Kotlin e Spring: segurança e infraestrutura
Falando sobre DevOps - Apresentação
Olá, tudo bem? Me chamo João Victor e serei o instrutor no curso de Infraestrutura e Segurança com Kotlin.
Audiodescrição: João Victor é uma pessoa de pele clara, olhos castanhos e cabelos pretos curtos. Usa bigode e cavanhaque. Veste um moletom branco e está sentado em uma cadeira preta. Ao fundo, uma parede branca com uma janela à direita.
O que vamos aprender?
Neste curso, teremos a oportunidade de aprender sobre como utilizar o Spring Security com Kotlin.
Spring Security é um framework do Spring voltada para a segurança que fornece diversas ferramentas para facilitar o trabalho com autenticação e autorização.
Assim, em vez de desenvolvermos algo manualmente, o Spring Security já entrega isso de uma forma muito mais tranquila e fácil de desenvolver. Uma vez que entendamos o funcionamento do Spring Security, poderemos trabalhar com JWT.
JWT é o JSON Web Token, que é um padrão da indústria.
Portanto, no contexto atual, ao abordarmos os conceitos de autenticação e autorização por meio de um token, estamos, na maioria das vezes, nos referindo ao JWT. Vamos explorar o funcionamento de um token para autenticar e autorizar pessoas usuárias a acessarem nossa aplicação.
Caso esse tema seja novo para você, teremos a oportunidade de compreender e criar nossos próprios tokens ao longo do curso. Quando alcançarmos uma compreensão completa da implementação de segurança, assim como do conhecimento relacionado à autenticação e autorização em nossa aplicação, tanto com quanto sem o uso de tokens, chegaremos ao ponto de criar as imagens da aplicação para executá-las em um container.
Para isso, utilizaremos o Docker em nosso curso.
Docker é a ferramenta de criação e execução de container mais conhecida atualmente no mercado.
Com o container, teremos uma grande facilidade em fazer o deploy da nossa aplicação nos diversos ambientes que podemos ter na nossa empresa. Seja um ambiente de TI, de teste integrado, de homologação ou até um ambiente de produção, veremos que com o container, nossa aplicação fica muito mais fácil de transitar em cada um desses ambientes.
Uma vez que tenhamos essa imagem do container e a possibilidade de deploy da aplicação em um ambiente produtivo, chegaremos ao heroku, que é um provedor de cloud 100% gratuito, até um certo limite. Conseguiremos subir nosso container no heroku e fazer o acesso à nossa aplicação diretamente em produção.
Conclusão
Assim, caso tenha despertado seu interesse este curso e você esteja convencido de que ele trará benefícios para sua carreira, convidamos você a se juntar a nós para explorar as inovações no âmbito da infraestrutura e no deploy de nossa aplicação. Aguardo por sua participação no próximo vídeo.
Obrigado e até mais!
Falando sobre DevOps - Um pouco de DevOps
Olá, estudante! Continuaremos com o nosso curso, focado na infraestrutura de nossa aplicação. Ao abordarmos o tema infraestrutura, pode parecer que estamos direcionados a um público ligado à operação e à infraestrutura, e não especificamente para pessoas desenvolvedoras.
No entanto, essa perspectiva não é mais verdadeira. Neste curso, abordaremos a infraestrutura considerando elementos como containers, ferramentas de build e a implementação (deploy) de nossa aplicação.
Atualmente, essas preocupações estão intimamente ligadas às equipes que trabalham no desenvolvimento de software e nas operações e infraestrutura. Para esclarecer esse ponto, é importante compreender que este curso é destinado tanto a profissionais de desenvolvimento quanto a profissionais de infraestrutura e operações.
É essencial refletir sobre a maneira como tradicionalmente encaramos o processo de entrega de nossas aplicações em ambientes de teste, homologação e produção.
O instrutor está usando o site draw.io para ilustrar em um sistema o que está sendo explicado.
Geralmente, designamos uma pessoa desenvolvedora para criar o código e entregar um sistema para uma pessoa profissional encarregada da equipe de infraestrutura. Dessa forma, temos nosso entregável, que é o software desenvolvido.
