
Você já parou para pensar como seria trabalhar com dados sem a ajuda da estatística? Imagina como seria complicado tentar extrair insights ou tomar decisões apenas observando uma enorme quantidade de dados, sem ferramentas para organizar, interpretar e validar essas informações.
Na Ciência de Dados, a estatística é o que nos permite transformar os dados em conhecimento prático, guiando desde as etapas iniciais de análise até a construção e validação de modelos.
O problema é que, muitas vezes, a estatística pode parecer intimidadora ou complicada, especialmente para quem está entrando na área de Dados. Mas não precisa ser assim!
A boa notícia que eu tenho pra te dar aqui é que, quando entendida e aplicada corretamente, a estatística pode simplificar a tomada de decisões e resolver problemas complexos com eficiência.
Neste artigo, vamos explorar como a estatística desempenha um papel crucial na Ciência de Dados e como você pode utilizá-la de forma prática e acessível.
Vamos entender como os Cientistas de Dados usam métodos estatísticos para resolver problemas do mundo real, quais análises são mais comuns e quais ferramentas estatísticas são mais utilizadas.
Ficou curioso(a)? Então vem comigo e descubra como a estatística pode transformar a forma como você trabalha com dados.
Qual a relação entre a Ciência de Dados e a Estatística?
Imagine que você trabalha em uma loja online e precisa descobrir por que as vendas de um determinado produto estão caindo.
Você tem acesso a uma grande quantidade de dados, como o número de visitas à página do produto, avaliações, o histórico de compras e até informações demográficas dos clientes. Agora, a pergunta é: como transformar todos esses dados em uma solução prática?
Para entender por que as vendas estão caindo, você primeiro precisa explorar os dados e tentar encontrar padrões.
