Olá! Eu sou o Bruno Raphaell, instrutor aqui na Alura, e vou te acompanhar neste curso de IA aumentada!
Audiodescrição: Bruno se descreve como um homem de cabelos cacheados pretos e curtos, pele negra, com a barba preta curta. Ele veste uma camisa preta, usa óculos com armação preta arredondada, e está sentado em uma cadeira preta em frente a uma parede branca iluminada em gradiente de verde, rosa e roxo, com uma estante de madeira com enfeites da Alura.
Você já teve algum voo atrasado ou perdeu alguma conexão devido a atraso? Esses atrasos costumam ocorrer por diversas razões, como condições climáticas, a necessidade de um avião se deslocar de um local para outro, ou imprevistos no momento do embarque dos passageiros que dificultam o embarque na hora prevista.
Os atrasos podem gerar custos tanto para as empresas quanto para os passageiros.
Diante desses cenários, fazemos parte de uma equipe de cientistas de dados que foi contratada por um aeroporto para realizar a otimização aeroportuária. Nosso objetivo é definir onde cada avião irá estacionar e, assim, construir planos de estacionamento mais adequados, rápidos e otimizados.
Para isso, sugerimos a criação de um modelo preditivo capaz de prever os atrasos nos voos e, assim, ajustar o plano de estacionamento com agilidade. Com essa solução, esperamos reduzir o tempo de espera dos passageiros e otimizar as operações do aeroporto.
Nossa primeira missão, portanto, consiste em desenvolver um modelo de machine learning, mais especificamente, um modelo de regressão. Este modelo será capaz de prever os atrasos nos voos com base em suas características. Essas previsões serão importantes, porque os outros processos de otimização utilizarão essa informação como entrada.
Para desenvolver esse modelo de machine learning, dispomos de um conjunto de dados com informações relevantes sobre cada voo. Porém, é importante ressaltar um detalhe: neste curso, não construiremos os planos de estacionamento otimizados. Vamos dar nosso primeiro passo, que é justamente construir o modelo de regressão.
Para aproveitar ao máximo esse projeto, é importante que você tenha conhecimento na linguagem de programação Python e conheça as bibliotecas Pandas, NumPy e Seaborn.
Vamos desenvolver esse projeto juntos?
Podemos solucionar, ou mesmo otimizar, essa etapa de atraso de voos conhecendo-os. Sendo assim, podemos construir um modelo de machine learning que seja capaz de prever esse atraso no voo, e a saída desse modelo de machine learning poderá ser utilizada como entrada para outros processos de otimização para melhorar ainda mais a operação desse aeroporto.
Como vamos inserir esses dados em um modelo de machine learning e ele precisa de dados, é ideal conhecermos esses dados. Então, nesta aula, vamos justamente conhecer os dados com os quais trabalhamos!
Começaremos no Google Colab. A primeira coisa que vamos fazer será renomear o notebook como modelo-atraso-voo.ipynb para identificá-lo melhor. Em seguida, vamos importar os dados.
Clicaremos no quarto ícone na aba mais à esquerda e depois em "Fazer upload para o armazenamento da sessão", correspondente ao primeiro ícone na aba "Arquivos". Vamos procurar o conjunto de dados flights, conjunto de dados de voo.
Após clicar em "Abrir", surgirá um aviso de que ele vai ser salvo em outro lugar. Podemos clicar em "OK". Feito isso, aguardamos os dados serem carregados para o ambiente do Google Colab.
Uma vez carregado o conjunto de dados, precisamos ler esses dados. Para isso, é necessária uma biblioteca muito interessante e muito utilizada em Data Science: a Pandas. Como fazemos essa leitura?
Primeiro, devemos importar a biblioteca com o seguinte comando:
import pandas as pd
Após importar a biblioteca, vamos executar a célula com "Shift + Enter" para criar outra célula abaixo. Agora temos que ler os dados. Esses dados estão em um formato chamado CSV. Como ler um CSV no Pandas?
