Olá, sou a Mirla Costa, instrutora aqui na Alura e vou me autodescrever:
Audiodescrição: Mirla Costa é uma mulher de pele clara, de cabelos cacheados, pretos e de tamanho médio. Tem o rosto fino e alongado, olhos e sobrancelhas pretas. Usa óculos de grau com armação redonda. Está com uma camiseta preta. Ao fundo, duas estantes flutuantes com uma iluminação verde e azul.
Aprenderemos que redes neurais não são um tema complexo que exige um conhecimento avançado.
Compreender o básico do Python, saber utilizá-lo, conhecer as bibliotecas mais comuns em Data Science e entender os conceitos de aprendizado supervisionado e classificação já é o suficiente para começarmos a trabalhar com redes neurais. É exatamente isso que vamos fazer neste curso!
Neste curso, vamos construir uma rede neural capaz de identificar se notas bancárias são autênticas ou falsas, utilizando valores extraídos de imagens dessas notas.
Para garantir que todos acompanhem o aprendizado, vamos explicar o que é uma rede neural e os conceitos essenciais para construí-la.
É importante ressaltar que vamos trabalhar com uma rede neural simples, focando nos conceitos básicos necessários para sua criação. O objetivo não é abordar de maneira aprofundada tópicos avançados de Deep Learning ("Aprendizado Profundo"), pois já existe uma formação específica sobre o tema, a formação de Deep Learning com TensorFlow Keras, que explora esses conceitos de forma mais detalhada.
Com isso, vamos começar a explorar o funcionamento das redes neurais!
Iniciaremos nossa jornada no aprendizado sobre redes neurais, começando pela construção da nossa primeira rede.
Montando uma MLP
Uma rede neural é composta por vários neurônios interconectados, formando uma estrutura semelhante a uma rede.
Os neurônios representam a unidade fundamental dentro de uma rede neural e foram inspirados na estrutura dos neurônios biológicos, encontrados em nosso cérebro. Para facilitar a compreensão de como funcionam os neurônios artificiais, é útil entender primeiro a estrutura de um neurônio biológico.
Um neurônio biológico pode ser dividido em três partes principais. Embora seja possível detalhar ainda mais a estrutura, não é necessário para o nosso estudo. As três partes essenciais são: os dendritos, que recebem sinais sinápticos; o corpo celular, onde os sinais são processados; e os terminais sinápticos, que enviam os sinais processados para outros neurônios ou células.
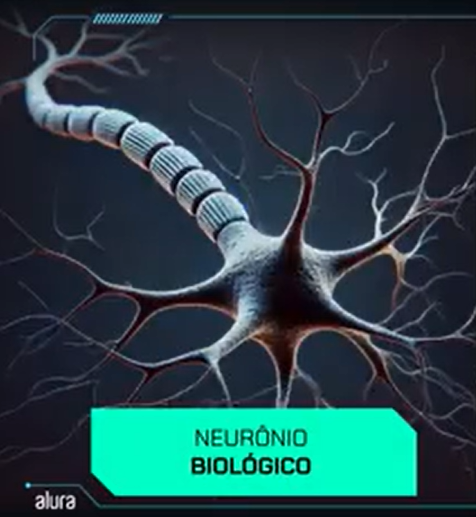
A partir dessa estrutura básica, podemos entender como um neurônio biológico serve de base para a criação de um neurônio artificial.
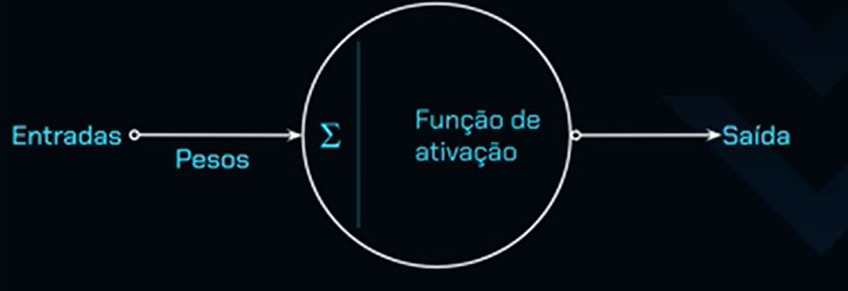
Um neurônio artificial é também conhecido como perceptron. A partir de agora, utilizaremos esse termo.
O perceptron possui entradas, onde os dados serão fornecidos. No contexto do nosso projeto, essas entradas correspondem às características das notas fiscais, com o objetivo de determinar se são autênticas ou falsas.
Cada entrada é associada a um peso, que representa a importância dessa característica no cálculo final. Quanto maior o peso, mais relevante é aquela característica para a decisão final do perceptron.
