Olá! Boas-vindas ao curso de Modelagem de Dados: Modelo Lógico. Meu nome é Igor do Nascimento Alves, sou instrutor na Escola de Dados e vou acompanhar você nesta jornada.
Audiodescrição: Igor se autodeclara como uma pessoa branca. Ele tem cabelos pretos e bem curtos e uma barba escura por fazer. Veste uma camiseta cinza com detalhes em preto, e está com airpods pretos nos ouvidos. À sua frente, um microfone num apoio de mesa. Ao fundo, um ambiente com iluminação azul e verde e um vaso de plantas à direita.
Neste curso, vamos aprender a desenvolver o modelo lógico e entender por que fazer isso.
Caso você já tenha seus dados armazenados, por exemplo, em uma planilha, esse modelo pode melhorar a criação e organização desses dados. E, caso queira ou precise dar o próximo passo, utilizando um banco de dados relacional ou o Power BI, o modelo lógico vai te ajudar a implementar com qualidade a criação de dados.
Para isso, vamos aprender como funciona uma chave primária, uma chave estrangeira, e a importância da padronização dos nomes de atributos, tabelas e entidades para guardar os dados com qualidade.
Para aprendermos esses diversos conceitos, vamos passar pelo projeto da FlexEmpresta.
Essa empresa já armazena seus dados em planilhas, porém, entendeu que precisa dar o próximo passo no armazenamento de dados, pois seus dados já não estão sendo utilizados de maneira eficiente nas planilhas atuais.
A empresa já começarou a andar nesse fluxo de criação do modelo de dados, criando um modelo conceitual a partir de reuniões de requisitos com as equipes de negócio e a compreensão das diferentes necessidades de armazenamento de dados da empresa.
A partir desse modelo conceitual, vamos criar um modelo lógico, tentando atender às necessidades da área de negócio.
Para acompanhar este curso de maneira fluída, é importante que você já conheça o conceito de modelo conceitual e o fluxo de construção de um modelo de dados.
Vamos começar?!
Já iniciamos o processo neste projeto da FlexEmpresta anteriormente. Então, vamos entender onde estamos neste momento?
Revisitando o fluxograma do processo de modelagem, começamos a desenvolver um mini-mundo, que é uma representação do que existe na área de negócios no mundo real.
Para iniciar esse processo, fazemos o levantamento de requisitos. Portanto, conversamos com especialistas das áreas de negócio para entender algumas regras desse projeto.
Por exemplo: uma pessoa colaboradora pode ser responsável por um cliente, e esse cliente tem um score. Todas essas relações vão surgindo à medida que entrevistamos a área de negócios e identificamos todos os requisitos necessários para esse modelo de dados.
A partir desse levantamento de requisitos, construímos nosso modelo conceitual, que é uma representação do que acontece na área de negócio em um modelo que estabelece visualmente as informações existentes e as relações entre elas.
A partir desse modelo conceitual pronto e aprovado pela área de negócios, podemos dar o nosso próximo passo: o modelo lógico.
O nosso objetivo ao criar modelos de dados é criar as bases reais. Para isso, temos ferramentas como a própria planilha que a empresa utiliza atualmente, bancos de dados relacionais, Power BI e assim por diante. Essas diversas ferramentas que vão armazenar os dados da organização precisam representar esse negócio.
O modelo conceitual que já temos pronto é focado em trazer os conhecimentos da área de negócio para o fluxograma. Agora, precisamos dar um passo em direção à ferramenta, pensando em como representar, por exemplo, como o relacionamento entre uma pessoa colaboradora e um cliente acontece de verdade. Ou seja: o que faz aquela seta que conecta as duas entidades funcionar?
Para isso, vamos ter que avançar para o próximo modelo, que seria o modelo lógico. Com ele, poderemos efetivar as conexões entre os dados e estabelecer padrões para utilizar os dados de maneira organizada dentro dessas ferramentas.
Então, vamos criá-lo!
Para criar o modelo lógico, vamos utilizar a mesma ferramenta que utilizamos no projeto do curso anterior, chamada Visual Paradigm Online, quando desenvolvemos o modelo conceitual.