Você pode começar aplicando técnicas estatísticas para analisar a distribuição dos dados, calcular a média das avaliações dos clientes ou entender como variáveis como idade e região afetam as vendas.
E aí? Será que os clientes mais jovens estão comprando menos? Será que as avaliações negativas estão afetando as vendas?
Felizmente, a estatística fornece ferramentas para responder a essas e outras perguntas de forma clara e objetiva.
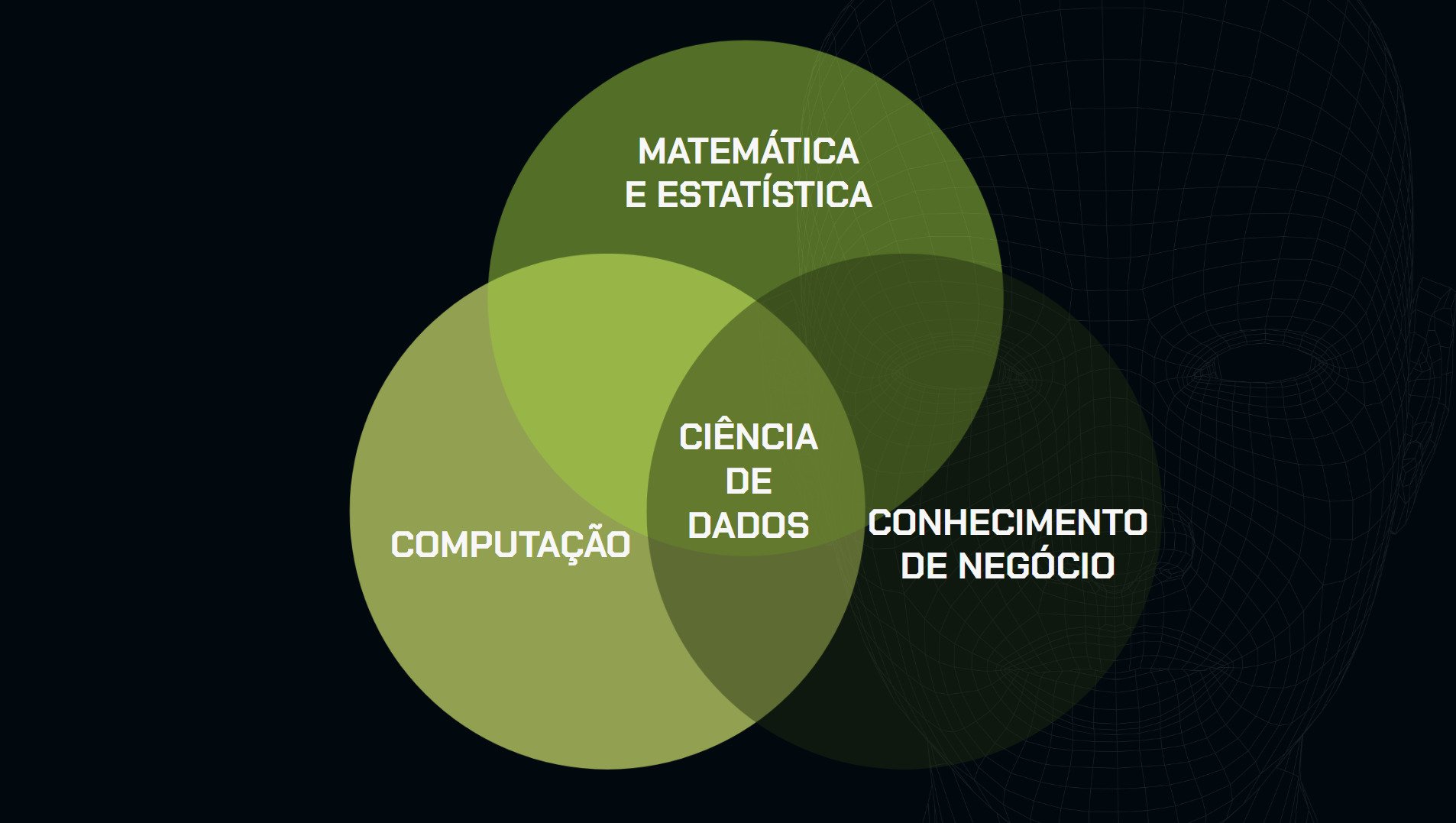
A estatística já é poderosa, mas na Ciência de Dados ela se torna ainda mais eficaz ao se integrar com outras duas áreas essenciais: a computação e o conhecimento de negócio.
Essa combinação permite que Cientistas de Dados não apenas façam análises precisas, mas também escalem essas análises e as apliquem de forma prática em cenários reais, gerando valor para as organizações.
Abaixo, temos o famoso Diagrama de Venn que ilustra as intersecções entre essas três áreas.
A estatística fornece a base para a análise de dados, enquanto a computação viabiliza o processamento e a automatização dessas análises em grande escala.
Por sua vez, o conhecimento de negócio garante que os insights extraídos sejam relevantes e aplicáveis ao contexto específico da empresa.
Legal! Já entendemos como a estatística faz parte da Ciência de Dados, mas como Cientistas de Dados a aplicam na prática em seu dia a dia?

Como Cientistas de Dados usam a estatística
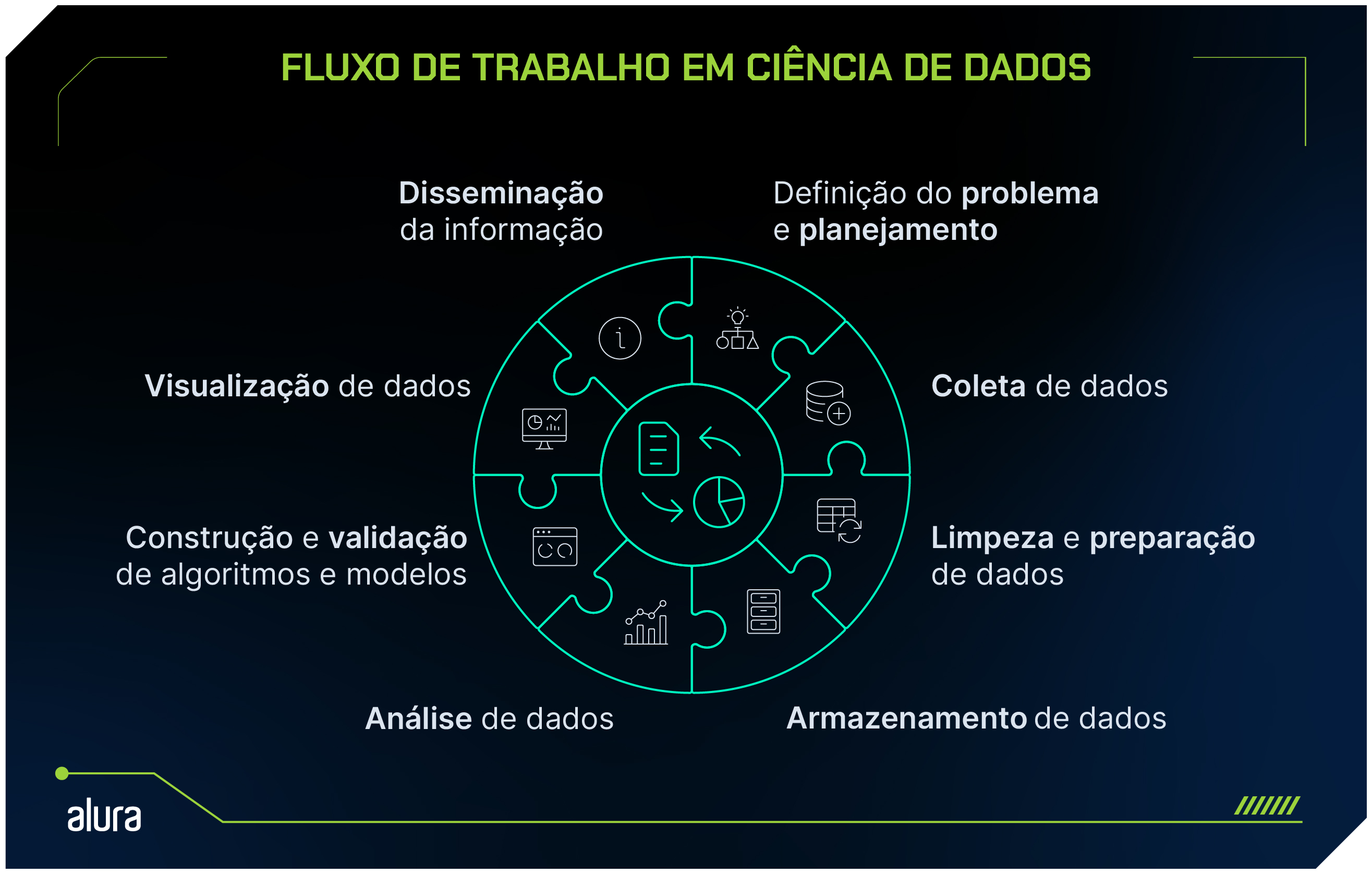
Para entender como os Cientistas de Dados utilizam a estatística, vamos explorar o fluxo de trabalho na área de Dados.
Quando vamos desenvolver um projeto, o processo começa com a definição clara do problema que se deseja resolver.
Em seguida, é elaborado um planejamento cuidadoso para a coleta de dados.
