

Atualmente, estamos em um cenário em que modelos, como o GPT, por exemplo, podem entender e gerar texto de forma quase humana, respondendo perguntas complexas e participando de conversas naturais.
Quando o ChatGPT se popularizou, em meados de 2022, o assunto Inteligência Artificial (IA) passou a ser muito conhecido. Porém, a ciência por trás dessa tecnologia já vem de longos anos de pesquisa.
Os grandes avanços recentes são possíveis graças a uma inovação chamada Transformers, uma arquitetura que mudou completamente o jogo da Inteligência Artificial ao ser publicada em 2017 e introduzir o mecanismo de atenção, que elevou consideravelmente a capacidade de modelos de linguagem compreenderem contexto na linguagem natural.
Neste artigo, vamos explorar como os Transformers funcionam e por que essa tecnologia está por trás dos avanços mais impressionantes em IA.
Vamos lá?
Breve história da arquitetura transformers
A arquitetura Transformers foi proposta em 2017 no artigo Attention is All You Need (“Atenção é Tudo que Você Precisa”), escrito por pesquisadores da Google.
Esse trabalho introduziu o uso de uma estrutura que revolucionou a forma como o Deep Learning estava sendo conduzido até então: mecanismos de atenção que compreendem contexto.
Antes disso, outros tipos de redes neurais profundas eram utilizadas para resolver tarefas de Inteligência Artificial, como as Redes Neurais Recorrentes (RNNs) e LSTMs.
Cada modelo precisava de um treinamento supervisionado para solucionar uma tarefa específica, como classificação de texto ou análise de sentimento, por exemplo.
Esses modelos funcionam em uma arquitetura sequence-to-sequence, ou seja, trabalham sequencialmente, analisando uma palavra após a outra.

Benefícios do Transformers
Essas arquiteturas continuam sendo utilizadas hoje em dia e se mantém muito relevantes, mas os mecanismos de atenção do Transformers trouxeram o grande benefício da paralelização.
Com a paralelização, a sentença inteira é vista ao mesmo tempo. Isso traz uma série de vantagens:
- Maior velocidade de treinamento
- Eficiência no reconhecimento de dependência entre palavras
- Melhoria no reconhecimento de padrões
- Capacidade de analisar problemas não sequenciais
GPT e BERT
Em 2018, um ano após a publicação do artigo que descreve a arquitetura Transformers, os modelos GPT e BERT foram lançados.
- GPT é sigla para Pré-Treinamento Generativo. Esse modelo, desenvolvido pela OpenAI, é a base para o GPT amplamente conhecido hoje através do ChatGPT.
- BERT, desenvolvido pela Google, está presente no dia a dia de quem usa os serviços da empresa. A partir de 2019, o BERT foi implementado nos serviços de busca para otimização do SEO. Desde então, tem sido integrado nas traduções automáticas, classificação de e-mails, interações do Google Assistente, entre outros.
GPT e BERT são representantes importantes dentre diversos modelos que seguem a arquitetura Transformers. Esse foi apenas o início de um grande salto na área de pesquisa em Machine Learning e Inteligência Artificial.
Para parametrizar o tamanho impacto dos modelos Transformers, podemos analisar o número de citações que o artigo tem recebido ao longo dos anos, desde seu lançamento.