Se você tiver o modelo conceitual do curso anterior, você pode carregá-lo na ferramenta e trabalhar a partir dele. Mas, caso você não tenha feito o curso anterior, você fazer o download desse modelo conceitual nas atividades desta aula.
Para carregar esse modelo no Visual Paradigm Online, precisamos primeiro fazer login na ferramenta. Feito isso, na página inicial, podemos clicar no botão do canto superior direito, na seta ao lado de "Create New", e depois selecionar "Import and Open".
Na tela seguinte, descemos a página até a opção de abrir um arquivo Visual Paradigm ("Or open a Visual Paradigm file (.art, .vpd) from:"). Temos três opções de fonte: o Google Drive, o Device e o Browser. Vamos clicar na opção Device, que é o armazenamento local.
Na nova aba, vamos fazer o upload desse arquivo (Modelagem de dados - Modelo Conceitual.vpd) para a ferramenta por meio da caixa de diálogo. Se você já tinha esse arquivo, clique em "Escolher arquivo" e localize o diretório onde o salvou. Se fez o download agora, o arquivo provavelmente está no diretório de Downloads. Selecionamos e clicamos em "Abrir" no explorador de documentos.
Com isso, o modelo conceitual que desenvolvemos no último curso será carregado
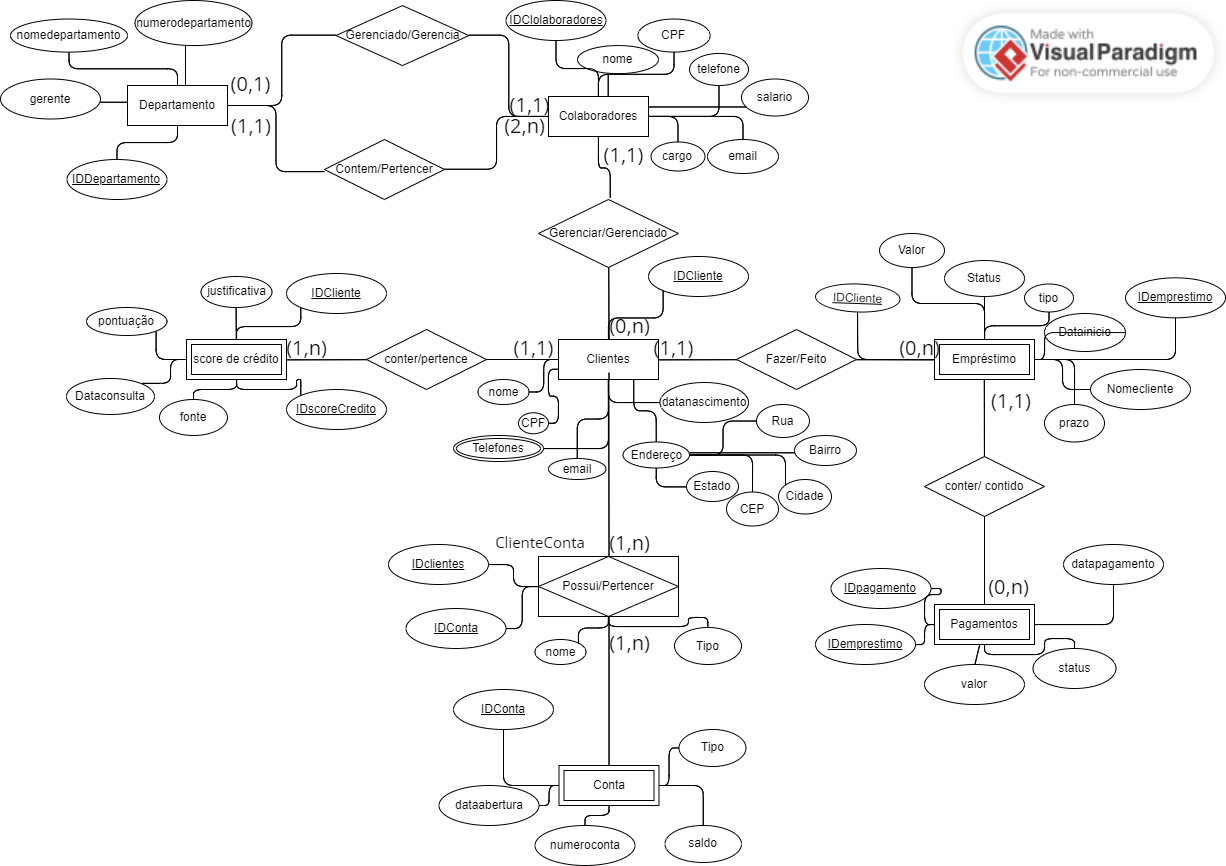
Nesse modelo, temos todas as entidades, atributos e relacionamentos dos dados da FlexEmpresta. Vamos começar a construir nosso modelo lógico a partir desse modelo conceitual.
