ORM: aprenda a simplificar a integração com bancos de dados


Se você já trabalhou com banco de dados, já passou pela situação de ter que escolher qual banco de dados utilizar e o pior, de escolher como o banco de dados se conectará a sua aplicação. Então, é bem provável que tenha ouvido falar sobre ORM, não é mesmo?
A sigla ORM vem do inglês Object-Relational Mapping (Mapeamento Objeto-Relacional).
E, ORM, nada mais é do que códigos que são usados para interagir com o banco de dados.
Em outras palavras, no lugar de realizar uma ação direta no banco de dados com um script SQL, utilizamos o ORM como ponte de comunicação entre o banco de dados e a aplicação.
Neste artigo vamos explorar o que é ORM, como funciona sua estrutura, vantagens, desvantagens e os principais tipos de ORM do mercado.
Bora lá?
O que é ORM?
Para entender o que é ORM, vamos começar com uma história real. Em 1980, as pessoas desenvolvedoras tinham como desafio vincular dois sistemas distintos: código de programação e banco de dados relacionais.
Com o tempo, a complexidade das aplicações tornou essa integração cada vez mais desafiadora.
As pessoas precisavam traduzir manualmente objetos de código para estruturas de banco de dados, um processo repetitivo e sujeito a falhas.
Na década de 1990, começaram a surgir as primeiras ferramentas de mapeamento objeto-relacional, buscando automatizar essa tradução para simplificar a integração entre os sistemas.
O termo ORM foi popularizado no início dos anos 2000, quando frameworks como Hibernate (Java) começaram a ganhar destaque, oferecendo uma "ponte" entre código e banco de dados.

Para quê serve o ORM?
O ORM serve para simplificar a interação entre aplicação e bancos de dados, fazendo com que as pessoas desenvolvedoras trabalhem com estruturas de banco de dados diretamente no código, sem precisar escrever consultas SQL manualmente para a maioria das operações.
Essa estratégia também acelera o desenvolvimento ao reduzir tarefas repetitivas relacionadas ao banco de dados.
Fora isso, o ORM permite que reutilizemos estruturas de código, como classes e relações, em várias partes da aplicação e permitem a troca do banco de dados com o mínimo de impacto no código.
A grande promessa do ORM, é ser uma ferramenta capaz de não te fazer aprender uma nova linguagem como SQL, para manipular os dados da sua aplicação.
Como funciona a estrutura ORM?
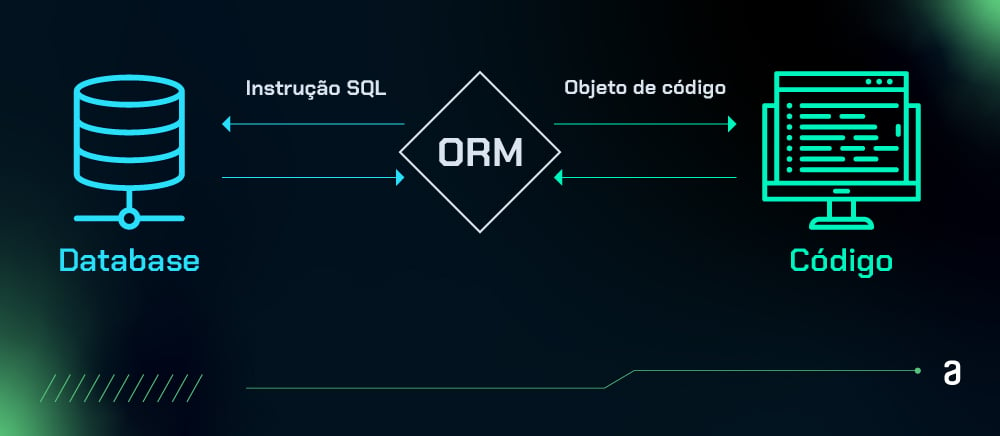
Na prática, o ORM atua como um tradutor. Ele converte as estruturas e comandos do código de programação em consultas SQL — e vice-versa.
Essa abstração permite que as pessoas desenvolvedoras trabalhem com o banco de dados como se estivessem lidando com objetos de sua linguagem de programação preferida, como Python, JavaScript, Java, dentre outras.
Por exemplo, imagine que precisamos acessar todos os dados de um cliente. Com SQL, a consulta seria algo como:
SELECT * FROM clientes WHERE id = 1;
Com um ORM, dentro do próprio código, escreveríamos algo mais direto:
Cliente.findByPk(1)
Bacana demais, né? Vamos entender mais a fundo como isso funciona.
