Data Science: explorando e analisando dados
Conhecendo os dados - Apresentação
Olá, pessoal! Meu nome é Guilherme Silveira, sou instrutor e um dos fundadores da Alura. Acompanharei você neste curso de Análise Exploratória de Dados em Data Science!
Audiodescrição: Guilherme é uma pessoa branca, de cabelos pretos bastante curtos, olhos castanho-escuros e barba preta por fazer. Está vestindo uma camiseta preta básica. À sua frente, um microfone com espuma protetora. Ao fundo, um ambiente iluminado por um degradê verde a roxo e ao fundo, à direita, uma estante com enfeites.
O que aprenderemos?
Neste curso, vamos abordar a análise exploratória de dados utilizando diversas ferramentas fundamentais que formam a base essencial do Python para o trabalho com dados.
Nesse sentido, utilizaremos a biblioteca Pandas praticamente o tempo inteiro, explorar um pouco de Seaborn para gráficos, junto do Matplotlib, e um pouco de NumPy também, usado "por trás dos panos" para fazer alguns trabalhos na nossa análise.
Analisar dados não é um curso teórico, mas também não é um curso 100% prático. Nos valeremos de muita prática, carregando um conjunto de dados real com notas e avaliações de filmes para explorar. E, à medida que executarmos toda essa prática, entrarão conceitos teóricos muito importantes na área de análise de dados.
Precisamos também entender como resumir as informações e os dados que temos de forma a apresentar valor para o nosso cliente. Vamos aprender a exibir essas informações relevantes por meio de uma visualização de dados — seja em forma de tabela, um número único, uma sequência de números, uma medida central, uma medida de dispersão ou um gráfico.
Para isso, abordaremos a questão prática para entender quais os parâmetros que permitem agrupar, transformar e mostrar os resultados das nossas análises (que serão acerca das notas dos filmes dadas pelos espectadores).
E, claro, também abordaremos questões teóricas que nós, como cientistas de dados, pensamos durante essa exploração. Afinal, o que queremos responder com nossas análises? O que nos leva a questionar algo sobre os nossos dados?
Vamos fazer tudo isso usando uma ferramenta chamada Google Colab, que funciona como um "caderno" em que escrevemos as nossas anotações, mas em forma de código Python. Essa ferramenta permite executar código sem precisar instalar nada no nosso computador, usando apenas a internet, na nuvem.
A partir disso, abrem-se outros caminhos para você seguir e se aprofundar: visualização de dados, testes estatísticos, predição e análise em machine learning (aprendizado de máquina), entre outros.
Podemos seguir vários caminhos quando sabemos trabalhar com Pandas e as outras ferramentas ao redor de Pandas nesse processo exploratório.
Então, boas-vindas a esse início de carreira como cientista de dados!
Até o próximo vídeo!
Conhecendo os dados - Conhecendo nossos dados e o Pandas
Para começar a analisar dados, precisamos de um caderno em que possamos fazer nossas anotações, cálculos, visualizar os dados e outras tarefas semelhantes.
Para isso, vamos utilizar a linguagem Python e um "caderno", que em inglês é chamado de Notebook. Existem ferramentas online que disponibilizam notebooks para escrevermos em Python. A ferramenta que vamos utilizar será o Google Colab.
Primeiros passos no Colab
Ao entrar nesse site, você pode criar um novo notebook clicando em "Arquivo > Novo Notebook" no canto superior esquerdo da tela. O nome padrão desse novo notebook limpo é "Sem título/Untitled", mas podemos alterá-lo para "Introdução à Ciência de Dados", dando um duplo clique no nome do topo da página.
Podemos fazer anotações nesse notebook, digitando em suas células, que são os campos de texto disponíveis no centro da tela com os dizeres "Comece a programar...". Notem que temos um botão de Play no início da célula, igual ao de reprodução de vídeo. Digitaremos nossos códigos Python dentro desses campos e os executaremos clicando nesse botão de Play.
Por exemplo: em Python, quando queremos criar uma variável, nós digitamos seu nome e a igualamos (com um sinal de igual =) ao seu valor que, se for uma palavra, deverá vir entre aspas duplas.
