Data Science: testes estatísticos com Python
Conhecendo os dados e explorando - Introdução
O tema desse curso de introdução à Data Science são os testes estatísticos! Para efetuarmos esses testes no Python, é importante que você tenha um conhecimento prévio de estatística. Portanto, os cursos Estatística I: Entenda seus dados com R e Estatística II: Aprofundando em hipóteses e correlações são pré-requisitos para o total aproveitamento deste módulo.
Ao longo dos nossos estudos, utilizaremos dados do MovieLens, que são avaliações de filmes (com notas de 0.5 a 5), e também do The Movie Database (TMDB).
Após carregarmos esses dados, analisaremos diversas distribuições entre eles, e também limparemos algumas informações "estranhas" contidas nesses conjuntos.
Após isso, trabalharemos com as notas e as médias - sejam de todos os filmes ou de filmes específicos. Por exemplo, abordaremos a confiança que é expressada por uma média e o possível intervalo que melhor representaria aquela amostra.
Além disso, o que acontece quando um filme tem 5 avaliações e outro que tem 1000 avaliações? Será que a média desses filmes é realmente comparável?
Analisaremos esses dados tanto visualmente (gráficos e plotagens), quanto por meio de testes estatísticos (como "teste Z", "teste T", "teste de Wilcoxon" e "ranksums"), gerando intervalos de confiança (quando apropriado) e utilizando bibliotecas como o StatsModels e o SciPy, além do Pandas, que já utilizamos nos cursos anteriores de Data Science.
Com tudo isso, poderemos, no futuro, comparar de maneira estatisticamente válida duas diferentes amostras de dados.
Vamos começar?
Conhecendo os dados e explorando - Limpando os dados e visualizando uma distribuição
No projeto deste curso, utilizaremos dois conjuntos de dados diferentes:
- o MovieLens, do instituto de pesquisa Grouplens, que agrupa avaliações de filmes
- o TMDB 5000, disponível no site da comunidade Kaggle, que contém informações como faturamento, orçamento, ano de lançamento, país de origem, entre outras
No Google Colaboatory, criaremos um novo notebook Python 3. Lembre-se que você também pode utilizar o Jupyter localmente na sua máquina, ou em outra plataforma que lhe permita escrever códigos Python, como o próprio Kaggle.
Nomearemos esse notebook como "Data Science - Introdução a Testes". Em seguida, faremos o upload do tmdb5000.csv, o primeiro dataset sobre o qual iremos trabalhar. Para isso, clicaremos na seta à esquerda da tela, e então em "Files > Upload". Caso a plataforma apresente uma mensagem informando que ele está aguardando uma conexão com o runtime, basta esperar até que a máquina virtual seja devidamente inicializada.
Quando carregamos um arquivo para a nuvem do Google Colab, ele é deletado toda vez que o runtime é desconectado, sendo necessário fazer o upload novamente. Carregado o arquivo, vamos importar a biblioteca Pandas, fazer a leitura do tmdb.csv com pd.read_csv() e atribuí-lo a uma variável tmdb.
