

No contexto da era da informação, empresas lidam diariamente com grandes volumes de dados gerados por diferentes fontes, como transações comerciais, interações de clientes e atividades operacionais.
O desafio é que esses dados, muitas vezes desorganizados e heterogêneos, dificultam a extração de insights valiosos para a tomada de decisões estratégicas.
Esse cenário gera a necessidade de uma abordagem estruturada para gerenciar e processar essas informações de forma eficiente.
Principalmente para os Engenheiros de Dados, o problema principal reside na falta de um sistema unificado para lidar com diferentes tipos de dados, desde dados brutos até informações refinadas prontas para análise.
Sem uma estratégia clara de gerenciamento de dados, as empresas correm o risco de enfrentar redundâncias, inconsistências e dificuldades na obtenção de uma visão holística de seus negócios.
Além disso, a falta de processos padronizados de transformação e análise de dados pode resultar em insights imprecisos ou incompletos.
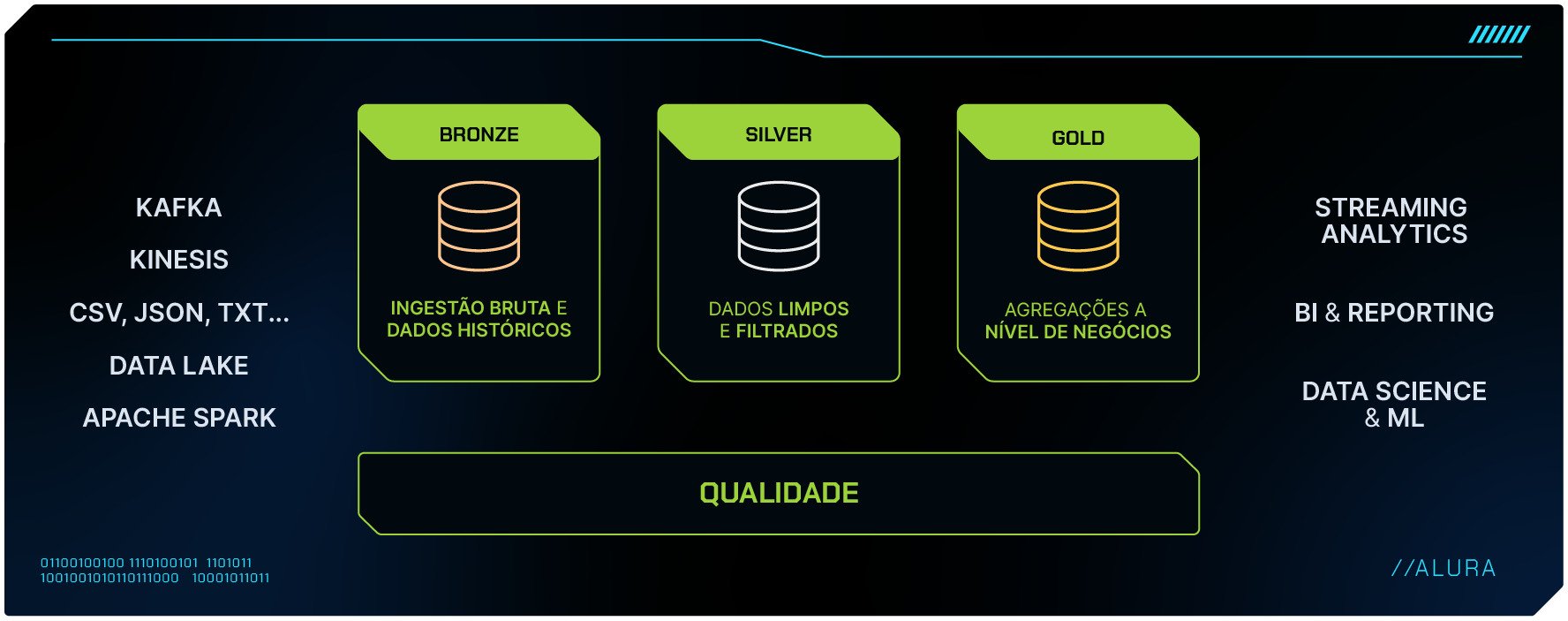
A solução para esses desafios é a implementação de uma abordagem em três camadas: System of Record (SoR), System of Transformation (SoT) e Specialized Processing Engines (SPEC), também conhecidas como camadas bronze, silver e gold.
A SoR é a base onde os dados brutos são armazenados. A SoT transforma esses dados em informações úteis, enquanto o SPEC aplica análises avançadas.
Cada camada tem suas vantagens e desafios. Quando bem integradas, oferecem uma base sólida para a tomada de decisões e inovação.
Essa abordagem em camadas permite que as empresas gerenciem seus dados de maneira eficiente, desde a coleta inicial até a geração de insights acionáveis.
Ao adotar um SoR, SoT e SPEC bem integrados, as organizações podem melhorar a qualidade dos dados, otimizar processos de análise e tomar decisões mais informadas e estratégicas para impulsionar o sucesso do negócio.
O que é SoR, SoT, Spec?
A camada SoR atua como a camada base, onde os dados brutos são armazenados em sua forma original, geralmente em sistemas de banco de dados ou repositórios de dados.
Esta camada é essencial para garantir a integridade e a durabilidade dos dados e é comumente utilizada em cenários onde é necessário preservar o registro original das informações, como transações financeiras ou registros de clientes.
A camada SoT entra em ação para processar e transformar os dados brutos coletados pelo SoR em informações úteis e acionáveis.
Isso envolve operações de limpeza, normalização, agregação e enriquecimento de dados, preparando-os para análises posteriores.