Camada de abstração de banco de dados
Essa camada atua como uma ponte entre a aplicação e o banco de dados, lidando com a comunicação e a execução de operações.
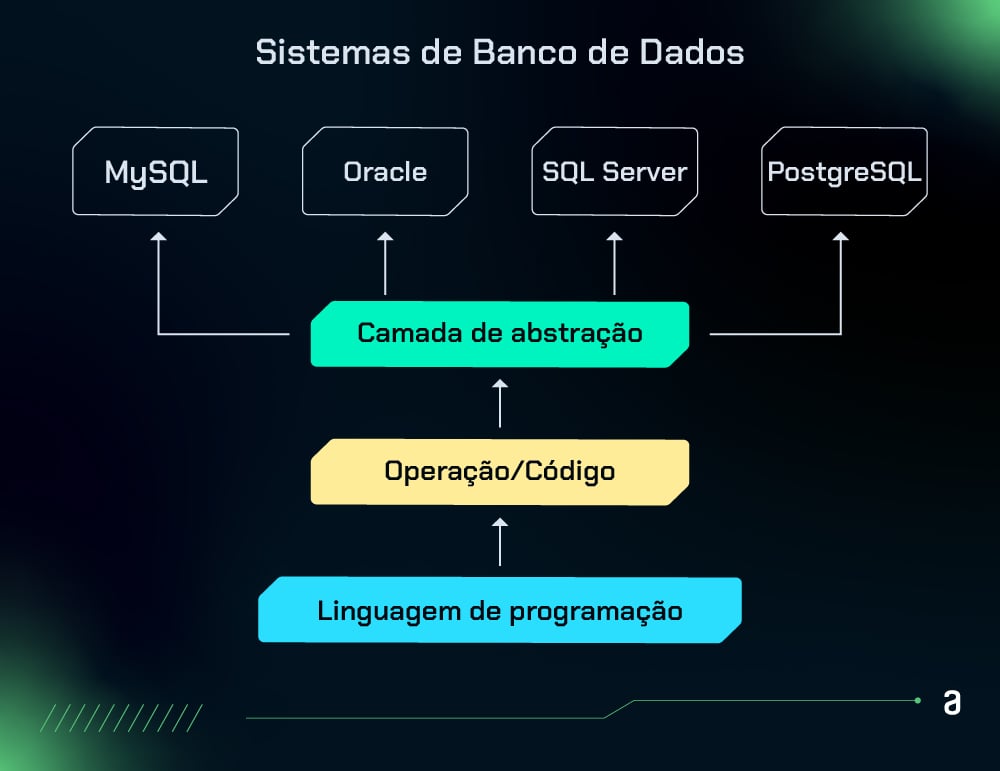
Essa abstração garante que operações de leitura e gravação sejam traduzidas em comandos SQL, compatíveis com o tipo de banco de dados configurado (MySQL, PostgreSQL, SQLite, etc.).
E, ela lida com tarefas como pooling de conexões, gerenciamento de sessões e tratamento de erros relacionados à conexão.
Dessa forma, você se concentra na lógica da aplicação sem se preocupar com os aspectos técnicos do banco.
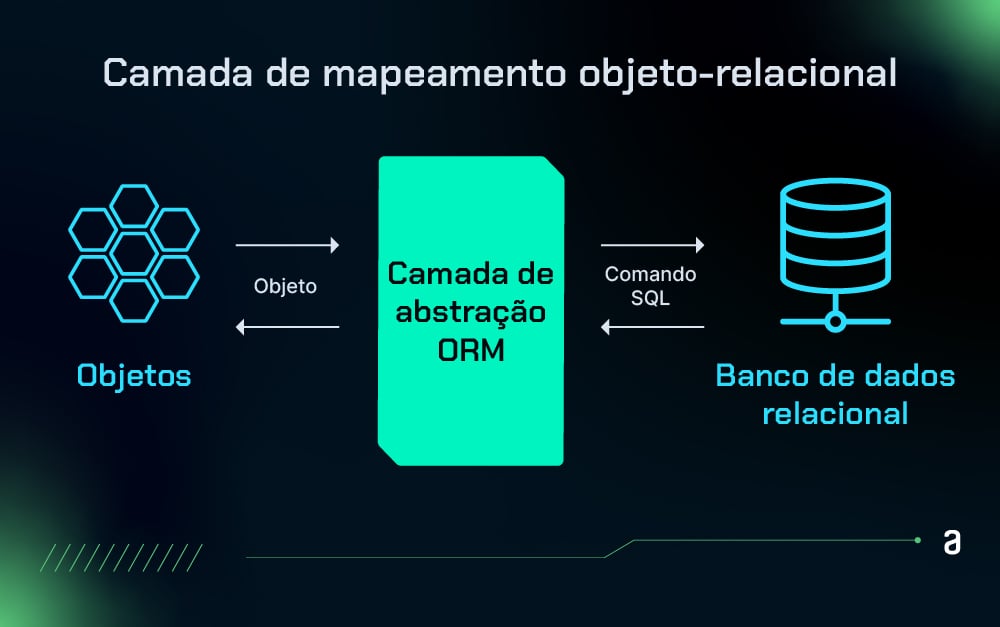
Camada de mapeamento objeto-relacional
Aqui, o ORM mapeia as classes da aplicação para as tabelas do banco de dados e vice-versa.