Para representar isso em um sistema, no canto inferior esquerdo, na seção "General", clicamos no ícone de uma pessoa representada por um ator (chamado de "actor" em inglês).
Em seguida, arrastamos esse ícone para a área mais à direita. Posteriormente, selecionamos a seta e a movemos para o lado direito do ator, apontando para a direita. A seguir, clicamos no ícone de retângulo e o arrastamos para além da ponta da seta. Dentro do retângulo, realizamos um duplo clique e digitamos "Entregável".
Por enquanto, temos o seguinte sistema:
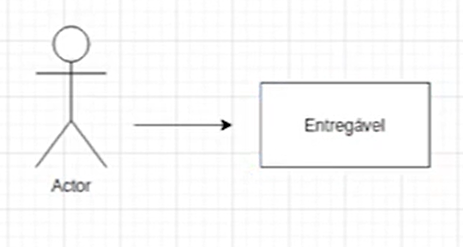
Temos então a figura da pessoa profissional de infraestrutura, encarregada de realizar o deploy da nossa aplicação nos servidores. Para representar isso, clicamos novamente em um ator do lado esquerdo e o posicionamos após o "Entregável".
Logo após, do lado esquerdo selecionamos "Text", posicionamos abaixo do primeiro ator que inserimos e digitamos "Dev". Clicamos novamente em "Text", posicionamos abaixo do segundo ator e digitamos "Infra".
Dessa forma, a representação que temos até o momento consiste em um ator, simbolizando a pessoa desenvolvedora, com uma seta apontando para a direita em direção ao "entregável". À direita desse entregável, há outro ator que representa a pessoa responsável pela infraestrutura.
A pessoa profissional de infraestrutura é capaz de implementar o sistema (entregável) no ambiente de teste, onde analistas de sistemas ou de produto podem testar a aplicação.
Além disso, essa pessoa realiza o deploy da aplicação, tanto para o ambiente de homologação (onde uma equipe dedicada a testes utiliza a documentação fornecida pela equipe de desenvolvimento para avaliar as regras de negócio e verificar a consistência entre o que está documentado e o que está no sistema) quanto para o ambiente de produção.
Para representarmos isso, inserimos três retângulos posicionados verticalmente à direita do ator que está representando a pessoa responsável pela infraestrutura. Logo após, digitamos "Teste", "Homologação" e "Produção", respectivamente, dentro de cada retângulo. Também inserimos três setas, cada uma saindo do ator "Infra" e apontando para cada retângulos à direita.
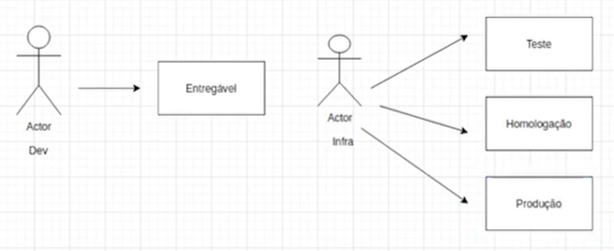
Seguimos um modelo tradicional de deploy, no qual as equipes de pessoas desenvolvedoras (responsáveis pela criação do entregável) e de infraestrutura (encarregadas pelo deploy da aplicação) operam de forma independente.
Aparentemente, essa abordagem parece totalmente adequada. Cada equipe trabalha em sua área específica, não há mistura entre as equipes. A equipe de homologação também homologa o projeto e, se tudo correr bem, a produção é iniciada. Mas, qual é o problema que começou a surgir com essa abordagem?
Como pessoa desenvolvedora, ao criar a aplicação, realizo testes em minha máquina local utilizando seus recursos, incluindo um banco de dados local com uma pequena quantidade de dados. Após concluir os testes locais e verificar que o sistema está funcionando corretamente, faço a entrega para a equipe de infraestrutura. Esse processo é, então, distribuído entre os diversos ambientes.
Entretanto, surge um problema: a equipe de homologação possui um banco de dados que ocasionalmente contém uma quantidade maior de dados do que o meu banco de dados local, sendo essa uma situação bastante comum. Além disso, podem ocorrer diferenças nas configurações. Se, por exemplo, o que foi entregue funcionou corretamente em minha máquina e na máquina de teste, mas apresentou falhas na fase de homologação, surgem então situações confusas.