import pandas as pd
tmdb = pd.read_csv('tmdb_5000_movies.csv')Com tmdb.head(), exibiremos os cinco primeiros registros desse dataset:
| budget | genres | homepage | id | keywords | original_language | original_title | overview | popularity | production_companies | production_countries | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 237000000 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | http://www.avatarmovie.com/ | 19995 | [{"id": 1463, "name": "culture clash"}, {"id":... | en | Avatar | In the 22nd century, a paraplegic Marine is di... | 150.437577 | [{"name": "Ingenious Film Partners", "id": 289... | [{"iso_3166_1": "US", "name": "United States o... | 2009-12-10 | 2787965087 | 162.0 | [{"iso_639_1": "en", "name": "English"}, {"iso... | Released | Enter the World of Pandora. | Avatar | 7.2 | 11800 |
| 1 | 300000000 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | http://disney.go.com/disneypictures/pirates/ | 285 | [{"id": 270, "name": "ocean"}, {"id": 726, "na... | en | Pirates of the Caribbean: At World's End | Captain Barbossa, long believed to be dead, ha... | 139.082615 | [{"name": "Walt Disney Pictures", "id": 2}, {"... | [{"iso_3166_1": "US", "name": "United States o... | 2007-05-19 | 961000000 | 169.0 | [{"iso_639_1": "en", "name": "English"}] | Released | At the end of the world, the adventure begins. | Pirates of the Caribbean: At World's End | 6.9 | 4500 |
| 2 | 245000000 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | http://www.sonypictures.com/movies/spectre/ | 206647 | [{"id": 470, "name": "spy"}, {"id": 818, "name... | en | Spectre | A cryptic message from Bond’s past sends him o... | 107.376788 | [{"name": "Columbia Pictures", "id": 5}, {"nam... | [{"iso_3166_1": "GB", "name": "United Kingdom"... | 2015-10-26 | 880674609 | 148.0 | [{"iso_639_1": "fr", "name": "Fran\u00e7ais"},... | Released | A Plan No One Escapes | Spectre | 6.3 | 4466 |
| 3 | 250000000 | [{"id": 28, "name": "Action"}, {"id": 80, "nam... | http://www.thedarkknightrises.com/ | 49026 | [{"id": 849, "name": "dc comics"}, {"id": 853,... | en | The Dark Knight Rises | Following the death of District Attorney Harve... | 112.312950 | [{"name": "Legendary Pictures", "id": 923}, {"... | [{"iso_3166_1": "US", "name": "United States o... | 2012-07-16 | 1084939099 | 165.0 | [{"iso_639_1": "en", "name": "English"}] | Released | The Legend Ends | The Dark Knight Rises | 7.6 | 9106 |
| 4 | 260000000 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | http://movies.disney.com/john-carter | 49529 | [{"id": 818, "name": "based on novel"}, {"id":... | en | John Carter | John Carter is a war-weary, former military ca... | 43.926995 | [{"name": "Walt Disney Pictures", "id": 2}] | [{"iso_3166_1": "US", "name": "United States o... | 2012-03-07 | 284139100 | 132.0 | [{"iso_639_1": "en", "name": "English"}] | Released | Lost in our world, found in another. | John Carter | 6.1 | 2124 |
Na primeira coluna, "budget", temos o orçamento - ou seja, quanto foi gasto na produção do filme. Em seguida, temos:
- genres (gêneros),
- homepage, a página do filme na internet,
- id, um número identificador,
- keywords, as palavras-chave associadas ao filme,
- original_language (língua original),
- original_title (título original),
- overview, uma descrição básica do filme,
- popularity, uma espécie de "nota" de popularidade calculada pelo próprio TMDB,
- production_companies, as empresas envolvidas na produção,
- production_contries, os países em que o filme foi produzido,
- release_date (data de lançamento),
- renevue (faturamento),
- runtime, o tempo de duração (em minutos),
- spoken_languages, as línguas faladas no filme,
- status, se o filme foi lançado ou não,
- tagline, uma rápida chamada do filme (como encontramos em propagandas),
- title (título),
- vote_average, uma nota média do filme
- e vote_count, que mostra o número de notas atribuídas ao filme.
Perceba que, no próprio site do TMDB, o usuário pode dar notas aos filmes, e dessas notas é tirada uma média. Mas que valores será que compreendem essa média?