Então, se quisermos criar a variável nome e atribuir a ela o valor Guilherme, escrevemos o seguinte código na célula:
[1]
nome = "Guilherme"
Esse é um código Python válido, que diz que a variável nome tem o valor "Guilherme". Podemos executá-lo clicando no botão Play da célula. Com isso, esse código Python será executado na nuvem do Google, e não na nossa máquina.
Podemos criar uma segunda célula para executar um novo código, clicando em "+ Código" no canto superior esquerdo da tela.
Nessa nova célula, vamos imprimir o valor da variável nome. Então, escrevemos:
[2]
print(nome)
E clicamos no botão Play. Feito isso, o nome "Guilherme" é exibido no canto de retorno logo abaixo da célula. Essa segunda execução é mais rápida, porque a máquina já está criada na nuvem do Google.
Podemos criar mais coisas seguindo o mesmo procedimento, por exemplo, uma variável idade com o valor 40, e imprimir o valor dessa variável na mesma célula, na linha de baixo (dando um "Enter" para isso):
[3]
idade = 40
print(idade)
Ao executar, o número "40" é exibido no campo de retorno!
O último código que inserimos em uma célula é impresso para nós. Então, se criarmos uma nova célula e atribuir o valor 42 para a variável idade e, na linha de baixo, apenas digitarmos o nome da variável idade, o novo valor será impresso no campo de retorno ao executarmos a célula.
[4]
idade = 42
idade
Se quisermos executar todos os códigos que escrevemos nesse notebook novamente, nas quatro células, podemos clicar em "Ambiente de execução (ou Runtime, em inglês) > Reiniciar sessão e executar tudo", depois confirmar a ação na caixa de diálogo. Ele vai reiniciar, limpar todas as variáveis e executar tudo de novo.
Se quisermos alterar o valor da variável nome para "Gui", podemos fazer isso editando a nossa primeira célula e clicando no botão Play para executá-la.
[1]
nome = "Gui"
Também podemos usar o atalho "Shift + Enter" para executar apenas essa célula.
Mas, se alteramos o valor de uma célula, provavelmente queremos executar esta célula e as células abaixo, que dependem desse valor atualizado.
Por exemplo, a nossa segunda célula imprime o valor da variável nome, mas não a rodamos novamente depois de atualizar o valor dessa variável, então a impressão ainda é "Guilherme". Nesses casos, é sempre bom reiniciar e rodar tudo de novo.
Essa é a ideia do notebook: ser um lugar onde fazemos as anotações, analisamos os nossos dados e trabalhamos com eles. Vamos fazer isso!
Conjunto de dados do MovieLens
Vamos apagar todas as células, clicando no ícone da lixeira em cada uma delas, à direita, para começar a trabalhar com dados reais. Ficaremos com apenas uma célula limpa no nosso notebook.
Neste curso, vamos trabalhar com dados relacionados a filmes e notas que pessoas deram para esses filmes em suas avaliações. Existe um conjunto de dados famoso chamado MovieLens, que disponibiliza diferentes datasets de avaliações.
Um deles contém 100 mil avaliações de cerca de 9 mil filmes, e é esse arquivo que queremos baixar. Podemos encontrá-lo na seção "recommended for education and development", na versão "Small" (pequena): ml-latest-small.zip.
Quando descompactamos esse arquivo ZIP, encontramos 5 arquivos, incluindo o ratings.csv, que é o arquivo de notas. Vamos abrir esse arquivo num editor de texto apenas para explorá-lo.
Este é um arquivo CSV, o que significa que ele tem vírgulas separando os valores. A primeira linha é um cabeçalho, que indica que temos os seguintes campos no nosso dataset:
- ID do usuário (
userId), que deve ser a pessoa que deu a nota, - ID do filme (
movieId), que deve ser o número do filme, - nota (
rating), - data da atribuição dessa nota (
timestamp).
Isso está representado da seguinte maneira no nosso CSV:
ratings.csv
userId,movieId,rating,timestamp
Cada uma das linhas seguintes representa uma avaliação, cujos valores são referentes a cada um dos campos, respectivamente: usuário, filme, nota e data.
1,1,4.0,964982703
1,3,4.0,964981247
1,6,4.0,964982224
1,47,5.0,964983815
1,50,5.0,964982931
...
Ou seja: o usuário 1 deu para o filme 1 a nota 4.0 no momento 964982703. O mesmo para o filme 3, no momento 964981247. Já para o filme 47, deu nota 5.0 no momento 964983815.
