R, Titanic e Data Science

O termo Data Science é uma das buzzwords do momento. Não vou me arriscar a defini-lo pois um post no blog não seria suficiente para definir com clareza o significado desta expressão. O livro Doing Data Science, publicado pela O'Reilly, dedica um capítulo inteiro a definição do termo e a wikipedia já tem um verbete dedicado a isso. O que posso afirmar com segurança é que Data Science envolve um conjunto de técnicas para processar e analisar dados para construir decisões de negócio inteligentes. É uma disciplina que utiliza diversas áreas do conhecimento, desde a estatística descritiva mais simples a complexos algoritmos da inteligência artificial.
Mas como começar a se envolver nessa área, que parece tão interessante mas ao mesmo tempo tão complexa? Nesse post apresentaremos uma introdução prática a esse tema, mãos a obra!
Onde conseguir dados?

Para se aventurar com Data Science precisamos, obviamente, de dados! Existem diversos sites na que oferecem grandes conjuntos de dados de graça. A Amazon Web Services hospeda grandes conjuntos de dados públicos e outra fonte interessante é o infochimps que oferece dados que podem ser baixados ou consultados por meio de uma API.
Neste post utilizaremos dados do Kaggle. Este site hospeda competições de Data Science. Em suas competições, o Kaggle libera dois conjuntos de dados sendo que o competidor tem acesso às respostas para apenas um conjunto dos dados e deve enviar as respostas do segundo. Ao final de um prazo estipulado, o competidor que tiver a maior precisão nas respostas vence a competição. Achou confuso? Ficará mais claro com o exemplo que usaremos nesse post.
A competição que participaremos é a do Titanic. O desafio é: sabendo dados dos passageiros como idade, sexo e classe de viagem, como prever quem teria sobrevivido ao desastre? É claro, essa é uma competição puramente educativa, o Kaggle hospeda competições para iniciantes e competições valendo premiações em dinheiro (nesse momento, existem competições valendo até 100 mil dólares!). Na nossa competição, são fornecidos dois arquivos .csv, no primeiro temos diversos dados pessoais de cada passageiro e sabemos se sobreviveram ou não ao desastre, costuma-se chamar esse conjunto de conjunto de treino. No segundo, temos os mesmos dados pessoais de outros passageiros e devemos definir quais sobreviveram ou não ao Titanic, este é o conjunto de teste e apenas o Kaggle tem as respostas para estes passageiros. O competidor que tiver a maior taxa de acerto no conjunto de teste vencerá a competição no dia 31 de dezembro.
Mão na massa!
Primeiro, faça uma conta no Kaggle e baixe os dois arquivos de dados da competição. Para analisar os dados utilizaremos o R. Esta linguagem foi idealizada para desenvolver programas voltados à estatística e já foi introduzida em um post anterior. A vantagem de utilizar o R é que podemos analisar facilmente os dados da competição e tirar conclusões rapidamente. Além disso, de acordo com uma pesquisa da a O'Reilly, é a linguagem mais usada em Data Science, então estamos no caminho certo!
Agora, vamos ler os dados do conjunto de treino e de teste:
> treino <- read.csv("train.csv") > teste <- read.csv("test.csv")
A função read.csv recebe o caminho para um arquivo csv, lê o conteúdo do arquivo e devolve um data frame, que é um objeto que representa os dados de uma tabela. Neste post, cada linha se iniciando com ">" é instrução que pode ser executada no shell do R de forma interativa, ou escritos em um script com um editor de texto.
Para ter uma ideia do conteúdo do data frame podemos usar algumas funções exploratórias do R, como a função names, que devolve as colunas de um data frame:
> names(treino) [1] "PassengerId" "Survived" "Pclass" "Name" "Sex" "Age" [7] "SibSp" "Parch" "Ticket" "Fare" "Cabin" "Embarked"
O resultado desta função é um array onde cada elemento é o nome de uma coluna do data frame. Podemos acessar todos os valores de uma coluna usando o operador $:
> treino$Survived [1] 0 1 1 1 0 0 0 0 1 1 1 1 0 0 0 1 0 1 0 1 0 1 1 1 0 1 0 0 1 0 0 1 1 0 0 0 1 0 0 1 0 0 0 [44] 1 1 0 0 1 0 0 0 0 1 1 0 1 1 0 1 0 0 1 0 0 0 1 1 0 1 0 0 0 0 0 1 0 0 0 1 1 0 1 1 0 1 1 ...