Existem diversas maneiras de analisarmos um dataframe do Pandas. Uma delas é a função describe(), que exibirá informações das colunas numéricas do conjunto:
tmdb.describe()| budget | id | popularity | revenue | runtime | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|
| count | 4.803000e+03 | 4803.000000 | 4803.000000 | 4.803000e+03 | 4801.000000 | 4803.000000 | 4803.000000 |
| mean | 2.904504e+07 | 57165.484281 | 21.492301 | 8.226064e+07 | 106.875859 | 6.092172 | 690.217989 |
| std | 4.072239e+07 | 88694.614033 | 31.816650 | 1.628571e+08 | 22.611935 | 1.194612 | 1234.585891 |
| min | 0.000000e+00 | 5.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 7.900000e+05 | 9014.500000 | 4.668070 | 0.000000e+00 | 94.000000 | 5.600000 | 54.000000 |
| 50% | 1.500000e+07 | 14629.000000 | 12.921594 | 1.917000e+07 | 103.000000 | 6.200000 | 235.000000 |
| 75% | 4.000000e+07 | 58610.500000 | 28.313505 | 9.291719e+07 | 118.000000 | 6.800000 | 737.000000 |
| max | 3.800000e+08 | 459488.000000 | 875.581305 | 2.787965e+09 | 338.000000 | 10.000000 | 13752.000000 |
Na tabela resultante, é possível verificar, por exemplo, que o valor mínimo para "vote_average é 0, e o máximo é 10. Essa é uma maneira tabular de visualizarmos essas informações, e ela nos permite, inclusive, verificar a mediana (que figura na linha 50%, e que representa o valor que divide o conjunto de dados ao meio - neste caso, 6.2) e os quartis (25% e 75%).
Uma maneira gráfica de visualizarmos essas informações é o histograma. Já aprendemos a criar histogramas com o seaborn, utilizando a função distplot():
sns.distplot(tmdb.vote_average)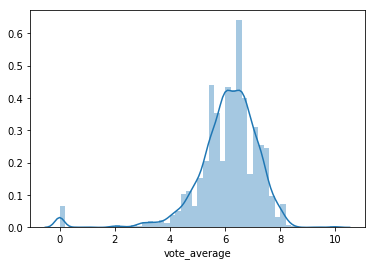
Vamos melhorar um pouco essa visualização. O distplot() nos devolve a informação dos eixos (axis, em inglês), e podemos trabalhar com eles. Atribuiremos o retorno da função a uma variável ax. A partir dela, usaremos set() para editar os eixos x e y, adicionando as legendas (labels) "Nota média" e "Densidade", respectivamente.
A densidade, que figura no eixo y, é uma normalização dos registros de um conjunto de dados para que a soma total deles seja 1.
Em seguida, usaremos set_title() para adicionarmos um título a esse histograma.
ax = sns.distplot(tmdb.vote_average)
ax.set(xlabel='Nota média', ylabel='Densidade')
ax.set_title('Média de votos em filmes no TMBD 5000')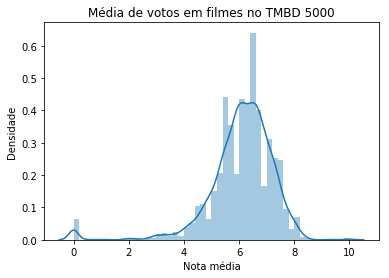
Nesse gráfico, não é possível obtermos a informação de quantas notas 0 aparecem, por exemplo, e gostaríamos de obtê-la. Para isso, precisaremos passar dois parâmetros para a função distplot(): norm_hist = False, para desativarmos a normalização; e kde = False.
O parâmetro kde = False deve ser adicionado pois, por padrão, ele é atribuído como verdadeiro. Quando isso acontece, a função distplot() também atribui verdadeiro ao parâmetro norm_hist, mesmo que o tenhamos desativado.
Já que alteramos a informação no eixo y, mudaremos também a legenda que é exibida nele:
ax = sns.distplot(tmdb.vote_average, norm_hist= False, kde= False)
ax.set(xlabel='Nota média', ylabel='Frequência')
ax.set_title('Média de votos em filmes no TMBD 5000')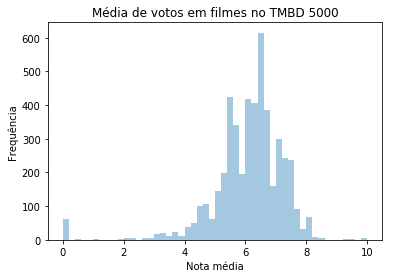
No novo histograma, podemos observar, por exemplo, que existem aproximadamente 70 notas 0 no nosso conjunto.
Outra maneira de visualizarmos a distribuição é o boxplot.
sns.boxplot(tmdb.vote_average)Por padrão, o boxplot é plotado da esquerda para a direita (no eixo x). Quando estamos comparando vários boxplots, costuma-se plotar os dados de baixo para cima (no eixo y), para facilitar a visualização.