A equipe de pessoas desenvolvedoras é confrontada com o erro e responde utilizando o clássico argumento: "Na minha máquina, funcionou, então não é minha responsabilidade". Começa então uma série de complicações devido às disparidades nos ambientes. O banco de dados de homologação difere do banco de dados de teste, que, por sua vez, difere do banco de dados local.
Essa situação começou a gerar consideráveis desafios nas entregas, resultando em atrasos significativos. A equipe de homologação recusava homologar até que o desenvolvimento resolvesse o problema, enquanto este alegava que a responsabilidade não era sua, mas sim da equipe de homologação.
No final, ninguém assumia a culpa, embora o cerne do problema fosse relacionado às configurações. O maior impacto dessa confusão entre as equipes residia no prejuízo causado pelos atrasos nas entregas.
Diante desse cenário, surgiu a necessidade de mudar. Era essencial promover uma maior integração entre as equipes, aproximando o desenvolvimento da infraestrutura e da homologação. Buscávamos cenários em que tudo operasse de maneira uniforme, eliminando as disparidades entre os ambientes e sendo mais homogêneo.
Iniciamos uma reflexão sobre como poderíamos acelerar nossas entregas. A homogeneidade dos ambientes tornaria possível atingir maior agilidade, mas como alcançar isso? Que ferramentas poderíamos empregar para eliminar barreiras e garantir a uniformidade dos ambientes?
Foi nesse contexto de necessidades – integração das equipes, agilidade nas entregas e ambientes homogêneos – que começou a emergir uma nova cultura na área de desenvolvimento e operações: o DevOps.
Entendendo a metodologia DevOps
Segundo o site da Red Hat , o DevOps é uma abordagem que põe ênfase na cultura empresarial, na automação (para evitar conflitos entre equipes, eliminando processos manuais) e no design de plataforma. Este tem como objetivo proporcionar maior valor aos negócios e aumentar a capacidade de resposta às mudanças por meio de entregas de serviços rápidos e de alta qualidade.
Isso é alcançado através de entregas rápidas e de alta qualidade de serviços de TI interativos. Adotar o DevOps implica na integração de aplicações à infraestrutura, incluindo aplicações modernas e nativas em nuvem.
Diante das limitações encontradas no processo tradicional de implantação (deploy), buscamos mais agilidade, resultando na adoção do DevOps. Agora, com o DevOps, as equipes de operações e infraestrutura estão mais próximas da equipe de desenvolvimento. Embora cada equipe ainda execute atividades específicas, a abordagem é mais integrada, visando acelerar o processo de entrega.
Essa implementação será realizada utilizando ferramentas que serão abordadas ao longo do curso, como containers e deploy em provedores de nuvem. Dessa forma, não será mais necessário manter uma grande quantidade de servidores físicos, CPDs específicos, entre outros elementos. Exploraremos, neste curso, a aplicação dessas ferramentas de automação para facilitar a entrega dos nossos sistemas.
Conclusão
Espero que tenham gostado desta introdução. O intuito foi contextualizar o destino que buscamos e a motivação para a necessidade dessa automação e agilidade. Agora, a proposta é seguir um aprendizado gradual, abordando eficientemente os passos necessários.
Aguardo vocês no próximo vídeo para dar continuidade ao estudo da infraestrutura, com nossa equipe de pessoas desenvolvedoras trabalhando em perfeita sincronia para obtermos resultados ainda melhores nas entregas.
Até a próxima!
Falando sobre DevOps - Infra da aplicação
Agora que compreendemos o conceito de DevOps, que envolve o uso de ferramentas ágeis e integração de equipes, vamos avançar e explorar como aplicar esse conceito à nossa aplicação desenvolvida nos cursos de Kotlin.
Explorando Ferramentas e Desafios na Execução da Aplicação
Até o momento, toda a nossa aplicação foi desenvolvida e testada localmente em nossas IDEs. Eu estou utilizando o IntelliJ (uma IDE para desenvolvimento em Java), mas você pode optar pelo Netbeans ou o Eclipse, desde que tenha o plugin do Kotlin instalado.
