Trabalhando com Relacionamentos: bancos de dados baseados em grafos e o Neo4j
Ao desenvolvermos uma aplicação, geralmente nos deparamos com a situação de trabalharmos com o banco de dados relacional, realizando diversas queries complexas. Tais queries podem possuir essa complexidade devido ao fato de estarmos modelando dados que não são naturais ao paradigma relacional, em um banco relacional.
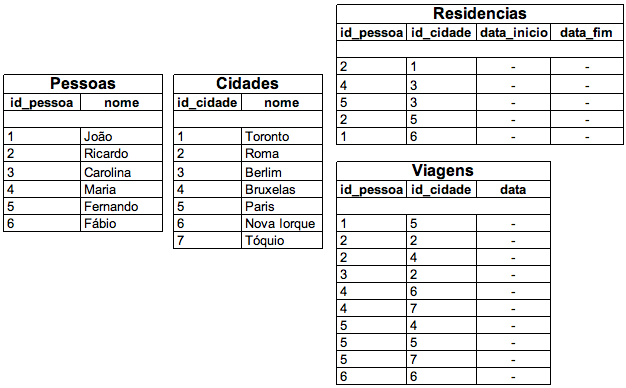
Imagine uma aplicação que deve manter as informações relativas a viagens e locais onde pessoas moraram. Com isso, deve ser possível saber quando uma pessoa viajou ou qual o período em que ela viveu em determinada cidade. Modelando esse problema em um banco de dados relacional, podemos chegar à seguinte estrutura de tabelas e seus respectivos dados: ```caption id="attachment_4457" align="aligncenter" width="550" caption="Tabelas com dados de viagens e residências (datas abreviadas por efeito de simplicidade)"

Com essa estrutura de tabelas, podemos realizar consultas, como por exemplo, procurar quais foram as pessoas que viajaram para o mesmo lugar que o `Ricardo`. Uma possibilidade para buscar essas informações do banco de dados seria a seguinte query SQL:
```sourcecode language="sql"
select distinct(v.id\_pessoa), p.nome from viagens v inner join pessoas p on ( v.id\_pessoa = p.id ) where v.id\_cidade in ( select viagens\_sub.id\_cidade from viagens viagens\_sub where viagens\_sub.id\_pessoa = 2 ) and v.id\_pessoa <> 2; 
Nesse caso, como não devemos retornar a próprio Ricardo, que é o ponto de partida da nossa consulta, o ignoramos com o filtro id <> 2.
Apesar de ser uma consulta realizada em dois passos (pois contém sub-selects), primeiro buscando as cidades as quais ele passou e em seguida descobrindo quem foi para essas cidades, a pesquisa não é difícil de ser realizada.
No entanto, quando o requisito é saber "por quais cidades passaram (seja morando ou viajando) as pessoas que passaram por Roma" a consulta já não é mais trivial de ser desenvolvida, podendo exigir diversos joins e subqueries que poderão tornar a consulta de extrema complexidade e muito pouco performática.
Modelando o mesmo problema de maneira diferente: Grafos
A aplicação modelada anteriormente pode ser remodelada através de grafos, onde teríamos um similar à imagem abaixo:
Analisando o grafo, se quisermos saber quem viajou para o mesmo lugar que o Ricardo, basta descobrirmos os relacionamentos de saída dele, que sejam do tipo VIAJOU, com isso, temos as cidades pelas quais o Ricardo viajou.
Em seguida, a partir de cada cidade, precisamos dos relacionamentos de entrada, que também sejam do tipo VIAJOU e com isso temos as pessoas que viajaram para os mesmos lugares que o Ricardo.
Podemos também realizar a complexa pesquisa sugerida anteriormente, para saber por onde passaram (morando ou viajando) as pessoas que passaram por Nova Iorque. Novamente, podemos percorrer o grafo tendo como ponto de partida Nova Iorque, porém, agora percorrendo os dois tipos de relacionamentos (MOROU e VIAJOU) de chegada à cidade. Com isso, teremos as pessoas.