Por questão de organização, seria interessante abrir outro arquivo. Mas editar o arquivo do modelo conceitual que carregamos vai facilitar o processo, porque evitaremos digitar todos os elementos a todo momento. Depois podemos apagar o modelo anterior desse arquivo caso não precisemos mais dele.
A ideia agora é começar o processo de construção do modelo lógico. Mas, como passamos esse modelo conceitual para o modelo lógico?
Vamos focar em uma das entidades, por exemplo, Colaboradores, e transformá-la para a representação em modelo lógico.
Para isso, vamos utilizar os mesmos ícones que utilizamos no último projeto, que encontramos na aba "Entity Relationship" do menu lateral esquerdo.
Nesse momento, vamos selecionar a primeira opção de ícone, chamada "Table" (tabela). Esse template de tabela será carregado no centro da tela, e podemos arrastá-la para fora do modelo conceitual. Ela tem um título e duas colunas: PK e UniqueID.
Se pensamos numa planilha ou num modelo de banco de dados, o fluxograma do modelo conceitual com a entidade e os atributos em volta conectados, por exemplo, não faz tanto sentido. Afinal, normalmente os atributos estão contidos na entidade.
Então, no modelo lógico, vamos representar essa ideia de "contenção". Vamos começar pela entidade de colaboradores. O primeiro para isso é mudar o nome da tabela de "Table" para "Colaboradores".
Essa tabela tem algumas linhas, e vamos preenchê-las com os atributos conectados a essa entidade, na coluna UniqueID: nome, CPF, telefone, salário, cargo, e-mail e ID do colaborador.
Para adicionar mais linhas nessa tabela, de modo a contemplar toda a quantidade de atributos, clicamos no "Setting Panel", localizado no menu lateral direito, selecionamos a última célula da tabela e clicamos em "Arrange > Insert Row After (inserir linha abaixo).
Agora temos a nossa entidade representada de uma maneira diferente do fluxograma:
TabelaColaboradores
| PK | UniqueID |
|---|---|
| Nome | |
| CPF | |
| Telefone | |
| Salario | |
| Cargo | |
| IDColaborador |
Observação: A tabela acima foi construída como visualização na ferramenta Visual Paradigm e transcrita como texto apenas para viabilizar a leitura dela na transcrição.
Já demos o nosso primeiro passo na construção do modelo lógico! Temos uma entidade representada num só item que contém os atributos. Essa é a diferença do modelo lógico para o modelo conceitual.
Essa representação é mais próxima da organização de dados das ferramentas de dados, então conseguiremos manipulá-los com mais qualidade. Ou seja, o modelo lógico serve para facilitar a criação do banco de dados real.
Um ponto de atenção é o fato de a nossa entidade chamar Colaboradores. A nossa representação já dá uma dica dos próximos passos de organização do fluxo de dados, pois chama essa unidade de "Table", por padrão. A padronização de nomenclaturas é muito importante.
Afinal, como diferenciamos um atributo de uma entidade? No modelo conceitual, usamos formatos diferentes de caixas. No modelo lógico, usamos padrão de nomes. Esse padrão pode ser um simples prefixo, como Tabela. Assim, o nome da nossa entidade de colaboradores será TabelaColaboradores.
Nessa etapa de modelo lógico, é muito importante começarmos a nos preocupar com a facilidade de identificação do que é uma entidade, o que é um atributo e qual atributo pertence a qual entidade. Conseguimos alcançar isso com padronização de nomes.
