Data Visualization: gráficos de composição e relacionamento
Proporção dos dados - Apresentação
Olá! Topa aprender como trabalhar com gráficos de composição e relacionamento de dados? É isso que vamos aprender neste curso! Meu nome é Afonso Rios e sou instrutor de Dados aqui na Alura.
Audiodescrição: Afonso se autodeclara como um homem de pele morena, olhos e cabelos curtos castanho-escuros e barba volumosa. Está de camiseta cinza com a logo da Alura no peito. Ao fundo, uma parede branca com uma iluminação azul e decorações em azul e cinza.
O que vamos aprender?
Neste curso, vamos aprender a manipular duas bases de dados diferentes, representando esses dados com composições e relacionamentos.
Para isso, aprenderemos a criar gráficos de composição voltados à proporção dos dados, como gráficos de pizza e de rosca.
Vamos trabalhar com gráficos de acumulação e subtração de totais, como os gráficos de cascata, que são muito utilizados no mercado financeiro.
Também vamos aprender a comparar gráficos com dados agrupados (gráficos de barras) e dados empilhados (em barras de porcentagem), entendendo qual seria melhor para apresentar ao nosso público. Vale ressaltar que existe uma diferença entre essas apresentações, e essa diferença será esclarecida durante o curso.
Além disso, aprenderemos como investigar variações dos dados, sejam elas em longos ou curtos períodos. Portanto, vamos trabalhar com gráficos de áreas e gráficos de inclinação, que são muito importantes para investigar essas variações.
Por fim, aprenderemos a relacionar os dados, sejam eles de mesma natureza ou de naturezas diferentes.
Todos esses tipos de gráficos, junto do uso de recursos como cores diferentes, anotações e outros elementos visuais, serão conhecidos aqui para que nossos gráficos sejam ainda mais completos e repletos de informações para o nosso público.
Pré-requisitos
É muito importante que, para fazer este curso, você tenha algum conhecimento prévio, ainda que básico, sobre:
- Linguagem Python
- Bibliotecas de manipulação de dados, como o Pandas e o NumPy
- Bibliotecas de visualização de dados, como o Matplotlib, o Plotly e o Seaborn.
Com tudo isso alinhado e pronto para aprendermos a desenvolver cada um desses gráficos, vamos começar a construir nossas visualizações e analisar essas bases de dados?
Proporção dos dados - Apresentando a base de dados
Antes de iniciar nosso curso, vamos escolher a paleta de cores que utilizaremos em nosso projeto. Isso é importante pois uma paleta de cores define não apenas a identidade visual das nossas apresentações de dados, mas também a acessibilidade de nosso projeto.
Paleta de cores
Nossa paleta é constituída de tons de azul, variando do mais escuro ao mais claro, numerados de 1 a 6; tons de cinza, do mais escuro ao branco; e por fim três tons de vermelho e três tons de verde:

Vamos inserir esses códigos de cores em nosso projeto e eles serão aplicados a todos os gráficos que criarmos ao longo do curso.
Para isso, executamos o código de definição da paleta de cores para podermos iniciar nosso projeto:
# Definindo a paleta de cores
AZUL1, AZUL2, AZUL3, AZUL4, AZUL5, AZUL6 = '#174A7E', '#4A81BF', "#6495ED", '#2596BE', '#94AFC5', '#CDDBF3'
CINZA1, CINZA2, CINZA3, CINZA4, CINZA5, BRANCO = '#231F20', '#414040', '#555655', '#A6A6A5', '#BFBEBE', '#FFFFFF'
VERMELHO1, VERMELHO2, LARANJA1 = '#C3514E', '#E6BAB7', '#F79747'
VERDE1, VERDE2, VERDE3 = '#0C8040', '#9ABB59', '#9ECCB3'
Após a execução, vamos conhecer nossa primeira base de dados, que será discutida ao longo das três primeiras aulas.
Importando a base de dados e a biblioteca Pandas
Essa base de dados será responsável por trazer os dados do PIB dos estados brasileiros entre os anos 2002 e 2020. Os valores do PIB incluirão o próprio PIB, os valores de impostos e os valores adicionados de bens e serviços, sejam eles agropecuários, industriais, de serviços e outras áreas de nossa economia.
Inicialmente, vamos importar nossa base de dados para estudar a composição desses valores, criando todos os gráficos de composição e respondendo aos questionamentos daqui para a frente.
