Formações Data Science Engenharia de dados com Databricks
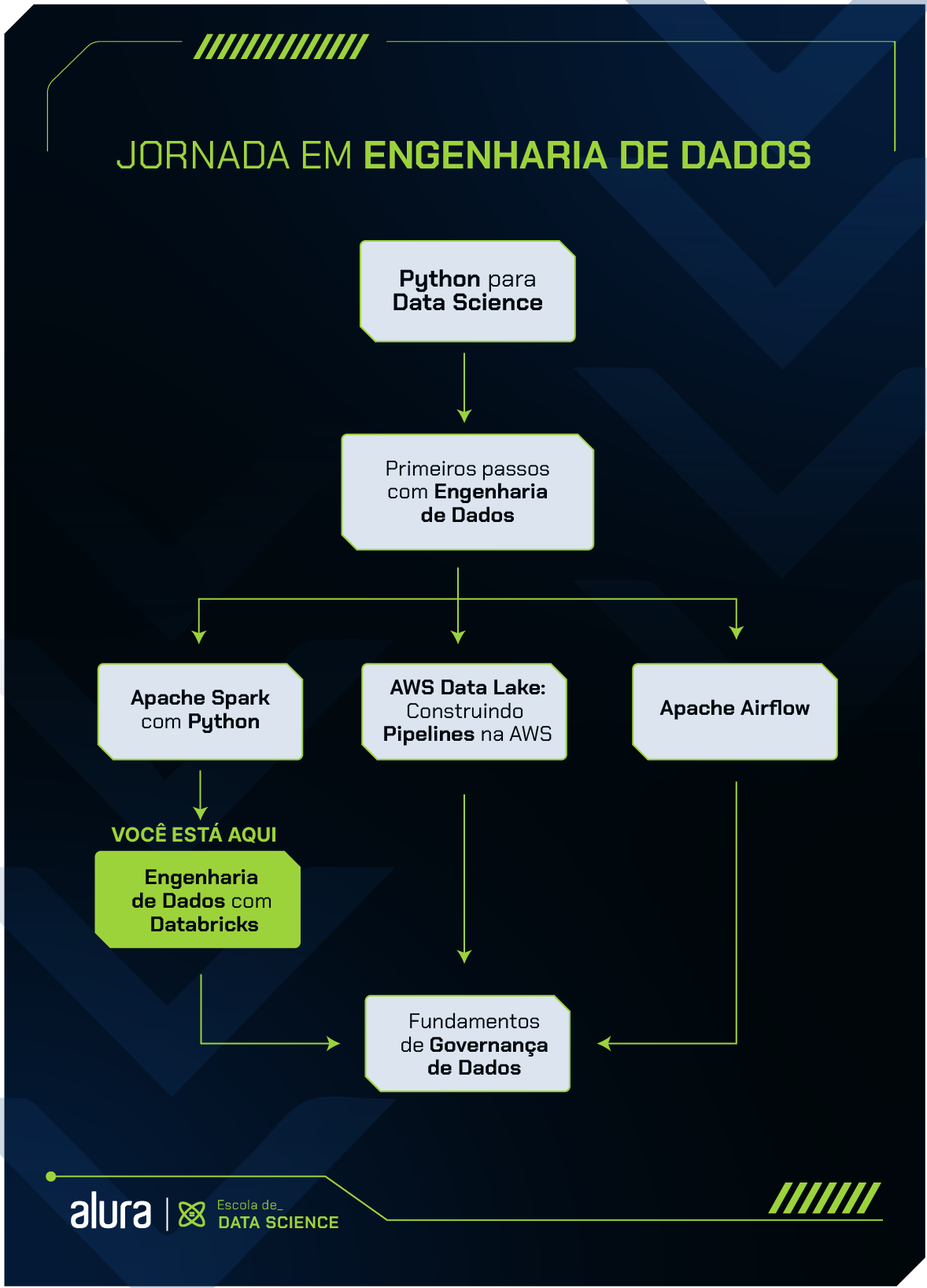
Formação Engenharia de dados com Databricks
* Esta formação faz parte dos nossos cursos de Data Science
Quero Estudar na AluraPara conclusão


