Estatística com Python: resumindo e analisando dados
Entendendo os dados - Apresentação
Olá! Eu sou Danielle Oliveira, instrutora da Escola de Dados, e vou te acompanhar neste curso sobre estatística com Python.
Audiodescrição: Danielle Oliveira se descreve como uma mulher de pele morena. Tem cabelos escuros cacheados e olhos castanhos. Usa uma blusa na cor preta e está sentada. Ao fundo, parede branca com iluminação grandiente do verde ao azul e duas pequenas prateleiras com decorações.
Vamos conhecer um pouco mais sobre o que aprenderemos durante este curso. Antes disso, é importante reforçar que este curso é destinado a quem está iniciando em estatística com Python. Além disso, se você já tiver conhecimento sobre esta linguagem, o curso também será muito proveitoso.
O que vamos aprender?
Nós iniciamos o desenvolvimento do nosso projeto como cientistas de dados em uma empresa que presta serviços de consultoria para outras empresas brasileiras. Vamos aplicar conceitos estatísticos, entender os tipos de dados das nossas variáveis, explorar problemas e identificar as melhores análises para compreender e resolver esses problemas.
Também aplicaremos medidas de tendência central e entenderemos a diferença entre cada uma delas. Além disso, utilizaremos medidas separatrizes e medidas de dispersão para resumir nossos dados. Por fim, vamos gerar insights e levantar hipóteses sobre as demandas que nos foram solicitadas.
Para atingir esses resultados, utilizaremos a base de dados disponibilizada de alguns setores da nossa empresa comercial, como vendas, marketing, RH e financeiro.
Agora que já conhecemos o que vamos estudar, vamos começar a praticar e entender sobre a estatística com Python.
Entendendo os dados - Importando os pacotes e lendo os dados
Nós atuaremos como cientistas de dados em uma consultoria que presta serviços para diversas empresas. Atualmente, estamos acompanhando uma rede de varejo que atende todo o Brasil. Nosso objetivo é, por meio da estatística e da análise de dados, responder diversos casos que auxiliarão na tomada de decisão e na geração de insights para esses clientes. Faremos isso utilizando dados coletados de diversos setores dessa empresa, como RH, vendas, marketing e financeiro.
O primeiro passo importante é começar a investigar nossa base de dados. Precisamos definir qual abordagem utilizaremos para responder a esses casos por meio da estatística e como investigaremos e manipularemos esses dados.
Para obter esses insights, utilizaremos o Google Colab Notebook, uma ferramenta amplamente utilizada por cientistas de dados. Com essa ferramenta, conseguimos criar textos e executar códigos.
Importando a biblioteca Pandas
Durante a construção do nosso projeto, exploraremos nossa base de dados, geraremos visualizações e responderemos a diversas perguntas. Para isso, começaremos importando um pacote essencial para cientistas de dados e pesquisadores: a biblioteca Pandas.
Já estamos com o notebook aberto. Não se preocupe, disponibilizaremos esse arquivo para que você possa acompanhar, passo a passo, a execução do projeto. Também é possível criar o notebook do zero para seguir com os estudos.
Para importar o Pandas, executamos o seguinte código: especificamos na célula a palavra import e indicamos qual biblioteca ou pacote queremos importar, que neste caso é o pandas. Podemos dar um apelido para esse pacote, utilizando o código as pd, para indicar como vamos nos referenciar ao Pandas durante todo o uso no notebook.
import pandas as pd
Podemos executar a importação, clicando no botão de "play" à esquerda da célula (ou atalho "Shift + Enter"). Não recebemos nenhum erro, portanto, o código foi executado com sucesso.
Carregando dados
Agora que já importamos o pacote necessário, começaremos a trabalhar com nossos dados. O primeiro passo é trazer os dados para dentro do notebook. Eles estão armazenados em um arquivo CSV na web, ou seja, fora do nosso notebook e não estão no ambiente local.
Conseguimos fazer a leitura desses arquivos especificando o link onde o arquivo está localizado, salvando-o em uma variável chamada url.