Primeiramente, importaremos nossa biblioteca de manipulação de dados, a Pandas, executando o seguinte código no nosso Colab:
import pandas as pd
Biblioteca importada!
Agora, vamos importar a base de dados que usaremos em nosso projeto, disponível no seguinte link do GitHub:
Criaremos um dataframe chamado df_pib, sendo ele igual ao pd.read_csv() do link que contém os dados do PIB de 2002 até 2020:
# Importando a base de dados com o PIB dos estados brasileiros de 2002 a 2020
df_pib = pd.read_csv("https://raw.githubusercontent.com/afonsosr2/dataviz-graficos-composicao-relacionamento/master/dados/pib_br_2002_2020_estados.csv")
Vamos executar o df_pib para visualizar nosso conjunto de dados:
df_pib
Ao abrir o conjunto de dados, notaremos algumas colunas importantes para nossa análise. Haverá uma coluna para o ano, uma para a sigla dos estados do Brasil e uma para a região à qual cada estado pertence, uma para o valor do PIB, os valores de impostos e os valores adicionados da agropecuária, da indústria, dos serviços e da administração e seguridade social.
| # | ano | sigla_uf | regiao | pib | impostos_liquidos | va | va_agropecuaria | va_industria | va_servicos | va_adespss |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2002 | RO | Norte | 7467629886 | 839731192 | 6627898698 | 715526872 | 1191090432 | 2484579193 | 2236702207 |
| 1 | 2003 | RO | Norte | 9425010486 | 1108434936 | 8316575548 | 1278658831 | 1216605061 | 3376727040 | 2444584625 |
| 2 | 2004 | RO | Norte | 11004641436 | 1288806654 | 9715834778 | 1288515348 | 1674933817 | 3986529419 | 2765856199 |
| 3 | 2005 | RO | Norte | 12511821181 | 1476144194 | 11035676990 | 1342222120 | 1887932121 | 4603783904 | 3201738843 |
| 4 | 2006 | RO | Norte | 13054713344 | 1613809974 | 11440903374 | 1238006193 | 2210692147 | 4320526746 | 3671678293 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 508 | 2016 | DF | Centro-Oeste | 235540044811 | 29145619376 | 206394425435 | 820754661 | 9662357225 | 103859865830 | 92051447720 |
| 509 | 2017 | DF | Centro-Oeste | 244722249337 | 29120461647 | 215601787690 | 828313642 | 8448768236 | 108322119432 | 98002586380 |
| 510 | 2018 | DF | Centro-Oeste | 254817204692 | 28692287369 | 226124917323 | 1022690641 | 9541298290 | 113768086938 | 101792841454 |
| 511 | 2019 | DF | Centro-Oeste | 273613711477 | 30686607647 | 242927103829 | 992393584 | 9453608031 | 125261853488 | 107219248727 |
| 512 | 2020 | DF | Centro-Oeste | 265847334003 | 25466227775 | 240381106228 | 1623976909 | 10942472569 | 116547655370 | 111267001381 |
Podemos verificar os tipos dos nossos dados utilizando o código:
# Verificando os tipos de dados e se existem dados nulos
df_pib.info()
Ao executar este código, podemos observar que temos 513 valores não nulos para todas as nossas colunas, indicando que nossos dados já estão tratados e não precisamos nos preocupar com a limpeza, apenas com a seleção e filtragem.
Os dados estão em tipos inteiros e objetos, não havendo dado do tipo float, pois os valores estão representados em tipo inteiro.
Retorno dos tipos
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 513 entries, 0 to 512
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ano 513 non-null int64
1 sigla_uf 513 non-null object
2 regiao 513 non-null object
3 pib 513 non-null int64
4 impostos_liquidos 513 non-null int64
5 va 513 non-null int64
6 va_agropecuaria 513 non-null int64
7 va_industria 513 non-null int64
8 va_servicos 513 non-null int64
9 va_adespss 513 non-null int64
dtypes: int64(8), object(2)
memory usage: 40.2+ KB
Questionamentos para os dados
Após importar nosso conjunto de dados e definir nossa paleta de cores, vamos conferir as perguntas que responderemos e análises que faremos ao longo destas aulas:
- Como está disposto o PIB nos estados brasileiros no ano de 2020? É possível notar os estados com maior e menor participação no PIB nacional?
