

Empresas como Amazon, Google, Microsoft, entre outras, fornecem parte da infraestrutura que já possuem para que nós usuários possamos utilizar em nossos projetos. Sendo assim, nesse artigo, vamos explorar os serviços da Amazon AWS.
Após meses de desenvolvimento em nosso projeto de e-commerce de livros de tecnologia, feito com o framework do Spring MVC, chegou o momento de levar esse nosso projeto para o ambiente de produção para que os usuários possam acessar nossa aplicação.
Para disponibilizar esse projeto na internet, precisamos de servidores, equipamentos de rede, alocação de endereços IP, etc, porém acaba sendo um custo muito elevado para nós, não é mesmo?
Dessa forma, justamente visando eliminar essa barreira inicial de investimento, empresas como Amazon, Google, Microsoft, entre outras, fornecem parte da infraestrutura que já possuem para que nós usuários possamos utilizar em nossos projetos. Sendo assim, nesse post, vamos explorar os serviços da Amazon AWS.
Cadastrando um livro
Nosso projeto tem como objetivo que os administradores da plataforma façam o cadastro dos livros, para que posteriormente esses livros estejam disponibilizados na home da aplicação, fazendo assim com que todos os usuários possam visualizar os produtos que oferecemos e, eventualmente, realizar a compra desses livros.
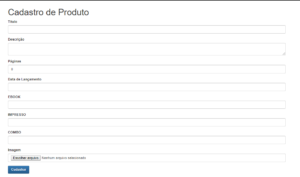
Em nossa página de cadastro de produto, devemos inserir informações do livro, como título, descrição, quantidade de páginas e valores dos livros, que são informações de texto e deverão ser persistidas diretamente no banco de dados.
Repare que temos também que cadastrar a imagem da capa do livro. Mas e agora, como faremos o tratamento dessa imagem?
Para armazenar imagens diretamente em um banco de dados serão necessárias linhas adicionais de código para realizar essa manipulação, além de podermos vir a ter alguns problemas de performance, será que existe outra forma de armazenar essas imagens sem ser no banco de dados?
Vamos usar então a infraestrutura da Amazon AWS para realizar o armazenamento das imagens das capas dos livros, mais precisamente o serviço Simple Storage Service, popularmente conhecido pela abreviação S3.

Utilizando o serviço S3
O primeiro passo para utilizarmos os serviços da Amazon AWS é acessar o endereço e criar a conta de acesso.
A Amazon AWS permite até o momento de escrita desse post, que os usuários utilizem determinados serviços gratuitamente por 12 meses, respeitando os limites mensais de uso de cada serviço.
Caso deseje ter mais informações sobre os limites de uso e os serviços que estão dentro desse limite gratuito de 12 meses, acesse esse link. O serviço Simple Storage Service (S3) está dentro desse limite de uso gratuito e poderemos utilizá-lo para nosso teste.
Uma vez que terminamos o processo de criação de conta na Amazon AWS, seremos redirecionados para o painel inicial onde temos uma lista com os vários serviços disponíveis. Na aba de Storage seremos capazes de visualizar o serviço do S3.
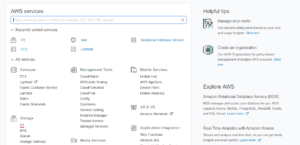
Ao sermos redirecionados para o painel de console do serviço S3, nós devemos criar o repositório (Bucket) que será responsável por armazenar as imagens de nossa aplicação. Para isso, clicamos no botão Create bucket.
Ao clicarmos no botão Create bucket, deveremos especificar um nome de identificação desse Bucket, o nome do Bucket deverá ser único em todo o ambiente da Amazon. Vamos escolher por exemplo, o nome imagens-livros-casadocodigo

Legal, especificamos o nome do Bucket, mas em que local esse Bucket será criado e nossos arquivos serão armazenados? Não falamos isso ainda, não é mesmo? Precisamos selecionar uma região de presença da Amazon AWS para poder criar o Bucket e armazenar esses arquivos. Vamos escolher, por exemplo, uma região aleatória, a região do Norte da Virgínia, nos Estados Unidos.

Feito isso, nós deveremos ter o Bucket com o nome imagens-livros-casadocodigo configurado na região Norte da Virgínia, nos Estados Unidos pronto para receber as imagens dos livros.