A partir das pessoas, precisamos dos seus relacionamentos de saída. Neste momento, teremos todos os lugares que foram viajados ou morados por quem já passou por Nova Iorque.
Banco de dados baseados em grafos e o Neo4j
Os bancos de dados relacionais não permitem que os dados sejam representados através de grafos de uma maneira natural, com isso, algumas pesquisas se tornam extremamente complexas, ou até mesmo impraticáveis nos bancos de dados relacionais, que é justamente o caso da consulta exemplificada anteriormente. Navegando pela estrutura do grafo, conseguimos facilmente os resultados os quais queríamos.
Com a popularização dos bancos de dados não relacionais e as diferentes formas de persistir dados, começam a surgir alternativas para a situação de dados que devem ser persistidos e consultados através de uma representação em grafo.
Esse é justamente o papel do banco de dados Neo4j, que permite que dados sejam persistidos e percorridos da mesma forma que os grafos e mantendo algumas características que se tornaram bastante comuns em bancos relacionais, como controle de transações e seguindo as propriedades ACID, além de suporte a pesquisas textuais, através da integração com o Lucene.
Consultas como as demonstradas anteriormente, quando realizadas no Neo4j, poderão ter performance significativamente superiores à mesma consulta em banco de dados relacional.
A API do Neo4j e como percorrer grafos
Uma vez que fizemos toda a configuração do Neo4j, podemos utilizar sua API para realizarmos a pesquisa no grafo, também chamado de Traversal.
Com isso, basta utilizarmos a classe Traversal invocando o método description() para indicarmos como o grafo deve ser percorrido e quais informações serão retornadas.
Node lugarDeOrigem = db.getNodeById( id ); Iterable<Node> nos = Traversal.description() .relationships(Relacionamentos.MOROU\_EM, Direction.BOTH) .relationships(Relacionamentos.VIAJOU\_PARA, Direction.BOTH) .evaluator(Evaluators.atDepth(2)) .traverse(lugarDeOrigem).nodes(); Acima, as invocações a relationships indicam que vamos percorrer os relacionamentos MOROU_EM e VIAJOU_PARA em ambos os sentidos, ou seja, tanto entrada como saída. Enquanto que no método evaluator indicamos quais os nós devem ser devolvidos, que no caso são os estiverem na profundidade 2 do traverse do grafo.
Por fim, indicamos qual é o nó de origem para realizar o traverse e invocamos o método nodes() para termos acesso aos nós devolvidos pelo Neo4j.
A melhor forma de persistir seus dados
Ao escolher um banco de dados, seja relacional ou não relacional, é necessário sempre analisar os tradeoffs entre as tecnologias e modelos diferentes. Alguns bancos de dados podem suportar modelos mais ricos e complexos, enquanto outros podem possuir estratégias de escalabilidade interessantes, pagando um preço em consistência ou disponibilidade.
Da mesma maneira que atualmente temos o conceito de programação poliglota, onde é importante conhecer bem a linguagem para escolher a mais adequada para cada aplicação, com os bancos de dados não é diferente. Cunharam até mesmo o termo persistência poliglota.
Situações práticas vão exigir o uso de mais de um tipo de banco de dados. Isso já ocorre quando queremos, além de guardar os dados em um banco relacional, poder pesquisar textualmente (isso se você considerar o Lucene como um banco de dados NoSQL). Um sistema de recomendação de produtos de um e-commerce deve guardar todos os itens comprados por cada usuário numa base relacional, e pode utilizar o Neo4J para também armazenar esses dados, com o único intuito de facilitar determinadas consultas. Dessa maneira, teríamos em uma mesma aplicação duas formas diferentes de persistir dados, utilizando a melhor tecnologia para cada situação, o que nos lembra o já desgastado "não existe bala de prata".