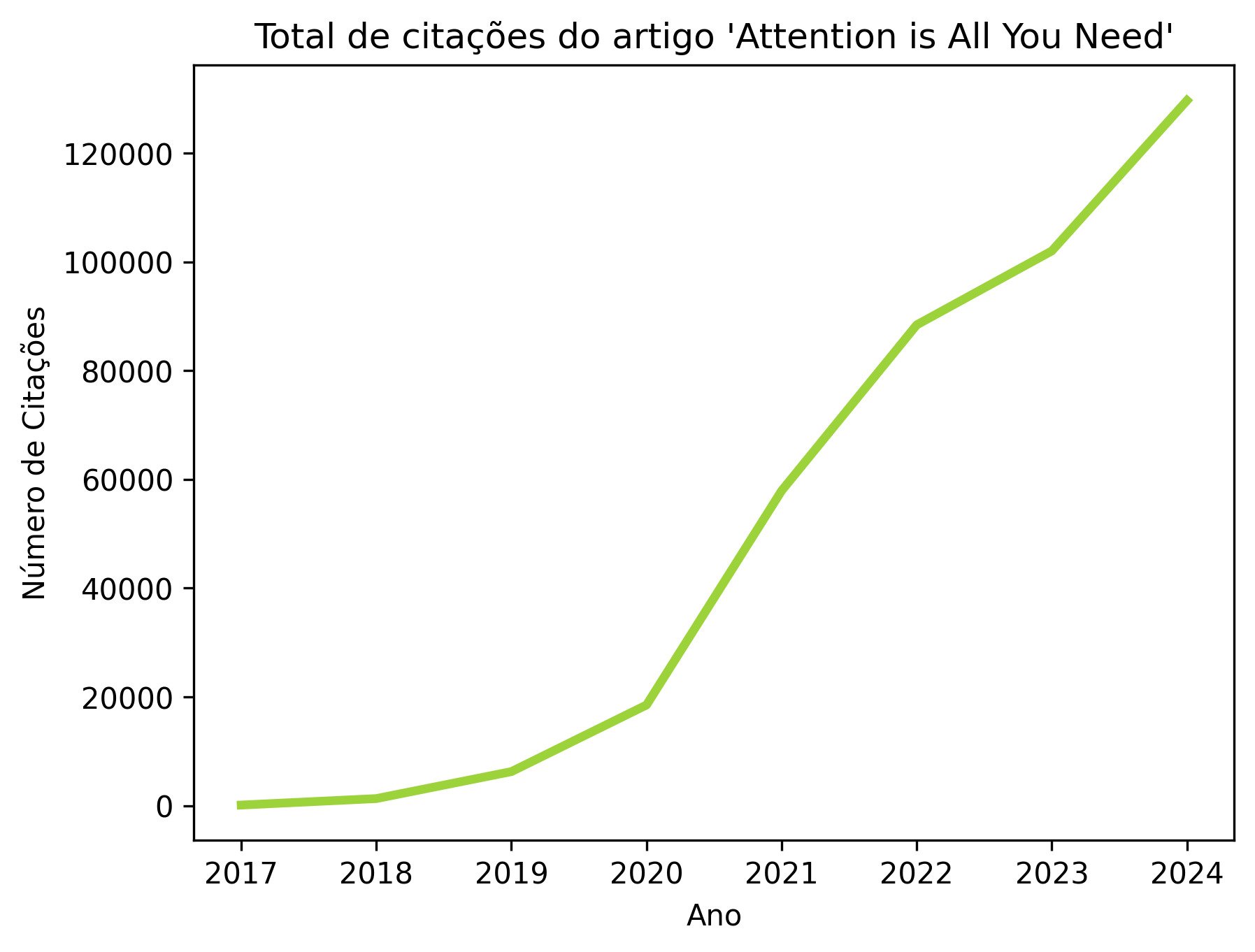
Em 2020, esse número já estava nas dezenas de milhares e, desde então, tem crescido rapidamente. No momento em que escrevo este artigo, são mais de 126 mil citações!
Como o Transformers funciona?
A transformação já começa antes mesmo de o texto entrar na estrutura do Transformer!
Imagine que queremos traduzir a frase “Dani gosta de café” para o espanhol, como no Google Tradutor. Recebemos a resposta “a Dani le gusta el cafe” em um piscar de olhos, mas, internamente, muita coisa acontece.
Quando o comando “Dani gosta de café” é enviado, ele é primeiro quebrado em pedacinhos de palavras que mantém o significado, os tokens. Então, os tokens precisam ser convertido para um formato numérico, que chamamos de embeddings.
Um embedding é uma sequência numérica que representa o significado da palavra, sua semântica, posição dentro do texto, contexto, etc. Essa sequência passa por diversas transformações dentro do modelo.
