Já pensou em construir um pipeline de processamento de dados utilizando ferramentas cloud como a AWS? Quer desenvolver um projeto de Engenharia de Analytics para aprimorar suas habilidades práticas? Neste curso, faremos a implementação de um pipeline de ETL utilizando o AWS Glue.
Meu nome é Afonso Rios, sou instrutor na Escola de Dados, e te dou boas-vindas a este curso!
Audiodescrição: Afonso se descreve como um homem de pele morena, com cabelos lisos castanho-escuros, barba castanha-escura, e olhos castanho-escuros. Ele veste uma camisa azul-escura, e ao fundo, há uma parede clara e lisa com iluminação esverdeada.
Ao longo deste curso, vamos atuar como pessoas engenheiras júnior de Analytics, participando de um treinamento para uma vaga no time de dados da Zoop, uma grande varejista que atende a todo o Brasil. Neste treinamento, o head de Dados nos forneceu uma amostra com três bases da Zoop:
- A base de vendas;
- A base de estoques;
- E a base de redes sociais.
Com isso em mãos, utilizaremos os serviços da AWS para analisar esses dados, criando relatórios e dashboards ao final desta formação. Este é o primeiro curso da formação, no qual focaremos na ingestão e tratamento dos dados para consultas e análises.
Durante essa jornada, iremos armazenar os dados no bucket S3, vamos construir as camadas Bronze e Silver para a ingestão dos dados, e também aprenderemos a criar pipelines de processamento de dados utilizando ferramentas da AWS.
Além disso, realizaremos o processo de ETL dos dados, preparando-os para consultas e análises, e conheceremos diversos recursos da AWS Glue, como, por exemplo:
- O Crawler;
- O Data Catalog;
- O Athena;
- O ETL Jobs;
- E o Data Quality.
Também realizaremos consultas ad-hoc, isto é, consultas instantâneas, utilizando o AWS Athena. Por fim, aprenderemos a controlar gastos na AWS, verificando quanto gastamos no projeto.
Tudo isso será feito seguindo os passos repassados pela liderança, desde a ingestão e o tratamento dos dados, até o dado pronto para consultas e análises.
Importante! Alguns recursos que utilizaremos possuem custos. Sempre que chegarmos a um ponto em que haverá custos relacionados ao projeto, deixaremos um aviso. Atente-se a essas explicações, para evitar cobranças indevidas e concluir o curso com o menor custo possível.
Para melhor aproveitamento do curso, é ideal ter conhecimentos em linguagem Python, especialmente, sobre a biblioteca PySpark, que faz a interface entre o Apache Spark e o Python, para tratar dados em grande volume. Além disso, é importante saber um pouco sobre Cloud Computing.
Uma vez alinhadas as expectativas, podemos dar início ao nosso projeto!
Estamos participando de um treinamento para o cargo de Engenharia de Analytics na Zoop, uma grande varejista que atende em todo o Brasil. Nosso primeiro desafio será receber bases da Zoop e realizar tratamentos de dados com elas no ambiente da AWS, para podermos fazer consultas, bem como criar dashboards e relatórios, trazendo insights para decisões estratégicas.
Para solucionar esse primeiro desafio, o head de Dados nos forneceu três bases de dados, com as quais trabalharemos realizando a ingestão no ambiente da AWS, o Amazon Web Services.
Passaremos por todas as funcionalidades e recursos utilizados no processo de ETL (Extract, Transform and Load), que é a extração, tratamento e carga desses dados.
A partir disso, surgem as seguintes questões:
- Quais são os dados a serem trabalhados?
- Quais ajustes precisaremos realizar?
Começaremos analisando um notebook no Google Colab, que já contém as três bases que aplicaremos no ambiente da AWS, apenas para visualizar o conteúdo das tabelas.
Ao clicar no ícone "Arquivos", no menu lateral à esquerda, encontramos as três bases:
Treinamento EA - Zoop.ipynb:
estoques_zoop_bronze.parquet;redes_sociais_zoop_bronze.parquet;vendas_zoop_bronze.parquet.
