Impactos da replicação e sharding em grandes volumes de dados
Quando pensamos na arquitetura de sistemas com grande volume de dados a primeira palavra que vem a mente é escalar. Além de desejar que cada uma das pesquisas em nosso sistema execute o mais rápido possível, precisamos criar meios para que, quando necessário, seja fácil adicionar mais recursos (como memória ou novos servidores) e o sistema consiga tirar proveito deles. Para isso muitas vezes precisamos ir além das diversas otimizações de performance e escalabilidade, como por exemplo a criação de um índice para buscas, o uso de caches e de chamadas assíncronas.
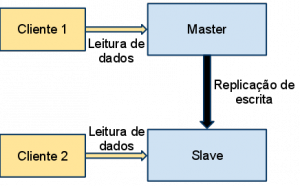
Outras duas abordagens importantes são a replicação e o particionamento horizontal (sharding). A simples ideia por trás da replicação é armazenar cópias dos dados em mais de um lugar. Em bancos de dados ela é tradicionalmente implementada através da criação de uma estrutura master-slave. O banco master é aquele onde são efetuados as alterações, que são então replicadas para o slave.
[](https://blog.caelum.com.br/wp-content/uploads/2010/11/master_slave.png)
Com isso as queries podem ser executadas agora não só em um, mas em dois nós. Quando as máquinas se sobrecarregarem de queries, criamos um novo nó slave que permite aliviar o trabalho das primeiras.
[](https://blog.caelum.com.br/wp-content/uploads/2010/11/master_slave_slave.png)Em uma arquitetura comum onde o banco funciona no esquema master-slaves baseado em replicação, todos os dados estão contidos em todos os nós: a consistência é mantida.
Se um nó de leitura parar de funcionar, não tem problema para as queries pois, todos os outros nós são capazes de responder as mesmas. Mas se o master falhar, as atualizações não funcionam.
[](https://blog.caelum.com.br/wp-content/uploads/2010/11/master_slave_slav_falho.png)Permitir escalar a leitura não aumenta necessariamente a performance percebida pela API: a query pode continuar lenta, mas mais queries podem rodar concorrentemente. Por outro lado, precisamos tomar cuidado na escrita: se a mensagem de atualização do master para os slaves for síncrona para garantir a consistência, o tempo de resposta para uma atualização fica maior.
Nesses casos podemos utilizar uma abordagem onde a replicação de uma atualização ocorre de maneira assíncrona e a consistência passa a ser em momentos indeterminados, mesmo que em banco de dados relacionais.
A replicação de dados nos permite garantir consistência através da redundância deles.
Em outra variação de replicação, qualquer nó pode responder por uma atualização e propagar tal mensagem para os outros: esse cenário é chamado de multi master. Outras variações como baseadas em Gossip podem ajudar a reparar dados que estão inconsistentes em determinado momento.
[](https://blog.caelum.com.br/wp-content/uploads/2010/11/multi_master1.png)Mas a query ainda pode estar lenta, por exemplo, no caso de um full table scan - um sinal forte de que algo está errado no design do armazenamento de seus dados. Nesses casos tentamos dividir a localização física dos dados, despedaçando os mesmos e colocando pedaços deles em nós distintos. Essa prática é conhecida como Sharding (decomposição).
[](https://blog.caelum.com.br/wp-content/uploads/2010/11/sharding_simples.png)A escolha de como dividir esses dados é dada através de um algoritmo de Sharding, que podemos escolher. O diagrama a seguir mostra duas opções para a distribuição dos dados em diversas máquinas:
[](https://blog.caelum.com.br/wp-content/uploads/2010/11/diagramas_sharding.png)Dessa maneira podemos facilmente distribuir a execução de uma query em diversós nós, tornando um full table scan diversos scans a rodarem em paralelo. O sharding pode resolver o problema das queries lentas, no entanto, pode criar outros problemas. Imagine que um dos servidores utilizados nesse Sharding fique momentaneamente fora do ar. Consequência: tais dados ficarão indisponíveis.
Outro problema ocorre quando uma query busca dados em um nó e esse resultado envolve executar queries em outros nós distintos de acordo com cada resultado original, causando lentidão. Por isso, decidir o algoritmo de Sharding depende das queries a serem executadas a fim de fazer essa distribuição da melhor forma possível. Por exemplo, como o Twitter apresentou e o e-bay discutiu sobre tais escolhas em seus ambientes durantes palestras no QCon 2010 em São Paulo.
Para resolver tais problemas, uma solução é misturar o sharding com replicação, ganhando maior disponibilidade, deixando ao algoritmo a decisão de quais nós conterão determinados dados. Esse é um cenário de alta complexidade e por isso mesmo todo cuidado deve ser tomado para só ser adotado quando realmente necessário. Tais situações podem ser suportadas por ferramentas noSQL baseadas no paper do Dynamo, como Cassandra, Riak etc. Cada ferramenta aborda o problema de uma maneira diferente:
"Bayou, Coda and Ficus allow disconnected operations and are resilient to issues such as network partitions and outages." " Dynamo allows read and write operations to continue even during network partitions and resolves updatedconflicts using different conflict resolution mechanisms. "
Arranhando como elas funcionam, quando um nó cai, os outros nos continuam trabalhando. Quando do momento de resolver o conflito, cada um utiliza uma estratégia diferente e permite diferentes abordagens para conciliar os dados conflitantes. Novamente, quanto mais escrita for feita para garantir a replicação, mais lento esse processo e as abordagens de atualização assíncrona podem fazer mais sentido novamente.
[](https://blog.caelum.com.br/wp-content/uploads/2010/11/sharding_replicacao.png)Um nó não precisa necessariamente ser uma cópia de outro nó, bastando que o elemento apareça em no mínimo N nós.
Conclusão
Escalar os dados de uma aplicação é uma tarefa complicada e a solução varia de acordo com o caso.
Fica fácil visualizar como a consistência se mantem em nosso sistema distribuído (eventualmente ou sempre) e como a maneira de executar as queries é alterada de acordo com a nossa necessidade de escalabilidade e performance.
Em alguns casos, simplesmente a replicação pode ser suficiente enquanto em outros pode ser necessário o Sharding ou uma combinação de ambos. Perceber a necessidade, entender como funciona processamento distribuído de dados e encontrar a combinação ideal é o grande desafio que o desenvolvedor ou arquiteto passa.
Agradecimentos ao Alexandre Porcelli pela revisão do artigo antes de sua publicação.