nan’)
print(‘is -> {}’.format(a is a))
print(‘== -> {}’.format(a == a))
E o resultado é:
is -> True
== -> False
Conclusão
Nesse post, entendemos a diferença dos comparadores == e is e vimos quando devemos usar cada um deles, concluindo que o operador is deve ser usado sempre e somente quando queremos comparar a identidade de um objeto, isto é, seu endereço na memória.
O ==, por sua vez, deve ser usado quando quisermos comparar valores (ou, na verdade, qualquer outra coisa!) de objetos.
Além disso, analisamos algumas peculiaridades específicas da implementação CPython, tornando mais pleno nosso conhecimento sobre o tópico.
Finalmente matamos essa dúvida, hein? E aí, gostou do conteúdo? Se quiser aprender mais sobre Python, se aprofundando nessa interessante linguagem, dê uma olhada em nossos cursos de Python na Alura!