Para isso, utilizamos o comando pd.read_csv(), para o qual passamos o caminho do arquivo. O arquivo está solto na pasta, então vamos simplesmente copiar o nome do arquivo e colar entre aspas simples e entre parênteses.
pd.read_csv('flights.csv')
Vamos verificar se assim funciona. Ao executar, é retornada a seguinte tabela:
| # | flight_id | airline | aircraft_type | schengen | origin | arrival_time | departure_time | day | year | is_holiday | delay |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 26 | MM | Airbus A320 | non-schengen | TCY | 8.885071 | 10.885071 | 0 | 2010 | False | 70.205981 |
| 1 | 10 | YE | Airbus A320 | non-schengen | TCY | 8.939996 | 11.939996 | 0 | 2010 | False | 38.484609 |
| 2 | 3 | BZ | Embraer E175 | schengen | TZF | 18.635384 | 22.635384 | 0 | 2010 | False | 2.388305 |
| 3 | 28 | BZ | Airbus A330 | non-schengen | EMM | 15.967963 | 17.967963 | 0 | 2010 | False | 19.138491 |
| 4 | 15 | BZ | Airbus A330 | non-schengen | FJB | 16.571894 | 19.571894 | 0 | 2010 | False | 15.016271 |
Nosso conjunto de dados está lido e trazido para o Google Colab.
Agora vamos atribuir o que escrevemos na célula anterior a uma variável específica chamada dados. Para conferir que deu certo, vamos visualizar as 5 primeiras linhas usando o comando head().
dados = pd.read_csv('flights.csv')
dados.head()
Vamos executar novamente com "Shift + Enter". Teremos o mesmo conjunto de dados apresentado acima, e já percebemos que conseguimos tirar algumas informações. Temos uma coluna chamada flight_id (identificador do voo); a airline (companhia aérea); o tipo da aeronave, que é aircraft_type; schengen, que indica se o voo é do espaço Schengen ou não.
O termo "Schengen" está relacionado com o Acordo de Schengen, um acordo europeu que tem implicações em termos de logística aeroportuária, mas não está diretamente relacionado com as operações aeroportuárias em si.
O aeroporto de origem (origin) está em siglas. Por exemplo: o aeroporto de Congonhas recebe a sigla CGH. Temos o arrival_time (hora de chegada), departure_time (hora de saída), o dia (day), e o ano que é correspondente a esse dia (year). Por exemplo: temos o dia 0 em 2010, então é 1º de janeiro de 2010.
Por fim, temos a coluna is_holiday, se é um feriado ou não, e a coluna delay, o atraso em minutos.
Importante notar que a hora em arrival_time está em formato decimal. Por exemplo: como seria 8.88 em horas? Poderíamos fazer um cálculo simples. Seria 0.88 multiplicado por 60 para saber a quantidade em minutos. Teríamos, basicamente, 8 horas e 52 minutos.
O mesmo processo se repete para departure_time. Multiplicamos os números após a vírgula por 60 para saber a quantidade de minutos. Teremos, assim, o tempo tanto em horas quanto em minutos.
Já conseguimos visualizar as linhas e sabemos o que é cada uma das colunas. O que podemos fazer agora é visualizar as últimas linhas. Verificar, por exemplo, quantas amostras temos no nosso conjunto de dados. Para isso, podemos usar o comando dados.tail(). Assim, visualizamos as últimas 5 amostras.
dados.tail()
| # | flight_id | airline | aircraft_type | schengen | origin | arrival_time | departure_time | day | year | is_holiday | delay |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 71170 | 3 | BZ | Embraer E175 | schengen | TZF | 18.635384 | 22.635384 | 364 | 2022 | True | 25.677277 |
| 71171 | 17 | BZ | Airbus A330 | non-schengen | CNU | 16.718722 | 21.718722 | 364 | 2022 | True | 52.624348 |
| 71172 | 7 | MM | Boeing 787 | schengen | TZF | 8.564949 | 13.564949 | 364 | 2022 | True | 56.167080 |
| 71173 | 5 | BZ | Airbus A320 | schengen | ZQO | 9.344097 | 12.344097 | 364 | 2022 | True | 56.758844 |
| 71174 | 29 | BZ | Boeing 737 | schengen | ZQO | 8.591208 | 11.591208 | 364 | 2022 | True | 41.401648 |
Percebemos que vai até a linha 71.174. Como começa em 0, consequentemente, temos 71.175 amostras no nosso conjunto de dados. Outra coisa que podemos fazer é visualizar a quantidade de colunas.