A formação de Databricks busca preparar estudantes para trabalhar com Ciência de Dados e Engenharia de Dados, utilizando recursos do Apache Spark e linguagens como Python e SQL.
Funciona como um guia de aprendizado para auxiliar pessoas interessadas em entrar no mercado de trabalho e também como mecanismo de consulta para profissionais experientes.
O Databricks é uma plataforma de computação em nuvem criada para cuidar da análise exploratória, criar modelos de machine learning e processar grandes volumes de dados de uma forma mais simples que as outras ferramentas do mercado. Essa plataforma foi desenvolvida em 2013 pelos mesmos criadores do Apache Spark.
Nesta formação, vamos conhecer a plataforma Databricks entendendo e aplicando de forma prática alguns conceitos como: análise exploratória, processamento de dados e machine learning.
Você vai aprender a manipular dados utilizando SQL, Python e Pandas. Além disso, vai trabalhar com diferentes formatos de arquivos, como: JSON, CSV, TXT, AVRO, Parquet e ORC. E também vai conhecer a biblioteca MLlib do Spark Core.
Por fim, vamos focar nossos estudos na orquestração de pipelines, integrando o Databricks com outras ferramentas de cloud para auxiliar nesse processo.
Para aproveitar melhor esse conteúdo, é importante que você já saiba programar em linguagem Python, tenha conhecimento em Spark e saiba conceitos básicos de SQL.
Conteúdos pensados para facilitar seu estudo
Formação completa para o mercado
Do zero ao sonhado emprego em sua área de interesse
Comece essa formação agora mesmo e capacite-se para seu próximo projeto!
Conheça os planos

Rodrigo é estatístico e especialista em Big Data com forte interesse em inteligência artificial, ferramentas de automação, geoprocessamento, desenvolvimento web, web scraping, machine learning e Data Science. É instrutor e coordenados da Escola de Dados da Alura.
Rodrigo é estatístico e especialista em Big Data com forte interesse em inteligência artificial, ferramentas de automação, geoprocessamento, desenvolvimento web, web scraping, machine learning e Data Science. É instrutor e coordenados da Escola de Dados da Alura.


Allan trabalha como instrutor de Ciência de dados na Alura desde 2019. Também é um dos autores do livro Séries temporais com Prophet pela Casa do Código.
Allan trabalha como instrutor de Ciência de dados na Alura desde 2019. Também é um dos autores do livro Séries temporais com Prophet pela Casa do Código.

Bruno é um instrutor de Data Science e Engenheiro Eletricista pela Universidade Federal do Piauí. Se dedica em áreas como Data Science, Machine Learning e Deep Learning, e possui grande interesse em engenharia de dados e engenharia de machine learning. Além disso, em seu tempo livre, ele gosta de jogar xadrez, tocar instrumentos musicais e jogar League of Legends.
Bruno é um instrutor de Data Science e Engenheiro Eletricista pela Universidade Federal do Piauí. Se dedica em áreas como Data Science, Machine Learning e Deep Learning, e possui grande interesse em engenharia de dados e engenharia de machine learning. Além disso, em seu tempo livre, ele gosta de jogar xadrez, tocar instrumentos musicais e jogar League of Legends.

Millena Gená é estudante de Ciência da Computação. Atualmente, é Instrutora de Dados aqui na Alura atuando principalmente na área de Engenharia de dados. Ela está sempre procurando aprender algo novo sobre tecnologia e é apaixonada por novas aventuras. Programar e ajudar as pessoas são seus hobbies favoritos! ^^
Millena Gená é estudante de Ciência da Computação. Atualmente, é Instrutora de Dados aqui na Alura atuando principalmente na área de Engenharia de dados. Ela está sempre procurando aprender algo novo sobre tecnologia e é apaixonada por novas aventuras. Programar e ajudar as pessoas são seus hobbies favoritos! ^^