Subindo um dataset para o Colab via CSV
Queremos abrir esse arquivo no nosso notebook. Para facilitar nosso trabalho, vamos usar bibliotecas que facilitam esse processo. Em Python, a biblioteca mais famosa e importante para uso no dia a dia se chama Pandas. Podemos conhecê-la melhor na documentação do Pandas.
No nosso notebook, vamos primeiramente importar o Pandas executando o seguinte código em uma célula:
import pandas as pd
Queremos ler o nosso arquivo de notas. Para facilitar nosso trabalho, já colocamos esse arquivo na internet, que podemos acessar no seguinte link:
https://raw.githubusercontent.com/alura-cursos/data-science-analise-exploratoria/main/Aula_0/ml-latest-small/ratings.csv
Vamos copiar esse link e retornar ao notebook. Na próxima célula, vamos pedir para o Pandas ler esse arquivo por meio do método read_csv(), passando a URL desse arquivo que acabamos de copiar como parâmetro, entre aspas duplas, resultando em pd.read_csv("https://raw.githubusercontent.com/alura-cursos/data-science-analise-exploratoria/main/Aula_0/ml-latest-small/ratings.csv").
Isso vai retornar para nós os dados com os quais vamos trabalhar, que são as notas. Então, podemos atribuir essa expressão à variável notas e, logo em seguida, imprimir esse resultado:
notas = pd.read_csv("https://raw.githubusercontent.com/alura-cursos/data-science-analise-exploratoria/main/Aula_0/ml-latest-small/ratings.csv")
notas
Ao executar essa célula, o Google Colab abre esse arquivo da internet, carrega-o, levanta-o na memória e cria uma tabela com os dados fornecidos, sob o nome notas, além de exibir essa tabela com os campos e dados que esperávamos:
Retorno (parcialmente transcrito)
| userId | movieId | rating | timestamp |
|---|---|---|---|
| 1 | 1 | 4.0 | 964982703 |
| 1 | 3 | 4.0 | 964981247 |
| 1 | 6 | 4.0 | 964982224 |
| 1 | 47 | 5.0 | 964983815 |
| 1 | 50 | 5.0 | 964982931 |
| ... | ... | ... | ... |
| 610 | 166534 | 4.0 | 1493848402 |
| 610 | 168248 | 5.0 | 1493850091 |
| 610 | 168250 | 5.0 | 1494273047 |
| 610 | 168252 | 5.0 | 1493846352 |
| 610 | 170875 | 3.0 | 1493846415 |
Agora, podemos fazer muitas coisas com essas notas!
Consultando o formato da tabela
Por exemplo, podemos querer saber qual é o formato dessa tabela, ou seja, quantas linhas e colunas ela tem. Para isso, chamamos o shape, um atributo de notas, executando o seguinte código:
notas.shape
Conforme o retorno, temos 100.836 linhas e 4 colunas (sendo a primeira delas apenas o indexador dos registros):
Retorno
(100836, 4)
Alterando nomes de colunas
Podemos também querer alterar o nome das colunas da nossa tabela, que estão em inglês no momento.
Para isso, primeiramente chamamos a propriedade notas.columns para trazer os nomes das colunas.
notas.columns
Retorno
Index(['userId', 'movieId', 'rating', 'timestamp'], dtype='object')
Para alterar esses nomes, então, vamos atribuir à expressão notas.columns uma lista com os novos nomes das colunas em português: "usuarioId", "filmeId", "nota", "momento". Como é uma lista, envolvemos esses valores entre colchetes.
Depois disso, se executarmos apenas notas novamente, observaremos que trocamos o atributo colunas para os nomes das colunas em português.
Se quisermos consultar apenas uma parcela da tabela para só ter uma ideia de como está nossa tabela, podemos pedir para retornar apenas as cinco primeiras linhas (ou seja, a "cabeça" da tabela) usando o método head(), o que resulta em notas.head().