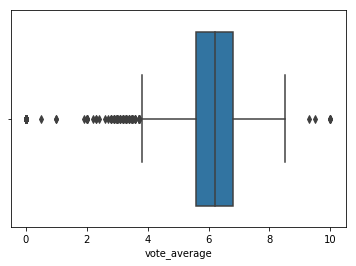
Nele, podemos visualizar a mediana (próxima de 6) e os quartis que dividem o nosso conjunto.
Essas são maneiras diferentes de visualizarmos as informações do nosso conjunto, cada uma com suas propriedades. Por exemplo, no histograma, apesar de conseguirmos identificar as frequências com mais exatidão, é impossível visualizar a mediana ou os quartis, que são algumas das principais informações no boxplot. Dessa forma, a utilização de cada visualização vai depender dos nossos objetivos.
Antes de prosseguirmos, vamos refinar o nosso boxplot adicinando uma legenda ao eixo x e um título:
ax = sns.boxplot(tmdb.vote_average)
ax.set(xlabel='Nota média do filme')
ax.set_title('Distribuição de nota média dos filmes do TMDB 5000')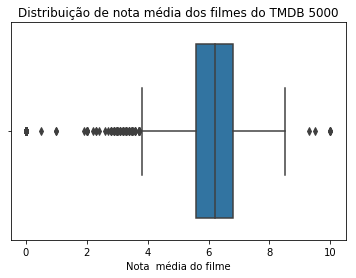
Uma informação bastante importante pode ser extraída dessas visualizações: uma quantidade razoável de filmes possuem média 0 e 10. Isso parece estranho, pois qualquer nota diferente de 0 ou 10, respectivamente, seria suficiente para mudar essas médias. Vamos verificar o que está acontecendo com nossos dados.
Com tmdb.query('vote_average == 0'), listaremos todos os filmes cuja média é igual a 0. O resultado é uma tabela semelhante a esta:
| budget | genres | homepage | id | keywords | original_language | original_title | overview | popularity | production_companies | production_countries | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1464 | 0 | [{"id": 18, "name": "Drama"}, {"id": 80, "name... | NaN | 310706 | [] | en | Black Water Transit | In this action thriller set in post-Katrina Ne... | 0.126738 | [{"name": "Capitol Films", "id": 826}] | [{"iso_3166_1": "US", "name": "United States o... | 2009-05-13 | 0 | 100.0 | [{"iso_639_1": "en", "name": "English"}] | Released | NaN | Black Water Transit | 0.0 | 0 |
| 3669 | 0 | [{"id": 35, "name": "Comedy"}, {"id": 18, "nam... | http://www.romeothemovie.com/ | 113406 | [] | en | Should've Been Romeo | A self-centered, middle-aged pitchman for a po... | 0.407030 | [{"name": "Phillybrook Films", "id": 65147}] | [{"iso_3166_1": "US", "name": "United States o... | 2012-04-28 | 0 | 0.0 | [{"iso_639_1": "en", "name": "English"}] | Released | Even Shakespeare didn't see this one coming. | Should've Been Romeo | 0.0 | 0 |
| 3670 | 0 | [{"id": 10751, "name": "Family"}] | NaN | 447027 | [] | en | Running Forever | After being estranged since her mother's death... | 0.028756 | [{"name": "New Kingdom Pictures", "id": 41671}] | [{"iso_3166_1": "US", "name": "United States o... | 2015-10-27 | 0 | 88.0 | [] | Released | NaN | Running Forever | 0.0 | 0 |
| 3852 | 0 | [{"id": 18, "name": "Drama"}] | NaN | 395766 | [{"id": 11162, "name": "miniseries"}] | en | The Secret | The Secret is the story of a real-life double ... | 0.042346 | [] | [] | 2016-04-29 | 0 | 200.0 | [] | Released | NaN | The Secret | 0.0 | 0 |
O importante, aqui, é a coluna "vote_count. Perceba que a maior parte dos filmes cuja média é 0 também possuem um número de votos igual a 0. Porém, se não existiram votos, o filme não deveria constar na plotagem dos nossos dados, já que não existe informação sobre a nota dele - diferente do que nos é apresentado agora, com a nota 0 identificando-os como filmes ruins.
