Boas-vindas a este curso! Meu nome é Lucas Mata, sou instrutor aqui na Alura.
Audiodescrição: Lucas Mata se descreve como um homem de pele clara. Tem olhos castanhos, barba e cabelos pretos. Usa óculos de armação arredondada e camiseta azul-clara. Ao fundo, o estúdio da Alura com iluminação azulada e lilás. À direita, uma estante com decorações.
Este curso é destinado a quem deseja ter uma visão sistêmica do desenvolvimento de um software, desde a concepção até a sua entrega e funcionamento, ou seja, sua disponibilidade para as pessoas usuárias.
Este curso é recomendado para pessoas desenvolvedoras, membros de times de operações, coordenadores, gestores e entusiastas de tecnologia, de modo geral.
É sugerido que tenha concluído o curso anterior desta formação, a fim de aproveitar de forma mais eficaz o conteúdo que será explorado neste curso.
No curso anterior, abordamos desde o estágio de concepção até o estágio de implantação de um software:
No estágio de implantação, analisamos algumas estratégias de deploy.
Retomaremos a partir deste ponto, analisando os testes realizados antes e logo após o deploy de uma aplicação.
Na sequência, precisamos monitorar a aplicação para garantir bom desempenho, eficiência e segurança. Para isso, utilizamos algumas ferramentas e práticas de observabilidade para entender como os diferentes componentes da aplicação estão interagindo.
Entram neste ponto as métricas, os traços distribuídos e os logs, que nos ajudam a entender o comportamento e encontrar erros para resolver gargalos antes que se tornem problemas para as pessoas usuárias.
Em seguida, analisaremos a questão da segurança, entendendo quais mecanismos podemos adotar no processo de desenvolvimento para tornar a aplicação mais segura. Exploraremos como criar planos de contingência para saber o que fazer em casos de incidentes, como interceptações, ataques e vazamentos de dados.
Avançaremos para o estágio de manutenção. Inevitavelmente, uma aplicação precisa passar por atualizações, mudanças de configuração e inclusão de novas funcionalidades. Vamos explorar boas práticas relacionadas à manutenção do código e à qualidade do código. Os testes são parte importante ao longo de todo o ciclo de vida de uma aplicação, assim como a refatoração para reduzir a dívida técnica.
Dessa forma, teremos uma aplicação atualizável, com uma vida longa e próspera, e com capacidade de escalar em termos de funcionalidades e novos recursos e serviços.
Por fim, analisaremos questões relacionadas à infraestrutura da aplicação, entendendo como migrar entre ambientes, utilizar ambientes múltiplos, como, por exemplo, de dois provedores de nuvem, e a boa prática de adotar a infraestrutura como código.
Aprenderemos tudo isso de maneira contextualizada, explorando os diferentes estágios e sua importância para que a aplicação funcione de maneira eficiente e segura. Além dos vídeos, preparamos algumas atividades e inserimos indicações de conteúdos extras para uma experiência aprofundada ao longo de todo o ciclo de vida de uma aplicação.
Qualquer dúvida ao longo do caminho, você tem o apoio do fórum e da nossa comunidade no Discord.
Nos vemos nos próximos vídeos para darmos sequência a essa jornada de aprendizado!
Com a nossa aplicação no ambiente de produção, estamos no estágio de implantação. Após utilizarmos uma estratégia de implantação, como aprendemos anteriormente, como Canary Deployment ou Blue-Green, será que simplesmente encerramos nossas atividades e apenas monitoramos se está tudo certo no painel do ambiente em que essa aplicação está implantada? Não, não é bem assim.
A primeira coisa a fazer após a implantação é realizar alguns testes, ainda que simples, para verificar o comportamento geral da aplicação. Essa verificação é conhecida como Smoke Testing. O termo "teste de fumaça" vem do mundo do hardware, onde esse teste envolvia verificar se o hardware não iria queimar quando energizado, daí o nome.
Nesse teste, verificamos de maneira orgânica, por exemplo, se estamos interagindo com uma plataforma de cursos online, verificamos as principais funcionalidades, como a inscrição em um curso e o acesso aos conteúdos disponíveis na plataforma.
Em diversas situações, as nossas aplicações podem fazer uso de diferentes tipos de componentes, como containers, instâncias e até mesmo funções desempenhando o papel de serviços serverless em ambientes de nuvem. Todos esses elementos podem coexistir dentro de uma única aplicação.