Anteriormente, para testar a aplicação, fazíamos requisições diretamente à aplicação localmente na IDE. Eu pessoalmente utilizo o Soap UI para requisições HTTP, mas você também pode escolher o Postman, uma opção bastante conhecida, ou até mesmo o navegador para realizar requisições do tipo GET.
Do lado superior esquerdo do Soap UI, clicamos em "REST". Será exibida uma janela intitulada "New REST Project" (Novo projeto REST) com um campo "URI".
Como exemplo, acessava o http://localhost:8080 e realizava uma chamada para o nosso endpoint, que é denominado tópicos: http://localhost:8080/topicos. Para isso, no campo "URI" digitamos o endereço mencionado e clicamos no botão "Ok" no canto inferior direito da janela.
http://localhost:8080/topicos
Será exibida uma janela intitulada "Request 1" (Solicitação 1).
No canto superior esquerdo dessa janela, temos o "method" (método) que vamos deixar como GET para listar os tópicos, caso existissem. Clicamos também do lado superior esquerdo no botão de play "▶" ou podemos usar o atalho "Alt + Enter".
Do lado direito, obtemos:
{
"content": [],
"pageable": {
"sort": {
"sorted": true,
"unsorted": false,
"empty": false
},
"offset":0,
"pageNumber": 0,
"pageSize": 5,
"paged": true,
"unpaged": false
},
"totalPages": 0,
"totalElements": 0,
"last": true,
size: 5,
"number": 0,
"sort":
"sorted": true,
"unsorted": false,
"empty": false
},
"first": true,
*numberOfElements": 0,
"empty": true
}
O resultado da nossa aplicação, neste caso, apresentava um conteúdo (content) vazio, pois ainda não tínhamos adicionado nenhum conteúdo ao nosso banco de dados. No entanto, isso foi apenas uma demonstração de como estávamos procedendo até o momento.
A questão é: qual é o problema dessa abordagem?
Tudo o que discutimos anteriormente implica que, ao utilizar minha máquina local para executar a aplicação e um banco de dados local, não tenho a garantia de que a aplicação terá o mesmo desempenho em minha máquina e nos demais ambientes.
Ao criar um entregável, ou seja, o build da minha aplicação, e repassá-lo à equipe de infraestrutura para realizar o deploy em outros servidores, enfrento a possibilidade de não ter o mesmo desempenho na minha máquina em comparação ao servidor.
Além disso, os servidores podem apresentar configurações diferentes entre si, com uma configuração "X" no servidor de homologação, uma configuração "Y" no servidor de teste, o que potencialmente acarreta problemas. A aplicação pode funcionar corretamente em minha máquina, mas não se comportar da mesma forma na homologação ou teste.
Precisamos extrair os conceitos de DevOps e as ferramentas necessárias para que isso não seja mais um problema para nós. O primeiro recurso que vamos utilizar é o container.
Entendendo container
Para compreender melhor o conceito de container, utilizaremos um diagrama.
O instrutor está usando o site draw.io para ilustrar em um diagrama o que está sendo explicado.
Assim como um container é transportado por embarcações ou linhas ferroviárias, na área de Tecnologia da Informação (TI), teremos uma abordagem semelhante. Analogamente ao container físico que usamos para transportar objetos de um lugar para outro, na TI, teremos algo similar.
Neste contexto, temos a aplicação. Se considerarmos nosso entregável como o arquivo .jar, temos então diferentes ambientes para realizar o deployment: teste, homologação e produção.
Portanto, do lado inferior esquerdo do draw.io selecionamos o retângulo, arrastamos e digitamos "Aplicação (.jar)" dentro dele. Arrastamos mais três retângulos posicionados verticalmente do lado direito da aplicação e digitamos, de cima para baixo, respectivamente: "Teste", "Homol" e "Prod".