Após a coleta, esses dados passam por um processo de limpeza e preparação, que é essencial para garantir que as análises que vêm a seguir sejam de qualidade.
Durante essa fase, a geração de visualizações gráficas pode ajudar a identificar outliers (dados discrepantes), dados faltantes ou inconsistências, tornando o processo de limpeza mais eficaz.
Com os dados prontos, o Cientista de Dados pode aplicar métodos estatísticos e algoritmos de Machine Learning para extrair insights, identificar padrões e realizar predições.
Depois que os resultados são validados, eles podem ser visualizados de maneira clara e intuitiva.
Essa visualização não só facilita a interpretação dos dados, mas também torna a comunicação das descobertas mais acessível e compreensível para diferentes públicos, incluindo gestores e equipes não técnicas.
Esse ciclo iterativo e contínuo é crucial, pois permite constantes refinamentos nas análises e nos modelos desenvolvidos, sempre com o objetivo de fundamentar decisões em dados confiáveis e precisos.
Assim, a estatística não é apenas uma ferramenta, mas uma aliada indispensável na busca por compreensão e inovação em um mundo repleto de informações.
A seguir, vamos explorar algumas maneiras de como a estatística pode ser utilizada para resolver problemas. Vamos lá!
Descrição dos dados
Imagine que você acabou de coletar dados sobre as compras de uma loja online. Você percebe que, entre as várias informações, existem dados como a idade dos clientes e o valor que eles gastam.
Agora, como você entenderia melhor esse conjunto de dados? A resposta está na descrição dos dados. Através de estatísticas descritivas, como a média e o desvio padrão, você pode criar um retrato claro do seu público.
Por exemplo, se a média de idade dos seus clientes é de 30 anos e a maioria gasta cerca de R$150, isso pode ajudar a empresa a direcionar suas estratégias de marketing de forma mais eficaz.
