Estatística com R: resumindo e analisando dados
Entendendo os dados - Apresentação
Você sabia que a estatística é uma habilidade extremamente importante para uma pessoa profissional na carreira de dados? Gostaria de utilizar seus conceitos para resolver problemas e projetos utilizando a linguagem R? É isso que vamos aprender neste curso sobre estatísticas com R.
Eu sou o Afonso Rios, instrutor da escola de Dados da Alura, e irei te acompanhar nesta jornada!
Audiodescrição: Afonso se descreve como um homem de pele morena, com cabelos lisos castanho-escuros e curtos, olhos castanho-escuros, e barba castanho-escura curta. Ele veste uma camisa azul, e está sentado em frente a uma parede clara iluminada em gradiente verde, com uma prateleira branca contendo decorações que remetem tanto a futebol quanto à Alura.
O que vamos aprender?
Neste curso, seremos cientistas de dados atuando em uma consultoria que presta serviços para empresas de várias áreas. O foco será usar conceitos da estatística para investigar dados e auxiliar nos problemas e demandas que uma rede de varejo enfrenta, baseando as decisões em análises.
Vamos compreender as diferenças entre os tipos de variáveis e como utilizá-las. Além disso, vamos explorar problemas para investigar qual análise faz mais sentido em cada contexto.
Também iremos diferenciar e comparar as relações entre as medidas de tendência central, aplicar as medidas separatrizes e de dispersão para resumir nossos dados, além de aprender a gerar insights e levantar hipóteses para resolver problemas.
Quais são os requisitos?
Para atingir esse resultado, precisaremos ter acesso aos dados provenientes dos setores de marketing, vendas, RH e financeiro da empresa.
Para quem é este curso?
Este curso é voltado para quem está começando, então vamos te acompanhar durante todas as aulas. Se você já conhece um pouco da linguagem R, melhor ainda, mas não é obrigatório.
Conclusão
Com as expectativas alinhadas, vamos colocar a mão na massa?
Entendendo os dados - Iniciando o projeto
Neste curso, vamos atuar como cientistas de dados em uma consultoria que presta serviços em diferentes áreas. Agora, vamos assistir uma rede de varejo que opera em todo o país, com o desafio de usar conceitos de estatística e análise de dados para pautar e resolver os cases, que vão ajudar tanto no processo de decisão quanto na geração de insights para as partes interessadas.
Iniciando o projeto
Ao longo desse processo, teremos acesso aos dados levantados por diversos times da empresa, sejam eles de marketing, vendas, RH ou financeiro. O problema que precisamos resolver é basicamente entender a abordagem adequada para cada caso, utilizando a estatística e a linguagem R como ferramentas. Precisamos identificar quais dados temos e para onde vamos com nossas análises.
Para analisar cada caso, utilizaremos um documento do Google Colab que vem com um passo a passo guiando todo o nosso aprendizado. Em resumo, o notebook é uma espécie de documento em que criamos tanto textos quanto códigos para executar e fazer a análise exploratória dos dados.
Observação: para utilizar o Google Colab, precisamos ter uma conta do Gmail.
Importando os pacotes
No Colab, temos um documento que traz inicialmente um resumo sobre o projeto e o processo que estamos passando na análise exploratória dos dados da empresa de varejo em que iremos trabalhar.
Começaremos com a primeira etapa, partindo do entendimento dos dados, onde importaremos os pacotes da linguagem R que serão utilizados e leremos os dados recebidos de marketing e de vendas inicialmente, que são os dados das vendas da empresa em determinado período.
Na primeira célula, temos duas bibliotecas:
tidyverseglue
O tidyverse é um pacote de pacotes da linguagem R que traz uma série de diferentes pacotes que trabalham com a parte de manipulação de dados até a visualização de dados.
Já o glue é utilizado para a formatação dos textos. O último trecho de código, options(repr.matrix.max.rows = 10), permite exibir os dados com no máximo 10 linhas, evitando que muitas linhas sejam executadas simultaneamente e apareçam na tela.