Isso significa que cada objeto no código é representado por uma linha na tabela do banco de dados.
Essa camada cuida de transformar os dados de um formato que a aplicação entende (objetos) para um formato que o banco de dados armazena (tabelas e registros), e realiza a operação inversa quando os dados são recuperados.
Camada de gerenciamento de transações
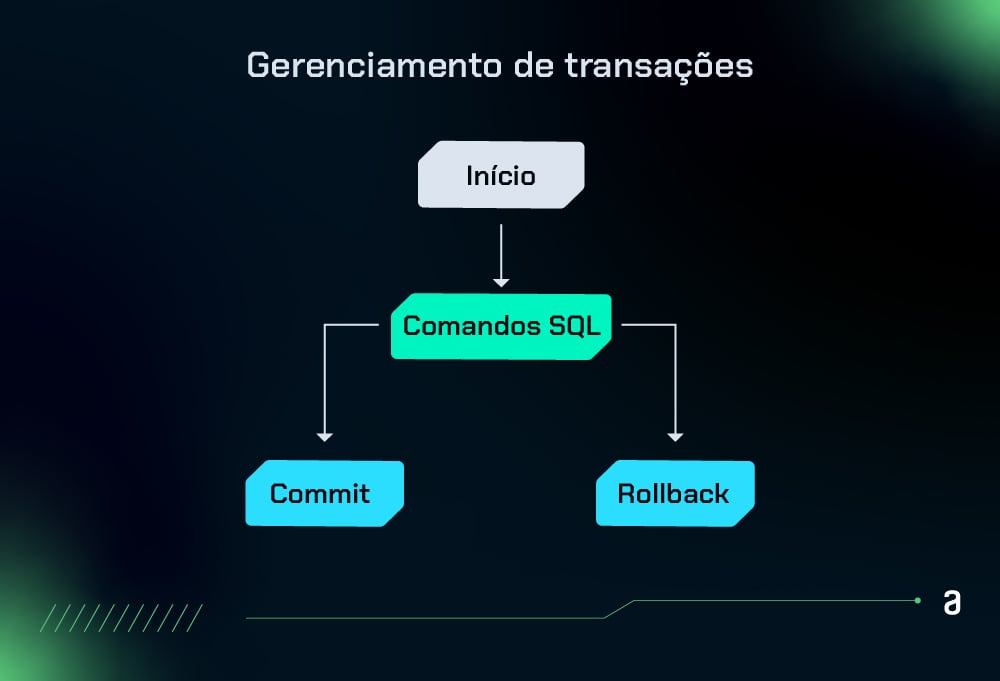
O gerenciamento de transações é importante para garantir que as operações de banco de dados sejam realizadas de forma segura e coesa.
Essa camada ajuda a controlar o início, a confirmação e o cancelamento de transações, assegurando que os dados não fiquem em um estado inconsistente em caso de falhas ou erros.
Em termos simples, é essa camada que garante que as mudanças feitas pelo código reflitam no banco de dados. Se um erro ocorrer no meio do processo, todas as alterações serão desfeitas.