Testes de hipótese
Agora, suponha que você está trabalhando em um projeto para melhorar a taxa de conversão de um site. Você acredita que a mudança na cor do botão "Comprar" pode aumentar as vendas.
Para testar isso, você formula duas hipóteses: a hipótese nula (H0), que diz que a mudança não terá efeito, e a hipótese alternativa (H1), que afirma que a mudança terá um impacto positivo.
Após coletar dados sobre as taxas de conversão antes e depois da mudança, você utiliza técnicas estatísticas para verificar se a diferença observada é significativa. O teste de hipótese permite que você tome decisões informadas com base em dados, minimizando o risco de conclusões erradas.
Análise de variância
E se você precisasse comparar a eficácia de três diferentes medicamentos para tratar uma doença específica?
Cada medicamento é administrado a um grupo distinto de pacientes, e a eficácia é avaliada através de uma pontuação de melhoria clínica.
Suponha que o Medicamento A tenha uma média de melhoria de 80 pontos, o Medicamento B de 75 pontos e o Medicamento C de 85 pontos.
Utilizando a análise de variância (ANOVA), você pode determinar se as diferenças nas médias de melhoria entre os grupos de pacientes que receberam cada medicamento são estatisticamente significativas.
A ANOVA testa a hipótese nula de que todas as médias são iguais, ou seja, que os medicamentos são igualmente eficazes.
Se o resultado da ANOVA rejeitar essa hipótese nula, a gente conclui que pelo menos um dos medicamentos tem uma eficácia significativamente diferente dos outros.
Essa técnica pode ser usada para comparar as médias de dois ou mais grupos em diversas áreas, além da saúde.
Teste A/B
Suponha que você trabalha para uma empresa de e-commerce e quer descobrir qual layout de página gera mais vendas.
Você decide testar duas versões da mesma página: a versão A (original) e a versão B (com algumas mudanças).
Depois de direcionar metade do tráfego para cada versão, você observa qual delas resulta em mais vendas.
Após um período, analisa os dados e verifica qual layout teve melhor desempenho. Os testes A/B são essenciais para otimizar produtos e estratégias, permitindo que você implemente mudanças que realmente mostraram ser melhores.
Modelos preditivos
Considere um cenário em que você deseja prever as vendas de uma loja para o próximo mês.
Usando dados históricos de vendas, sazonais e outras variáveis, você pode construir um modelo preditivo.
Imagine que seu modelo indica que, com base nas tendências anteriores, você pode esperar um aumento de 15% nas vendas.
Com essa informação, a loja pode ajustar seu estoque e suas estratégias de marketing para atender à demanda prevista, evitando perdas e maximizando lucros.
Avaliação de modelos
Após criar um modelo preditivo, como você sabe se ele realmente está funcionando bem?
Suponha que você criou um modelo de regressão para prever o preço de casas com base em características como tamanho e localização.
Para avaliar seu desempenho, você pode usar o erro quadrático médio (MSE), que mede a média das diferenças entre os preços reais e previstos. Se o MSE for de R$ 25.000, isso indica que o modelo apresenta um erro desse valor em relação ao valor previsto, seja para mais ou para menos.
Além disso, existe um tal de coeficiente de determinação (R2), que mostra a proporção da variação nos preços que seu modelo consegue explicar.
Por exemplo, um R2 de 0,85 significa que 85% da variação nos preços é capturada pelo modelo.
Esses insights ajudam a identificar a eficácia do seu modelo e a necessidade de ajustes, como incluir mais variáveis ou testar diferentes algoritmos para melhorar as previsões.
Storytelling com dados
Pense em um Cientista de Dados apresentando os resultados de uma análise de vendas. O que seria mais atrativo para o público-alvo: mostrar apenas números em tabelas ou criar gráficos que contam uma história? Eu com certeza voto na segunda opção e você?
Ao exibir uma visualização que mostra, por exemplo, como as vendas aumentaram após uma campanha de marketing específica, é possível transmitir a mensagem de forma clara e impactante.
O Storytelling com dados coloca os dados em um contexto real, ajudando a equipe a entender o que funcionou e o que pode ser melhorado, facilitando a tomada de decisões mais precisas.
Bom, essas são algumas das formas de aplicar a estatística na Ciência de Dados. Incrível, né? Mas quais ferramentas podemos usar para realizar essas tarefas?
Na área da Ciência de Dados, as linguagens de programação mais populares são Python e R.
A seguir, vamos explorar ferramentas disponíveis em ambas as linguagens!