Vamos executar esse código para fazer as importações necessárias:
# Importando os pacotes do projeto
library(tidyverse)
library(glue)
options(repr.matrix.max.rows = 10)
Retorno da célula:
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Note que ele trouxe o pacote dplyr, muito importante para manipulação de dados e faz parte do pacote do tidyverse, e o ggplot2, que também faz parte do tidyverse.
Além desses dois pacotes principais que utilizaremos no projeto, ele também menciona conflitos de funções comuns entre as bibliotecas básicas e a biblioteca trazidas do
tidyverse, mas saberemos como tratá-las e utilizá-las no formato correto, evitando esses problemas.
Realizando a leitura dos dados
Com a importação concluída, vamos partir para a leitura da primeira base de dados, que é justamente para análise do perfil da clientela de acordo com as compras realizadas.
Para começar, vamos declarar em uma nova célula a variável dados, que receberá o DataFrame, isto é, uma estrutura de tabela com as variáveis em colunas. Em seguida, usamos o sinal <- para atribuir à variável dados a leitura de um arquivo CSV (read.csv()), com um caminho do GitHub.
Por fim, usamos glimpse(dados) para checar a estrutura dos dados.
dados <- read.csv("https://raw.githubusercontent.com/afonsosr2/estatistica-r-frequencias-medidas/refs/heads/main/dados/vendas_ecommerce.csv")
glimpse(dados)
Retorno da célula:
Rows: 200,000
Columns: 10
$ id_compra <chr> "9f86e969-221a-4b1a-9b48-9aba719b61cf", "659f9b07-be…
$ sexo_biologico <chr> "Masculino", "Feminino", "Feminino", "Feminino", "Ma…
$ idade_cliente <int> 33, 33, 36, 21, 31, 29, 44, 19, 24, 36, 32, 24, 41, …
$ regiao_cliente <chr> "Sul", "Nordeste", "Sudeste", "Sul", "Centro-Oeste",…
$ categoria_produto <chr> "Ferramentas e Construção", "Alimentos e Bebidas", "…
$ preco_unitario <dbl> 96.80, 247.68, 627.46, 2025.07, 99.24, 131.20, 909.8…
$ quantidade <int> 2, 1, 2, 8, 5, 1, 2, 3, 3, 7, 1, 2, 2, 6, 1, 5, 7, 5…
$ total_compra <dbl> 193.60, 247.68, 1254.92, 16200.56, 496.20, 131.20, 1…
$ tempo_entrega <int> 18, 6, 8, 6, 13, 13, 14, 11, 10, 14, 5, 10, 16, 8, 6…
$ avaliacao <int> 1, 4, 5, 5, 5, 5, 5, 4, 3, 3, 4, 4, 4, 5, 2, 5, 5, 3…
Ao executar, recebemos 200 mil linhas, ou seja, 200 mil registros de vendas, e 10 colunas. Temos dados como sexo biológico, idade, região do cliente, categoria dos produtos, preço, quantidade de vendas, total da compra, tempo de entrega e avaliação. São valores de caracteres (chr), inteiros (int), double (dbl), entre outros, compondo uma série de diferentes dados na base.
A partir disso, já conseguimos observar algumas colunas interessantes e ideias de análise que podemos ter. Por exemplo: podemos verificar as vendas por região, pelo sexo biológico, explorar os tipos de produtos ou o tempo de entrega, verificar se há alguma influência na avaliação, entre outras possibilidades. Muitas dessas análises serão abordadas ao longo deste curso.
Para todas essas análises fazerem sentido, devemos ter atenção em dois pontos importantes:
- Precisamos saber qual tipo de dado temos;
- E o que desejamos investigar com esse tipo de dado.
Nesse momento, a estatística se torna essencial, pois a depender do tipo de dado e de como ele se comporta, há diferentes formas de analisar o dado para responder à necessidade da clientela.
Tudo isso é focado no tripé conhecido da ciência de dados: a estatística, ou matemática; a programação, que seria a linguagem R; e o conhecimento do negócio, entender o que o dado traz.
