Estatística com R: aplicando testes de hipóteses
Teste de normalidade e etapas de um teste de hipótese - Apresentação
Você já se perguntou como utilizar a estatística para ajudar na tomada de decisões e gerar insights, investigando os dados e reduzindo as incertezas das análises? Quer aprender a utilizar testes estatísticos para validar hipóteses e tomar decisões mais confiáveis utilizando a linguagem R como ferramenta?
É exatamente isso que vamos aprender neste curso de Estatística com R: aplicado a teste de hipóteses.
Meu nome é Afonso Rios, sou instrutor na Escola de Data Science da Alura.
Audiodescrição: Afonso se descreve como um homem de pele morena, com cabelos e olhos castanhos escuros. Usa uma camisa preta com o símbolo da Alura. Ao fundo, há uma parede com iluminação esverdeada e algumas decorações que remetem tanto à Alura quanto ao futebol.
O que aprenderemos?
Neste curso, atuaremos como consultores, prestando consultorias em diversas empresas e respondendo a algumas demandas que elas solicitam. Essas demandas serão aplicadas utilizando conceitos de estatística e inferência de dados para auxiliar na resolução desses casos, ajudando tanto na tomada de decisões quanto na geração de insights.
Neste curso, vamos aprender a analisar dados e considerar o contexto, além de levantar hipóteses sobre os problemas que enfrentaremos. Também aprenderemos a definir o teste estatístico adequado para cada tipo de problema, de acordo com os dados e as necessidades do negócio.
Executaremos testes de hipóteses em diversos casos, interpretando corretamente os resultados. Vamos lidar com incertezas e tomar decisões baseadas em evidências, bem como validar essas hipóteses em problemas reais.
Por fim, utilizaremos a linguagem R para reportar essas análises, os resultados esperados e comunicar esses resultados em forma de insights para gestores e clientes.
Pré-requisitos
Para aproveitar ao máximo este curso, é importante que você já tenha algum conhecimento na linguagem R, especialmente em conceitos de estatística e inferência estatística, como distribuição de frequência, medidas de tendência central, medidas de separatrizes, medidas de dispersão, amostragem, estimativa de valores, cálculos de probabilidade, nível de confiança e significância. Esses conceitos são primordiais para se trabalhar com o teste de hipóteses.
Com as expectativas alinhadas, vamos começar o nosso projeto!
Teste de normalidade e etapas de um teste de hipótese - Iniciando o projeto
Estamos atuando como cientistas de dados em uma consultoria que presta serviços a diversas empresas de diferentes áreas. Nosso desafio é aplicar conceitos de estatística, mais precisamente de inferência estatística e testes de hipóteses, para resolver casos que auxiliem tanto nas tomadas de decisão quanto na geração de insights para a nossa clientela.
Para isso, teremos acesso a resultados de pesquisas e dados de diferentes equipes dessas empresas, sejam casos voltados para marketing, vendas, logística ou até recursos humanos. Por exemplo, podemos verificar se a remuneração está adequada entre os pares ou se um tipo de campanha faz mais sentido que outra, entre diversas situações nas quais podemos aplicar o teste de hipóteses.
Precisamos entender qual abordagem será necessária para cada caso, utilizando conceitos tanto de estatística quanto da linguagem R. Também precisamos definir qual teste de hipóteses deve ser aplicado para cada problema, de acordo com os dados que temos e, claro, com o que queremos responder.
Por exemplo, se uma empresa de produção deseja saber se sua produção segue um padrão de qualidade, que tipo de teste deve ser realizado? Como realizar esse teste? Tudo isso será abordado em nosso curso.
Importando pacotes e configurando o ambiente
Para iniciar, trouxemos um documento do Google Colab, que é um notebook com diversas instruções, um passo a passo, dos processos para criar diferentes testes de hipóteses e responder perguntas.
Primeiro, trouxemos uma pequena introdução do contexto do notebook e, claro, a iniciação do projeto. Antes de começar a executar qualquer teste de hipóteses ou entender os processos, é importante importar os pacotes necessários, tanto para as pessoas pesquisadoras quanto para as pessoas cientistas de dados.
No R, existem diversos pacotes que podem auxiliar no assunto de teste de hipóteses e inferência estatística. Nesse caso, apresentamos uma forma alternativa de importar esses pacotes. Em vez de importar pacote por pacote, o que pode demorar muitos minutos no ambiente do Colab por ser em nuvem, criamos um ambiente virtual no GitHub.