Para evitar contar manualmente, utilizamos o método shape, então digitamos dados.shape em uma nova célula.
dados.shape
Retorno da célula:
(71175, 11)
Como retorno, temos exatamente o que acabamos de executar: 71.175 linhas e 11 colunas ao todo. Já conseguimos ter essas duas informações, mas não conseguimos ter informações e estatísticas mais descritivas. Por exemplo: qual o valor médio das colunas numéricas? Qual o valor máximo? Qual a mediana? Não temos essas informações só com o que executamos.
Para obter essas informações, vamos executar o método describe(), ou seja, dados.describe() em uma nova célula.
dados.describe()
Executando com "Shift + Enter", inicialmente, serão dadas somente informações das colunas numéricas:
| # | flight_id | arrival_time | departure_time | day | year | delay |
|---|---|---|---|---|---|---|
| count | 71175.000000 | 71175.000000 | 71175.000000 | 71175.000000 | 71175.000000 | 71175.000000 |
| mean | 15.465135 | 13.283159 | 16.480222 | 182.000000 | 2016.000000 | 12.548378 |
| std | 8.649646 | 4.023380 | 4.143705 | 105.366769 | 3.741684 | 23.125349 |
| min | 1.000000 | 7.065594 | 10.065594 | 0.000000 | 2010.000000 | -41.028033 |
| 25% | 8.000000 | 8.939996 | 12.668655 | 91.000000 | 2013.000000 | -4.412876 |
| 50% | 15.000000 | 14.258911 | 16.376052 | 182.000000 | 2016.000000 | 9.740454 |
| 75% | 23.000000 | 16.909690 | 20.041281 | 273.000000 | 2019.000000 | 27.650853 |
| max | 30.000000 | 19.341235 | 23.341235 | 364.000000 | 2022.000000 | 125.632352 |
Percebemos que não há 11 colunas, justamente porque estão retiradas as colunas categóricas. Temos flight_id, arrival_time, departure_time, day, year e delay. Não faz tanto sentido analisar a coluna flight_id, pois é um identificador. Então, vamos partir para o arrival_time.
Em arrival_time, temos: a média (mean); o desvio padrão (std); o valor mínimo (min); o primeiro quartil (25%); a mediana (50%), que é o valor que está no meio do conjunto de dados, nesse caso, 14.25; o terceiro quartil (75%), que é 16.9; e o valor máximo (max) que temos de arrival_time, ou seja, o maior valor que um avião chegou nesse aeroporto foi às 19 horas e 34 minutos. Multiplicamos por 60 para saber a quantidade exata de minutos.
Em compensação, o valor máximo do departure_time, isto é, a hora de saída, é 23.34. Multiplicamos novamente por 60 para saber a quantidade exata de minutos. Temos o valor médio 16 para o departure_time e o valor médio 13 para o arrival_time, por exemplo, e temos essas mesmas estatísticas para as outras colunas.
delayComo nossa variável alvo, isto é, o problema de negócio com os dados que tentamos resolver é relacionado ao atraso, precisamos analisar a coluna delay. A média do atraso é 12 minutos, o desvio padrão é 23, o valor mínimo é -41, ou seja, houve voos que adiantaram, e o valor máximo é de 125 minutos, ou seja, houve aviões que atrasaram até 2 horas e 5 minutos, o que é bastante tempo. Como fazer para visualizar estatísticas descritivas para variáveis categóricas?