Então, executaremos a seguinte célula:
notas.columns = ["usuarioId", "filmeId", "nota", "momento"]
notas.head()
E teremos a seguinte resposta:
Retorno (parcialmente transcrito)
| usuariold | filmeId | nota | momento |
|---|---|---|---|
| 0 | 1 | 4.0 | 964982703 |
| 1 | 1 | 4.0 | 964981247 |
| 2 | 1 | 4.0 | 964982224 |
| 3 | 1 | 5.0 | 964983815 |
| 4 | 1 | 5.0 | 964982931 |
Consultando apenas uma coluna
Podemos fazer muito mais com esse objeto notas. Por exemplo, podemos consultar apenas uma coluna desse dataset, como a coluna nota.
Para isso, escrevemos o nome do nosso objeto notas seguido de colchetes. Dentro dos colchetes, passamos entre aspas duplas o nome da coluna desejada: nota.
notas["nota"]
O retorno será apenas os valores da coluna nota:
Retorno (parcialmente transcrito)
4.0
4.0
5.0
5.0
...
4.0
5.0
5.0
3.0
Antes tínhamos uma tabela, agora temos uma única coluna!
No Pandas, essas são coisas distintas. Quando temos a tabela, chamamos de DataFrame, ou seja, um grande quadro de dados. Quando temos uma única coluna, chamamos de Series, ou seja, uma série de dados.
Para saber o que podemos fazer com dataframes e series, é possível consultar a documentação de pandas.DataFrame e pandas.Series.
Extraindo valores únicos
Agora, queremos saber quais são as notas possíveis que as pessoas atribuem aos filmes. Ou seja, queremos saber os valores únicos dessas notas.
Para saber como fazer isso, podemos consultar a documentação — algo que faremos muito ao trabalhar com qualquer linguagem de programação. Conforme os guias, podemos aplicar o método unique() para retornar valores únicos de um objeto Series
Então, aplicaremos esse método na coluna nota do nosso objeto notas para extrair o que desejamos:
notas["nota"].unique()
Ao executar esse código, recebemos os valores únicos dessa lista de notas:
Retorno
array([4. , 5. , 3. , 2. , 1. , 4.5, 3.5, 2.5, 0.5, 1.5])
Os valores desse array são as notas possíveis.
Você pode se perguntar se, por exemplo, a nota zero não existe, já que ela não apareceu nesse array. Mas não podemos afirmar isso com base nessa operação, já que extraímos apenas as notas que as pessoas deram, e não exatamente as possíveis. Ou seja, pode ser que a nota zero exista, mas ninguém da nossa amostra atribuiu nota zero para nenhum filme.
O mesmo vale para outros valores. Por isso, precisamos saber como a pesquisa foi realizada. São informações importantes para entender esses dados:
- Qual a escala de notas aplicada na pesquisa?
- Quais são as notas que efetivamente encontramos nos resultados?
Contando valores
Agora, queremos saber quão frequentemente aparecem cada uma dessas notas. Podemos contar esses valores usando o método value_counts().
Aplicando-o na coluna nota do nosso objeto notas, teremos:
notas["nota"].value_counts()
Retorno
4.0 26818
3.0 20047
5.0 13211
3.5 13136
4.5 8551
2.0 7551
2.5 5550
1.0 2811
1.5 1797
0.5 1370
Ou seja: a nota 4.0 foi atribuída 26.818 vezes, e é a nota mais frequente do nosso conjunto de dados. Já a nota 0.5 foi atribuída 1.370 vezes, sendo essa a nota menos frequente.
Com isso, podemos tirar uma conclusão digna de uma real análise de dados: as pessoas não têm a tendência de atribuir notas "quebradas" ao avaliar um filme.
Além disso, também parece haver uma tendência de atribuir mais notas altas que baixas. O instrutor interpreta isso como sendo uma questão de atitude: se gastamos nosso tempo avaliando um filme, é porque ele é muito bom ou muito ruim. Algo médio geralmente não toma a nossa atenção a esse ponto.
Calculando média
Podemos também querer saber a média das notas. Para isso, usamos o método mean():
notas["nota"].mean()
A média de todas as notas avaliadas nessa amostra é de aproximadamente 3,5 conforme o retorno desse código.
Conclusão
Repare no poder da biblioteca Pandas! Rapidamente carregamos um arquivo de dados, exploramos essa tabela, exploramos uma coluna e extraímos cálculos dela por meio de métodos precisos que o Pandas disponibiliza. Com isso, pudemos tirar conclusões iniciais acerca dos nossos dados.