Nesse contexto, surge a questão:
Como realizar testes adequados para garantir que a funcionalidade está apresentando bom desempenho e operando corretamente, mesmo antes de ser implantada?
Talvez inicialmente possamos pensar em realizar testes unitários para testar cada um desses componentes. Essa é uma opção, mas os testes unitários não cobrem 100% do funcionamento de um serviço. Eles cobrem partes e seções de uma aplicação, mas não se destinam a esse tipo de verificação completa.
Podemos realizar testes de integração para verificar se os serviços estão integrados e funcionando bem. É um bom teste que devemos fazer!
Além disso, podemos realizar um teste conhecido como teste E2E (end-to-end).
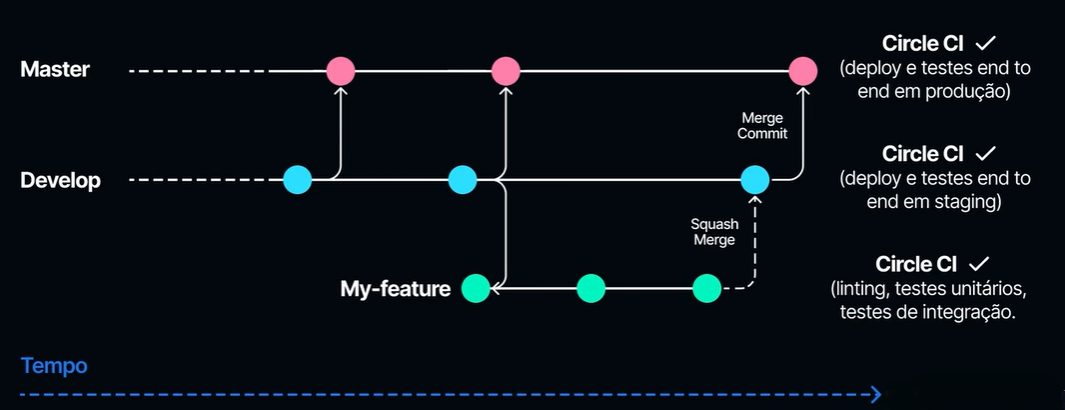
Nos testes end-to-end realizamos um teste completo do funcionamento da aplicação.
Esses testes são conduzidos em um ambiente chamado de staging, que é um ambiente anterior à produção que simula exatamente as mesmas condições do ambiente de produção. Verificamos o funcionamento da aplicação. Se for aprovado nos testes end-to-end, passamos para a entrega dessa nova versão da aplicação no ambiente de produção. No ambiente de produção, podemos realizar novamente os testes end-to-end para garantir que tudo está funcionando conforme o esperado.
Além disso, se percebermos que a aplicação em produção teve algum problema ou resultado negativo, utilizamos uma ferramenta chamada de rollback. Nosso pipeline automatizado de entrega contínua pode descontinuar essa versão e implantar a versão anterior que estava funcional, garantindo que as pessoas usuárias tenham uma descontinuidade muito breve e que a aplicação volte a ficar disponível de maneira plena, sem prejuízo no funcionamento geral.
Na imagem, demonstramos o uso dos testes end-to-end tanto no ambiente staging, em uma branch chamada Develop, como também na branch Master, onde temos as versões da aplicação para o ambiente de produção. Também realizamos os testes end-to-end.
No My-feature, começamos com testes unitários para testar a funcionalidade que acabamos de implementar antes de fazer um merge na branch Develop. Todo esse processo de teste, implantação e rollback deve ser automatizado para eliminar tarefas repetitivas e manuais.
Se lidamos com uma aplicação como um e-commerce, que pode ter picos de acesso, precisamos realizar testes de carga.
Esses testes simulam vários acessos simultâneos à aplicação, visando testar sua resiliência e robustez para suportar múltiplos acessos simultâneos.
Podemos usar ferramentas como Apache JMeter e Gatling para conduzir esses testes de carga.
Além disso, devemos realizar testes de penetração, conhecidos como Pentests. Esses testes são mais alinhados à segurança e visam identificar vulnerabilidades na aplicação, permitindo ajustes para evitar problemas de vazamento de dados e uso indevido.
Antes e depois do deploy, realizamos uma série de testes para garantir que a aplicação funcionará adequadamente.