Sou graduado em Ciência da Computação. Atuo como instrutor de Data Science e Machine Learning no Grupo Alura, tendo como principais interesses na tecnologia: criação de modelos e análise de dados. Nas horas vagas assisto e analiso dados de basquete e adoro ouvir podcasts de humor como Nerdcast e Jujubacast.
Sou graduado em Ciência da Computação. Atuo como instrutor de Data Science e Machine Learning no Grupo Alura, tendo como principais interesses na tecnologia: criação de modelos e análise de dados. Nas horas vagas assisto e analiso dados de basquete e adoro ouvir podcasts de humor como Nerdcast e Jujubacast.
Neste passo inicial, preparamos um conteúdo para ajudar você a conhecer melhor o Databricks, como navegar na plataforma e manipular dados utilizando Python e SQL.
Na primeira etapa dessa jornada, você vai aprender os principais recursos da plataforma Databricks, entender como configurar e criar um cluster, usar comandos SQL utilizando Hive e SparkSQL e também entender as vantagens e desvantagens de utilizar os diferentes tipos de arquivos. No final dessa etapa, você será capaz de manipular dados utilizando os principais recursos do Databricks.

Artigo Databricks: o que é e para que serve? | Alura

Curso Databricks: conhecendo a ferramenta
08h
Curso Databricks: trabalhando com diversos formatos e tipos de arquivos
08hNesta fase da formação, vamos mergulhar em outras ferramentas do Spark, focando no seu uso dentro do Databricks. Vamos aprender a usar a API da Pandas no Spark para manipulação de dados, uma alternativa poderosa para o Pandas, mas com um desempenho superior em grandes conjuntos de dados.
Em seguida, faremos o curso Databricks: criando um sistema de recomendação. Aqui, aprenderemos a usar a biblioteca MLlib, uma biblioteca de machine learning escalável que fornece vários algoritmos e utilitários (incluindo métodos de regressão, classificação, clustering e filtragem colaborativa), bem como ferramentas para construir pipelines de machine learning.
Com esses dois cursos, você estará bem equipado para usar o Databricks para ciência de dados, desde a análise exploratória até a criação de modelos preditivos.

Curso Databricks: análise de dados
08h
Curso Databricks: criando um sistema de recomendação
10hNesta etapa, vamos explorar a orquestração dos notebooks no Databricks utilizando o Apache Airflow e o Azure Data Factory.
Aprenderemos como agendar a execução dos notebooks no ambiente do Azure Databricks, utilizando ferramentas poderosas como PySpark, Airflow, Databricks e requisições de API. Além disso, utilizaremos o Data Factory e o Databricks com Scala para ler e manipular os dados de imóveis nas camadas bronze e silver de um Data Lake que vamos criar no Azure.
Ao completar essa etapa, você estará equipado com as habilidades necessárias para automatizar tarefas no Databricks utilizando o Airflow e o Data Factory, impulsionando a eficiência e a produtividade em suas operações de análise de dados.
Artigo Scala para engenharia de dados: primeiros passos

Curso Databricks e Data Factory: criando e orquestrando pipelines na nuvem
10h
Curso Databricks: construindo pipelines de dados com Airflow e Azure Databricks
10hEscola
Além dessa, a categoria Data Science conta com cursos de Ciência de dados, BI, SQL e Banco de Dados, Excel, Machine Learning, NoSQL, Estatística,e mais...
Conheça a EscolaImpulsione a sua carreira com os melhores cursos e faça parte da maior comunidade tech.
1 ano de Alura
Assine o PLUS e garanta:
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
No Discord, você tem acesso a eventos exclusivos, grupos de estudos e mentorias com especialistas de diferentes áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Acelere o seu aprendizado com a IA da Alura e prepare-se para o mercado internacional.
1 ano de Alura
Todos os benefícios do PLUS e mais vantagens exclusivas:
Luri é nossa inteligência artificial que tira dúvidas, dá exemplos práticos, corrige exercícios e ajuda a mergulhar ainda mais durante as aulas. Você pode conversar com a Luri até 100 mensagens por semana.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Transforme a sua jornada com benefícios exclusivos e evolua ainda mais na sua carreira.
1 ano de Alura
Todos os benefícios do PRO e mais vantagens exclusivas:
Mensagens ilimitadas para estudar com a Luri, a IA da Alura, disponível 24hs para tirar suas dúvidas, dar exemplos práticos, corrigir exercícios e impulsionar seus estudos.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.