Basta rodar o seguinte código com "Shift + Enter" para puxar a biblioteca com todos os pacotes necessários para o curso:
# Baixando o arquivo de ambiente do R
R_environment_file <- "https://github.com/alura-cursos/estatistica-r-testes-hipoteses/raw/refs/heads/main/libs/library.tar.gz"
download.file(R_environment_file, destfile="./library.tar.gz")
# unzip do arquivo library do R: 'library.tar.gz' para a pasta library do R
untar("library.tar.gz", "library")
# Mudando a pasta das libs do R para './library'
.libPaths("library")
Isso reduz o tempo de minutos para segundos, pois os pacotes já estão consolidados e serão descompactados no ambiente do Colab quando estivermos executando nossos dados.
Em seguida, faremos a importação dos pacotes do projeto. Já os instalamos, mas ainda não estão no ambiente onde queremos aplicá-los. Para isso, utilizamos pacotes como: dplyr para manipulação de dados; ggplot2 para visualização; rstatix para pipelines de estatística e teste de hipóteses; e BSDA, que também é utilizado para alguns tipos de testes necessários no curso.
# Importando os pacotes do projeto
library(dplyr, warn.conflicts = F)
library(ggplot2, warn.conflicts = F)
library(rstatix, warn.conflicts = F)
library(BSDA, warn.conflicts = F)
options(repr.matrix.max.rows = 10)
O parâmetro warn.conflicts que colocamos em cada pacote é apenas para evitar conflitos. Não é um erro, mas sim um aviso. Por fim, configuramos options() com repr.matrix.max.rows = 10 para que, ao rodar uma tabela, ela não exiba todos os valores, mas apenas os 10 primeiros para visualização.
Configurando parâmetros visuais no ggplot2
Agora, trouxemos outro código, que também será executado antes de começar o projeto. Essa célula serve para criar parâmetros para trabalhar com visuais no ggplot2. Para evitar ajustes manuais nos rótulos, tamanhos de texto e títulos, deixamos tudo formatado previamente. Assim, todos os visuais criados no ggplot2 terão essa formatação.
# Ajustando parâmetros para visuais que serão construídos ao longo do curso
options(repr.plot.width = 16, repr.plot.height = 8)
tema <- theme(
plot.title=element_text(size = 22, hjust = 0.5),
axis.title.y=element_text(size = 16, vjust = +0.2),
axis.title.x=element_text(size = 16, vjust = -0.2),
axis.text.y=element_text(size = 14),
axis.text.x=element_text(size = 14),
legend.position = "none")
Existem cursos na Alura, especialmente na formação de R, que explicam como criar esse tema. Vamos rodar e armazenar o código.
Compreendendo fundamentos dos testes de hipóteses
Antes de começar a fazer os testes de hipóteses, é importante entender como serão esses processos. Já aprendemos em cursos anteriores a estimar valores, calcular a probabilidade de distribuição normal, calcular intervalos de confiança e tamanho de amostra, além de compreender o nível de significância e confiança. Tudo isso serve de base para os testes de hipóteses que aplicaremos nesse curso.
Mas o que seria um teste de hipóteses?
De forma resumida, um teste de hipótese é uma ferramenta para ajudar a tomar decisões e tirar conclusões sobre uma população com base em dados amostrais.
Ao invés de realizar uma pesquisa censitária, podemos usar uma amostra que ditará os comportamentos da população. Aprendemos sobre isso ao discutir estimativa de valores e tamanho de amostra.
No teste de hipótese, agimos como detetives, levantando hipóteses, ou seja, afirmações, baseadas em probabilidade. Assim, avaliamos se as evidências coletadas sustentam ou refutam essas afirmações.
Nesse campo, podemos responder perguntas como: existe uma diferença significativa entre dois grupos? A média observada é compatível com o valor esperado? As variáveis do projeto estão relacionadas?
Quando usamos testes estatísticos, queremos entender padrões dos dados, comparar grupos ou verificar relações entre variáveis.
Para que o curso tenha fluidez e compreensão dos processos, dividimos em duas partes:
- testes paramétricos: que têm uma distribuição conhecida e assumem premissas em relação à população;
- testes não-paramétricos: que são mais flexíveis.
Ao longo do curso, abordaremos problemas práticos, aplicando o teste de hipóteses e utilizando a linguagem R. Dessa forma, desenvolveremos habilidades para discernir a abordagem mais adequada para cada tipo de dado e processo, além de interpretar e gerar conclusões sobre os dados.