Não basta apenas utilizar a programação; precisamos entender o que aquele determinado significa. Vamos aplicar tudo isso utilizando a ferramenta da linguagem R e os conceitos da estatística.
Conclusão
Agora que importamos os pacotes necessários e fizemos a primeira checagem dos dados, vamos investigar o que eles significam e entender quais demandas precisamos atender!
Entendendo os dados - Investigando os tipos dos dados
Observando rapidamente nossos dados, identificamos uma série de valores, sejam textuais, numéricos inteiros ou numéricos decimais. A depender da análise que queremos fazer, cada coluna ou variável possui uma forma específica de ser trabalhada e adequada para extrair informação a partir dos dados. A ideia é entender como identificar o tipo de variável e extrair informação disso.
Investigando os tipos dos dados
Realizando a leitura dos primeiros dados
Para isso, vamos acessar novamente o Colab e fazer a leitura dos primeiros dados:
head(dados, 5)
Utilizamos a função head() para realizar a leitura dos primeiros dados do DataFrame, passando entre parênteses dados e o número 5, pois queremos ler os cinco primeiros registros.
| # | id_compra | sexo_biologico | idade_cliente | regiao_cliente | categoria_produto | preco_unitario | quantidade | total_compra | tempo_entrega | avaliacao |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 9f86e969-221a-4b1a-9b48-9aba719b61cf | Masculino | 33 | Sul | Ferramentas e Construção | 96.80 | 2 | 193.60 | 18 | 1 |
| 2 | 659f9b07-be10-4849-b2ab-dd542498a1e8 | Feminino | 33 | Nordeste | Alimentos e Bebidas | 247.68 | 1 | 247.68 | 6 | 4 |
| 3 | d317d7df-1126-42e5-bf4b-0e178bd4e14e | Feminino | 36 | Sudeste | Eletrônicos | 627.46 | 2 | 1254.92 | 8 | 5 |
| 4 | bb99bcf6-b333-493e-9ec2-c39f8695503c | Feminino | 21 | Sul | Eletrônicos | 2025.07 | 8 | 16200.56 | 6 | 5 |
| 5 | 898e4624-84e9-4c41-b181-66d3b7ccfef7 | Masculino | 31 | Centro-Oeste | Papelaria e Escritório | 99.24 | 5 | 496.20 | 13 | 5 |
Observando o retorno, temos dados textuais, como o sexo biológico (sexo_biologico) e a categoria do produto (categoria_produto). Também temos dados numéricos, como a idade da pessoa cliente (idade_cliente) e o preço unitário (preco_unitario), seja ele um número inteiro ou um número decimal, e cada um desses terá um jeito diferente de ser trabalhado.