Portanto, teremos que remover esses registros do nosso dataframe. Mas repare que ainda há um registro curioso na tabela:
| budget | genres | homepage | id | keywords | original_language | original_title | overview | popularity | production_companies | production_countries | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4400 | 0 | [] | NaN | 219716 | [] | en | Sparkler | Melba is a Californian trailer-park girl who i... | 0.547654 | [] | [] | 1999-03-19 | 0 | 96.0 | [] | Released | NaN | Sparkler | 0.0 | 1 |
Nesse caso, o filme recebeu uma única nota 0, o que também é um número muito pequeno para tirarmos conclusões significativas. Portanto, na nossa seleção dentro desse conjunto de dados, manteremos somente os registros com 10 ou mais notas. Atribuiremos esse novo conjunto a uma variável diferente e usaremos describe() para exibirmos algumas de suas características:
tmdb_com_mais_de_10_votos = tmdb.query('vote_count >= 10')
tmdb_com_mais_de_10_votos.describe()| budget | id | popularity | revenue | runtime | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|
| count | 4.392000e+03 | 4392.000000 | 4392.000000 | 4.392000e+03 | 4391.000000 | 4392.000000 | 4392.000000 |
| mean | 3.164545e+07 | 49204.119991 | 23.448815 | 8.990969e+07 | 108.430881 | 6.226935 | 754.441712 |
| std | 4.162736e+07 | 80136.249777 | 32.592158 | 1.682870e+08 | 21.014719 | 0.893215 | 1272.263761 |
| min | 0.000000e+00 | 5.000000 | 0.011697 | 0.000000e+00 | 0.000000 | 1.900000 | 10.000000 |
| 25% | 2.895962e+06 | 8403.500000 | 6.512166 | 1.365700e+04 | 95.000000 | 5.700000 | 83.750000 |
| 50% | 1.700000e+07 | 13084.500000 | 14.827784 | 2.685837e+07 | 105.000000 | 6.300000 | 288.500000 |
| 7 | |||||||
| 5% | 4.200000e+07 | 46831.250000 | 30.258282 | 1.022818e+08 | 118.500000 | 6.800000 | 831.000000 |
| max | 3.800000e+08 | 417859.000000 | 875.581305 | 2.787965e+09 | 338.000000 | 8.500000 | 13752.000000 |
Dessa vez, o vote_average mínimo passou a ser 1.9 - o que significa que todos os filmes tiveram pelo menos uma nota diferente de 0. Repare que o vote_average máximo também foi alterando, passando a ser 8.5. Isso porque os filmes no nosso conjunto que apresentavam uma média 10 possuíam apenas 1 ou 2 votos!
Agora que limpamos nossos dados, vamos refazer as nossas plotagens, começando pelo histograma:
ax = sns.distplot(tmdb_com_mais_de_10_votos.vote_average, norm_hist= False, kde= False)
ax.set(xlabel='Nota média', ylabel='Frequência')
ax.set_title('Média de votos em filmes no TMBD 5000')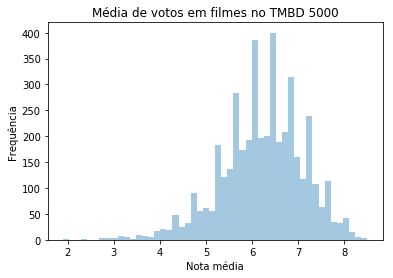
Com isso, nosso histograma não mais apresenta registros nas notas 0 e 10. Já se refizermos o histograma plotando a densidade desses dados:
ax = sns.distplot(tmdb_com_mais_de_10_votos.vote_average)
ax.set(xlabel='Nota média', ylabel='Densidade')
ax.set_title('Média de votos em filmes no TMBD 5000')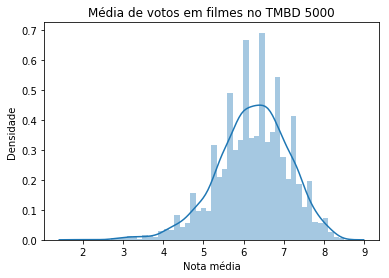
Teremos uma curva semelhante a uma distribuição normal, mas que não é exatamente simétrica, já que possui uma densidade um pouco maior na parte esquerda do gráfico. Mas repare, também, que analisando essa divisão a partir de uma média visual, existe um espaço mais amplo de valores possíveis para a esquerda (de 6 até 0) do que para a direita (de 6 até 10).