Já entendemos os pacotes necessários, o que são testes de hipótese e nosso processo ao longo do curso. Vamos começar a aplicar nosso primeiro teste estatístico?
Teste de normalidade e etapas de um teste de hipótese - Teste de normalidade (Shapiro-Wilk)
Aprendemos em cursos anteriores a trabalhar com vários conceitos da estatística, desde a análise de dados até a inferência estatística, seja por meio de estimação de valores, cálculo de probabilidade e trabalho com diferentes distribuições de dados.
Agora, precisamos entender como o teste de hipótese pode nos ajudar a compreender o comportamento dos dados. Para isso, vamos trabalhar com nosso primeiro teste estatístico, no qual vamos avaliar nossa hipótese sobre os parâmetros populacionais, seja aceitando ou rejeitando essa hipótese com base em uma amostra.
Conhecendo estudo de caso
Para ilustrar, trouxemos um estudo de caso de uma empresa varejista de e-commerce que possui um setor de recursos humanos. Nesta empresa, a área de recursos humanos está realizando uma análise dos dados das pessoas colaboradoras para entender melhor a distribuição de duas variáveis importantes:
- a remuneração das pessoas funcionárias, que reflete a estrutura salarial da empresa
- as horas de treinamento realizadas pelas pessoas colaboradoras durante o ano de 2004, que indicam o investimento em capacitação.
Antes de aplicar qualquer teste estatístico, é essencial verificar se essas variáveis seguem ou não uma distribuição normal, pois muitos métodos estatísticos, como os testes paramétricos, assumem a normalidade dos dados.
Para responder a essas perguntas, utilizaremos um teste muito importante que avalia a normalidade dos dados, chamado teste de Shapiro-Wilk. Não se preocupe em entender todos os conceitos agora, pois nos próximos vídeos explicaremos cada um com mais detalhes, para que fique claro quando você estiver realizando os processos para outros testes.
Entendendo teste de normalidade
O teste de normalidade de Shapiro-Wilk é um método estatístico que avalia se uma amostra de dados vem de uma distribuição normal. Ele compara a distribuição observada, de onde veio a amostra, com uma distribuição normal teórica, gerando assim um p-valor.
Vamos aprender mais à frente o que é o p-valor, mas, neste momento, é importante prestar atenção em dois pontos sobre ele:
- Se
p-valorfor maior que o nível de significância (geralmente 0,05, que representa 5%), não rejeitamos a hipótese nula, ou seja, os dados seguem uma distribuição normal; - Se
p-valorfor menor que o nível de significância, rejeitamos a hipótese nula, o que indica que os dados não seguem uma distribuição normal.
Além do teste que vamos utilizar, já aprendemos outras formas de visualizar se uma variável é uma distribuição normal ou não, como por meio de histogramas e curvas de densidade. Embora essas formas não ofereçam tanta certeza, pela forma da distribuição, podemos ter uma ideia se os dados são normais. No entanto, é importante realizar testes de hipótese, que nos dão segurança para esse tipo de resposta.
Para realizar esse teste, vamos usar uma função do R chamada shapiro.test() da biblioteca Stats. Assim, conseguiremos verificar se os dados seguem ou não uma distribuição normal.
Preparando dados e definindo significância
Inicialmente, vamos ler nossos dados com read.csv(), passando o link onde está a tabela, chamada tabela_colaboradores.csv. Vamos rodar essa tabela e armazenar em dados.
dados <- read.csv("https://raw.githubusercontent.com/alura-cursos/estatistica-r-testes-hipoteses/refs/heads/main/dados/colaboradores.csv")
Para verificá-los, utilizaremos head() na variável dados, que nos permite observar as seis primeiras linhas.
head(dados)
Saída: A data.frame 6x8
# id_colaborador
<chr>nome
<chr>sexo_biologico
<chr>idade
<int>cargo
<chr>nota_desempenho
<chr>remuneracao
<dbl>horas_treinamento
<int>1 DIR000001 Théo Sales Masculino 45 Diretor(a) Bom 29950.79 17 2 DIR000002 Isis Pinto Feminino 45 Diretor(a) Bom 27261.07 22 3 DIR000003 Isabelly Garcia Feminino 45 Diretor(a) Bom 25635.61 29 4 DIR000004 Nina Pereira Feminino 45 Diretor(a) Excelente 27678.60 18 5 DIR000005 Otávio Azevedo Masculino 46 Diretor(a) Excelente 32084.55 25 6 GER000006 João Pedro da Mata Masculino 42 Gerente Excelente 21656.81 17
Entre as colunas, duas são de maior interesse: a coluna de remuneracao e a horas_treinamento.