Portanto, temos dados categóricos, bem como dados numéricos.
Como diferenciar cada tipo de variável?
Como entender e diferenciar cada tipo de dado? Para explicar isso melhor, trouxemos um fluxograma que resume bem essa informação. Observe a imagem abaixo:
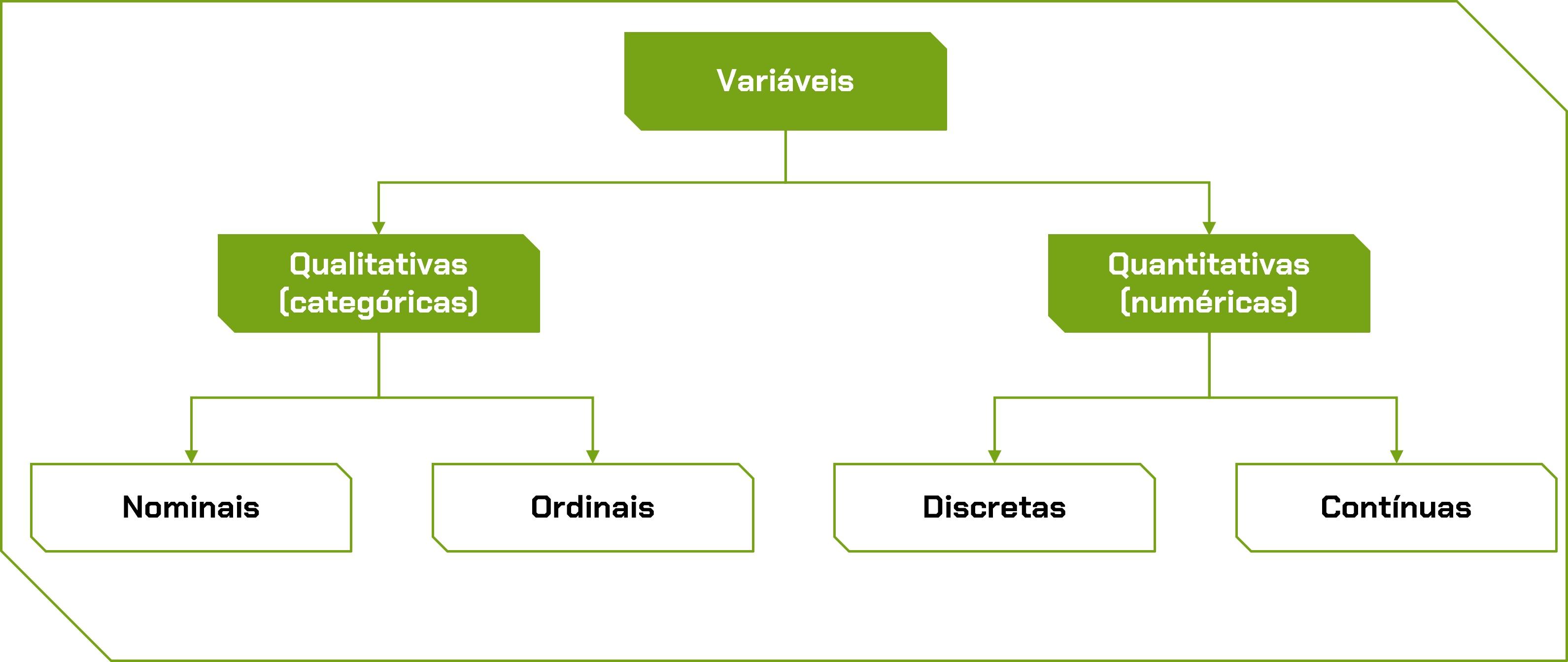
Note que as variáveis são divididas basicamente em duas categorias: a primeira é a qualitativa, que são os dados categóricos; e a segunda é a quantitativa, que são os dados numéricos.
As variáveis qualitativas possibilitam categorizar e classificar os dados, e podem ser do tipo nominal e ordinal. Variáveis qualitativas nominais não possuem uma ordem natural e podem ser, por exemplo, o tipo do produto ou a região, como sul, sudeste, e assim por diante.
Já as categóricas ordinais possuem uma ordem natural, ou uma hierarquia, como o nível de escolaridade (ensino fundamental, médio e superior) ou os meses do ano (janeiro, fevereiro, março). Nesse caso, há uma ordem natural das coisas e uma hierarquia a ser seguida.
Por outro lado, as variáveis quantitativas representam números, e podem ser realizados cálculos com eles, ou seja, eles têm um significado matemático. Esses números podem ser tanto contínuos quanto discretos. Os discretos são os números que podemos contar, valores inteiros, como a idade de uma pessoa e a quantidade de produtos vendidos.
Já os contínuos são números que estão em um intervalo, e eles podem ter muitos valores, por exemplo, a altura ou o peso de uma pessoa tem a possibilidade de ser contável, a depender da natureza e da precisão da medida. No entanto, diferente do número discreto, o número contínuo terá progresso em um intervalo muito maior de contato.
Analisando dados com o dplyr
Agora que entendemos a diferença entre cada variável, que tal colocar na prática analisando um dado? Nesse caso, vamos investigar uma variável categórica nominal: a categoria_produto.
Iremos analisá-la para visualizar, por exemplo, a quantidade de vendas, isto é, a quantidade de registros que temos dentro dessas categorias.
Abaixo, temos algumas documentações com os links das funções mais utilizadas em cada aula. Basta acessá-los para entender melhor o que cada uma representa.