Vamos começar a explorar os nossos dados. Quantos passageiros sobreviveram ao desastre?
> table(treino$Survived) 0 1 549 342
A função table calcula o número de valores diferentes em um array. Podemos ver que a maioria dos passageiros no conjunto de treino morreram (549), o que já era esperado. Para ter uma ideia da proporção dos passageiros que morreram, podemos usar a função prop.table:
> prop.table(table(treino$Survived)) 0 1 0.6161616 0.3838384
Portanto, aproximadamente 61% dos passageiros do conjunto de teste não sobreviveram ao desastre. Com isso, faremos a nossa primeira submissão ao desafio do Kaggle. Como a maioria dos passageiros não sobreviveram, podemos submeter a solução mais simples, em que nenhum passageiro sobrevive! A submissão deve ser feita por meio de um csv com duas colunas, com o id do passageiro do conjunto de teste e a previsão de seu futuro no desastre:
> submissao <- data.frame(PassengerId=teste$PassengerId, Survived=0) > write.csv(submissao, file="primeira_tentativa.csv", row.names=FALSE)
Para criar o csv com a submissão, criamos um novo data frame com as colunas PassengerId e Survived e escrevemos o csv no sistema de arquivos. Agora basta submeter nosso arquivo submissao.csv pela interface do Kaggle. O site compara a nossa submissão com as respostas corretas e exibe o resultado:

Conseguimos uma taxa de acerto de aproximadamente 62%, o que faz bastante sentido já que a taxa de passageiros que não sobreviveram no nosso conjunto de treino é de 61%. Parece ruim? Pois é ruim mesmo, mas repare que mesmo com uma estratégia tão simples já estamos à frente de alguns competidores!
Segunda tentativa
Agora podemos aplicar um pouco de conhecimento do domínio do nosso problema. Esse é um ponto importante, não basta simplesmente aplicar algum algoritmo que faça a mágica, sempre será necessário ter algum conhecimento sobre os domínio dos dados que estamos manipulando. Nesse caso o domínio é bem simples: um desastre em um navio. Quais passageiros teriam prioridade de acesso aos botes de emergência? Seguindo o bom senso, seria natural supor que as mulheres e crianças tiveram preferência no momento de salvação, mas será que os dados do Titanic comprovam essa suposição? Vamos separar os passageiros por sexo:
> homens <- treino[treino$Sex == "male", ] > mulheres <- treino[treino$Sex == "female", ]
Com isso temos dois data frames novos e agora podemos analisar essas categorias de passageiros separadamente:
`> prop.table(table(homens$Survived)) 0 1 0.8110919 0.1889081
prop.table(table(mulheres$Survived)) 0 1 0.2579618 0.7420382`
Portanto, podemos ver que apenas 18% dos homens sobreviveram enquanto esse número é muito maior para as mulheres, 74%!
Vamos analisar agora os passageiros com idade abaixo de 5 anos. Primeiro, precisamos corrigir nosso conjunto de treino pois nem todos os passageiros tem suas idades definidas. Podemos preencher os valores em branco com a média da idade dos passageiros (o que é uma aproximação grosseira, mas é uma boa tentativa inicial):
> passageiros.com.idade <- treino[!is.na(treino$Age),] > idade.media <- mean(passageiros.com.idade$Age)
Agora vamos colocar a idade média no nosso data frame e selecionar os passageiros com menos de 5 anos:
> treino[is.na(treino$Age), ]$Age <- idade.media > criancas <- treino[treino$Age < 5, ]
Será que a maioria das crianças também foram salvas do desastre?
> prop.table(table(criancas$Survived)) 0 1 0.325 0.675
De acordo com nossos dados de treino, 61% dos passageiros com menos de 5 anos se salvaram ao desastre!
Agora podemos construir uma estratégia mais inteligente e fazer nossa segunda submissão. Uma aproximação muito mais realista seria supor que todos as crianças e mulheres se salvaram. Vamos construir nossa segunda submissão usando esta estratégia:
> teste[is.na(teste$Age), ]$Age <- idade.media > teste$Survived <- 0 > teste[teste$Sex=="female",]$Survived <- 1 > teste[teste$Age < 5,]$Survived <- 1 > submissao <- data.frame(PassengerId=teste$PassengerId, Survived=teste$Survived) > write.csv(submissao, file="segunda_tentativa.csv", row.names=FALSE)
Submetendo o novo csv ao Kaggle conseguimos um resultado muito melhor, 76% de precisão!