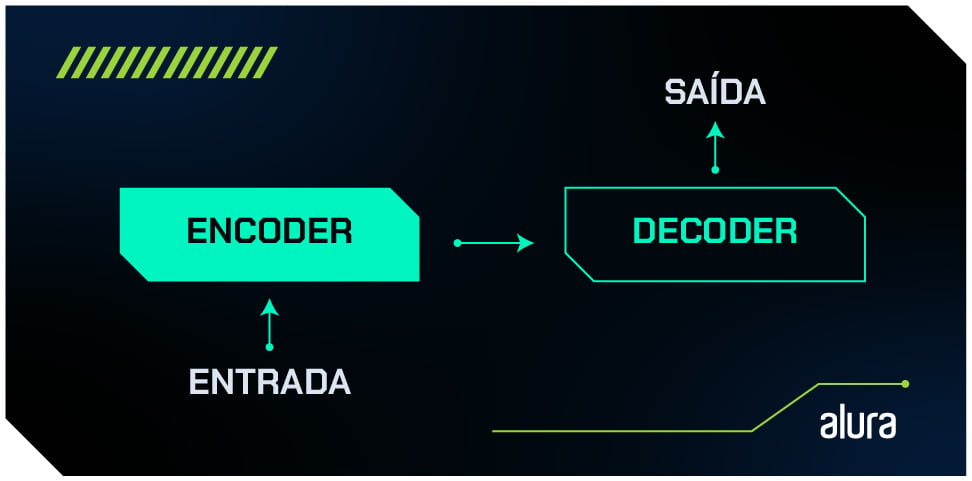
Com os embeddings formados, estamos prontos para entrar de fato na arquitetura Transformers.
A arquitetura é composta por dois mecanismos principais: o encoder e o decoder. Em termos simples, o encoder processa a entrada (por exemplo, uma sentença) e o decoder gera a saída (que pode ser uma tradução, a continuação de um texto, etc).
Cada um desses mecanismos é repetido algumas vezes, formando um conjunto de encoders e outro conjunto de decoders, que processam as informações uma após a outra. Essa repetição dos mecanismos faz com que o resultado final seja de maior qualidade pois, a cada repetição, os resultados ficam mais assertivos.
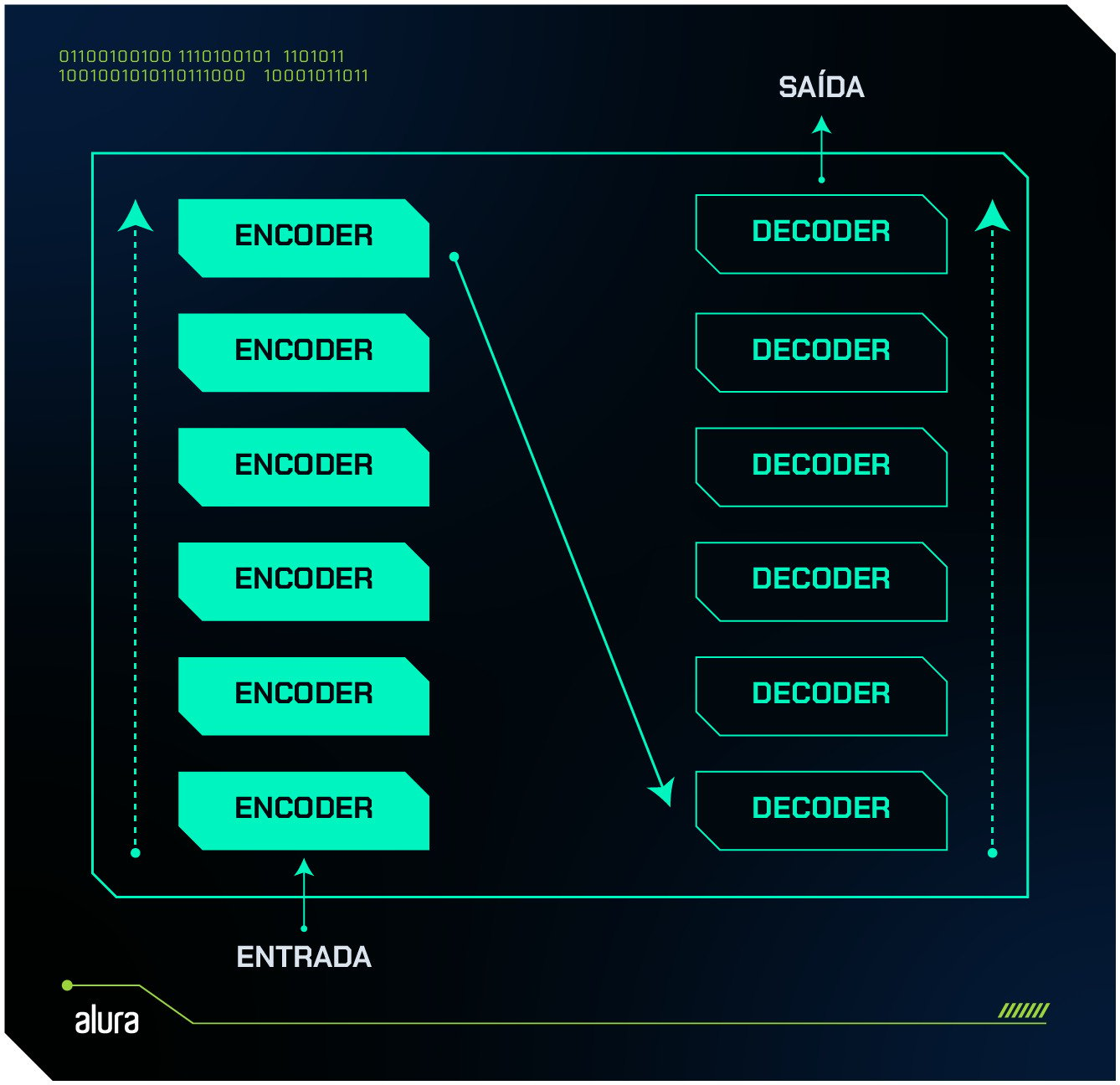
Além desses dois componentes, também temos uma camada chamada de language modeling head, responsável pelo processamento final do texto.
Cada mecanismo - encoder, decoder e language modeling head - possui subcomponentes importantes, que veremos com mais detalhes a seguir.
A imagem abaixo mostra a anatomia completa do modelo, com cada mecanismo e seus subcomponentes.