Em seguida, utilizaremos o Pandas para fazer a leitura dos dados com a função read_csv(), já que os dados estão em formato CSV. Armazenaremos isso na variável df, que conterá um dataframe.
url = 'https://raw.githubusercontent.com/alura-cursos/estatistica-r-frequencias-medidas/refs/heads/main/dados/vendas_ecommerce.csv '
df = pd.read_csv(url)
Em seguida, faremos a leitura dos dados através de uma outra função. Vamos especificar o dataframe, que será df, e utilizaremos a função head() para obter como retorno os cinco primeiros registros desse dataframe. Dessa forma, teremos a certeza de que os dados foram importados corretamente para dentro dessa variável.
df.head()
| id_compra | sexo_biologico | idade_cliente | regiao_cliente | categoria_produto | preco_unitario | quantidade | total_compra | tempo_entrega | avaliacao |
|---|---|---|---|---|---|---|---|---|---|
| 9f86e969-221a-4b1a-9b48-9aba719b61cf | Masculino | 33 | Sul | Ferramentas e Construção | 96.80 | 2 | 193.60 | 18 | 1 |
| 659f9b07-be10-4849-b2ab-dd542498a1e8 | Feminino | 33 | Nordeste | Alimentos e Bebidas | 247.68 | 1 | 247.68 | 6 | 4 |
| d317d7df-1126-42e5-bf4b-0e178bd4e14e | Feminino | 36 | Sudeste | Eletrônicos | 627.46 | 2 | 1254.92 | 8 | 5 |
| bb99bcf6-b333-493e-9ec2-c39f8695503c | Feminino | 21 | Sul | Eletrônicos | 2025.07 | 8 | 16200.56 | 6 | 5 |
| 898e4624-84e9-4c41-b181-66d3b7ccfef7 | Masculino | 31 | Centro-Oeste | Papelaria e Escritório | 99.24 | 5 | 496.20 | 13 | 5 |
Depois de executar, teremos como retorno os cinco primeiros registros.
Analisando estrutura da base
Outra forma de validar essas informações é verificando a quantidade de linhas e colunas do nosso dataset. Isso é importante porque não conseguiríamos visualizar todos os registros existentes na base de dados, especialmente se a quantidade de dados for muito grande.
Para visualizar e entender o tamanho da nossa base de dados, podemos utilizar uma função que retorna a quantidade de colunas e linhas do dataset. Na próxima célula, vamos especificar novamente o df, que é o dataset, e utilizar a função shape().
df.shape
(200000, 10)
Com isso, confirmamos que o dataset possui 200 mil linhas e 10 colunas.
Além disso, podemos verificar a estrutura da nossa base de dados, ou dataset, para identificar valores nulos e os tipos de dados de cada campo. Isso nos ajuda a validar se os dados precisam de algum tratamento antes de iniciar as análises. Para isso, utilizaremos a função info() no dataframe df.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200000 entries, 0 to 199999
Data columns (total 10 columns):
# Column Non-Null Count Dtype 0 id_compra 200000 object 1 sexo_biologico 200000 object 2 idade_cliente 200000 int64 3 regiao_cliente 200000 object 4 categoria_produto 200000 object 5 preco_unitario 200000 float64 6 quantidade 200000 int64 7 total_compra 200000 float64 8 tempo_entrega 200000 int64 9 avaliacao 200000 int64 dtypes: float64(2), int64(4), object(4)
Assim, obtemos informações como o nome das colunas e a quantidade de linhas em cada coluna, que são todas iguais. Verificamos também se existem valores nulos; neste caso, não há nenhum. Caso encontrássemos, seria necessário algum tratamento. Além disso, identificamos o tipo de cada coluna, como object (campo string), int (inteiro) e float (números decimais).
Conclusão
Dessa forma, conseguimos importar nossos dados e explorar o dataset. Com esses dados, poderemos responder a diversas perguntas, como a quantidade de vendas por região, uma informação muito importante para nosso cliente.
Para todas essas análises, existem duas perguntas cruciais:
- Qual o tipo de dado que temos?
- O que desejamos investigar com esses dados?
A estatística é fundamental para investigar os dados com os quais estamos lidando. Agora que preparamos nosso ambiente, com os dados importados e os pacotes instalados, vamos começar a obter insights importantes para a empresa cliente.
Entendendo os dados - Investigando os tipos dos dados
Ao avaliar os nossos dados, conseguimos identificar uma variedade de formatos diferentes. Ou seja, nossos dados possuem tipos distintos, como dados numéricos (que são os inteiros e decimais) e dados textuais (que são as strings). Baseado nisso, trabalharemos de forma diferenciada com esses dados. Como podemos identificar a natureza ou o tipo dos nossos dados e extrair informações a partir disso?
