AWS Data Lake: análise de dados com Athena e Quicksight
Preparando o ambiente - Apresentação
Olá! Eu sou a Ana Hashimoto e irei te acompanhar ao longo do curso AWS Data Lake: Análise de dados com Athena e QuickSight, destinado a pessoas que desejam aprender sobre AWS na prática.
Audiodescrição: Ana se descreve como uma mulher branca de cabelo preto liso abaixo dos ombros, olhos pretos e sobrancelhas pretas. Ela veste uma blusa preta e está em um cenário de fundo branco com iluminação verde.
O que vamos aprender?
Neste curso, vamos construir um dashboard utilizando o AWS QuickSight, uma ferramenta de visualização de dados na nuvem que possui diversos recursos para a criação de gráficos e tabelas personalizadas, que facilitam a geração de insights para tomadas de decisão.
Com este curso, você conseguirá criar um dashboard completo na AWS, utilizando os melhores recursos de DataViz. Nele, vamos construir visões quantitativas, qualitativas, e tabelas analíticas.
Além disso, aprenderemos sobre recursos de inteligência artificial e também sobre a comunidade do AWS QuickSight.
Para melhor aproveitamento do curso, recomendamos que você tenha conhecimento prévio em Cloud Computing (Computação em Nuvem).
Vamos começar a nossa jornada?
Preparando o ambiente - Entendendo a pipeline
Para criarmos a visualização de dados com a AWS QuickSight, primeiramente, precisamos entender como será a arquitetura e quais serão os serviços utilizados para isso.
Entendendo a pipeline
Nos cursos anteriores, fizemos a ingestão das informações do site Data Boston diretamente na camada bronze da AWS. Depois, realizamos alguns tratamentos e padronizações e salvamos na camada silver. Por fim, fizemos algumas harmonizações e salvamos na camada gold.
Agora que temos os dados tratados e harmonizados, podemos criar a visualização deles. Nesse cenário, nosso desafio será o seguinte:
Como obter insights a partir dos dados do Data Boston para auxiliar as lideranças nas tomadas de decisão?
Para isso, vamos construir um dashboard completo na AWS QuickSight, no qual criaremos várias visualizações, como gráficos, tabelas, planilhas, entre outras.
Nesse caso, utilizaremos a AWS QuickSight, pois construímos toda a arquitetura na AWS. Porém, no mercado, há diversas outras ferramentas para visualização de dados, como o Tableau, o Power BI, o ClickView, entre outros serviços.
Além disso, iremos utilizar o conceito de Data Driven, em que a empresa utiliza os dados para tomadas de decisões. Por isso, focaremos em obter insights através destes dados.
Compreendendo a arquitetura da formação