Camada de consulta
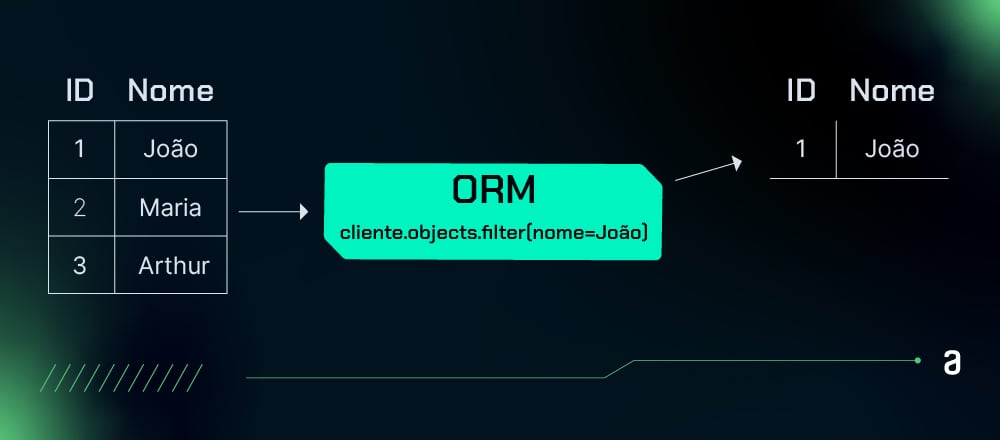
A camada de consulta é onde as operações de leitura e escrita são definidas. Em vez de escrever código SQL manualmente, você pode usar métodos do ORM para gerar queries de forma programática.
Isso permite que você se concentre na lógica da aplicação e deixe que o ORM trate da criação e execução das consultas de banco de dados.
Ela traduz comandos como Cliente.objects.filter(nome="João") em consultas SQL que o banco de dados entende e executa.
Camada de caching
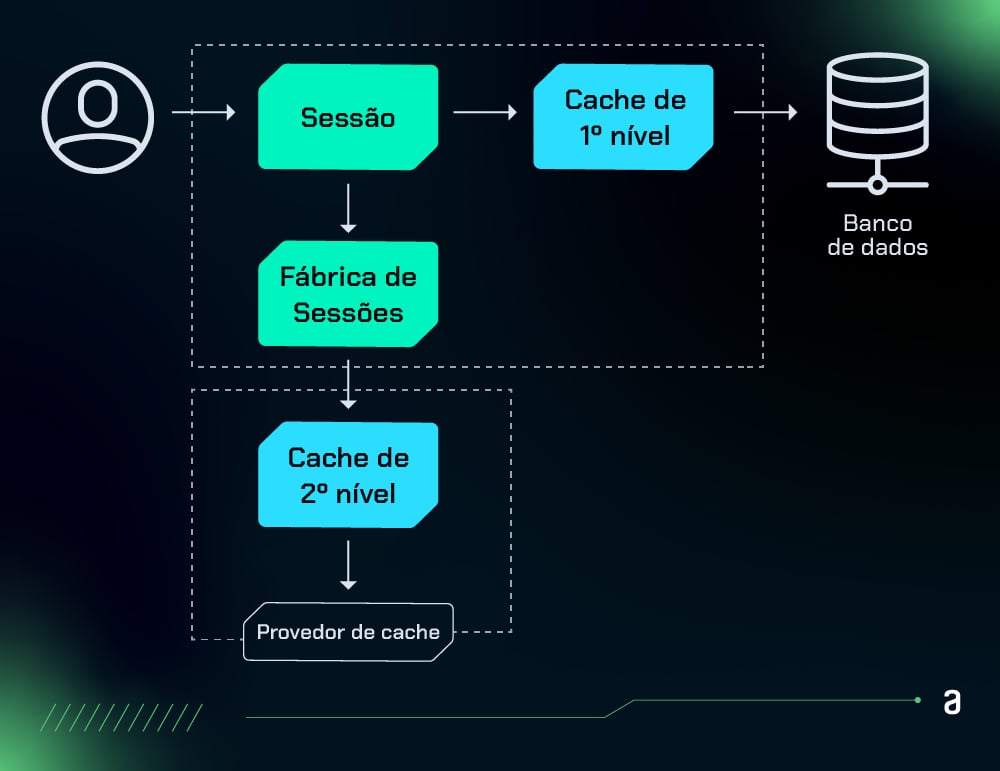
A camada de caching armazena em cache os resultados de consultas para reduzir a carga de trabalho do banco de dados e acelerar o acesso aos dados.
Essa camada ajuda a melhorar o desempenho da aplicação ao evitar consultas repetitivas ao banco e mantendo os dados mais acessíveis para operações futuras.