- Houve uma significativa mudança na distribuição do PIB por região comparando os valores de 2002 e 2020?
- Qual a participação do estado de Minas Gerais no PIB de todo o Brasil no ano de 2020?
- Como está distribuído o PIB do estado da Bahia em 2020 separado por impostos líquidos e os valores adicionados brutos dos bens e serviços produzidos?
- Qual a evolução anual do PIB do estado do Rio de Janeiro entre os anos de 2010 a 2020?
- Como está distribuído o PIB nos 3 últimos quinquênios (lustro) dos dados (2010, 2015, 2020) na Região Sul do Brasil divididos pelos estados (Paraná, Santa Catarina e Rio Grande do Sul)?
- Como estão distribuídos, em porcentagem, os valores adicionados de bens e serviços descritos na base de dados em relação a cada região no ano de 2020?
- Na agropecuária, como estão distribuídos seus valores adicionados por região dentro do período da base dos dados (2002 - 2020)?
Todas essas questões serão respondidas ao longo das próximas aulas. Vamos começar?
Proporção dos dados - Problemas em um gráfico de pizza
Já alinhamos a paleta de cores e importamos os dados que vamos utilizar em nosso projeto. Agora, para começar a construir os gráficos de composição, vamos trabalhar com os questionamentos propostos. Vamos começar pelo primeiro:
Como está disposto o PIB nos estados brasileiros no ano de 2020? É possível notar os estados com maior e menor participação no PIB nacional?
Nesse sentido, temos duas variáveis de interesse: o próprio estado, que seria a nossa "Sigla UF", e o valor do PIB.
Os valores a serem apresentados aqui serão em escala percentual, pois estamos trabalhando com valores expressivos, e talvez a escala percentual consiga tornar essa visualização mais compacta, permitindo-nos apresentar uma quantidade maior de dados no mesmo espaço.
Tratamento dos dados
Para isso, vamos primeiramente tratar nosso dado para fazer essa composição. Vamos criar um dataframe chamado df_pib_2020, e fazer uma cópia profunda do df_pib que importamos em nossa aula anterior, usando o método copy():
df_pib_2020 = df_pib.copy()
Fazemos uma cópia profunda para evitar que as alterações feitas em um dataframe afetem o outro. Logo, as alterações que faremos no df_pib_2020 não afetarão o df_pib.
Agora, vamos fazer um query (consulta) para obter apenas os dados do ano de 2020:
df_pib_2020 = df_pib_2020.query("ano == 2020")
Além disso, também vamos definir o valor do estado como nosso índice, usando set_index():
df_pib_2020 = df_pib_2020.query("ano == 2020").set_index("sigla_uf")
Estamos definindo o índice para facilitar quando formos trabalhar com gráficos, assim poderemos puxar esse valor mais facilmente para representar dentro da nossa visualização.
Também vamos ordenar esses valores (com o método sort_values()) de acordo com o PIB. A ordem será decrescente, do maior para o menor, então usamos o parâmetro ascending=False.
Por fim, selecionamos apenas a coluna "pib", ou seja, no nosso dataframe teremos o sigla_uf como índice e os valores de PIB como coluna, sendo apenas uma coluna, então:
df_pib_2020 = df_pib_2020.query("ano == 2020").set_index("sigla_uf").sort_values("pib", ascending=False)[["pib"]]
Depois, juntamos os dois códigos criados anteriormente com a consulta de df_pib_2020 usando o método head():
# Criando um df com os dados desejados
df_pib_2020 = df_pib.copy()
df_pib_2020 = df_pib_2020.query("ano == 2020").set_index("sigla_uf").sort_values("pib", ascending=False)[["pib"]]
df_pib_2020.head()
Rodando esse código, recebemos a visualização do nosso dataframe. Ele representa, no lado esquerdo, as siglas dos estados como índice e, no lado direito, os valores de PIB:
| sigla_uf | pib |
|---|---|
| SP | 2377638979835 |
| RJ | 753823710636 |
| MG | 682786116407 |
| PR | 487930593779 |
| RS | 470941846057 |
Mesmo esses sendo valores absolutos, ao representarmos no gráfico, veremos que os valores serão apresentados de forma relativa.
Desse modo, já conseguimos separar a quantidade que queremos no nosso código, que são apenas as duas variáveis de interesse: sigla_uf e pib.