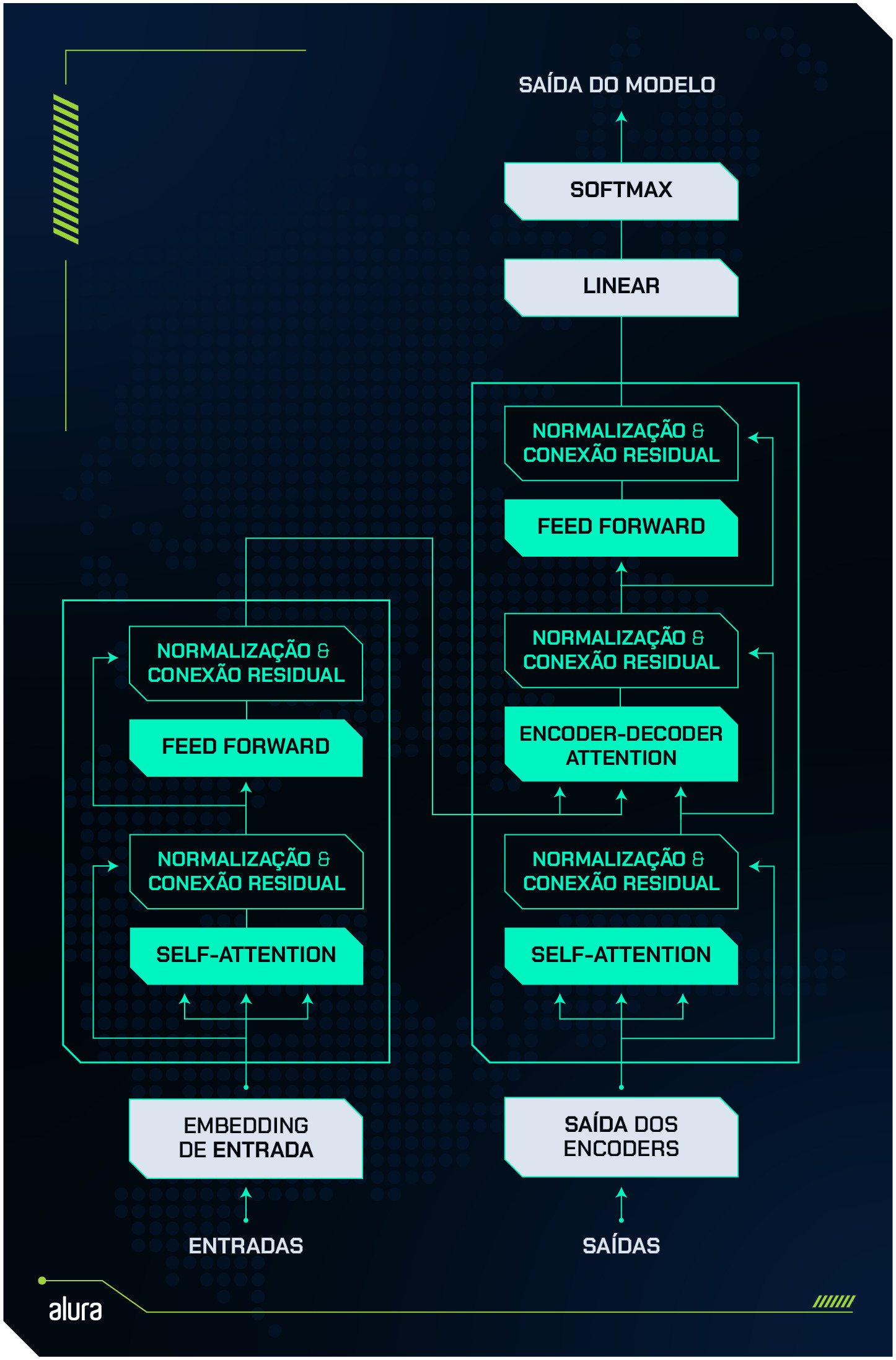
Curiosidade: Modelos baseados no Transformer nem sempre utilizam todos os componentes. O BERT, por exemplo, utiliza apenas o encoder, e o GPT utiliza só o decoder.
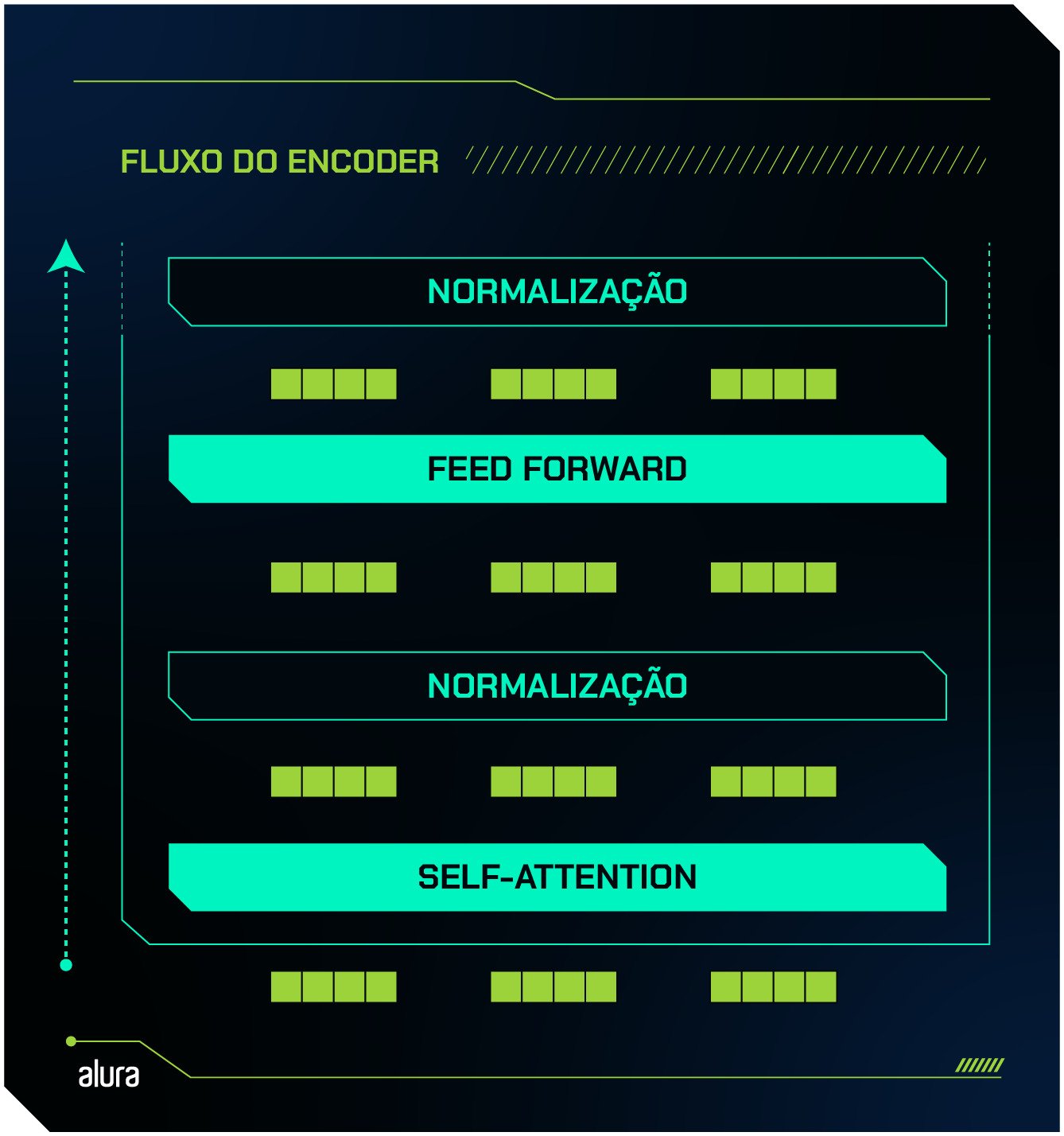
O processo de codificação - Encoder
A função do encoder é “entender” o texto de entrada. Para isso, dentro do encoder existem duas camadas principais:
- Self Attention: o mecanismo de atenção que identifica quais palavras de uma sentença estão mais relacionadas entre si.
- Feed forward: uma rede neural tradicional que processa as informações extraídas da camada self-attention, refinando a compreensão do contexto.
Além dessas, temos duas camadas auxiliares, são elas:
- Normalização: um cálculo que mantém as saídas de uma camada em formato adequado para a próxima.
- Conexões residuais: um mecanismo que faz o “resgate” do input, garantindo que o contexto inicial não seja perdido ao longo do processamento.