Entra o Machine Learning
Mas será que 5 anos de idade é mesmo o melhor limiar para a idade? Será que esse é o valor que melhor separa os que sobreviveram dos que morreram no nosso conjunto? Além disso, e os outros atributos? Será que o preço da passagem também é determinante para o destino de um passageiro no acidente? E quanto a classe da passagem, será que os passageiros da primeira classe tiveram maiores chances de sobrevivência? Poderíamos construir regras mais inteligentes, combinando os atributos. Por exemplo:
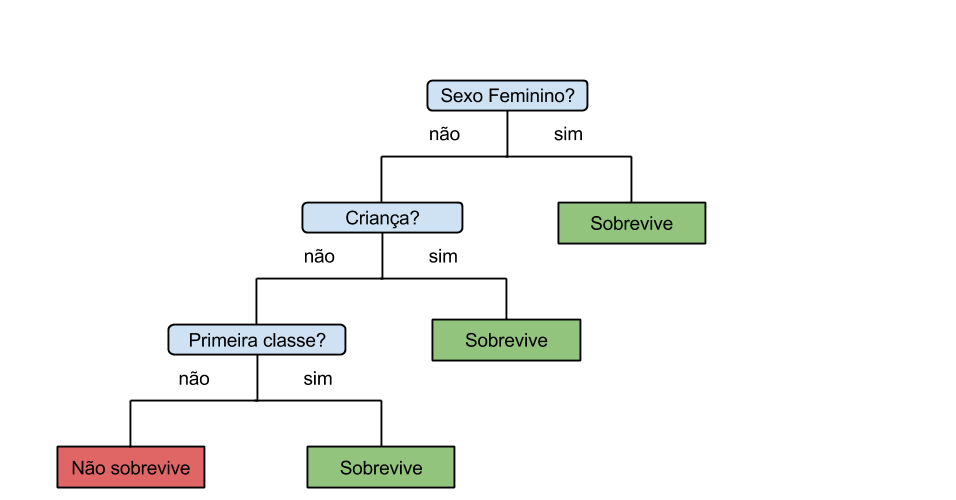
Esta figura é a representação de um estrutura chamada de árvore de decisão. Uma árvore de decisão nos permite representar regras para tomar decisões. Na nossa segunda tentativa, acabamos criando indiretamente uma árvore de decisão mais simples:
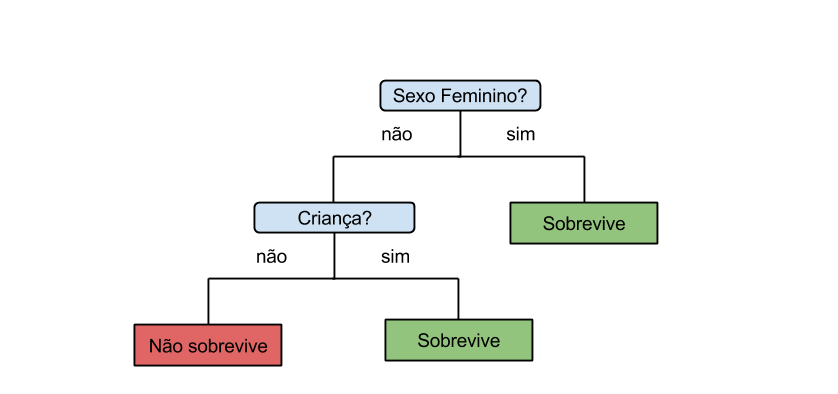
Poderíamos gastar um bom tempo analisando cada um dos atributos e buscar quais são os valores que melhor separam os passageiros que sobreviveram, porém seria muito trabalhoso testar a quantidade imensa de combinações. Para a nossa sorte, existe um algoritmo da Inteligência Artificial que constrói a árvore de decisões a partir dos atributos que desejar e já existe uma implementação para o R! O algoritmo não percorre todas as possibilidades (esta estratégia seria muito lenta caso o número de atributos fosse muito grande) mas consegue encontrar uma resposta boa rapidamente.