Investigando os tipos de dados
Vamos começar a investigar mais a fundo no nosso dataset. Primeiramente, vamos relembrar a estrutura do dataset através da função df.head().
df.head()
| id_compra | sexo_biologico | idade_cliente | regiao_cliente | categoria_produto | preco_unitario | quantidade | total_compra | tempo_entrega | avaliacao |
|---|---|---|---|---|---|---|---|---|---|
| 9f86e969-221a-4b1a-9b48-9aba719b61cf | Masculino | 33 | Sul | Ferramentas e Construção | 96.80 | 2 | 193.60 | 18 | 1 |
| 659f9b07-be10-4849-b2ab-dd542498a1e8 | Feminino | 33 | Nordeste | Alimentos e Bebidas | 247.68 | 1 | 247.68 | 6 | 4 |
| d317d7df-1126-42e5-bf4b-0e178bd4e14e | Feminino | 36 | Sudeste | Eletrônicos | 627.46 | 2 | 1254.92 | 8 | 5 |
| bb99bcf6-b333-493e-9ec2-c39f8695503c | Feminino | 21 | Sul | Eletrônicos | 2025.07 | 8 | 16200.56 | 6 | 5 |
| 898e4624-84e9-4c41-b181-66d3b7ccfef7 | Masculino | 31 | Centro-Oeste | Papelaria e Escritório | 99.24 | 5 | 496.20 | 13 | 5 |
Assim, obtemos as cinco primeiras linhas do dataset, que apresentam uma variedade de tipos diferentes de dados.
Existem dados de string, como sexo_biologico, e dados numéricos, como o total_compra, que é um dado numérico decimal. Outro exemplo é a idade_cliente, que é um dado inteiro, por exemplo, 33 anos.
Essas variáveis (ou colunas) podem ser classificadas em dois tipos: variáveis categóricas, que são consideradas qualitativas; e variáveis numéricas, que são consideradas quantitativas. Vamos explorar um pouco mais sobre essas classificações.
- Qualitativas (categóricas): representam uma característica ou categoria e são subdivididas em duas classificações:
- Nominais: não possuem uma ordem natural, como o tipo do produto;
- Ordinais: possuem uma ordem ou hierarquia, como nível de escolaridade, que segue uma sequência como primeira série, segunda série, terceira série, e assim por diante.
- Quantitativas (numéricas): representam números e podem ser mensuradas. Elas são subdivididas em duas classificações:
- Quantitativas discretas: são valores inteiros e contáveis, como a quantidade de produtos;
- Quantitativas contínuas: podem assumir qualquer valor em um intervalo, como altura ou peso.
Manipulando variável qualitativa nominal
A partir disso, podemos realizar análises sobre nossos dados. Vamos começar investigando uma variável qualitativa nominal, que é a quantidade de vendas. Nesse caso, vamos calculá-la por categoria.
Para isso, precisamos buscar as categorias existentes dentro do nosso dataset. Aplicaremos um filtro para buscar apenas a variável categoria. Em uma nova célula, especificamos df e passamos o campo que queremos filtrar entre colchetes e aspas, que é categoria_produto.
df['categoria_produto']
| # | categoria_produto |
|---|---|
| 0 | Ferramentas e Construção |
| 1 | Alimentos e Bebidas |
| 2 | Eletrônicos |
| 3 | Eletrônicos |
| 4 | Papelaria e Escritório |
| ... | ... |
| 199995 | Eletrônicos |
| 199996 | Eletrônicos |
| 199997 | Roupas, Calçados e Acessórios |
| 199998 | Alimentos e Bebidas |
| 199999 | Beleza e Cuidados Pessoais |
Obtemos como retorno apenas a coluna de categoria. No entanto, como todos os registros são retornados, existem várias categorias duplicadas. Vamos aplicar um filtro para retornar apenas as categorias de forma única. A partir do código inicial, vamos acrescentar a função unique().
df['categoria_produto'].unique()
array(['Ferramentas e Construção', 'Alimentos e Bebidas', 'Eletrônicos', 'Papelaria e Escritório', 'Beleza e Cuidados Pessoais', 'Casa e Mobílias', 'Roupas, Calçados e Acessórios', 'Livros', 'Brinquedos', 'Esporte e Lazer'], dtype=object)
Com essa função, é retornado um array com apenas as categorias únicas, sem repetição. Temos ferramentas de construção, alimentos e bebidas, eletrônicos, papelaria, escritório, entre outros.