Agora vamos entender um pouco a arquitetura e como faremos a construção do dashboard. A seguir, temos o desenho da arquitetura completa da nossa formação, contendo todos os cursos:
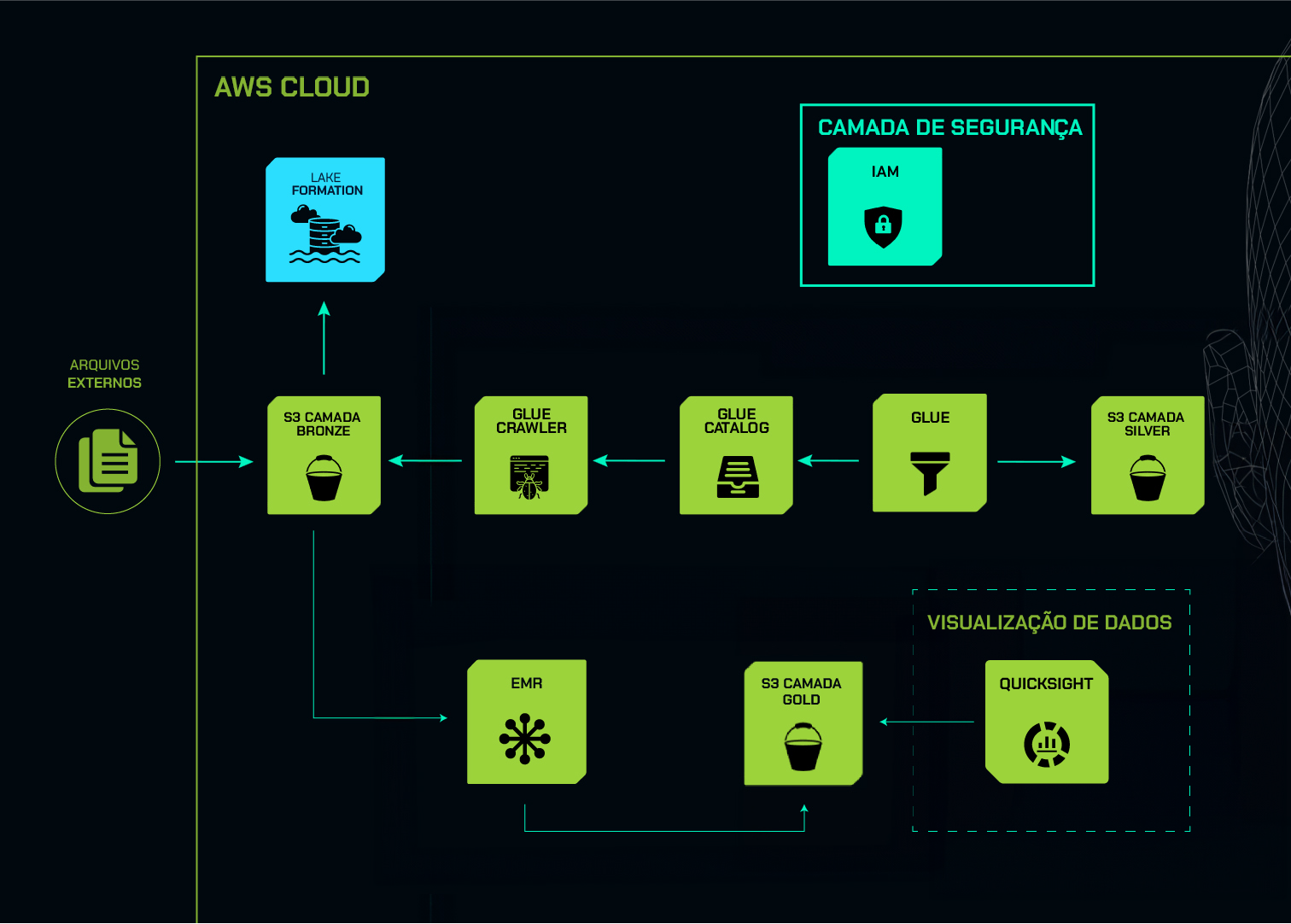
Este curso é representado pelo quadrado pontilhado no canto inferior direito do diagrama, que se refere exclusivamente ao pilar de visualização de dados com a AWS QuickSight. Porém, para chegarmos até esse momento, foi necessário passar por uma série de serviços.
Primeiramente, há um ícone à esquerda representando o pilar de arquivos externos, que são as informações do site Data Boston.
A partir disso, fizemos a ingestão diretamente no Bucket S3, na camada bronze, representado pelo ícone à direita.
O retângulo maior, que envolve todos os ícones, representa a camada AWS. Assim, saímos do contexto on-premises e entramos na AWS com a AWS S3.
Utilizamos também o serviço de Lake Formation, que apresenta a camada de data lake na AWS. Além disso, usamos um serviço chamado Glue Crawler, onde fizemos a extração das informações do Bucket S3, e salvamos o catálogo de dados, isto é, o Glue Data Catalog.
Depois, utilizamos o AWS Glue, onde fizemos o ETL e a preparação dos dados para depois salvar na camada silver, no Bucket S3, também na AWS.
Temos também o pilar de segurança, representado por um retângulo no cando superior direito do diagrama. Nesse caso, utilizamos o serviço IAM para a segurança das informações.
No canto inferior esquerdo do diagrama, encontramos o serviço EMR, utilizado para fazer o processamento das informações. Posteriormente, salvamos na camada gold do Bucket S3 os dados tratados e harmonizados. Por fim, usaremos o serviço AWS QuickSight para visualização de dados.
Conclusão
Neste curso, iremos focar somente no pilar de visualização. Conhecemos toda a arquitetura da formação de AWS Data Lake, mas trabalharemos apenas com a visualização de dados.
No próximo vídeo, entenderemos um pouco mais sobre o AWS QuickSight!
Preparando o ambiente - Executando código EMR para criação da camada gold
Agora que já compreendemos a arquitetura e os serviços que serão utilizados para a construção da visualização de dados com o AWS QuickSight, precisamos de uma fonte de dados para a criação do nosso dashboard.
Para isso, vamos utilizar a camada gold, que já contém as informações do site Data Boston tratadas e harmonizadas.
Executando o código EMR para criação da camada gold
Nosso desafio será reestabelecer a camada gold no Bucket S3 da AWS, pois excluímos essa camada no curso anterior.
Para resolver isso, primeiramente, vamos reestabelecer o cluster EMR e, em seguida, iremos executar o script Spark.