Agora podemos trabalhar mais em cima disso, a partir da próxima aula. Até lá!
Conhecendo os dados - Primeiras visualizações
Recapitulando o que fizemos no nosso projeto até agora, nós analisamos a coluna nota do nosso dataframe e começamos a explorar e refletir sobre os números que encontramos. Esse processo é chamado de análise exploratória.
Esse não é um processo aleatório, mas sim um processo em que buscamos ferramentas que nos auxiliam a entender o que os nossos dados podem nos dizer.
Por exemplo, a função value_counts que usamos conta o número de vezes que um valor aparece dentro de um conjunto de dados, o que nos permitiu ter ideias sobre como as pessoas pensam e agem ao avaliar um filme.
Para chegar a essas ideias, consultamos nossos dados de várias formas: por meio de uma tabela original (notas), de uma série que exibia os valores de apenas uma coluna (nota), de um agrupamento de valores (contagem de frequência das notas) e até mesmo por meio de um número único (a média de notas). Todas essas são formas de visualizar nossos dados e extrair informações deles.
No entanto, ainda não conseguimos entender completamente a real distribuição desses valores. Percebemos que a nota mais comum é 4, por exemplo, mas será que a maioria das pessoas dá uma nota de 3,5 para cima, realmente, como havíamos hipotetizado? Essa afirmação faz sentido com base nos dados que temos? Para responder a essas perguntas, precisamos visualizar esses números em gráficos.
Para isso, o Pandas nos oferece visualizações não só de tabelas e números, mas também de gráficos. Vamos construir um exemplo.
Plotando um gráfico com Pandas
Vamos pegar nosso conjunto de dados, o dataframe notas, extrair apenas a coluna nota e pedir para ele desenhar um gráfico, ou plotar um gráfico, usando a função plot().
notas["nota"].plot()
No entanto, o gráfico resultante do código acima não faz sentido, pois não representa informação alguma:
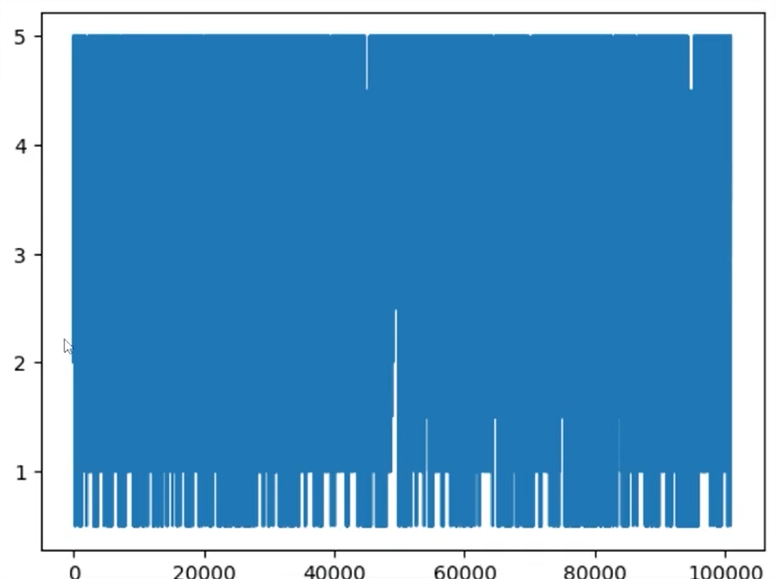
Com esse código, simplesmente plotamos uma nota após a outra, de zero a cem mil, com essas notas variando de zero a cinco. Não conseguimos concluir nada com essa visualização sem um certo agrupamento!
Não queremos visualizar uma linha para cada uma das cem mil notas dadas. Queremos visualizar, por exemplo: Quantas pessoas deram a nota 5? Quantas pessoas deram a nota 4? Quantas pessoas deram a nota 3? E 3,5? Algo parecido com a função que já conhecemos, a value_counts, que soma quantas vezes cada valor aparece no conjunto de dados!
Histograma: frequência de notas
Para plotar essa contagem dos valores, existe um tipo diferente de gráfico, muito importante, desenvolvido justamente para esse fim: o histograma.