Ferramentas estatísticas mais usadas em ciência de dados
Na ciência de dados, tanto Python quanto R são linguagens de programação amplamente utilizadas, e ambas possuem diversas bibliotecas e pacotes que facilitam a aplicação de técnicas estatísticas.
Essas ferramentas são fundamentais para realizar análises detalhadas e transformar dados brutos em informações valiosas. A seguir, vou te apresentar as bibliotecas e pacotes mais utilizados em ambas as linguagens.
Python
Pandas: é uma biblioteca essencial para a manipulação e análise de dados em Python. Oferece estruturas de dados como DataFrames e Series, que permitem trabalhar com dados tabulares de maneira eficiente e intuitiva. É ideal para tarefas como limpeza de dados, transformações, obtenção de estatísticas descritivas e agregação de informações.
Matplotlib: é a base para a criação de gráficos em Python, permite visualizar distribuições de dados, tendências e padrões estatísticos através de gráficos como histogramas, gráficos de dispersão, linhas de tendência, entre outros.
Seaborn: é baseada na Matplotlib e proporciona uma interface de alto nível para a criação de gráficos de forma mais intuitiva e elegante. Ela oferece recursos avançados para visualizações de correlação, distribuição e variação, ideais para análises estatísticas mais detalhadas.
NumPy: é fundamental para operações estatísticas que envolvem cálculos com arrays e matrizes. Suporta funções estatísticas básicas como média, mediana, desvio padrão e variação, além de ser a base para operações mais complexas em outras bibliotecas.
SciPy: é utilizado para tarefas estatísticas mais avançadas como intervalos de confiança, testes de hipótese e análise de regressão.
Statsmodels: Utilizada para modelagem estatística avançada, permite a construção de modelos de regressão linear e análise de séries temporais.
Scikit-learn: Conhecida principalmente por suas funcionalidades de Machine Learning, esta biblioteca também fornece ferramentas estatísticas como regressão e métricas de validação de modelos. Também inclui métodos para validação cruzada, o que é essencial para avaliar a eficácia de modelos.
R
dplyr: é um pacote da linguagem R amplamente utilizado para manipulação e análise de dados, que facilita a aplicação de técnicas estatísticas por meio de uma sintaxe intuitiva e eficiente. O dplyr permite que os usuários realizem operações como filtragem, seleção de variáveis, criação de novas colunas e resumo de dados de maneira rápida e clara.
ggplot2: é uma das ferramentas mais poderosas e flexíveis para visualização de dados em R. Permite aos usuários criar gráficos complexos e esteticamente agradáveis com relativa facilidade. Seja para explorar dados ou apresentar resultados analíticos, o ggplot2 oferece uma ampla gama de tipos de gráficos, como boxplots, histogramas e gráficos de dispersão, que podem ser facilmente personalizados e combinados para comunicar insights de forma eficaz.
stats: este pacote fornece uma ampla gama de funções e ferramentas para realizar análises estatísticas, incluindo modelos de regressão, testes de hipótese, análises de variância (ANOVA), entre outras.
caret: é uma ferramenta unificada para treinamento e avaliação de modelos de Machine Learning. O caret simplifica o processo de criação de modelos preditivos, oferecendo funções para pré-processamento de dados, seleção de características, ajuste de hiperparâmetros e avaliação de modelos.
Bastante coisa legal, né? Independentemente de a linguagem ser Python ou R, o domínio dessas bibliotecas e pacotes permite que Cientistas de Dados resolvam uma variedade de problemas, desde análises descritivas e validação de hipóteses até modelagens preditivas.
Conclusão
Se você está se aventurando na Ciência de Dados, a estatística vai andar lado a lado com você. Ela oferece ferramentas indispensáveis para interpretar dados, validar hipóteses e garantir que as soluções desenvolvidas sejam robustas e confiáveis.
A estatística vai sempre ajudar a transformar dados em insights significativos, e assegurando que as decisões tomadas sejam baseadas em evidências sólidas.
Que tal aprender estatística de forma prática e aplicada? Aqui na Alura, temos duas formações incríveis esperando por você: uma focada na linguagem Python e outra em R.
Venha estudar com a gente e potencialize suas habilidades!🚀
Créditos
Conteúdo: Valquíria Alencar
Produção técnica: Rodrigo Dias
Produção didática: Cláudia Machado
Designer gráfico: Alysson Manso