Mas, e agora? Imagine se qualquer pessoa ou aplicação pudesse acessar esse Bucket para enviar arquivos, não seria nada bom, não é mesmo?
Nós queremos que nosso projeto de e-commerce seja o único com a permissão necessária de realizar o acesso a esse Bucket para enviar as imagens das capas dos livros. Isto é, teremos que mexer nas permissões de acesso.
Configurando permissões de acesso
Nós temos agora o Bucket configurado para receber as imagens das capas dos livros que serão cadastradas, porém para que nossa aplicação acesse esse Bucket para enviar as imagens dos livros é necessário configurarmos as devidas credenciais concedendo essa permissão. Fazemos isso através do serviço Idendity and Access Management, Idendity and Access Management, IAM.
Ao sermos redirecionados para a configuração do serviço de IAM, o primeiro passo será criar um usuário, o qual teremos que dar um nome para esse usuário, vamos dar por exemplo o nome acesso_s3, e informamos na sequência que esse usuário irá acessar os serviços da Amazon através de um programa, opção Programmatic Access.
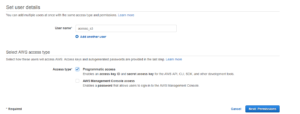
Ótimo, nós já informamos o nome desse usuário bem como a forma que irá interagir com os serviços da Amazon, mas ainda não falamos que esse usuário terá permissão de acessar o serviço S3 da Amazon, devemos, portanto, vincular essa política de acesso.
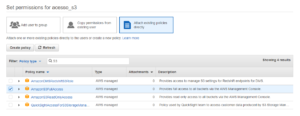
Ao final dessa etapa de criação do usuário, a Amazon irá fornecer para nós duas credenciais: um identificador de acesso nomeado como access key e uma chave de segredo nomeada como secret access key.