Citamos alguns testes: começamos com os smoke tests logo após o deploy, para verificar rapidamente as funcionalidades; os testes end-to-end validam o comportamento completo; os testes unitários são realizados no início, antes de fazer um merge de uma funcionalidade em uma branch; o ambiente staging emula a produção e ajuda nos testes end-to-end; e, por fim, realizamos testes de penetração e de carga para verificar a resiliência e escalabilidade da aplicação.
Após a realização dos testes, a atividade no ciclo de vida de uma aplicação não se encerra. É necessário continuar o monitoramento da aplicação, iniciando, assim, um novo estágio desse ciclo, o qual será detalhado a seguir!
Após o estágio de implantação, o próximo passo é o estágio de monitoramento. Nesse estágio, realizamos o acompanhamento contínuo da aplicação.
Por exemplo, em uma plataforma educacional que oferece vídeos explicativos sobre os conteúdos do Enem para estudantes, o monitoramento se torna essencial, especialmente à medida que o final do ano se aproxima.
Nesse período, os estudantes tendem a se dedicar mais aos estudos, o que resulta em picos de acesso à plataforma. Caso a plataforma apresente problemas de disponibilidade e não esteja sendo monitorada, isso pode gerar um grande volume de reclamações em fóruns, chats e diversos canais de contato com as pessoas administradoras.
Para evitar esse tipo de evento, precisamos monitorar a plataforma. Monitorar significa verificar o desempenho e a saúde da plataforma, garantindo que tudo esteja funcionando bem. Para essa atividade, contamos com o apoio de algumas ferramentas, como o Prometheus, uma ferramenta open source ("código aberto") muito utilizada para monitorar aplicações.
Outras opções incluem o Datadog e o New Relic. Se estivermos utilizando nossa aplicação em um ambiente de produção na nuvem, como a AWS, temos o CloudWatch.
No CloudWatch, por exemplo, observamos no menu lateral à esquerda "Alarmes", "Logs", "Métricas", "Eventos" e explicações dos "Conceitos básicos do CloudWatch" na parte central da página, como a definição de alarmes. Podemos, a partir dessas ferramentas, definir alarmes de acordo com algumas ocorrências e métricas.
Essas ferramentas são essenciais para observar e monitorar nossas aplicações, permitindo o rastreamento e a análise de métricas. É possível configurar alarmes com base em limites preestabelecidos.
Por exemplo, uma das métricas monitoradas é a disponibilidade, ou uptime, que indica se a aplicação está acessível para as pessoas usuárias. Outra métrica importante é a velocidade de resposta das APIs. Caso a resposta seja excessivamente lenta, é possível configurar alarmes para alertar a equipe responsável pela aplicação em produção.
O tempo de carregamento das páginas é crucial para garantir uma boa experiência para a pessoa usuária. A latência de rede e de processamento, que é o tempo de resposta após clicar em um botão na interface, também é importante.
A utilização de recursos computacionais é uma métrica relevante, indicando o percentual de CPU utilizado, ou seja, a capacidade de processamento da aplicação no ambiente de produção, assim como a memória. Se estivermos próximos de 100%, e houver mais demanda de processamento, a aplicação pode apresentar desempenho ruim para as pessoas usuárias. Por isso, precisamos de triggers ("gatilhos") que nos alertem.
Se atingirmos um determinado limite, precisamos adotar estratégias para melhorar a escalabilidade da aplicação. Podemos monitorar o volume de acessos, quantas pessoas usuárias estão conectados à plataforma, e rastrear e analisar os registros de erro ou logs. A partir dos erros, podemos identificar funcionalidades com mau comportamento, e os registros são fundamentais para refatorar e atualizar a aplicação.
O monitoramento contínuo de uma aplicação é essencial para garantir seu bom desempenho, segurança e atendimento às expectativas das pessoas usuárias. Além de definir alarmes, é importante prever a ocorrência de erros e picos de acesso para reagir antes que eventos ocorram, garantindo que não haja descontinuidade no comportamento da aplicação.
Quando lidamos com a utilização de recursos computacionais e estamos perto de esgotar a capacidade de processamento, que tipo de estratégia podemos adotar? É nesse ponto que entra a escalabilidade. A seguir, analisaremos melhor o que seria essa escalabilidade no contexto de uma aplicação em produção!
O curso Ciclo de vida de aplicações: monitorando, atualizando e evoluindo um software possui 113 minutos de vídeos, em um total de 52 atividades. Gostou? Conheça nossos outros cursos de Arquitetura em DevOps, ou leia nossos artigos de DevOps.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:

O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