Podemos executar o mesmo método. Vamos copiar dados.describe(), colar em uma nova célula abaixo, e adicionar o parâmetro include que será igual a 'O'.
dados.describe(include='O')
Serão dadas as quatro colunas que são categóricas:
| # | airline | aircraft_type | schengen | origin |
|---|---|---|---|---|
| count | 71175 | 71175 | 71175 | 71175 |
| unique | 3 | 6 | 2 | 10 |
| top | BZ | Airbus A320 | schengen | TZF |
| freq | 47598 | 30778 | 42569 | 14162 |
Primeiramente, temos a coluna airline, que é a companhia aérea. São três companhias aéreas diferentes, e a que mais aparece (top) é a BZ, com a frequência (freq) de 47598. Podemos replicar essas análises para as outras três colunas. Assim, conseguimos ter uma análise mais descritiva de nossas colunas categóricas.
Já conseguimos extrair bastante informação com os métodos que executamos, mas há outro método que fornece informações bastante relevantes: o método info(). Vamos executar em uma nova célula dados.info().
dados.info()
Executando esse método, temos a seguinte saída:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 71175 entries, 0 to 71174
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 flight_id 71175 non-null int64
1 airline 71175 non-null object
2 aircraft_type 71175 non-null object
3 schengen 71175 non-null object
4 origin 71175 non-null object
5 arrival_time 71175 non-null float64
6 departure_time 71175 non-null float64
7 day 71175 non-null int64
8 year 71175 non-null int64
9 is_holiday 71175 non-null bool
10 delay 71175 non-null float64
dtypes: bool(1), float64(3), int64(3), object(4)
memory usage: 5.5+ MB
Temos o RangeIndex, que indica a quantidade de linhas do conjunto de dados, que varia de 0 a 71.174; bem como o número de colunas, totalizando 11. Nesse caso, temos duas informações muito relevantes: as colunas Non-Null Count, que é a quantidade de valores não nulos, e Dtype, que é o tipo da coluna.
Percebemos que todas as colunas têm 71.175 valores não nulos. Isso indica que não há dados nulos no nosso conjunto de dados, o que significa que não precisamos nos preocupar com esse tipo de tratamento.
Outra coisa que percebemos é o tipo dos dados. Todos os tipos estão correspondentes com as informações, então também não precisamos nos preocupar com a conversão do tipo da coluna para a tipagem correta, pois já estão na tipagem correta.
Conseguimos tirar essas duas informações que são muito relevantes. Porém, construímos uma análise estatística basicamente com números. Para visualizar as informações de forma mais abrangente, o ideal construir gráficos!
Construímos nossas análises estatísticas dos dados, mas para termos uma análise ainda mais abrangente, o ideal é construir análises gráficas. É isso que vamos fazer neste vídeo!
Começaremos no ambiente de desenvolvimento do Google Colab, a partir do momento que deixamos no vídeo passado. Deixamos uma célula de markdown pré-pronta, com o título "Visualizações gráficas dos dados", para deixar nosso notebook mais organizado, e também preparamos uma célula de código para digitarmos.
Como vamos trabalhar com gráficos, o ideal é trazer bibliotecas que trabalhem com gráficos em Python. Vamos trabalhar com duas: Matplotlib e Seaborn. Então, vamos importá-las para o nosso ambiente. Para isso, fazemos import matplotlib.pyplot as plt, que é o apelido dessa biblioteca na comunidade, e import seaborn as sns, que também é o apelido da biblioteca. Vamos executar a célula com ""Shift + Enter"".
import matplotlib.pyplot as plt
import seaborn as sns
Agora as bibliotecas estão no nosso ambiente de desenvolvimento. Na próxima célula, vamos colar um código pré-pronto. O ideal é que você pause o vídeo, copie o código para o seu notebook, e depois retorne para explicarmos linha a linha.
average_delay = dados.groupby('airline')['delay'].mean().reset_index()
sns.barplot(x='airline', y='delay', data=average_delay)
plt.title('Companhias aéreas vs atrasos médios')
plt.xlabel('Companhias aéreas')
plt.ylabel('Atraso médio em minutos')
plt.show()
sns.countplot(data=dados, x='airline')
plt.title('Número de voos por companhia aérea')
plt.xlabel('Companhia aérea')
plt.ylabel('Número de voos')
plt.show()
Na primeira linha, onde temos average_delay, nós agrupamos pela companhia aérea, porque queremos construir um gráfico de atrasos médios por companhia aérea. Como queremos saber a média do atraso, usamos ['delay'].mean().