O boxplot desse novo conjunto também é mais parecido com uma distribuição normal, apesar de ser mais denso nos quartis abaixo da mediana:
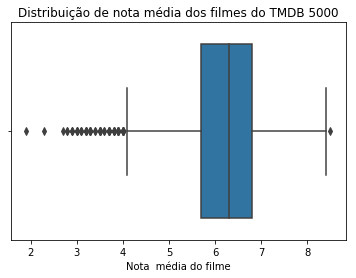
Até o momento, nós analisamos um conjunto de dados e o limpamos de acordo com um problema que foi identificado. A partir de agora, analisaremos a distribuição de outras informações e aplicaremos diversos testes sobre elas.
Conhecendo os dados e explorando - Visualizando e limpando o movielens
Nós analisamos visualmente a média dos filmes do TMDB 5000, e percebemos que seu comportamento é parecido com uma distribuição normal, com exceção do lado esquerdo do gráfico.
Agora, vamos comparar esse conjunto com os dados do MovieLens, procurando saber se esse comportamento se repete. Primeiramente, carregaremos o arquivo ratings.csv e o importaremos, atribuindo essa leitura a uma variável notas. Feito isso, exibiremos os 5 primeiros registros desse dataset:
notas = pd.read_csv("ratings.csv")
notas.head()Temos aqui um formato diferente, com a identificação do usuário (userId), a identificação do filme (movieId) e a nota que foi dada para cada filme (rating).
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
Ou seja, não temos as médias de cada filme, então teremos que calculá-la. Para isso, agruparemos as notas por filme (notas.groupby("movieId")) e tiraremos a média apenas do campo rating (o único em que essa medida faz sentido), atribuindo o retorno a uma variável nota_media_por_filme. Então, exibiremos os 5 primeiros registros:
nota_media_por_filme = notas.groupby("movieId").mean()["rating"]
nota_media_por_filme.head()| movieId | |
|---|---|
| 1 | 3.920930 |
| 2 | 3.431818 |
| 3 | 3.259615 |
| 4 | 2.357143 |
| 5 | 3.071429 |
Em seguida, geraremos a primeira visualização dessas médias. Para isso, repetiremos o processo que fizemos para as médias do TMDB 5000, acrescentando .values à variável nota_media_por_filme de modo a pegar somente os valores, e não os ids de cada filme:
ax = sns.distplot(nota_media_por_filme.values)
ax.set(xlabel='Nota média', ylabel='Densidade')
ax.set_title('Média de votos em filmes no MovieLens')Dessa vez, temos um gráfico com notas de 0 a 5. Novamente, ainda que não tenhamos filmes com média 0, temos alguns cuja média é 5. Portanto, é de se esperar que existam alguns filmes com poucos votos.
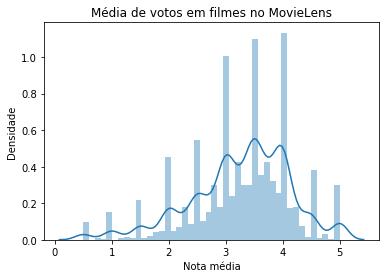
Com notas.groupby("movieId").count(), contaremos quantos votos cada um dos filmes possui nesse conjunto, atribuindo o resultado a uma variável quantidade_de_votos_por_filme. Com ela, faremos uma query() que selecionará apenas os filmes com 10 ou mais votos.