Ela age como uma “memória temporária” que agiliza a consulta aos dados e diminui o número de consultas feitas ao banco.
Por que usar ORM?
Agora que já vimos tudo isso, vamos conferir algumas motivações para usar ORM?
A interação com bancos de dados tradicionalmente envolve o uso de SQL bruto, que embora atenda a muitas necessidades, apresenta desafios à medida que a aplicação cresce.
Por exemplo, atualizar consulta por consulta é trabalhoso, e a criação manual de códigos SQL não é isenta de erros e também uma alteração na estrutura do banco pode exigir muitas modificações no código.
O ORM surge como uma solução para esses problemas, oferecendo uma abordagem mais prática para trabalhar com bancos de dados.
Como disse anteriormente, você escreve operações de banco de dados sem escrever SQL diretamente, permitindo focar na lógica da aplicação.
Isso simplifica a leitura e a escrita de dados e também o gerenciamento de mudanças estruturais, já que o ORM ajusta automaticamente as consultas necessárias.
Então, você já viu motivos para usar um ORM, bora nos aprofundar nas vantagens e desvantagens dessa abordagem?
Vantagens de usar ORM
Quando uma pessoa desenvolvedora decide usar um ORM, está optando por uma ferramenta que facilita a interação entre o código e o banco de dados, ajudando a manter tudo mais organizado.
Em vez de lidar diretamente com consultas SQL em cada parte do sistema, o ORM cria aquela ponte, que já mencionei aqui algumas vezes, traduzindo as interações com o banco de dados de forma simplificada.
Imagine que você precisa buscar informações do total que foi comprado por um determinado cliente, reunindo dados das tabelas clientes e pedidos.
Você pode usar algo parecido com o código abaixo:
const totalCompras = await Cliente.findOne({
where: { id: 1 },
include: {
model: Pedido,
attributes: [[sequelize.fn('SUM', sequelize.col('valor')), 'total']],
},
});
Essa consulta é mais legível e também mais segura, pois o ORM cuida automaticamente de detalhes como formatação, proteção contra injeções de SQL e otimização da query.
Outra grande vantagem é que o ORM faz com que as pessoas desenvolvedoras foquem na lógica do sistema, em vez de escrever e ajustar manualmente consultas SQL repetitivas.
Se for necessário, por exemplo, mudar o banco de dados de MySQL para PostgreSQL, o ORM torna essa transição muito mais simples, pois a maior parte do código já está abstrata e independente de um banco específico.
Isso dá flexibilidade para que as decisões sobre infraestrutura sejam feitas sem prejudicar o desenvolvimento.
E, como os modelos e relacionamentos são centralizados, é mais fácil para diferentes pessoas trabalharem juntas no mesmo projeto, sem o risco de conflitos de consultas SQL espalhadas pelo código. Isso também facilita a manutenção e evolução do sistema.
Se você também precisar fazer operações ao mesmo tempo de atualização e cadastro, com um ORM, tudo isso pode ser tratado em uma transação única, garantindo que, se algo der errado, nenhuma das alterações será aplicada, mantendo a integridade dos dados.
No final, usar um ORM é ganhar agilidade nos projetos, tornando a aplicação mais alinhada aos padrões do mercado e fácil de evoluir.
Desvantagens de usar ORM
Mesmo com todas as vantagens de se utilizar um ORM, existem algumas preocupações que devem ser levadas em conta para evitar problemas futuros.
A primeira, é o desempenho em consultas complexas, já que o ORM pode gerar consultas SQL menos otimizadas do que as escritas manualmente, o que impacta diretamente a performance.
Outro ponto importante é a abstração que pode fazer com que as pessoas percam o entendimento mais profundo sobre o banco de dados, dificultando otimizações ou ajustes finos quando necessários.
Isso significa que, mesmo que o ORM seja uma ferramenta muito utilizada no dia a dia, é importante também ter atenção ao seu uso para garantir que a aplicação saia ganhando e não se torne um ponto de gargalo no sistema.
Tipos de ORM
A seleção de um ORM varia conforme a linguagem de programação usada e as demandas específicas de cada aplicação.
Bora dar uma conferida nas opções populares para Java, Python, JavaScript e Node.js?

ORM em Java
Ao trabalhar com Java, a escolha de um ORM é guiada pelas especificidades do projeto. As opções disponíveis oferecem soluções que vão desde a simplicidade no mapeamento de dados até ferramentas mais avançadas para sistemas grandes.