Nesse script, faremos a leitura da camada bronze, que contém os dados brutos do Data Boston, e no próprio script, realizaremos alguns tratamentos e harmonizações que serão salvos na camada gold.
A exclusão foi feita por ser uma boa prática excluir da AWS dados que não serão utilizados em curto ou médio prazo, de modo a evitar cobranças indevidas. Como não iríamos utilizar os dados da camada gold, fizemos a exclusão, e agora vamos reestabelecer as informações.
Clonando um cluster
Com o Console da AWS aberto, vamos buscar por "EMR" na barra de pesquisa da parte superior da tela. Na tela inicial da página "Amazon EMR", sempre aparecerão os clusters.
Nesse caso, vamos clonar o último cluster (EMR_AWSALURA), utilizado no curso anterior para executar o script Spark. Para cloná-lo, basta marcar a caixa de seleção à esquerda do nome do cluster e, em seguida, clicar no botão "Clone" no canto superior direito da tabela de clusters.
Ao clonar um cluster, a AWS sempre irá perguntar se queremos incluir os steps. Nesse caso, vamos incluir, pois foi justamente nesse step que colocamos o script Spark para ser executado.
Para isso, vamos marcar a opção "Include 1 step(s) with new cluster" e depois clicar no botão laranja "Edit configurations" no canto inferior direito da janela.
As configurações serão basicamente as que fizemos no curso anterior, pois se trata de um clone. Como essas configurações deram certo antes, não precisamos passar item a item neste vídeo, então podemos descer até o fim da tela e clicar no botão "Clone cluster" no canto inferior direito.
Analisando o step em execução
Ao fazer isso, o processo de criação do cluster será iniciado e o step será executado logo na sequência. Se clicarmos na aba "Steps" abaixo do sumário, encontraremos o step com o status pendente (Pending).
Clicando no ícone de mais (+) à esquerda da coluna "Step ID", encontraremos os argumentos:
spark-submit --deploy-mode cluster s3://alura-datalake-emr/main.py --database alura-datalakeaws --table_source bronzebronze --table_target gold
Essa é a parte principal quando executamos um script no cluster EMR, que é basicamente de onde ele obtém as informações, onde ele vai salvar, e qual script será executado. Nesse caso, ele executará o script main.py e irá salvar na camada gold na AWS.
Ao final da execução, não houve erro no status, ou seja, o script foi executado com sucesso. Basicamente, ele fez a leitura da camada bronze, conforme apontado em bronzebronze nos argumentos; depois executou o script main.py, fazendo a leitura da camada bronze; e após realizar todos os tratamentos, harmonizações e padronizações necessários, ele salvou a camada gold na AWS.
Verificando as informações na camada gold
Agora, para sabermos se o step foi executado com sucesso, podemos utilizar a AWS Athena para fazer uma consulta ad-hoc e verificar se as informações estão, de fato, na camada gold.
Lembrando que o AWS Athena, assim como o EMR, é um serviço pago, então caso não queira ter nenhuma cobrança, pedimos que você apenas acompanhe o curso e não execute na sua máquina.
Na barra de pesquisa, vamos buscar por "Athena" e clicar no primeiro link da lista. Nesse caso, já temos uma consulta salva que fizemos anteriormente:
SELECT * FROM "alura-datalakeaws"."gold" limit 10;
Basicamente, fazemos um SELECT * FROM do bucket alura-datalakeaws, e selecionamos a camada gold com limites de 10 linhas. Abaixo da consulta, conseguimos visualizar se ela foi executada com sucesso.
Na tabela "Results", ele trouxe todos os campos da camada gold. Com isso, percebemos que foi executado com sucesso.
Conclusão
Primeiramente, reestabelecemos o cluster EMR clonando um cluster que deu certo, bem como o seu step. Nesse step, passamos como argumentos tanto o script quanto o local que ele irá fazer a leitura, além do local onde serão salvas as informações. Feito isso, utilizamos a AWS Athena para fazer uma consulta na camada gold e conferir se os dados foram salvos corretamente.
Ao final, identificamos que o script foi executado com sucesso, e agora temos a camada gold para a criação do nosso dashboard no AWS QuickSight.
No próximo vídeo, aprenderemos um pouco mais sobre DataViz. Até logo!
Sobre o curso AWS Data Lake: análise de dados com Athena e Quicksight
O curso AWS Data Lake: análise de dados com Athena e Quicksight possui 125 minutos de vídeos, em um total de 42 atividades. Gostou? Conheça nossos outros cursos de Engenharia de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Preparando o ambiente
- Iniciando com AWS Quicksight
- Criando gráficos no AWS Quicksight
- Recursos adicionais no AWS Quicksight
- Novidades no AWS Quicksight