Com as três bases adicionadas ao notebook, vamos importar a biblioteca Pandas para ler as tabelas. Para isso, em uma nova célula, faremos o import de pandas com o apelido pd.
Feito isso, ainda na mesma célula, iremos declarar três variáveis: vendas, estoques e redes_sociais. Utilizaremos o método pd.read_parquet() para ler os arquivos no formato .parquet, passando entre parênteses o caminho onde eles estão localizados.
import pandas as pd
vendas = pd.read_parquet("vendas_zoop_bronze.parquet")
estoques = pd.read_parquet("estoques_zoop_bronze.parquet")
redes_sociais = pd.read_parquet("redes_sociais_zoop_bronze.parquet")
Após executar a célula, conseguimos salvar em variáveis as três tabelas.
Analisaremos primeiro a tabela de vendas (vendas). Para isso, em uma nova célula, vamos utilizar o comando vendas.head(), para exibir as cinco primeiras linhas da tabela.
vendas.head()
| # | ID_venda | Dia | Mês | Ano | Horario | Canal_venda | Origem_venda | ID_produto | Produto | Categoria_produto | … | Quantidade | Metodo_pagamento | ID_cliente | Nome_cliente | Genero_cliente | Idade_cliente | Cidade_cliente | UF_cliente | Regiao_cliente | Avaliacao |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 20 | 8 | 2021 | 08:58:00 | Loja 2 | Loja | 3 | Cafeteira | Eletrodomésticos | … | 3 | Cartão de débito | 21 | Manuella Pereira | Feminino | 28 | Campo Grande | Mato Grosso do Sul | Centro-Oeste | 4 |
| 1 | 1 | 20 | 8 | 2021 | 11:32:00 | Loja 1 | Loja | 14 | Impressora | Eletrônicos | … | 1 | Dinheiro | 218 | Maria Sophia Rios | Feminino | 40 | Uberlândia | Minas Gerais | Sudeste | 3 |
| 2 | 2 | 20 | 8 | 2021 | 13:19:00 | Loja 1 | Loja | 29 | Máquina de café | Eletrodomésticos | … | 2 | Cartão de crédito | 277 | Ana Sophia Marques | Feminino | 34 | Campinas | São Paulo | Sudeste | 5 |
| 3 | 3 | 20 | 8 | 2021 | 13:42:00 | Loja 2 | Loja | 3 | Cafeteira | Eletrodomésticos | … | 1 | PIX | 282 | Clara Rezende | Feminino | 39 | São Gonçalo | Rio de Janeiro | Sudeste | 3 |
| 4 | 4 | 20 | 8 | 2021 | 14:49:00 | Loja 1 | Loja | 8 | Micro-ondas | Eletrodomésticos | … | 1 | Cartão de débito | 295 | Thiago Lima | Masculino | 59 | Foz do Iguaçu | Paraná | Sul | 2 |
Como retorno, recebemos uma tabela com 21 colunas no total, incluindo dados relativos ao tempo da compra (Dia, Mês e Ano), ao horário da compra (Horario), e a canais onde a compra foi realizada (Canal_venda), por exemplo.
Além disso, temos características sobre o produto, como o tipo (Produto) e a categoria (Categoria_produto), e também características do próprio cliente, como o gênero (Genero_cliente), a idade (Idade_cliente), a cidade (Cidade_cliente), entre outros dados.
Note que há bastante informação para explorar apenas com essa base de dados.