Hibernate
O Hibernate ajuda desenvolvedores a criarem aplicações de forma mais simples, garantindo que os dados sobrevivam ao ciclo de vida do processo da aplicação.
Ele também possibilita a escrita de classes persistentes que seguem os conceitos da Programação Orientada a Objetos (POO), como herança, polimorfismo, associação e composição.
Como um framework de Mapeamento Objeto-Relacional (ORM), o Hibernate se preocupa com a persistência de dados no contexto de bancos de dados relacionais, usando JDBC.
E, o Hibernate é uma implementação da especificação Java Persistence API (JPA), podendo ser usado em qualquer ambiente que a suporte, como aplicações Java SE e servidores de aplicação Java EE, isso permite flexibilidade no uso em diferentes contextos.
Outro benefício é sua escalabilidade, projetado para funcionar em clusters de servidores de aplicação, viabilizando seu uso em sistemas que atendem desde centenas de pessoas usuárias até milhares.
É compatível com uma ampla gama de bancos de dados, como HSQL Database, MySQL, PostgreSQL, Oracle, Microsoft SQL Server, entre outros.
EclipseLink
O EclipseLink é um projeto de código aberto da Eclipse Foundation que oferece uma implementação completa e compatível com a Java Persistence API (JPA), com suporte a todos os recursos obrigatórios da especificação, além de funcionalidades avançadas que vão além do padrão.
O EclipseLink viabiliza que pessoas desenvolvedoras Java interajam com diversos serviços de informação, como bancos de dados, web services, objetos XML, entre outros.
Assim, ele não se limita apenas à implementação do JPA, mas também inclui outros padrões como JAXB.
Além disso, ele se destaca por incluir um sistema de cache em nível de objeto, com coordenação de cache distribuído, o que melhora significativamente o desempenho em aplicações grandes.
O EclipseLink é compatível com uma ampla variedade de bancos de dados, como Oracle, MySQL, PostgreSQL, Sybase, entre outros, garantindo versatilidade para diferentes demandas de projetos.
Essa diversidade de suporte permite que ele seja integrado a soluções legadas ou atuais, se adaptando a necessidades específicas.
Ele também suporta mapeamentos avançados, possibilitando configurações detalhadas para atender a cenários complexos de persistência de dados.
Outro diferencial é a disponibilidade de opções de bloqueio otimista e pessimista, proporcionando maior controle sobre a concorrência em transações.
ORM em Python
Python conta com diversas opções de ORM, cada uma voltada para diferentes tipos de projetos.
Desde frameworks flexíveis que permitem controle total até alternativas que priorizam a simplicidade e a legibilidade… Ou seja, há opção para todos os gostos!
SQLAlchemy
SQLAIchemy é uma biblioteca que facilita a comunicação entre programas Python e bancos de dados, adotando o paradigma ORM. Mas o que isso significa?
Isso significa que transforma classes e objetos Python em tabelas e registros nos bancos de dados relacionais, além de converter chamadas de métodos em comandos SQL de forma automática.
Assim como os outros ORMs, ele veio para reduzir a complexidade do desenvolvimento, oferecendo uma interface consistente para interagir com diferentes banco de dados, como PostgreSQL, MySQL, SQLite, MariaDB e Oracle, isso elimina a necessidade de escrever consultas SQL diretamente, possibilitando que as pessoas desenvolvedoras manipulem dados usando apenas Python, o que resulta em redução significativa de erros comuns, como falhas de sintaxe ou vulnerabilidade de injeção de SQL.
É ideal para sistemas que estão em constante evolução, pois equilibra bem a simplicidade com o controle necessário para gerenciar a persistência de dados.
Pony ORM
O Pony é um ORM que possibilita as pessoas desenvolvedoras trabalharem com o conteúdo de um banco de dados na forma de objetos.
Ele facilita o mapeamento das tabelas do banco de dados para classes e objetos Python, fazendo com que o processo de interação com o banco seja mais intuitivo e alinhado com o paradigma de programação orientada a objetos.
Ele se destaca por sua sintaxe simples e intuitiva, tornando a escrita de consultas mais acessível.
Ele também lida automaticamente com otimizações, garantindo que as consultas sejam executadas de forma mais rápida sem a necessidade de ajustes adicionais.
Atualmente, o Pony oferece suporte a cinco tipos de bancos de dados: SQLite, MySQL, PostgreSQL, CockroachDB e Oracle.