Por enquanto, temos:
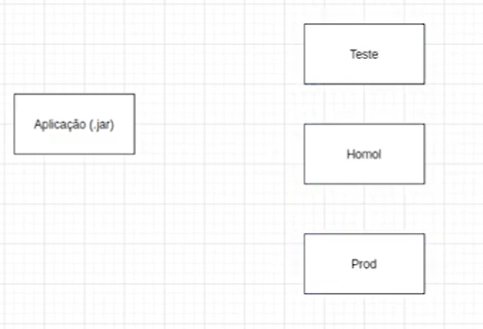
Cada um desses ambientes requer o deployment da aplicação, e, para garantir o correto funcionamento, são estabelecidas conexões com bancos de dados específicos, onde realizamos requisições necessárias.
Para exemplificar esse conceito, movemos da esquerda para a direita mais três ícones de banco de dados, identificados como "Cylinder" (Cilindro) ao passar o mouse sobre eles. Em seguida, adicionamos três setas conectando cada retângulo representando um ambiente aos respectivos bancos de dados.
Agora, introduziremos o conceito de container. Trata-se de uma caixa invisível na qual podemos incorporar a aplicação, tornando-a completamente autocontida. O container abrigará tanto a aplicação quanto todas as dependências e configurações necessárias para a execução.
Portanto, se precisarmos das dependências e configurações da aplicação, estará tudo autocontido nesse container.
Para representar isso, podemos arrastar mais um retângulo e colocá-lo por cima do retângulo do lado esquerdo do diagrama que representa a aplicação .jar. Logo após, clicamos com o botão direito do mouse sobre o novo retângulo e escolhemos a opção "To back" (Voltar) ou podemos usar o atalho "Ctrl + Shift + B".
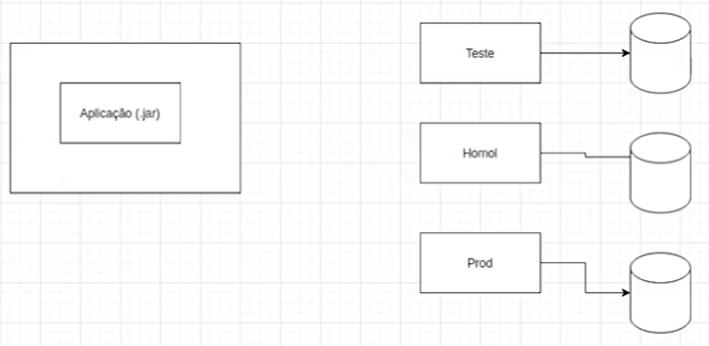
A particularidade reside no fato de que podemos utilizar um container não apenas para a aplicação, mas também para o banco de dados. Por exemplo, é viável integrar um banco de dados ao container contendo todas as configurações essenciais para a aplicação. Se houver a necessidade de uma base específica (X) para a aplicação, realizamos a configuração no container correspondente e estabelecemos a comunicação entre os containers.
Para ilustrar, incluímos um retângulo com um cilindro contido nele para representar o banco de dados abaixo da aplicação. Em seguida, adicionamos uma seta que se estende da aplicação para o banco de dados na parte inferior.
Você pode estar se perguntando: qual a relevância disso para os ambientes? E como isso se conecta aos desafios que enfrentamos?
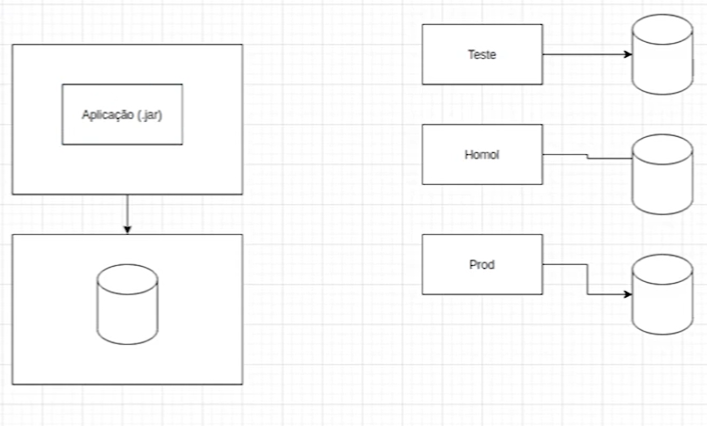
Atualmente, conseguimos transportar nossos dois containers para todos os ambientes. A aplicação que executamos localmente funciona da mesma forma no ambiente de teste, pois está encapsulada. Ela é autocontida dentro de um container que contém todas as configurações, incluindo o banco de dados.