O embedding inicial passa pela camada de self-attention, é normalizado e recebe conexões residuais. Em seguida, passa pela camada feed-forward, onde é novamente normalizado e recebe conexões residuais. Segue comigo que vou explicar melhor como cada etapa funciona.
Mecanismo de Self Attention
O mecanismo de atenção permite que o modelo capture as sutilezas de contexto e significado de um texto.
Simultaneamente, o mecanismo de atenção calcula a relação de cada palavra individual com todas as outras palavras da frase. Por exemplo, na frase:
Dani gosta muito de café, mas só se for coado.
O modelo precisa entender que "coado" está relacionado a "café", e não a "Dani" ou "gosta", que estão mais fortemente relacionadas entre si. Ele atribui pesos diferentes a cada palavra, dependendo dessas relações. Nesse caso, "coado" recebe um peso maior em relação a "café", porque essas palavras estão diretamente conectadas no contexto da frase.
O bloco de self-attention funciona como se o modelo observasse diferentes aspectos do contexto simultaneamente, cada um focando em detalhes específicos. Esse mecanismo é chamado multi-headed attention: em vez de calcular a relevância de uma palavra para o contexto apenas uma vez, o modelo faz isso várias vezes, com cada "camada" analisando a frase sob diferentes perspectivas.
Por exemplo, em "Dani gosta muito de café, mas só se for coado", uma das camadas de atenção pode se concentrar na relação entre "coado" e "café", enquanto outra pode focar na conexão entre "Dani" e "gosta".
Esse mecanismo permite uma compreensão mais rica e profunda das múltiplas relações contextuais presentes na linguagem natural.
Normalização e Conexões Residuais
Assim que o processamento nas “múltiplas mentes de atenção” é feito, cada única mente gera uma saída individual a partir do seu “ponto de vista”, contendo diversas informações sobre semântica, significado e contexto.
Porém, a próxima camada precisa de uma entrada única. Aí que entra a normalização: alguns cálculos são feitos para que todas essas informações sejam “compactadas” novamente ao formato utilizado em todas as camadas de codificação.