Ainda temos muitas entidades e atributos para representar! Vamos seguir com essa tarefa no próximo vídeo.
Conseguimos montar a entidade de Colaboradores com seus atributos no modelo lógico. Vamos para as próximas, começando pela próxima entidade mais importante do nosso modelo: a de Clientes.
Para facilitar o processo, podemos criar uma cópia da primeira tabela. Vamos clicar na tabela Colaboradores com o botão direito, selecionar "Copy" para copiar, depois clicar na área ao lado da tabela com o botão direito e selecionar "Paste here" para colar.
Já podemos começar essa tabela respeitando o padrão de nomenclatura que definimos, incluindo o prefixo Tabela no nome da tabela para diferenciar as entidades dos atributos. Então, essa segunda tabela se chamará TabelaClientes.
O próximo passo é incluir os atributos dessa entidade na tabela, como já sabemos fazer. Para remover os atributos herdados da cópia da TabelaColaboradores, podemos clicar na linha duas vezes para selecioná-la e depois clicar em "Delete".
Os atributos de clientes são: Nome, CPF, Telefones, Email, Endereço Completo (reduzindo a composição do endereço do modelo conceitual, que continha rua, estado, cidade, etc.), Data de Nascimento e ID do Cliente.
Vamos chamar a atenção novamente para a padronização, especialmente importante na criação de um banco de dados que vai crescer e se tornar cada vez mais complexo. Sendo assim, além do padrão dos nomes das tabelas com o prefixo, vamos adicionar um padrão no nome dos atributos também, que são os campos das tabelas.
Podemos sempre escrever o nome dos atributos com a primeira letra maiúscula. E, se o nome do atributo tiver mais de uma palavra, começamos a segunda palavra também com a letra maiúscula e não damos espaço entre as duas. Então, o atributo de endereço completo fica "EndereçoCompleto", e data de nascimento fica "DataNascimento", e o mesmo vale para "IDCliente".
Com isso, teremos o seguinte:
TabelaClientes
| PK | UniqueID |
|---|---|
| Nome | |
| CPF | |
| Telefones | |
| EnderecoCompleto | |
| DataNascimento | |
| IDCliente |
No modelo conceitual, a padronização de nomenclatura não é uma preocupação, porque o foco é criar um esquema visual da organização dos dados. No modelo lógico, no entanto, é necessário representar os dados de modo a pensar em como vamos registrá-los no banco de dados real. Por isso, a padronização de nomes é importante.
Se analisarmos ambas as tabelas que criamos, notaremos que os campos têm nomes muito parecidos e alguns iguais, como nome, CPF, email, etc. Por isso, a padronização se torna importante novamente, pois as informações parecidas podem dificultar a identificação imediata da referência desses dados.
Para resolver esse tipo de problema, podemos utilizar um sufixo para ajudar a identificar a referência da informação. Para o nome do colaborador, podemos usar "NomeColaborador". Já no caso do Cliente, que é a entidade mais importante do nosso negócio, podemos manter apenas "Nome".
Aplicando a mesma lógica para o restante dos campos da TabelaColaboradores repetidos em outras entidades, ela ficará assim:
TabelaColaboradores
| PK | UniqueID |
|---|---|
| NomeColaborador | |
| CPFColaborador | |
| TelefoneColaborador | |
| Salario | |
| EmailColaborador | |
| Cargo | |
| IDColaborador |
O mesmo vai valer para todos as outras entidades, sendo os sufixos dos campos de atributos repetidos o nome da entidade em si. A exceção é a entidade Clientes que, por ser a mais importante, leva os atributos como padrão, sem precisar de sufixo.
Conseguimos montar duas das nossas entidades mais importantes. A partir das regras de nomenclatura e de representação que definimos, podemos repetir esses passos para todas as nossas entidades.
Se você quiser, pode praticar criando as próximas primeiras entidades. Mas, não se preocupe: na próxima aula, vamos conferir o resultado desse modelo lógico completo, com todas as entidades representadas.
Até mais!
O curso Modelagem de dados: desenvolvendo o modelo lógico possui 90 minutos de vídeos, em um total de 43 atividades. Gostou? Conheça nossos outros cursos de SQL e Banco de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