Para defini-lo, adicionamos como parâmetro de plot() o tipo (kind) histograma (hist), resultando em:
notas["nota"].plot(kind='hist')
O histograma conta a frequência de cada valor do nosso conjunto de dados e a exibe para nós:
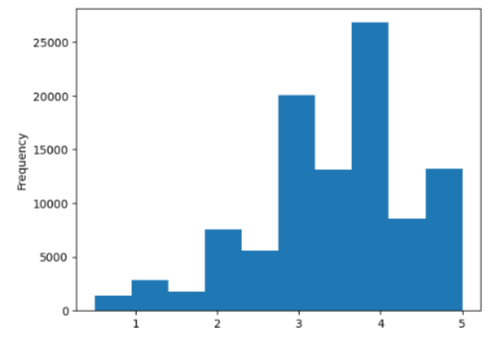
A nota 5 apareceu aproximadamente 15 mil vezes. A nota 4 apareceu pouco mais de 25 mil vezes. Conseguimos visualizá-las de outra forma que não a tabela!
E você pode pensar que esse gráfico é infinitamente melhor do que a tabela original. Isso é parcialmente verdade, porque o gráfico exibe valores aproximados, e não exatos. Já a tabela nos dizia a exata quantidade de vezes que cada nota aparecia.
Por exemplo, com a tabela, sabíamos precisamente que a nota 1,5 é 40% mais frequente que a nota 0,5. Ou seja, a visualização em tabela também tem um valor muito importante nas nossas análises.
No entanto, na tabela é mais difícil visualizar informações como o relacionamento global dos valores. Quando plotamos em um gráfico - nesse caso, o histograma -, percebemos mais rapidamente a expressão das notas, umas em relação às outras.
Por exemplo: a frequência da nota 3,5 é significativamente mais baixa que a nota 4, mas significativamente maior que a nota zero.
Esse é o valor dos gráficos ao explorarmos nossos dados e levantarmos questões e conclusões sobre eles, e que não tira o valor da tabela para esse mesmo fim!
A nossa ideia de que a maioria das pessoas dá uma nota acima de 3 parece verdade quando observamos o histograma. Mas, nós sabemos dizer por que parece verdade?
Na tabela, conseguimos conferir que mais de 80 mil pessoas deram notas acima de 3. Esse número é muito maior que as aproximadamente 20 mil notas abaixo de 3. Isso fica muito claro para nós ao ler a tabela.
Também temos essa sensação com o gráfico, mas por quê? Porque o que estamos observando não é a altura da barra, mas o espaço preenchido de azul abaixo dela! A área de pessoas que votaram 3 ou mais é muito maior que a área de pessoas que votaram de 2,5 para baixo. Nosso cérebro consegue fazer essa comparação razoavelmente rápido, porque a diferença é bem grande.
Cálculo de mediana
Podemos nos perguntar: onde está a divisão da metade das pessoas que deu nota mais alta e a metade que deu a nota mais baixa? Isso é, qual é a nota que divide nosso conjunto de notas ao meio?
Não conseguimos saber essa informação apenas observando o gráfico. Então, usamos uma fórmula para encontrar esse valor - a fórmula de mediana, que divide nossos dados pela metade.
No Pandas, essa fórmula é aplicada pelo método median(). Podemos aplicá-lo na nossa series nota da seguinte forma:
notas["nota"].median()
Ao executar, temos que a mediana do nosso conjunto de dados é a nota 3.5.
Se quisermos imprimir tanto a média (com o método mean(), que já conhecemos) quanto a mediana, podemos primeiramente salvar esses valores em variáveis:
mediana = notas["nota"].median()
media = notas["nota"].mean()
Na mesma célula, podemos imprimir o conteúdo dessas variáveis em strings dizendo "A mediana é X" e "A média é Y".
Para construir essas strings, passamos os nomes das variáveis entre chaves (como "Mediana é {mediana}"), junto de um f antes das aspas, para indicar que a string deve ser preenchida pelo conteúdo das variáveis:
print(f"Mediana é {mediana}")
print(f"Média é {media}")
Executando essa célula, recebemos como resposta:
Retorno
- Mediana é 3.5
- Média é 3.501556983616962
Os valores de média e mediana para esse conjunto de dados são bem parecidos, mas poderia ser bem diferente.
Descrevendo nosso conjunto de dados
Você pode se perguntar: "Assim como a média e a mediana, como é que eu divido três quartos? E um quarto? Qual é o maior valor do conjunto de dados?". De fato, existem diversas medidas que podemos fazer para descrever o nosso conjunto de dados!