Para fazer essa navegação e exploração do dado, vamos utilizar o dplyr, que faz parte do tidyverse e é utilizado para manipulação dos dados.
Nesse caso, é utilizado o conceito das funções verbais para realizar ações sobre os dados. Para usá-las, precisamos utilizar uma estrutura chamada pipe (%>%). A cada pipe, ou seja, a cada execução realizada, podemos fazer uma alteração, uma modificação ou uma ação sobre a base de dados.
Utilizando a função select()
Primeiramente, queremos coletar todos os dados da categoria categoria_produto. Para isso, chamaremos dados e adicionaremos o pipe (%>%). Em seguida, vamos usar a função select() para selecionar todos os valores de categoria_produto.
dados %>%
select(categoria_produto)
Como retorno, recebemos 200 mil registros:
categoria_produto |
|---|
| Ferramentas e Construção |
| Alimentos e Bebidas |
| Eletrônicos |
| Eletrônicos |
| Papelaria e Escritório |
| ⋮ |
| Eletrônicos |
| Eletrônicos |
| Roupas, Calçados e Acessórios |
| Alimentos e Bebidas |
| Beleza e Cuidados Pessoais |
Analisando essa tabela, percebemos que talvez essa informação não seja tão necessária para nós, pois apenas foram retornados todos os valores. Para trazer um significado mais interessante, que tal analisar quantas categorias temos? Quais são os valores únicos, isto é, os valores distintos?
Utilizando a função distinct()
Para isso, vamos chamar dados em uma nova célula, usar o pipe novamente, e usar a função distinct() para selecionar valores distintos de categoria_produto.
dados %>%
distinct(categoria_produto)
Retorno da célula:
categoria_produto |
|---|
| Ferramentas e Construção |
| Alimentos e Bebidas |
| Eletrônicos |
| Papelaria e Escritório |
| Beleza e Cuidados Pessoais |
| Casa e Mobílias |
| Roupas, Calçados e Acessórios |
| Livros |
| Brinquedos |
| Esporte e Lazer |
Agora, há 10 registros na tabela, ou seja, 10 categorias no projeto. Essa informação é mais interessante que a anterior, pois explicamos quantas categorias iremos trabalhar na base de dados.
Utilizando a função count()
Já sabemos quantas categorias temos, mas agora vamos descobrir a quantidade de vendas por categoria. Queremos contar quantas vezes tivemos o dado.
Em uma nova célula, vamos declarar uma variável chamada produtos, na qual vamos salvar a contagem que será feita. Passaremos para ela dados %>% e, na sequência, chamaremos a função count(), para contar os dados de categoria_produto.
Para ordenar pela quantidade representada, podemos adicionar o parâmetro sort=T na função count(). Dessa forma, ordenamos do maior para o menor.
produtos <- dados %>%
count(categoria_produto, sort=T)
produtos
Ao executar, recebemos a seguinte tabela:
categoria_produto | n |
|---|---|
| Eletrônicos | 36060 |
| Roupas, Calçados e Acessórios | 27917 |
| Casa e Mobílias | 26015 |
| Beleza e Cuidados Pessoais | 22026 |
| Esporte e Lazer | 19939 |
| Alimentos e Bebidas | 18022 |
| Papelaria e Escritório | 13936 |
| Livros | 13790 |
| Ferramentas e Construção | 12063 |
| Brinquedos | 10232 |
A partir disso, podemos concluir, por exemplo, que eletrônicos possuem 36 mil registros, enquanto brinquedos possuem 10 mil registros. Portanto, há mais registros de venda de eletrônicos do que brinquedos, uma informação importante.
Gerando uma visualização gráfica
Somente com a tabela, conseguimos ranquear os produtos com mais registros de venda. No entanto, seria interessante visualizar isso também de maneira gráfica, visual.
Usaremos o ggplot2 para fazer essa operação. Abaixo, trouxemos um código pré-pronto para você executar, em que trabalhamos com o ggplot() e a funcionalidade dele ocorre por meio de camadas.
ggplot(produtos) +
geom_col(aes(x = n, y = reorder(categoria_produto, n)))
Primeiro, queremos a camada em que passamos o dado. Depois, passamos o tipo de gráfico desejado. Por fim, as coordenadas que queremos desenhar.