Nessa etapa, também acontecem as conexões residuais. O que acontece é que os embeddings iniciais, sem nenhum processamento, são somados às saídas dos mecanismos de atenção. Dessa forma, o próximo mecanismo recebe as informações do processamento de atenção, mas também fica sabendo como o texto de entrada é originalmente.
Ou seja, os embeddings iniciais estarão sempre dentro dos encoders, não só apenas no primeiro. Isso garante que o contexto original não se perca.
O próximo passo é o bloco Feed forward.
Mecanismo Feed Forward
A rede neural Feed forward é uma das arquiteturas mais antigas e fundamentais de Machine Learning. Esse mecanismo contém múltiplas camadas de neurônios e, nele, a informação sempre flui em uma única direção.
No Transformer, a camada Feedforward faz um refinamento das saídas dos mecanismos de atenção. Nessa parte, o contexto não é analisado, o foco é no processamento das informações já capturadas.
Após a passagem pela rede Feedforward, a normalização acontece novamente. Então, o processo se repete em cada um dos encoders presentes no modelo.
A codificação está pronta após passar por todos os encoders presentes no conjunto do modelo.
O momento da decodificação (Decoder)
Chegamos no momento da geração da resposta!
A estrutura do decoder se assemelha à que vimos anteriormente, no encoder, com algumas diferenças importantes.
- Self-Attention: o mecanismo de atenção que vimos anteriormente. Porém, esse tem uma atenção parcial.
- Encoder-Decoder Attention: outro mecanismo de atenção.
- Feedforward: a mesma estrutura presente no encoder. Um mecanismo simples de rede neural que tem a função de refinar as saídas dos mecanismos de atenção.
- Normalização e conexão residual: camadas intermediárias que funcionam como no encoder, mantendo o padrão e o contexto inicial.

No encoder, vimos que todas as representações são processadas de forma paralela, possibilitando que o entendimento do contexto seja tão exato.
Já no decoder, as palavras são geradas uma de cada vez, em sequência. Mas o contexto também é considerado! Além de observar a entrada (ou seja, os embeddings que foram entregues pelo encoder), o decoder também trata de observar as saídas que já foram geradas por ele mesmo, implicando na existência de dois mecanismos de atenção.
Vamos compreender melhor cada um deles a seguir.
Self-Attention
Nessa camada, o mecanismo self-attention realiza um comportamento chamado de autorregressivo.
A atenção é focada apenas nas palavras que já foram geradas anteriormente pelo decoder.
Voltando ao exemplo da tradução da frase “Dani gosta de café” para o espanhol. A cada processamento, o mecanismo de atenção vai ter uma visão diferente:
- Token especial para iniciar a geração de texto
- “A”
- “A Dani”
- “A Dani le”
- “A Dani le gusta”
- “A Dani le gusta el”
- “A Dani le gusta el cafe”
- Token especial para finalizar o processamento.
Enquanto isso, os embeddings das palavras que ainda serão geradas estão mascarados, ou seja, ocultos, para que o modelo não veja informações futuras durante a geração. Assim, o modelo respeita a ordem de geração do texto.
Encoder-Decoder Attention
É esse componente que recebe todas as informações que estão vindo do encoder, que processou a entrada completa.
A atenção também se volta às palavras que já foram geradas, mas com a grande responsabilidade de transformar o contexto inicial do comando em uma resposta consistente e coerente.
Normalização, Conexões Residuais e Feed forward
Essas camadas funcionam de forma similar ao que acontece no encoder. O cálculo de normalização mantém os embeddings em um formato adequado e o mecanismo feed forward faz o refinamento.
As conexões residuais têm uma leve diferença. No decoder, elas continuam entre as camadas principais (self-attention, encoder-decoder attention e feed forward) e conectam as informações que foram processadas anteriormente dentro do próprio decoder.
Essa sequência de processamento é repetida em todos os decoders empilhados no modelo. A saída final é uma série de representações numéricas da interpretação do modelo sobre as palavras que devem ser geradas.
Language Modeling Head
A language modeling head é a última camada de processamento do Transformer e é composta por duas partes principais:
- Linear: conecta a saída dos decoders ao vocabulário do modelo.
- Softmax: calcula a probabilidade de cada palavra ser a próxima na sequência.
A camada linear recebe as representações matemáticas geradas pelos decoders, chamadas de vetores. Esses vetores são versões mais complexas e refinadas dos embeddings criados pelos encoders.