Em seguida, podemos conferir a tabela de estoques (estoques). Ao executar o comando estoques.head(), conseguimos verificar que há menos colunas na tabela.
estoques.head()
| # | ID_estoque | ID_produto | Produto | Categoria_produto | Data | Horario | Quantidade_em_estoque | Quantidade_novos_produtos | Quantidade_vendida |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | Smart_TV_55" | Eletrônicos | 2021/07/01 | 21:45:00 | 100 | 20 | 0 |
| 1 | 1 | 1 | Frigobar | Eletrodomésticos | 2021/07/01 | 20:13:00 | 100 | 29 | 0 |
| 2 | 2 | 2 | Ventilador_de_teto | Eletrodomésticos | 2021/07/01 | 13:30:00 | 100 | 16 | 0 |
| 3 | 3 | 3 | Cafeteira | Eletrodomésticos | 2021/07/01 | 06:20:00 | 100 | 10 | 0 |
| 4 | 4 | 4 | Smartphone | Eletrônicos | 2021/07/01 | 14:33:00 | 100 | 49 | 0 |
Nessa tabela, encontramos colunas como ID_estoque, ID_produto, Produto, Categoria_produto, bem como Data e Horario de chegada do produto no estoque.
Ao final, há três variáveis interessantes: Quantidade_em_estoque; Quantidade_novos_produtos; e Quantidade_vendida. Basicamente, trata-se de um controle de estoques.
Por fim, para visualizar a tabela de redes sociais (redes_sociais), vamos primeiro ajustar a exibição das colunas, com o método pd.set_option() recebendo os parâmetros 'display.max_colwidth', 100. Feito isso, na mesma célula, podemos utilizar o comando redes_sociais.head().
pd.set_option('display.max_colwidth', 100)
redes_sociais.head()
| # | ID_social | Data | Influencia_autor | Plataforma | Nome_produto | Categoria_produto | Comentario |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 2021-09-07 | 7864 | X (Twitter) | Cafeteira | Eletrodomésticos | Estou impressionado com a qualidade e a eficiência. #Cafeteira Nota 4 |
| 1 | 1 | 2021-09-30 | 60503 | X (Twitter) | Impressora | Eletrônicos | Produto ok, mas achei o preço um pouco elevado. #Impressora Nota 3 |
| 2 | 2 | 2021-09-19 | 86828 | X (Twitter) | Máquina de café | Eletrodomésticos | Produto incrível! Desempenho muito acima da média. #Maquinadecafe Nota 5 |
| 3 | 3 | 2021-09-19 | 28615 | X (Twitter) | Cafeteira | Eletrodomésticos | Produto bom, mas nada excepcional. #Cafeteira Nota 3 |
| 4 | 4 | 2021-09-12 | 38424 | Micro-ondas | Eletrodomésticos | Produto ruim. Esperava muito mais. #Micro-ondas Nota 2 |
Esse código nos permite visualizar todo o texto em uma coluna. Ao ler redes_sociais.head(), identificamos na tabela as colunas ID_social, Data, Influencia_autor, Plataforma, Nome_produto, Categoria_produto, e Comentario.
Observação: na coluna
Comentario, temos o texto do comentário, a hashtag do produto, e uma nota. Seria útil se a nota fosse uma coluna; faremos esse tratamento futuramente.
Além desses dados, recebemos instruções do head de Dados sobre ajustes necessários em cada tabela. Essas informações estão organizadas em um arquivo chamado Zoop_ETL_AWS.xlsx.
Neste arquivo, encontramos, por exemplo, uma planilha específica com características das redes sociais, listando os tipos de dados necessários nas colunas, as descrições das transformações a serem feitas, e os nomes das colunas a serem criadas ou modificadas.
Planilha
Redes Sociaisdo arquivoZoop_ETL_AWS.xlsx:
| Nome da Coluna | Tipo de dado | Descrição da transformação |
|---|---|---|
ID_social | long | N/A |
Data | date | N/A |
Influencia_autor | int | N/A |
Plataforma | string | N/A |
Nome_produto | string | N/A |
Categoria_produto | string | N/A |
Avaliacao | int | Criar coluna. Extrair nota que está no final da coluna Comentário |
Comentario | string | Modificar coluna. Retirar a expressão "Nota ?" |
Por exemplo: na tabela de redes sociais (redes_sociais), criaremos uma coluna de avaliação (Avaliacao) e modificaremos a coluna de comentário (Comentario).