Uma das características mais interessantes do Pony é a possibilidade de interagir com o banco de dados usando Python puro. Muito bom, né?
Assim as pessoas desenvolvedoras familiarizadas com Python podem escrever consultas com expressões geradoras ou funções lambda, que são convertidas em SQL, proporcionando uma experiência de desenvolvimento mais fluida.
ORM em Node.JS
Com a popularidade do Node.js, surgiram ferramentas específicas para gerenciar bancos de dados de forma prática.
Nesse ambiente, os ORMs atendem a diferentes necessidades, desde projetos simples até aplicações complexas que demandam controle avançado. Vamos conhecer dois deles agora!
Prisma
O Prisma é uma solução de código aberto, que também veio para facilitar a comunicação com o banco de dados.
Uma das características mais interessantes do Prisma é a sua capacidade de gerar um esquema de banco de dados de forma automática.
Ele funciona como um mapa, onde você define as tabelas e as relações entre elas, tudo em um arquivo chamado schema.prisma.
Ele suporta diversos tipos de banco de dados, como PostgreSQL, MySQL, SQLite, MariaDB e outros.
Isso quer dizer que você pode começar com um banco de dados mais simples e depois migrar para um mais completo sem grandes dores de cabeça.
TypeORM
O TypeORM é um projeto de código aberto que pode ser executado em diversas plataformas, como Node.js, navegadores, Cordova, Ionic, React Native, Expo e Electron, entre outras.
Ele é compatível com TypeScript e JavaScript (ES2021), aproveitando os recursos mais recentes dessas linguagens para facilitar o desenvolvimento de aplicações que utilizam bancos de dados.
Também é compatível com uma ampla gama de banco de dados, incluindo MySQL, MariaDB, Postgres, CockroachDB, SQLite, Microsoft SQL Server, Oracle, entre outros.
E se você prefere bancos NoSQL, ele também dá suporte ao MongoDB. Ou seja, com ele, você não vai ficar sem opções.
Seja para pequenos projetos com poucas tabelas ou aplicações empresariais de grande porte que envolvem múltiplos bancos de dados, o TypeORM oferece suporte abrangente.
E um dos diferenciais dele é suportar os padrões Active Record e Data Mapper; essa característica oferece para as pessoas desenvolvedoras liberdade de escolher a abordagem mais adequada para a estruturação do código, seja priorizando simplicidade ou separação de responsabilidades.
Como aprender sobre ORM
Ufa! Foi informação à beça, né? Mas calma, a jornada não para por aqui. Agora é hora de entender como estudar sobre ORM e mergulhar mais ainda no assunto!
Se você quer aprender mais sobre ORM e como aplicar esse conceito em seus projetos, a Alura oferece diversos cursos que podem te ajudar.
Vem comigo conferir alguns cursos que podem ser o próximo passo para aprimorar suas habilidades.
Cursos da Alura
- ORM com Node.js: desenvolvendo uma API com Sequelize e SQLite
- ORM com Node.js: avançando nas funcionalidades do Sequelize
- Persistência com JPA: Hibernate
- Nest.js: Persistindo dados com TypeORM e PostgreSQL
Esses cursos são ótimos para levar seu conhecimento de ORM para o próximo nível e aplicar essas habilidades de maneira prática em seus projetos.
Até a próxima e bons estudos!
Referências
- O que é ORM (português, gratuito, youtube): vídeo explicativo sobre o conceito de ORM e sua aplicação no desenvolvimento de software
- Hibernate Documentação (inglês, gratuito, site): documentação completa e atualizada do Hibernate
- EclipseLink (inglês, gratuito, site): guia detalhado sobre conceitos e uso do EclipseLink para mapeamento e persistência em Java
- SQLAlchemy (inglês, gratuito, site): introdução prática e objetiva ao ORM do SQLAlchemy, com exemplos para iniciar rapidamente
- Pony ORM (inglês, gratuito, site): documentação completa do Pony ORM, abordando conceitos, instalação e exemplos de uso para trabalhar com banco de dados em Python
- Object-Relational Mapping (ORM) in Software Development (inglês, gratuito, site): visão geral dos conceitos de ORM, com foco em sua aplicação prática no desenvolvimento de software
- 3 Opções de ORMs para Aplicações Node.js (português, gratuito, site): artigo sobre os principais ORMs para aplicações Node.js, com comparações e dicas de uso