Agora que temos posse dessas credenciais devemos configurar nosso projeto para que faça uso dessas credenciais e seja possível enviar as imagens das capas dos livros.
Configurando integração com a Amazon AWS
Agora que temos o Bucket criado no serviço do S3 e as credenciais de acesso para esse Bucket, devemos fazer a configuração em nosso projeto para que seja possível realizar a integração com os serviços da Amazon, enviando as imagens dos livros.
Para realizar essa integração do projeto desenvolvido com o framework do Spring MVC com os serviços da Amazon, iremos adicionar uma dependência em nosso projeto.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-context</artifactId>
<version>1.2.1.RELEASE</version>
</dependency>
Uma vez adicionada essa dependência em nosso projeto, poderemos montar uma classe de configuração para que usemos as credenciais de acesso, vamos montar a classe de configuração chamada AmazonConfiguration.
Para utilizar as credenciais de acesso ao Bucket, vamos colocar um método nessa classe que deverá retornar um objeto do tipo BasicAWSCredentials que espera receber no construtor justamente o identificador de acesso e a chave de segredo que nós possuímos.
@Configuration
public class AmazonConfiguration {
private static final String ACCESS_KEY="[Minha chave de acesso]";
private static final String SECRET_KEY="[Minha chave de segredo]";
private static final String REGION="us-east-1";
@Bean
public BasicAWSCredentials basicAWSCredentials(){
return new BasicAWSCredentials(ACCESS_KEY, SECRET_KEY);
}
}
Nesse momento, configuramos que esse método irá retornar um objeto do tipo BasicAWSCredentials com a devida permissão de acesso ao Bucket. Falta nós criarmos o objeto do tipo AmazonS3 para que possamos posteriormente utilizar os métodos para enviar as imagens das capas dos livros.
Na construção desse objeto AmazonS3, precisaremos informar o código de identificação dessa região Norte da Virgínia (onde nosso Bucket foi criado) juntamente com as credenciais de acesso que foram configuradas no método basicAWSCredentials() que acabamos de criar. Ao final, nossa classe AmazonConfiguration deverá ter ficado dessa forma
@Configuration
public class AmazonConfiguration {
private static final String ACCESS_KEY="[Minha chave de acesso]";
private static final String SECRET_KEY="[Minha chave de segredo]";
private static final String REGION="us-east-1";
@Bean
public BasicAWSCredentials basicAWSCredentials(){
return new BasicAWSCredentials(ACCESS_KEY, SECRET_KEY);
}
}
@Bean
public AmazonS3 amazonS3() {
return AmazonS3ClientBuilder.standard().withRegion(REGION)
.withCredentials(new AWSStaticCredentialsProvider(basicAWSCredentials())).build();
}
}
Tendo o arquivo de configuração finalizado, devemos ir até a classe do projeto responsável pelo tratamento das imagens e fazer o uso dos métodos para enviar os arquivos para o Bucket que criamos.
Configurando classe de tratamento de imagens
Vamos até a classe de nosso projeto responsável pelo tratamento das imagens, chamada FileSaver e pedir para o Spring fazer a injeção do objeto do tipo AmazonS3 que configuramos na classe AmazonConfiguration
@Autowired
private AmazonS3 amazonS3;
Com isso, poderemos chamar o método putObject para fazer o envio das imagens para o Bucket. O primeiro argumento desse método espera receber um objeto do tipo PutObjetctRequest, onde deveremos passar as informações do nome do Bucket, nome com o qual o arquivo deverá ser salvo no Bucket, o fluxo de dados que compõem o arquivo e metadados de informação, caso seja necessário.
@Autowired
private AmazonS3 amazonS3;
private static final String BUCKET="[Nome do Bucket que criamos]";
public String write(MultipartFile file) {
try {
amazonS3.putObject(new PutObjectRequest(BUCKET,
file.getOriginalFilename(), file.getInputStream(),null)
Por padrão, quando um arquivo é enviado para o Bucket, esse arquivo possui uma visibilidade privada e com isso nenhum usuário que for acessar a aplicação será capaz de visualizar a imagem das capas dos livros.
Dessa forma, nós precisamos alterar a visibilidade desses arquivos para que a leitura seja pública, ou seja, qualquer usuário que tiver a URL de acesso, conseguirá visualizar as imagens das capas dos livros.
Para isso, devemos chamar o método withCannedAcl e passar como argumento desse método uma ENUM de leitura pública, com isso, quando as imagens dos livros forem cadastradas no Bucket, terão uma visibilidade pública de leitura e todos os usuários irão conseguir visualizar as imagens.
withCannedAcl(CannedAccessControlList.PublicRead));
Agora que as imagens das capas dos livros foram passadas para o Bucket, esse nosso método deverá retornar justamente a URL de acesso de cada uma dessas imagens para que seja persistida no banco de dados, com as demais informações que compõem o livro.
Por padrão, os arquivos dentro de um Bucket na Amazon seguem a seguinte estrutura de acesso:
- http://s3.amazonaws.com/ [Nome do Bucket] / [Nome do arquivo]. Colocamos então:
return "http://s3.amazonaws.com/"+BUCKET+"/"+file.getOriginalFilename();
Com isso, nossa classe final responsável pelo tratamento das imagens cadastradas deverá ter ficado dessa forma
@Component
public class FileSaver {
@Autowired
private AmazonS3 amazonS3;
private static final String BUCKET="[Nome do Bucket que criamos]";
public String write(MultipartFile file) {
try {
amazonS3.putObject(new PutObjectRequest(BUCKET,
file.getOriginalFilename(), file.getInputStream(),null)
.withCannedAcl(CannedAccessControlList.PublicRead));
return "http://s3.amazonaws.com/"+BUCKET+"/"+file.getOriginalFilename();
} catch (IllegalStateException | IOException e) {
throw new RuntimeException(e);
}
}
}
Analisando resultados
Nós fizemos as configurações necessárias em nosso projeto para enviar as imagens das capas dos livros, falta somente nós testarmos a aplicação e ver se de fato as imagens estão sendo enviadas para o Bucket e se conseguimos visualizar as imagens em nossa aplicação. Para esse teste, iremos utilizar a imagem do livro Algoritmos em Java do autor Guilherme Silveira.
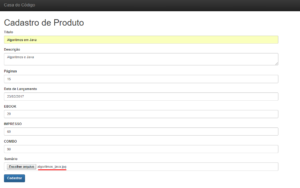
O que esperamos nesse momento é que ao clicarmos no botão Cadastrar, a imagem do livro seja passada para o Bucket que configuramos no serviço do S3 e que possamos visualizar essa imagem na home da aplicação.

Veja que temos aqui justamente a informação que o livro foi cadastrado com sucesso, vamos conferir se a imagem do livro está no Bucket que configuramos na Amazon?
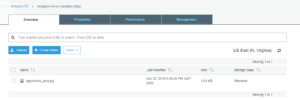
Vejam só o resultado, agora nesse Bucket temos justamente um arquivo com nome algoritmos_java.jpg, que é justamente a imagem do livro que cadastramos, será que se formos na home de nossa aplicação, conseguiremos visualizar a imagem do livro cadastrado?
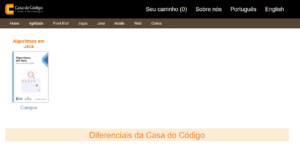
Olha só!! Conseguimos ter a imagem do livro que cadastramos sendo disponibilizada na aplicação, com isso, todos os usuários da internet que forem acessar a home serão capazes de visualizar as informações dos livros que acabamos de cadastrar.
Você pode encontrar a versão final do projeto com as alterações nesse link.
Gostaria de aprender mais sobre a Amazon AWS e Cloud Computing? Na Alura temos cursos especialmente sobre Cloud Computing