Para obter essa descrição mais completa dos nossos dados, podemos aplicar o método describe() na nossa coluna nota:
notas["nota"].describe()
Ao executar esse código, receberemos a seguinte resposta:
Retorno
count 100836.000000
mean 3.501557
std 1.042529
min 0.500000
25% 3.000000
50% 3.500000
75% 4.000000
max 5.000000
Name: nota, dtype: float64
Ou seja, esse conjunto de dados possui 100.836 leituras, a média de 3,5015, o valor mínimo de 0,5, o valor máximo de 5, mediana de 3,5 e assim por diante. Temos várias medidas calculadas automaticamente para nós!
Boxplot
O histograma não é a única forma de visualizar a distribuição dos nossos valores. Como podemos visualizar, por exemplo, a mediana, os 50%? E também os 25% e os 75%? Onde está a maioria das nossas notas?
Para fazer isso, usamos outro tipo de plot, chamado boxplot, também criado por um dos grandes inventores dessa área de análise de dados.
Mas, para plotar um boxplot, usaremos uma biblioteca específica para gráficos no Python, e não mais o Pandas, chamada Seaborn.
Para usá-la, precisamos primeiro importá-la no nosso notebook do Colab, executando o seguinte código:
import seaborn as sns
Agora podemos aplicar o método sns.boxplot() na coluna nota do nosso dataframe notas para gerar esse boxplot.
sns.boxplot(notas["nota"])
Retorno
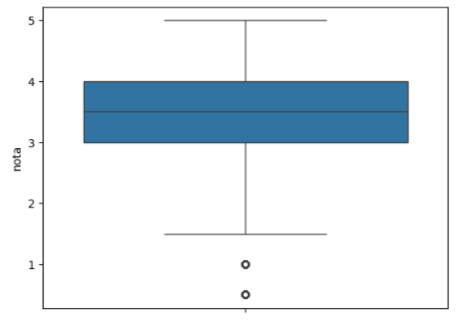
Esse boxplot mostra para nós que a mediana está no 3,5 por meio do traço horizontal ao centro da caixa azul.
O boxplot padrão do Seaborn representa, na borda superior da caixa, acima da linha da mediana, 25% dos valores que estão acima da mediana e 25% que estão abaixo dela. Ou seja, 50% das notas está entre 3 e 4.
Isso quer dizer que a maioria das pessoas dá notas entre 3 e 4. Para dar uma nota muito baixa, o filme precisa ser muito ruim; para dar nota muito alta, o filme precisa ser ótimo! Então, a maior parte das notas que damos fica entre 3 e 4, se as notas são de 0 a 5.
A linha vertical que atravessa o boxplot, também chamada de "bigodes", são os outros quase 25% dos dados, tanto acima da caixa quanto abaixo, completando 100%.
Nessa versão padrão do boxplot do Seaborn, os pontos soltos são os outliers, ou seja, os dados que fogem muito da distribuição da amostra. Ambas as notas outliers estão abaixo de 1,5.
Essa é uma forma de desenhar o boxplot, mas não a única! E ela já diz bastante para nós, principalmente a parte do miolo que concentra a maioria das notas, que está entre 3 e 4.
É possível visualizar essa mesma informação no histograma de alguma maneira, mas não exata. E isso só é possível por conta da distribuição específica dos dados que estamos analisando.
Em outra amostra, com outros dados, talvez tivéssemos barras muito diferentes e desconcentradas no histograma, e não conseguiríamos visualizar a real distribuição dos dados - apenas plotando um boxplot.
Gráficos diferentes têm papéis diferentes e trazem informações diferentes para nós, baseadas nos mesmos dados. É muito importante lembrar que tabelas, números soltos ou gráficos são, todas, formas de visualizar e tentar extrair informações de uma amostra dados.
Até a próxima!
Sobre o curso Data Science: explorando e analisando dados
O curso Data Science: explorando e analisando dados possui 172 minutos de vídeos, em um total de 58 atividades. Gostou? Conheça nossos outros cursos de Data Science em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Conhecendo os dados
- Analisando os dados
- Entendendo os tipos de variáveis
- Visualizando os dados
- Ajustando os visuais
- Estatística dos dados