Já tabela de estoques (estoques), faremos modificações em mais de uma coluna. Observe abaixo:
Planilha
Estoquesdo arquivoZoop_ETL_AWS.xlsx:
| Nome da Coluna | Tipo de dado | Descrição da transformação |
|---|---|---|
ID_estoque | long | N/A |
ID_produto | long | N/A |
Produto | string | Modificar coluna. Trocar "_" por espaço nos nomes dos produtos |
Categoria_produto | string | N/A |
Data | date | Modificar coluna. Transformar coluna em data válida |
Horario | timestamp | N/A |
Quantidade_em_estoque | int | N/A |
Quantidade_novos_produtos | int | N/A |
Quantidade_vendida | int | N/A |
Por fim, na tabela de vendas (vendas), haverá exclusão, criação e modificação de colunas.
Planilha
Vendasdo arquivoZoop_ETL_AWS.xlsx:
| Nome da Coluna | Tipo de dado | Descrição da transformação |
|---|---|---|
ID_venda | long | N/A |
Dia | - | Excluir coluna |
Mês | - | Excluir coluna |
Ano | - | Excluir coluna |
Data | date | Criar coluna. Concatenar valores de dia, mês e ano em uma só |
Horario | timestamp | N/A |
Canal_venda | string | N/A |
Origem_venda | string | N/A |
ID_produto | long | N/A |
Produto | string | N/A |
Categoria_produto | string | Modificar coluna. Preencher dados faltantes das categorias de acordo com o produto |
Preco_unitario | double | N/A |
Quantidade | int | N/A |
Metodo_pagamento | string | N/A |
ID_cliente | long | N/A |
Nome_cliente | string | N/A |
Genero_cliente | string | N/A |
Idade_cliente | int | N/A |
Cidade_cliente | string | N/A |
UF_cliente | string | Modificar coluna. Trocar estados por extenso em siglas |
Regiao_cliente | string | N/A |
Avaliacao | int | N/A |
Assim, concluímos que há bastante trabalho a ser feito por meio do ETL na AWS.
Conseguimos observar os dados que vamos tratar e entender os ajustes necessários. Agora, vamos iniciar nosso projeto na AWS. Para isso, precisamos entender o pipeline dos dados, como será o processamento, e quais recursos e serviços utilizaremos. Abordaremos isso no próximo vídeo!
Em um projeto de Engenharia de Analytics na AWS, precisamos definir quais serviços e recursos serão necessários para atingir determinado objetivo. Neste caso, vamos criar um pipeline de ingestão e tratamento de dados para consultas e criação de dashboards.
Para isso, precisamos entender como será a arquitetura na AWS para alcançar esse resultado.
Já temos as bases de dados de vendas (vendas), estoques (estoques) e redes sociais (redes_sociais) que utilizaremos nesse processo.
Com base nisso, como será a nossa arquitetura para comportar todas as informações?
Para entender melhor a arquitetura, trouxemos um fluxograma que explica todo o processo de ingestão, tratamento e carga dos dados para consultas que realizaremos ao longo do curso, além dos serviços e recursos necessários para cada uma dessas etapas. Observe-o abaixo:
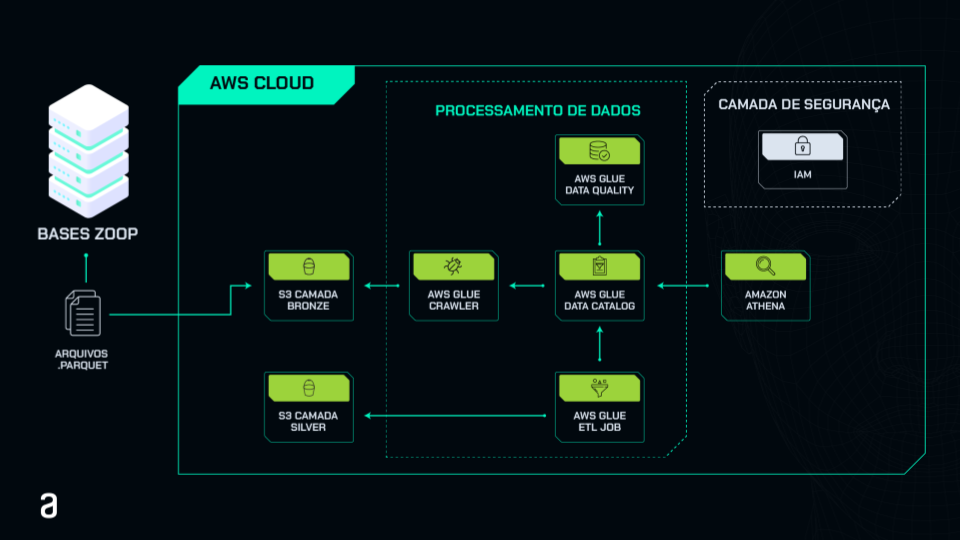
Observação: quando chegarmos ao momento específico de cada um desses elementos e serviços, haverá explicações detalhadas sobre o que cada um realiza dentro do pipeline.