O SoT é frequentemente utilizado em situações onde os dados precisam ser organizados e estruturados de forma consistente para suportar análises de negócios ou para alimentar sistemas de relatórios e dashboards.
Por fim, a camada SPEC representa a etapa avançada do processamento de dados, onde são aplicadas técnicas de análise avançada, como aprendizado de máquina, processamento de linguagem natural ou análise de séries temporais.
Esta camada é particularmente útil em cenários onde é necessário extrair insights mais profundos dos dados ou automatizar tarefas complexas, como detecção de fraudes, recomendações personalizadas ou previsão de demanda.
Integração entre as camadas
A integração das camadas SoR, SoT e SPEC é fundamental para garantir um fluxo de dados contínuo e eficiente ao longo do ciclo de vida dos dados.
Essa integração assegura que os dados sejam coletados, transformados e analisados de maneira coordenada e eficaz, permitindo que as organizações obtenham insights valiosos para a tomada de decisões.
O processo começa com a SoR, que coleta e armazena os dados brutos de várias fontes internas e externas.
A seguir, os dados são transmitidos para a camada SoT, onde passam por processos de transformação.
Aqui, os dados brutos são limpos, normalizados e agregados conforme as regras de negócios específicas da organização. Após a transformação, os dados chegam à camada SPEC, onde são submetidos a análises avançadas.
Essa camada permite automatizar decisões complexas e descobrir padrões que podem não ser visíveis de outra forma.
A integração eficiente entre essas camadas depende de uma infraestrutura bem planejada e de ferramentas adequadas que facilitam a transferência e transformação dos dados.
Ferramentas de ETL (Extract, Transform, Load) desempenham um papel crucial na movimentação de dados entre as camadas SoR e SoT, enquanto plataformas de análise de dados e machine learning são essenciais para a camada SPEC.
Aplicação em Data Lakes
A aplicação das camadas SoT, SoT e SPEC em Data Lakes é essencial para garantir a organização, transformação e análise eficazes dos dados, proporcionando uma estrutura robusta e escalável para o gerenciamento de grandes volumes de informações.
A integração dessas três camadas em um Data Lake permite uma gestão de dados mais eficiente e estruturada.
Cada camada adiciona valor aos dados, desde a coleta inicial até a análise avançada, assegurando que os dados estejam sempre prontos para gerar insights significativos.
Isso é particularmente importante em ambientes de big data, onde o volume, a variedade e a velocidade dos dados podem tornar a gestão e a análise desafiadoras.
Com SoR, SoT e SPEC, os Data Lakes podem suportar não apenas o armazenamento massivo de dados, mas também a sua transformação e análise em tempo real, proporcionando uma vantagem competitiva significativa para as organizações.
Desafios na implementação
Implementar a estrutura das camadas SoR, SoT e SPEC em uma organização pode apresentar vários desafios que precisam ser cuidadosamente gerenciados para garantir o sucesso do projeto.
Um dos principais desafios é a integração de sistemas legados. Muitas organizações já possuem sistemas estabelecidos que armazenam e gerenciam dados de maneiras específicas. Integrar esses sistemas com a nova estrutura pode ser complexo e exigir significativas modificações de software e infraestrutura.
Além disso, a migração de dados dos sistemas legados para os novos repositórios do SoR pode ser um processo arriscado, propenso a erros e demorado.
Outro desafio significativo é a qualidade dos dados. Dados brutos armazenados no SoR frequentemente contêm inconsistências, duplicações e erros. Garantir que os dados sejam limpos e normalizados durante o estágio SoT é uma tarefa complexa e contínua.
Ferramentas e processos robustos de transformação de dados são necessários para garantir que os dados resultantes sejam precisos e úteis para análises avançadas na camada SPEC.
A gestão da mudança organizacional também é crítica. A implementação dessas camadas muitas vezes requer uma mudança significativa na maneira como os dados são gerenciados e utilizados dentro da organização.
Isso pode encontrar resistência por parte dos funcionários acostumados aos processos antigos. Treinamento adequado e comunicação clara sobre os benefícios da nova estrutura são essenciais para obter a adesão e colaboração de toda a equipe.
Escalabilidade é outro desafio a ser considerado. À medida que a quantidade de dados cresce, a infraestrutura deve ser capaz de escalar para acomodar o aumento do volume de dados sem perder desempenho.
Isso inclui não apenas armazenamento adicional para o SoR, mas também capacidade de processamento para o SoT e ferramentas analíticas avançadas para o SPEC.
Finalmente, há o desafio da segurança e conformidade. Proteger os dados em todas as camadas é vital para evitar violações e garantir a conformidade com regulamentações como GDPR e LGPD.
Isso exige implementar controles de segurança rigorosos, como criptografia, controles de acesso e monitoramento contínuo, além de garantir que todos os processos de transformação e análise de dados estejam em conformidade com as normas regulatórias.
Superar esses desafios requer uma abordagem bem planejada e estratégica, com investimentos adequados em tecnologia, processos e pessoas.
Uma implementação bem-sucedida dessas camadas pode transformar a maneira como os dados são gerenciados e utilizados, proporcionando uma base sólida para decisões mais informadas e estratégias de negócios mais eficazes.
Resumo das camadas SoR, SoT e SPEC


Conclusão
A utilização das camadas SoR, SoT e SPEC no contexto de Engenharia de Dados proporciona uma estrutura robusta e eficiente para a coleta, transformação e análise de dados.
Esta abordagem segmentada facilita a gestão descentralizada dos dados, melhora a governança e promove a escalabilidade.
Assim, as organizações podem transformar grandes volumes de dados em informações acionáveis, impulsionando a inovação e a tomada de decisões estratégicas.