Para usar a implementação no R precisamos instalar o pacote rpart. O ecossistema do R possui uma quantidade imensa de pacotes que podem ser instalados dentro do próprio shell, com a função install.packages:
> install.packages("rpart") > library(rpart)
A função library carrega um pacote dentro de um script R. Agora, podemos utilizar a função rpart:
> arvore <- rpart(Survived ~ Age + Sex + Pclass + Fare, data=treino, method="class")
No primeiro argumento, definimos uma fórmula especificando quais são os atributos que o algoritmo vai considerar para construir a árvore de decisões. Neste caso, o algoritmo vai utilizar a idade, sexo, classe de viagem e o preço da passagem para construir a árvore. Além disso definimos a estratégia que será usada para construir a árvore, como queremos classificar os passageiros em categorias (se sobrevive ou não), especificamos method="class".
Podemos ver a árvore resultante, imprimindo o objeto:
> print(arvore) n= 891 node), split, n, loss, yval, (yprob) * denotes terminal node 1) root 891 342 0 (0.61616162 0.38383838) 2) Sex=male 577 109 0 (0.81109185 0.18890815) 4) Age>=6.5 553 93 0 (0.83182640 0.16817360) * ...
É difícil interpretar esta representação em texto da árvore construída. Podemos obter uma representação gráfica da árvore usando outros pacotes do R:
> install.packages("rattle") > install.packages("RColorBrewer") > library(rattle) > library(RColorBrewer) > fancyRpartPlot(arvore)
Que resulta na seguinte figura:
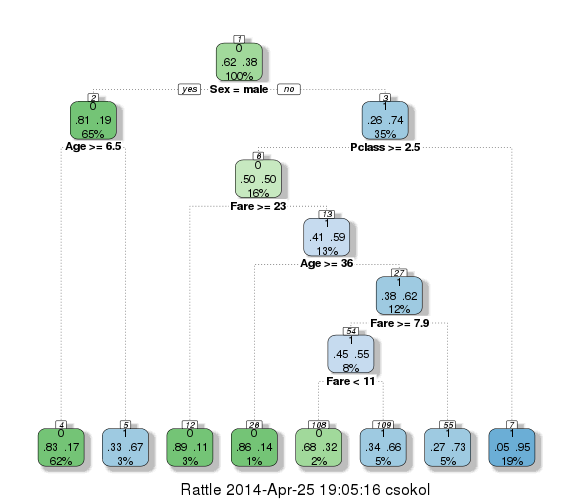
Nesta representação, cada nó interno representa uma divisão entre os passageiros a partir do valor de um atributo. Cada nó final especifica a categoria que a árvore atribuirá a um passageiro que cair naquele nó. Por exemplo, no nó final da extrema esquerda, podemos observar que passageiros do sexo masculino com idade maior ou igual a 6.5 serão classificados com 0 (ou seja, não sobrevivem). Já passageiros do sexo masculino com idade menor que 6.5 seriam classificados com 1. Repare que o algoritmo encontrou algumas relações não tão triviais, como por exemplo: mulheres viajando na primeira ou segunda classe são classificadas com 1, enquanto as de terceira classe que pagaram menos que 23 são classificadas com 0.
Agora, vamos usar essa árvore para fazer as previsões sobre os dados de teste e gerar o csv e construir uma nova submissão, usando a função predict:
> submissao = data.frame(PassengerId=teste$PassengerId, Survived=teste$Survived) > previsao = predict(arvore, teste, type="class") > submissao$Survived = previsao > write.csv(submissao, file="terceira_tentativa.csv", row.names=FALSE)
Submetendo o novo arquivo ao Kaggle, obtemos uma precisão de 77%:

Melhoramos menos que 1%, o que mostra que utilizar a técnica mais complexa nem sempre traz grandes resultados. Mas repare que subimos mais de 200 posições no ranking! Para melhorar nossa performance, o passo seguinte seria limpar nossos dados, a informação da idade dos passageiros parece muito importante para o nosso modelo e a aproximação que fizemos pela média é imprecisa.
Em resumo, data science é uma área interessante e vai muito além de aplicar bons algoritmos de Machine Learning. Inspencionar e limpar os dados é extremamente importante, além do conhecimento do domínio que estamos investigando. Misturar estas técnicas corretamente é o que faz a diferença nessa competição do Kaggle e o que faria a diferença, por exemplo, em um sistema de recomendação real.
Nota: este post foi baseado fortemente nesta série de posts de Trevor Stephens e neste markdown de Curt Wehrley.