No entanto, queremos a quantidade de vendas por categoria. Vamos avançar na construção desse objetivo. Em uma nova célula, vamos especificar novamente o df['categoria_produto'] e realizar a contagem através da função value_counts().
df['categoria_produto'].value_counts()
| categoria_produto | count |
|---|---|
| Eletrônicos | 36060 |
| Roupas, Calçados e Acessórios | 27917 |
| Casa e Mobílias | 26015 |
| Beleza e Cuidados Pessoais | 22026 |
| Esporte e Lazer | 19939 |
| Alimentos e Bebidas | 18022 |
| Papelaria e Escritório | 13936 |
| Livros | 13790 |
| Ferramentas e Construção | 12063 |
| Brinquedos | 10232 |
Assim, obtemos a quantidade de vendas por cada categoria. A categoria com mais vendas é a de eletrônicos, seguida por roupas e calçados.
Para visualizar melhor essa informação, vamos plotar um gráfico. Antes disso, precisamos ajustar o comando. Quando utilizamos value_counts(), cria-se uma series. Para plotar o gráfico com esses dados, precisamos que essa informação volte a ser um dataframe.
Para isso, utilizamos a função reset_index(). Além disso, salvamos essas informações na variável produtos.
produtos = df['categoria_produto'].value_counts().reset_index()
produtos
| # | categoria_produto | count |
|---|---|---|
| 0 | Eletrônicos | 36060 |
| 1 | Roupas, Calçados e Acessórios | 27917 |
| 2 | Casa e Mobílias | 26015 |
| 3 | Beleza e Cuidados Pessoais | 22026 |
| 4 | Esporte e Lazer | 19939 |
| 5 | Alimentos e Bebidas | 18022 |
| 6 | Papelaria e Escritório | 13936 |
| 7 | Livros | 13790 |
| 8 | Ferramentas e Construção | 12063 |
| 9 | Brinquedos | 10232 |
Agora, vamos plotar essas informações em um gráfico. Para realizar a plotagem, vamos importar a biblioteca Matplotlib, utilizada para plotagem de gráficos. Em uma nova célula, importamos a biblioteca matplotlib, especificamente o pacote pyplot, e usamos o alias plt.
import matplotlib.pyplot as plt
Em seguida, especificamos plt.barh() para plotar um gráfico de barras horizontais. Dentro da função, vamos definir a coluna produtos['categoria_produto'] no eixo Y e a coluna produtos['count'] no eixo X. Assim, plotamos a categoria do produto e a contagem de vendas.
Por fim, adicionamos plt.show() para visualizar o gráfico.
plt.barh(produtos['categoria_produto'], produtos['count'])
plt.show()
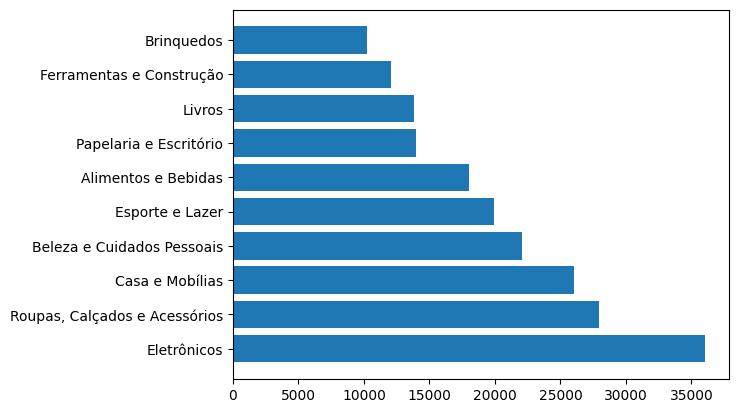
No gráfico, as categorias aparecem ordenadas da menor para a maior quantidade de vendas. A visualização gráfica torna mais interessante trabalhar e identificar os dados. Com isso, conseguimos identificar uma informação importante: a categoria de eletrônicos é a que mais possui vendas, o que é relevante para nosso cliente, uma rede de varejo.
Já trabalhamos com uma variável qualitativa nominal, mas há diversos outros tipos de variáveis que podemos explorar.
Sobre o curso Estatística com Python: resumindo e analisando dados
O curso Estatística com Python: resumindo e analisando dados possui 170 minutos de vídeos, em um total de 56 atividades. Gostou? Conheça nossos outros cursos de Estatística em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Entendendo os dados
- Identificando o perfil do público
- Analisando a tendência dos dados
- Investigando os dados dos colaboradores
- Analisando as variações dos dados