Para ficar mais evidente o que fizemos, vamos criar uma nova célula acima, colar a primeira linha do código e imprimi-la digitando average_delay na segunda linha da célula.
average_delay = dados.groupby('airline')['delay'].mean().reset_index()
average_delay
Ao executar essa célula com ""Shift + Enter"", percebemos que é retornado um DataFrame.
| # | airline | delay |
|---|---|---|
| 0 | BZ | 3.077595 |
| 1 | MM | 40.498007 |
| 2 | YE | 25.772248 |
Qual a necessidade do reset_index()? Se não o colocássemos, seria retornada uma series, e queremos trabalhar com esse conjunto de dados como um DataFrame. Por isso, usamos o .reset_index(). Assim, temos um DataFrame e conseguimos trabalhar de forma mais fácil, referenciando as colunas airline e delay.
Podemos excluir a nova célula criada e retornar para a anterior.
Na linha seguinte, temos o método sns.barplot(), onde no eixo x adicionamos airline, no eixo y, delay, e em data, adicionamos o DataFrame average_delay que mostramos anteriormente.
Em seguida, adicionamos o título "Companhias aéreas vs atrasos médios", nomeando o eixo x como "Companhias aéreas" e o eixo y como "Atraso médios em minutos". Na última linha do primeiro gráfico, imprimimos com plt.show().
Outro gráfico que queremos construir é o número de voos por companhia aérea. Para isso, usamos o comando sns.countplot(), que vai fazer uma contagem dos valores da coluna airline, com os dados que trabalhamos, que é o DataFrame airline que importamos. O título é "Número de voos por companhia aérea", com o eixo x sendo "Companhia aérea" e o eixo y "Número de voos".
Ao executar a célula com ""Shift + Enter"", obtemos os seguintes gráficos:
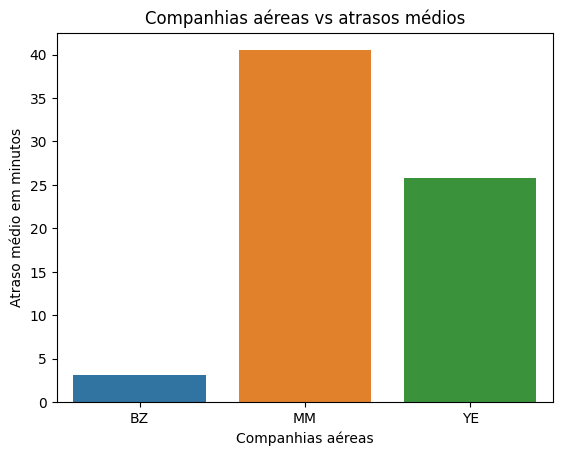
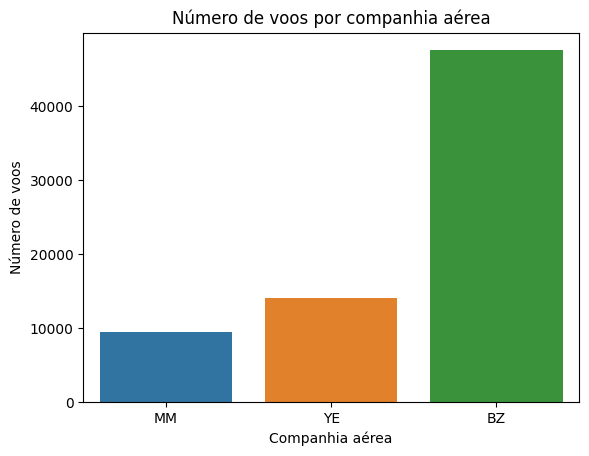
No primeiro gráfico, percebemos que a companhia aérea com mais atraso médio é a MM, seguida por YE e por último a BZ. Já no segundo gráfico, mesmo a BZ tendo o menor atraso, é a companhia aérea que mais tem voos, com mais de 40.000 voos, seguida por YE e por último MM. Ou seja, a MM é a que tem menos voos e atrasa mais.