Gerando o gráfico
Agora, vamos gerar o gráfico. Para isso, precisamos importar uma biblioteca que faça a criação desse gráfico, o Matplotlib:
# Importando as bibliotecas
import matplotlib.pyplot as plt
Vamos definir a área do gráfico, que é todo o espaço externo da visualização chamado de fig, e o eixo onde estará nosso gráfico, chamado de ax. A figura terá 6 de comprimento por 6 de largura:
# Área do gráfico e tema da visualização
fig, ax = plt.subplots(figsize=(6,6))
Abaixo, vamos gerar o nosso gráfico, que será um gráfico de pizza. Para isso, vamos utilizar a função ax.pie(). Ou seja, vamos passar ax, que será o nosso objeto axis (eixo) e, em seguida, .pie().
Esse ax.pie() recebe alguns parâmetros. Dentre eles, o data, que serão nossos dados; ou seja, o nosso df, que será o df_pib_2020.
Vamos passar também x, que será a nossa coluna "pib", ou seja, os valores. Também vamos passar os labels, que seriam os valores que estarão escritos próximos a essas fatias. Logo, labels será igual a df_pib_2020.index, porque as nossas siglas são os índices nesse nosso dataframe.
Além disso, vamos passar outros parâmetros. Temos o autopct, que se refere à representação da porcentagem dentro da pizza. Portanto, o autopct vai receber, entre aspas, uma string que vai formatar esse dado.
Para formatar, vamos começar e terminar com sinal de porcentagem, para mostrar que esse é o espaço de formatação, e escrever como será a formatação do dado. Logo, vamos colocar % seguido de um 1f e novamente porcentagem: autopct = "%.1f%".
Com isso, estamos indicando que queremos que o dado em percentual seja formatado com uma casa decimal. E, por fim, vamos colocar mais um sinal de porcentagem para que o símbolo apareça ao lado do número: "%.1f%%":
ax.pie(data = df_pib_2020, x = "pib", labels = df_pib_2020.index, autopct = "%.1f%%")
Outro parâmetro que podemos incluir nessa função seria o radius, o raio da pizza. Portanto, vamos colocar um radius de 1.1. O pctdistance é a distância do centro da pizza até o ponto onde queremos que seja escrito nosso dado. Assim, vamos definir como 0.8, para colocar mais próximo do final da pizza, e não próximo do centro.
Por fim, vamos trazer um outro componente, que serão as propriedades do texto.
Vamos chamar um textprops que vai receber um dicionário (("")) . Nesse dicionário, vamos passar apenas a modificação do size, o tamanho, definindo-o como 12.
Dessa forma, teremos o seguinte código para gerar o gráfico:
# Gerando o gráfico de pizza
ax.pie(data = df_pib_2020, x = "pib", labels = df_pib_2020.index, autopct = "%.1f%%",
radius = 1.1, pctdistance=0.8, textprops={"size":12})
Além disso, vamos também personalizar essa visualização e criar um título superior, "Produto Interno Bruto (PIB) por estado (2020)" explicando os valores percentuais no subtítulo:
# Personalizando o gráfico
plt.suptitle('Produto Interno Bruto (PIB) por estado (2020)', size=18, color=CINZA1)
plt.title('Em porcentagem (%)', fontsize=14, color=CINZA3, pad = 15, x = 0.1, y = 0.98 )
Vamos executar o código para ver como ficou o nosso gráfico:
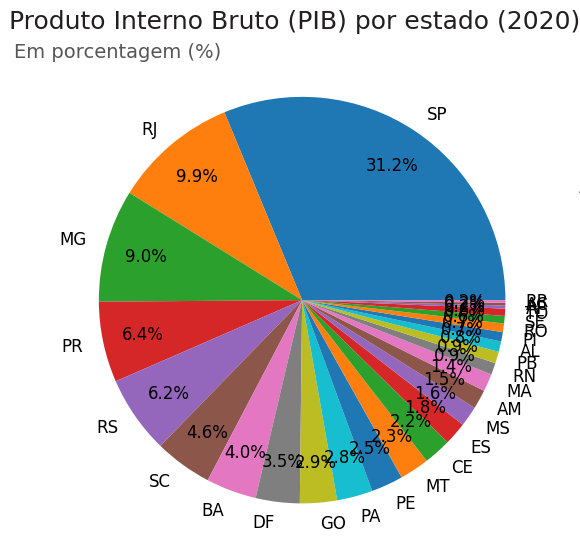
Fica um pouco difícil de visualizar, não é? São Paulo, Rio de Janeiro e Minas Gerais, com a maior representatividade, são mais fáceis de distinguir dos outros estados. Quanto menor for a participação do estado no PIB, mais difícil enxergar. Não conseguimos notar os estados menores.