Para saber quantos dados possuímos, podemos usar o método nrow(), que nos mostrará que temos 11.090 linhas, ou seja, 11.090 colaboradores na tabela de dados.
nrow(dados)
Saída: 11090
Quando trabalhamos com o processo de hipótese, não necessariamente usamos todos os dados, por isso falamos de amostras. Vamos selecionar uma quantidade de pessoas dentro desse total e analisar essa amostra, relacionando-a com os parâmetros populacionais.
Antes de iniciar um teste, é importante definir a significância do teste, ou seja, a quantidade de erro tolerável no projeto. Nesse caso, utilizaremos a significância mais comum, que é 0,05 (5%), o que significa que temos 95% de confiança de que o que está sendo representado é a realidade.
significancia <- 0.05
Como trabalhamos com amostras e não com populações, não temos certeza de que estaremos 100% corretos. A significância nos dá o grau de aceitação do erro que pode haver na estimativa.
Visualizando dados com histogramas
Após definir a significância, vamos criar uma visualização, como fizemos anteriormente. Vamos criar dois histogramas para verificar como os dados estão distribuídos e perceber se a distribuição pode ou não ser normal.
Para isso, utilizaremos a biblioteca cowplot para fazer plots juntos, colocando-os lado a lado em colunas.
O p1, que seria o nosso primeiro plot, será configurado na função ggplot(). O primeiro parâmetro será a tabela dados. Em aes(), utilizaremos a coluna remuneracao para o eixo x.
Para o segundo gráfico, definido como p2, faremos outro ggplot(). Dessa vez, passaremos os dados como base e a coluna será horas_treinamento no eixo x.
library(cowplot)
p1 <- ggplot(dados, aes(x = remuneracao)) + geom_histogram() +
labs(y = "Frequência", x = "Remuneração", title = "Histograma da Remuneração") +
tema
p2 <- ggplot(dados, aes(x = horas_treinamento)) + geom_histogram() +
labs(y = "Frequência", x = "Horas de treinamento", title = "Histograma das Horas de treinamento em 2024") +
tema
plot_grid(p1, p2, labels = "AUTO")
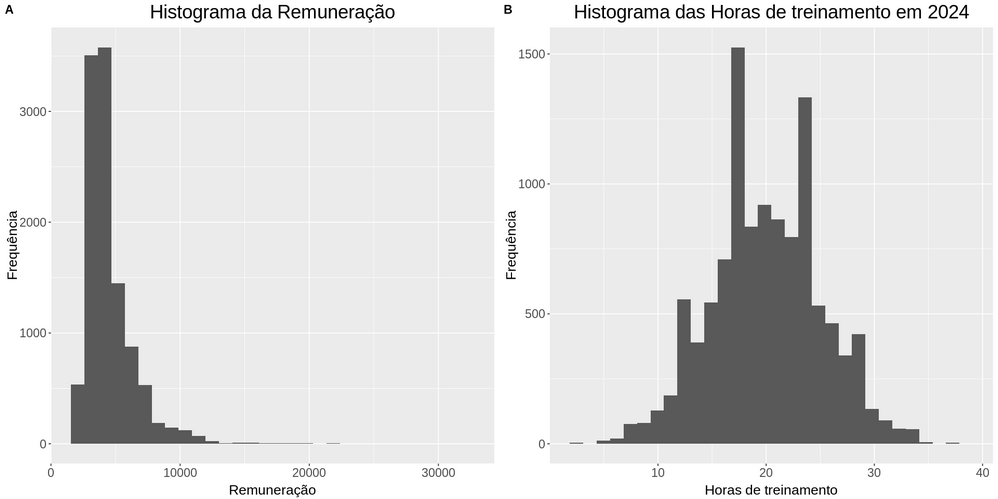
Assim, geramos dois gráficos. O gráfico da esquerda apresenta o histograma de remuneração. Sabemos que um gráfico de distribuição normal tem o formato de um sino, com uma curva que se distribui do topo ao longo da cauda.
No entanto, este primeiro gráfico parece achatado e deslocado para a esquerda. Isso é comum, pois altos salários podem puxar a média para cima, alongando a cauda direita. Provavelmente, essa distribuição não será simétrica, mas utilizaremos o teste de Shapiro-Wilk para confirmar.