Essas camadas podem ser representadas pelo sinal de mais (+) ou pelos próprios elementos nas variáveis. O ggplot() é a função inicial que chamamos para executar, onde inserimos a base de dados produtos que acabamos de construir.
Para geom_col(), passamos primeiro a coordenada x. Queremos criar um gráfico de barras para ter no eixo y os nomes, e no eixo x, o tamanho da barra. Dito isso, passamos o tamanho n para o eixo x, e categoria_produto para y.
Por fim, usamos a função reorder() para ordenar categoria_produto.
Retorno da célula:
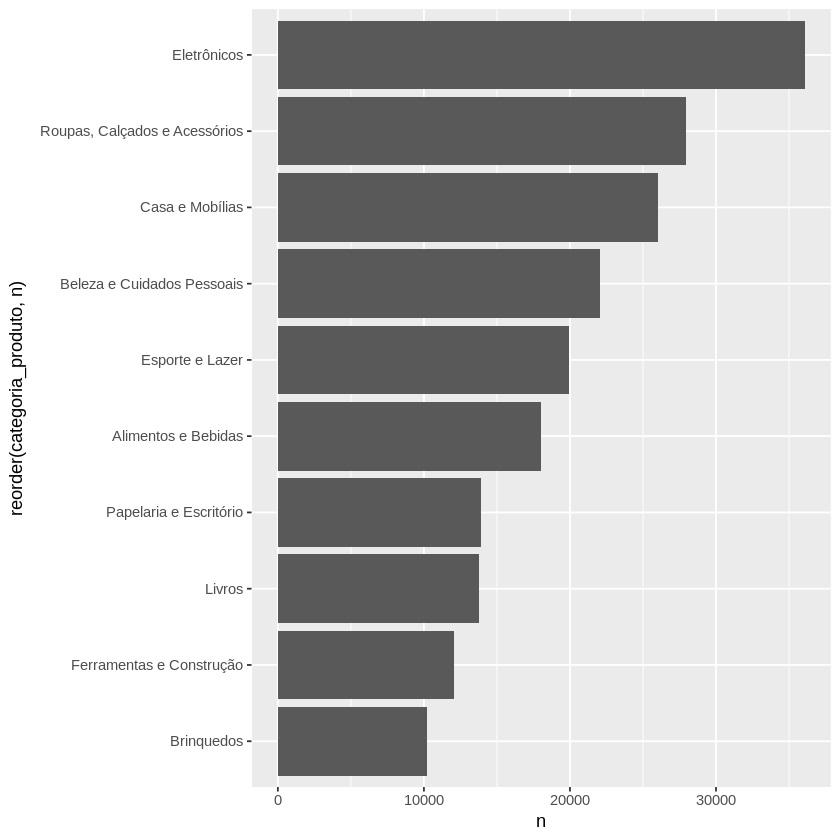
Agora, temos a mesma tabela, mas representada visualmente em um gráfico de barras, o que pode ser muito mais interessante em um relatório, por exemplo, trazendo também os valores.
Dessa forma, conseguimos apresentar uma análise ainda mais rica.
Conclusão
Pense no que fizemos utilizando apenas uma variável qualitativa nominal. Apenas com ela, conseguimos trazer a quantidade de vendas por tipo de categoria.
Até o momento, entendemos os tipos de variáveis e como funciona uma variável qualitativa nominal. Nosso próximo passo será ajustar a base utilizando uma variável qualitativa ordinal!
Sobre o curso Estatística com R: resumindo e analisando dados
O curso Estatística com R: resumindo e analisando dados possui 201 minutos de vídeos, em um total de 56 atividades. Gostou? Conheça nossos outros cursos de Estatística em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Entendendo os dados
- Identificando o perfil do público
- Analisando a tendência dos dados
- Investigando os dados dos colaboradores
- Analisando as variações dos dados