quantidade_de_votos_por_filme = notas.groupby("movieId").count()
quantidade_de_votos_por_filme.query("rating >= 10")Quero, então, saber quais são os filmes que compõem esse conjunto. Para isso, utilizaremos o index (que se refere a movieId), já que esse campo é um índice e não uma coluna determinada. Criaremos, com essa query(), uma variável filmes_com_pelo_menos_10_votos.
quantidade_de_votos_por_filme = notas.groupby("movieId").count()
filmes_com_pelo_menos_10_votos = quantidade_de_votos_por_filme.query("rating >= 10").indexO formato devolvido por essa função é Int64Index. Podemos extrair somente os valores, criando um array, com filmes_com_pelo_menos_10_votos.values.
A variável nota_media_por_filme, que criamos anteriormente, é uma série que contém as médias e os ids dos filmes no conjunto. Agora, queremos somente os valores cujo índice está contido em filmes_com_pelo_menos_10_votos.
Para isso, usaremos o indexador .loc[]. Como parâmetro, ele pode receber um índice ou até mesmo um array, que é exatamente o que temos em filmes_com_pelo_menos_10_votos! Atribuiremos a series retornada pelo .loc[] a uma nova variável, de nome bastante extenso mas igualmente explicativo:
nota_media_dos_filmes_com_pelo_menos_10_votos = nota_media_por_filme.loc[filmes_com_pelo_menos_10_votos.values]
nota_media_dos_filmes_com_pelo_menos_10_votos.head()| movieId | |
|---|---|
| 1 | 3.920930 |
| 2 | 3.431818 |
| 3 | 3.259615 |
| 5 | 3.071429 |
| 6 | 3.946078 |
Agora, podemos gerar novamente um histograma, agora com dados mais significantes:
ax = sns.distplot(nota_media_dos_filmes_com_pelo_menos_10_votos)
ax.set(xlabel='Nota média', ylabel='Densidade')
ax.set_title('Média de votos em filmes no MovieLens')Com isso, teremos uma visualização que se assemelha mais à do TMDB 5000, sem os extremos da esquerda (0.5) e da direita (5).
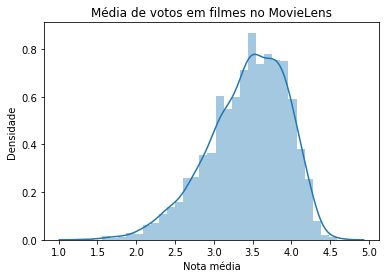
Se traçarmos uma "mediana imaginária" por volta do 3,5, teremos uma curva um pouco mais abaulada à esquerda, e um pouco mais inclinada à direita - da mesma forma que no histograma do TMBD 5000. Claro, podem existir outros fatores que tornam a distribuição daquele conjunto mais "espalhada".
Vamos gerar também o boxplot dos dados do MovieLens:
ax = sns.boxplot(x=nota_media_dos_filmes_com_pelo_menos_10_votos.values)
ax.set(xlabel='Nota média do filme')
ax.set_title('Distribuição de nota média dos filmes do MovieLens')Repare que essa nova visualização também se assemelha àquela do TMDB, com os quartis à esquerda (25% e 50%) mais densos que os da direita.
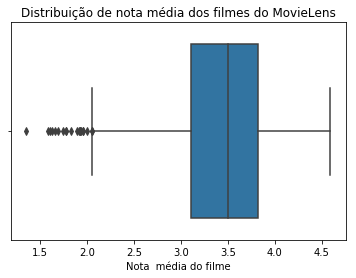
Uma análise "visual" dessas distribuições estão nos indicando que as pessoas se comportam de maneira similar. A seguir, continuaremos explorando esses dados.
Sobre o curso Data Science: testes estatísticos com Python
O curso Data Science: testes estatísticos com Python possui 140 minutos de vídeos, em um total de 44 atividades. Gostou? Conheça nossos outros cursos de Estatística em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Visualização da distribuição dos dados coletados
- Quantis
- Teste com uma amostra
- Dificuldades práticas
- Teste de uma variável com duas amostrar
- Normalidade e não paramétricos