O segundo gráfico tem uma aparência mais próxima de um sino, embora apresente alguns picos. Precisamos verificar se é ou não simétrica, e para isso, aplicaremos o teste de Shapiro-Wilk nas amostras dessas duas distribuições, para determinar se são distribuições normais. Teremos 95% de confiança nos resultados, devido a um erro de significância de 5%.
Aplicando teste de Shapiro-Wilk
Vamos realizar o teste em cada uma das variáveis. Primeiro, testaremos a remuneração, verificando o p-valor. Relembrando que rejeitaremos a hipótese nula (H₀) se o p-valor for menor ou igual a alpha.
Para isso, selecionaremos uma amostra dos nossos dados, utilizando sample_n() para obter 500 linhas aleatórias da tabela de dados. Para que você consiga reproduzir esse teste, configuramos um seed de 2025.
set.seed(2025)
amostra <- sample_n(dados, 500)
Em seguida, realizaremos o teste de Shapiro-Wilk na coluna remuneracao da amostra através da função shapiro.test().
resultado <- shapiro.test(amostra$remuneracao)
resultado
Saída: Shapiro-Wilk normality test
data: amostra$remuneracao
W = 0.81457, p-value < 2.2e-16
O resultado nos fornecerá a estatística de teste W e o p-valor, que é muito pequeno, próximo de zero.
Para salvar o p-valor, vamos pegar a variável resultado seguido de cifrão p.value.
p_valor <- resultado$p.value
p_valor
Saída: 1.45856887720388e-23
Note como o valor está elevado a vigésima terceira potência negativa, ou seja, muito próximo de zero.
Por fim, verificamos se p-valor é menor ou igual à significancia escolhida, que é o teste propriamente dito.
p_valor <= significancia
Saída: TRUE
Se o p_valor é menor que a significância, isso significa que precisamos rejeitar a hipótese nula. O teste de Shapiro-Wilk retornou um p-valor muito baixo, ou seja, menor do que 0.05 - o que indica que a distribuição da remuneração não é normal.
O histograma já mostrava uma distribuição assimétrica à direita, com uma cauda longa para valores altos de remuneração. Esse comportamento é comum em dados salariais.
Agora, realizaremos o teste para horas_treinamento, seguindo o mesmo processo. Na variável resultado, armazenaremos a solução de shapiro.test() da coluna amostra$horas_treinamento.
resultado <- shapiro.test(amostra$horas_treinamento)
resultado
Saída: Shapiro-Wilk normality test
data: amostra$horas_treinamento
W = 0.99428, p-value = 0.05759
O resultado do teste de Shapiro-Wilk mostra um p-valor de 0.0575, que é maior que 0.05. Vamos armazenar esse resultado$p.value na variável p_valor.
p_valor <- resultado$p.value
p_valor
Saída: 0.0575945898497616
Por fim, vamos executar o teste para conferir se p_valor é menor ou igual a significancia escolhida.
p_valor <= significancia
Saída: FALSE
O resultado é falso. Isso significa que não rejeitamos a hipótese nula, aceitando que as amostras de horas de treinamento vem de uma distribuição normal. O histograma também indicava uma distribuição mais simétrica, com a maioria dos colaboradores concentrados em um número médio de horas de treinamento.
Com base nesses resultados, chegamos em duas conclusões. Primeiro, para remuneração, métodos estatísticos que não assumem normalidade, como testes não paramétricos, podem ser mais adequados. Já para horas de treinamento, métodos paramétricos podem ser aplicados com maior confiança, pois a amostra faz parte de uma distribuição normal.
Próximos passos
O teste de normalidade foi apenas o primeiro de uma série de testes que aprenderemos. Ele é importante para adequar os dados para testes paramétricos.
Na sequência, aplicaremos o teste de hipótese para outros casos, explicando sobre o p-valor, hipótese nula e alternativa, estatísticas de teste e outros conceitos essenciais para a construção de um teste de hipóteses e interpretação de seus resultados. Até já!
Sobre o curso Estatística com R: aplicando testes de hipóteses
O curso Estatística com R: aplicando testes de hipóteses possui 216 minutos de vídeos, em um total de 60 atividades. Gostou? Conheça nossos outros cursos de Estatística em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Teste de normalidade e etapas de um teste de hipótese
- Testes paramétricos: bicaudal e unicaudal
- Testes paramétricos para duas ou mais amostras
- Testes não paramétricos para dados categóricos
- Teste não paramétricos para dados numéricos