Agora, vamos construir um gráfico do tipo de voo, ou seja, se é Schengen ou não. Vamos copiar o código da célula anterior, mas em vez de agrupar por airline, agruparemos por schengen, e ajustaremos os títulos e eixos conforme o contexto.
Para começar, vamos selecionar airline dentro de groupby() e usar o atalho "Ctrl + Shift + L" para selecionar todas as ocorrências de airline na célula e substituir por schengen. Assim, fizemos a alteração necessária tanto em barplot() quanto em countplot().
Quanto aos títulos, no lugar de "Companhias aéreas vs atrasos médios" teremos "Tipo do voo vs atrasos médios", com "Tipo do voo" no eixo x e "Atraso médio em minutos" no eixo y. Da mesma forma, no lugar de "Número de voos por companhia aérea" teremos "Número de voos por tipo do voo", com "Tipo do voo" no eixo x e "Número de voos" no eixo y.
average_delay = dados.groupby('schengen')['delay'].mean().reset_index()
sns.barplot(x='schengen', y='delay', data=average_delay)
plt.title('Tipo do voo vs atrasos médios')
plt.xlabel('Tipo do voo')
plt.ylabel('Atraso médio em minutos')
plt.show()
sns.countplot(data=dados, x='schengen')
plt.title('Número de voos por tipo do voo')
plt.xlabel('Tipo do voo')
plt.ylabel('Número de voos')
plt.show()
Executando a célula com "Shift + Enter", temos os gráficos abaixo:
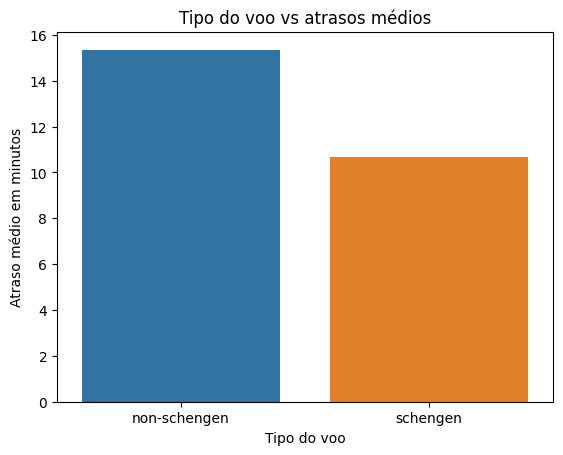
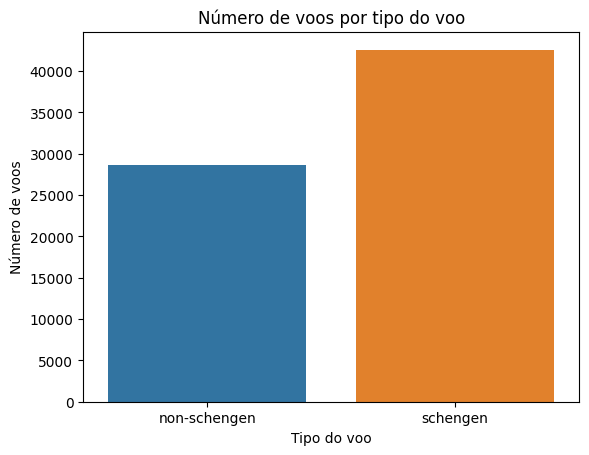
No primeiro gráfico, percebemos que os voos fora do espaço Schengen tendem a atrasar mais, em média 15 minutos, enquanto os que são do espaço Schengen atrasam em média 10 minutos.
Entretanto, mesmo o tipo do voo sendo non-schengen, eles aparecem em menos quantidade no conjunto de dados, e ainda assim são os que atrasam mais. Enquanto isso, os voos do tipo schengen aparecem em muita quantidade; em compensação, atrasam menos.