Para resolver esse problema, vamos executar um código de texto na célula de criação do gráfico, que vai trazer uma pequena explicação sobre seu comportamento:
# Anotando uma conclusão no gráfico
ax.text(1.1, 0.5,
'Um $\\bf{gráfico\ de\ pizza}$, consegue trazer a informação de\n'
'participação no PIB de forma direta, no entanto, percebemos\n'
'que o uso de $\\bf{muitas\ fatias}$ atrapalham na análise dos\n'
'dados para estados com $\\bf{menor}$ parcela no PIB.\n'
'Além de gerar incômodo visualmente para quem lê.\n\n'
'Percebemos que os estados de $\\bf{São\ Paulo}$, $\\bf{Rio\ de\ Janeiro}$ e $\\bf{Minas\ Gerais}$\n'
'possuem $\\bf{maior}$ participação no PIB nacional, porém, não conseguimos\n'
'precisar quais estados tem a menor e quanto seria em percentual.',
fontsize=12,
linespacing=1.45,
color=CINZA3, transform= ax.transAxes)
plt.show()
Ela explica, basicamente, que o nosso gráfico consegue trazer de maneira direta a participação de cada um dos estados brasileiros no PIB de 2020; no entanto, o uso de muitas fatias prejudica a nossa visualização. Além de gerar um pouco de desconforto ao olhar esse tipo de gráfico, quanto menor o valor, mais difícil será perceber qual é a participação dos estados:
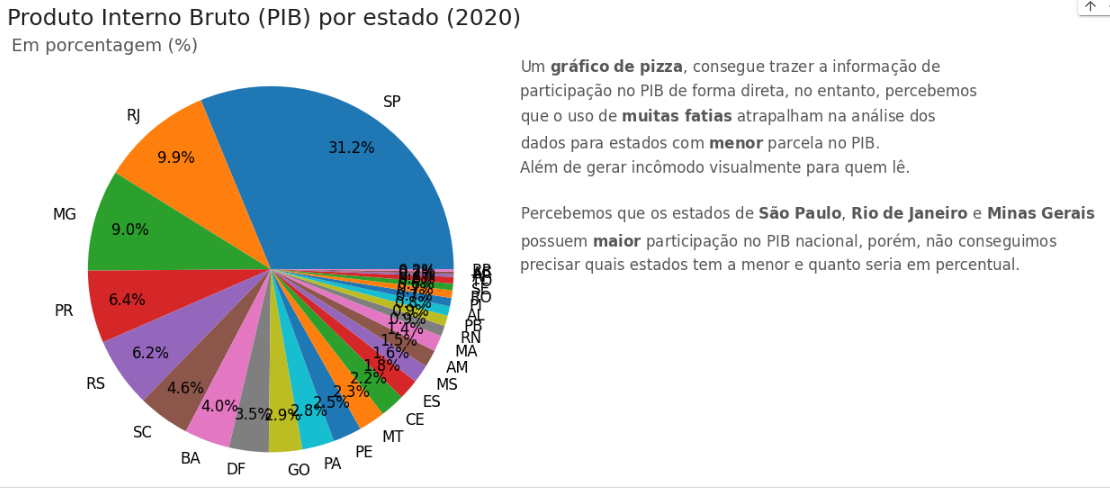
Portanto, um gráfico de pizza não é adequado para muitas fatias, ou seja, para muitas categorias de dados.
Nesse ponto, podemos pensar no seguinte: se o gráfico de pizza não é ideal para uma quantidade tão grande de fatias, qual o máximo de fatias que podemos representar? Precisamos refletir sobre isso.
Conseguiremos utilizar a pizza de alguma forma para representar nossos dados? Descobriremos a seguir!
Sobre o curso Data Visualization: gráficos de composição e relacionamento
O curso Data Visualization: gráficos de composição e relacionamento possui 204 minutos de vídeos, em um total de 60 atividades. Gostou? Conheça nossos outros cursos de Data Science em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Proporção dos dados
- Compondo dados estáticos
- Compondo dados dinâmicos
- Investigando a variação dos dados
- Relacionando dados