Dessa forma, não precisamos acessar o banco de dados de Homol ou realizar updates e alter tables no ambiente de Homol para garantir o funcionamento da aplicação como no ambiente local. Simplesmente transportamos tudo para cada um desses ambientes, o que é mais comum na cloud, mas também é possível ter ambientes locais, como mencionado no CFD próprio, em servidores de metal, que ainda são utilizados por muitas empresas.
Dessa forma, alcançamos um comportamento consistente em nossa aplicação de teste. Assim que confirmamos que o teste foi bem-sucedido, podemos transferir os containers para um ambiente de Homol.
Podemos clicar em "Text" do lado inferior esquerdo e inserir acima da aplicação e do banco de dados à esquerda o texto "Teste". Logo após, excluímos os retângulos e seus respectivos bancos de dados à direita. Para representar o ambiente de Homol, alteramos o texto "Teste" para "Homol":
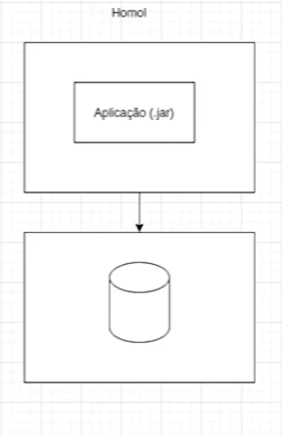
É importante garantir que tudo funcione perfeitamente, pois não houve alterações, configurações distintas ou uma base de dados diferente. Tudo o que estamos replicando, desde o ambiente local até a produção, será idêntico.
Desse modo, estabelecemos um ambiente homogêneo para facilitar e agilizar nossas entregas. A homogeneidade dos ambientes é essencial, e os containers viabilizam essa uniformidade.
Agora, abandonamos a prática de realizar deploy em cada ambiente e torcer para que sejam o mais homogêneos possível, transitando para um ambiente que é 100% homogêneo. Essa garantia é possível porque fomos nós que criamos os containers e os implementamos nos ambientes necessários na empresa, de acordo com suas dimensões e necessidades.
Você pode estar se perguntando: como exatamente os containers funcionam e são executados?
Funcionamento e execução de containers
Utilizaremos executores de containers, que são ambientes projetados para executar containers e viabilizar toda essa funcionalidade. Um exemplo de executor amplamente reconhecido é o Docker, embora não aprofundaremos muito nesse executor específico neste momento; abordaremos esse tema mais detalhadamente posteriormente.
Ao termos o Docker integrado aos nossos ambientes, ao inserirmos o container com a aplicação e o banco de dados, seja um Kafka ou outra plataforma de mensageria, garantimos que nossa aplicação funcione consistentemente em todos os ambientes.
Conclusão
Optamos por uma abordagem mais teórica nesta aula para compreender a trajetória de nossa aplicação e começar a introduzir o conceito de containers. Este será um elemento valioso, proporcionando uma significativa assistência e aprimorando a qualidade e homogeneidade de nossas entregas.
A partir deste ponto, faremos uma transição das aulas teóricas para práticas, explorando efetivamente o funcionamento de nossa aplicação com containers e uma infraestrutura mais elaborada para otimizar os benefícios da cultura DevOps.
Espero que tenham gostado e nos vemos no próximo vídeo. Obrigado!
Sobre o curso Kotlin e Spring: segurança e infraestrutura
O curso Kotlin e Spring: segurança e infraestrutura possui 293 minutos de vídeos, em um total de 55 atividades. Gostou? Conheça nossos outros cursos de Kotlin em Programação, ou leia nossos artigos de Programação.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Falando sobre DevOps
- Segurança com HTTP Basic
- Segurança com JWT
- Profiles
- Docker
- Deploy