No fluxograma, temos à esquerda a parte das bases que recebemos do head de Data, que consiste em arquivos .parquet com as bases de vendas, estoques e redes sociais.
Dentro do retângulo maior, temos o AWS Cloud, que representa tudo que estará no ambiente da AWS. Começamos pelo bucket S3, simbolizado pela caixa "S3 CAMADA BRONZE".
A camada bronze é a que recebe os dados brutos. Sendo assim, faremos a ingestão diretamente na camada bronze, que será a primeira etapa do nosso projeto dentro da AWS.
No interior do retângulo maior, podemos observar um retângulo menor pontilhado, que representa o momento do processamento dos dados, utilizando vários recursos do AWS Glue.
Entre os recursos, temos o AWS Glue Crawler, responsável por ler e catalogar os dados, puxando-os do S3 e construindo tabelas no Data Catalog. O AWS Glue Data Catalog armazena as informações das tabelas e os metadados, disponibilizando-os para outros serviços do AWS Glue, como o AWS Glue ETL Job, que realiza o processo de ETL, transformando as tabelas dos dados brutos do S3.
Após o processamento, voltamos para fora do retângulo pontilhado, na caixa "S3 CAMADA SILVER", correspondente à camada Silver. Esta camada contém os dados processados, transformados e harmonizados, prontos para serem utilizados em consultas e outras situações necessárias.
Além disso, no processamento de dados, temos também o recurso AWS Glue Data Quality, responsável por assegurar a qualidade dos dados. Esses dados processados seguem regras e processos específicos para verificar se estão com a qualidade necessária para uso.
Fora do retângulo pontilhado, à direita, temos o Amazon Athena, responsável por realizar consultas de dados no Data Catalog. Por fim, no canto superior direito, está a camada de segurança da AWS, o IAM, um usuário que utilizaremos para todos esses processos, evitando o uso da raiz.
Após este vídeo, disponibilizaremos uma atividade em que você criará seu próprio usuário de IAM para realizar todos esses processos no decorrer do curso.
Importante! Parte desses recursos, principalmente o AWS Glue, possui custos de utilização. Sempre que passarmos por processos que exigem cuidado com essa questão para evitar cobranças indevidas, deixaremos um aviso. Portanto, preste atenção nas orientações quando elas forem apresentadas ao longo das aulas.
Esta é a arquitetura da AWS que vamos implementar e criar no projeto. Agora, precisamos iniciar o primeiro processo na AWS: uma vez criado o usuário de IAM, estaremos prontos para realizar a ingestão dos dados no bucket S3. Nos encontramos no próximo vídeo!
O curso Engenharia de Analytics: implementando um pipeline ETL com AWS Glue possui 176 minutos de vídeos, em um total de 52 atividades. Gostou? Conheça nossos outros cursos de Engenharia de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Catálogo de tecnologia para quem é da área de Marketing
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
20% de desconto na Pós Tech
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Acesso ao catálogo da Casa do Código e leitura dentro da plataforma
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