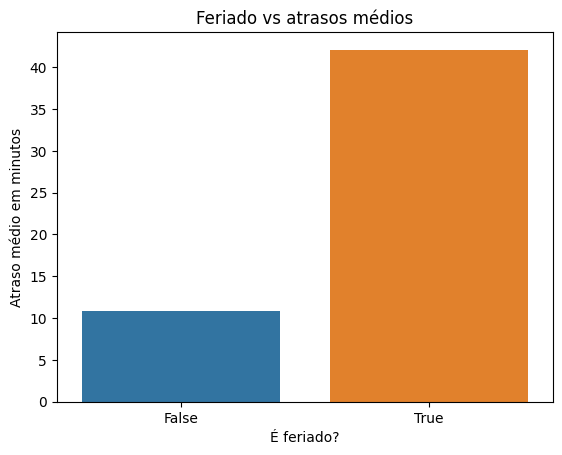
A seguir, vamos analisar se os atrasos em feriados são maiores ou menores do que em dias não feriados. Para isso, criaremos uma nova célula e ajustaremos o código anterior para a coluna is_holiday, alterando títulos e eixos para refletir a análise de feriado versus atraso médio.
average_delay = dados.groupby('is_holiday')['delay'].mean().reset_index()
sns.barplot(x='is_holiday', y='delay', data=average_delay)
plt.title('Feriado vs atrasos médios')
plt.xlabel('É feriado?')
plt.ylabel('Atraso médio em minutos')
plt.show()
Ao executar a célula com "Shift + Enter", observamos que, durante os feriados, os voos tendem a atrasar mais.
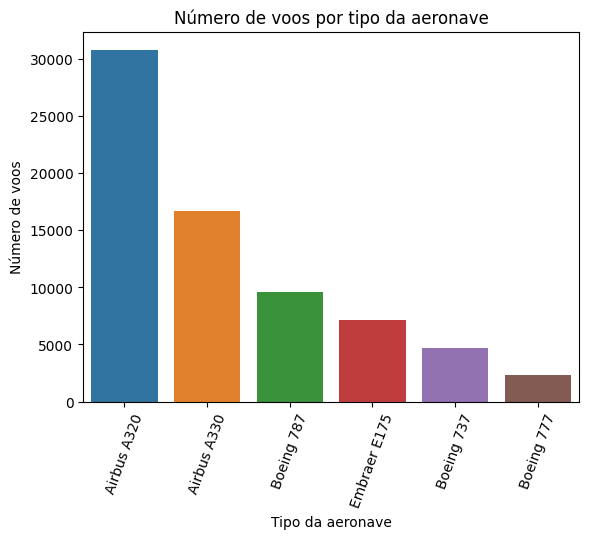
Outra análise que podemos é sobre o tipo de aeronave. Pegamos o segundo gráfico que construímos, um countplot(), e adicionamos em uma nova célula. Queremos saber a contagem de amostras por tipo de aeronave. Alteramos o eixo x para aircraft_type e ajustamos os títulos e eixos. Para organizar o gráfico, adicionamos uma ordenação decrescente e rotacionamos os nomes das aeronaves em 70 graus com plt.xticks(rotation=70).
order = dados['aircraft_type'].value_counts().index
sns.countplot(data=dados, x='aircraft_type', order = order)
plt.title('Número de voos por tipo da aeronave')
plt.xticks(rotation=70)
plt.xlabel('Tipo da aeronave')
plt.ylabel('Número de voos')
plt.show()
Ao final, conseguimos construir gráficos descritivos das nossas informações e extrair informações relevantes do nosso conjunto de dados. Resta visualizar a distribuição das variáveis, incluindo a variável alvo, para analisarmos como essa variável se comporta!
O curso IA aumentada: prevendo atrasos de voos possui 128 minutos de vídeos, em um total de 43 atividades. Gostou? Conheça nossos outros cursos de Data Science em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