Nessa etapa, cada um dos vetores é mapeado pela camada linear, que tem acesso ao vocabulário completo do modelo. Para cada palavra desse vocabulário, o vetor recebe uma pontuação que reflete a probabilidade de essa palavra ser a próxima na sequência gerada.
Em seguida, a camada softmax processa as pontuações atribuídas pela camada linear e as converte em probabilidades. A palavra com probabilidade mais alta será escolhida como a próxima palavra gerada pelo modelo.
E, então, a geração de texto acontece!
Os números de camadas, cabeças de atenção, tamanho do vocabulário, escolha de probabilidades diferentes e muitas outras características, são hiperparâmetros de modelos Transformers. Isso quer dizer que podem ser configuradas no treinamento do modelo e afetam o seu desempenho. Existem métodos que podem ser utilizados para se encontrar o ajuste ideal de hiperparâmetros.
Como o modelo é treinado?
Inicialmente, todos os modelos Transformers são treinados como modelos de linguagem auto-supervisionados, ou seja, não há intervenção humana na identificação dos dados.
O próprio modelo aprende a partir de uma quantidade muito grande de texto não-processado, identificando padrões na linguagem.
Dessa forma, há uma compreensão estatística profunda do modelo acerca do comportamento da linguagem natural. O modelo já pode prever próximas palavras ou identificar palavras faltantes, por exemplo.
Após esse treinamento inicial, acontece o processo chamado transfer learning (aprendizado por transferência), em que o modelo é ajustado para tarefas específicas através de uma base de dados menor, em que os dados estão rotulados por humanos. Essa é a fase supervisionada do treinamento do modelo.
Essas tarefas podem ser tradução, classificação de texto ou respostas para perguntas.
Alguns usos de modelos Transformers ainda podem contar com técnicas de refinamento contínuo através de feedback humano.

Recursos
Em geral, os modelos Transformers são muito grandes e complexos. O GPT4, por exemplo, pode ter sido treinado com centenas de terabytes de informação textual, considerando a quantidade de 170 trilhões de parâmetros utilizada nesse modelo.
GPT-3 e GPT-4: o que é, diferenças e como a inteligência artificial pode te ajudar
Modelos como esse demoram de semanas a meses para serem treinados, exigem infraestrutura robusta e podem ter impactos ambientais massivos, dependendo do tipo de energia utilizado.
Nesse sentido, a plataforma Hugging Face desempenha um papel essencial ao disponibilizar um ambiente em que diversos modelos pré-treinados estão hospedados para uso.
A plataforma, inclusive, desenvolveu a biblioteca Transformers que fornece os recursos necessários para o uso de diversos modelos pré-treinados, além de um vasto repositório de datasets, promovendo a colaboração e o avanço dos conhecimentos coletivos em Inteligência Artificial e Aprendizado de Máquina.

Inicialmente, os modelos foram desenvolvidos para lidar com Processamento de Linguagem Natural. Hoje em dia, atuam também em visão computacional com imagens, vídeos e no processamento de áudio.
O modelo Vision Transformer, por exemplo, teve sucesso treinando um modelo com arquitetura Transformer para processar matrizes de pixels e trabalhar com reconhecimento de imagem.
Veja algumas das tarefas que são desempenhadas por modelos Transformer:
- Classificação de Imagens
- Geração de Texto
- Reconhecimento de Entidades Nomeadas
- Detecção de Fraude
- Classificação de Texto
- Conversão de fala para texto
- Assistente virtual e chatbots
- Correção gramatical
- Geração de código
- Pesquisa semântica
A arquitetura Transformers redefiniu o estado da arte em processamento de linguagem natural e abriu portas para aplicações impressionantes em Inteligência Artificial.
Nesse artigo, conhecemos a anatomia dessa arquitetura e como o fluxo de informação se transforma em cada camada de encoders e decoders.
A era de Inteligência Artificial que vivemos atualmente se deve ao avanço científico proporcionado pelo artigo Attention is All You Need e por todas as pesquisas que a precederam.
Agora que você conhece a fundo o que são Transformers, explore suas diversas aplicações e continue estudando sobre modelos de IA na formação Dominando Hugging Face com Python aqui da Alura.
Abraços!