Após as entradas e os pesos serem fornecidos, o perceptron começa a processar esses valores. O primeiro passo desse processamento é uma soma aritmética, onde as entradas são multiplicadas pelos pesos e, em seguida, somadas. O resultado dessa soma é enviado para uma função de ativação.
A função de ativação é uma função matemática que recebe esse valor de entrada, realiza um cálculo e retorna um resultado. Não se preocupe, a partir daqui não falarei mais de matemática, mas é importante entender esse processo para conhecer o funcionamento do perceptron.
A função de ativação é o último passo no processo do perceptron, pois é ela quem toma a decisão final sobre o valor de saída, ou seja, a decisão do neurônio. No nosso projeto, as características de uma nota fiscal são associadas a um peso, processadas e enviadas para a função de ativação.
A função de ativação então determina se, com base nessas características, a nota fiscal é autêntica ou falsa. Ela gera um valor que é interpretado como uma classificação, no nosso caso, indicando se a nota fiscal é autêntica ou falsa, de acordo com o contexto do projeto.
Compreendemos a estrutura de um perceptron, mas quais tipos de problemas ele é capaz de resolver? Vamos analisar um exemplo.
Considerando este conjunto de dados, em um plano representado no lado direito da tela, como seria possível separar essas informações?

Observamos que, mais acima, estão os valores positivos, representando as notas autênticas, enquanto os valores negativos, marcados com "x", correspondem às notas falsas. Para separar esse conjunto de dados, a solução é simples: basta traçar uma reta que divida os dois grupos. Tudo que estiver acima dessa reta será considerado nota autêntica, e tudo abaixo será classificado como nota falsa.
Isso ocorre porque o perceptron é capaz de resolver problemas lineares.
Quando o problema é não linear, o perceptron, ou neurônio, não consegue resolver a situação simplesmente traçando uma reta para separar os dados. Embora tentemos dividir os conjuntos de dados que estão acima ou abaixo de uma reta, isso não resolverá o problema. Na realidade, é necessário adicionar uma curva:

Ao introduzir uma elipse ou uma curva, conseguimos separar de forma eficaz as notas autênticas das notas falsas.
O perceptron, por ser capaz de resolver apenas problemas lineares, enfrenta limitações ao lidar com problemas não lineares. A solução para isso é adicionar camadas de neurônios, ou camadas de perceptrons. Dessa forma, surge a rede neural chamada multilayer perceptron (MLP), ou perceptron de múltiplas camadas, que possibilita resolver problemas mais complexos e não lineares.
Agora, vamos explorar a estrutura da nossa MLP.
Esse tipo de rede neural é frequentemente representado por imagens com círculos conectados por linhas, algo que muitos já devem ter visto. Vamos entender como essa estrutura funciona na prática.
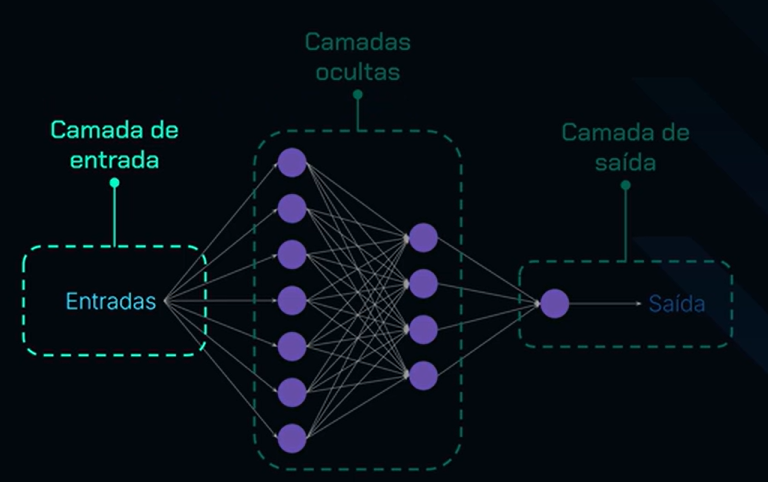
O primeiro componente dessa estrutura é a camada de entrada. Esta camada é responsável por receber as informações que a rede neural precisa processar. No nosso caso, por exemplo, seriam as características das notas fiscais. Após o envio dessas entradas, cada uma delas é associada a um peso específico.
Em seguida, a informação é encaminhada para as camadas ocultas. Essas camadas são formadas por diversos neurônios, representados pelos círculos roxos na imagem. Cada neurônio, como aprendemos anteriormente, é uma unidade artificial, com a função de receber as entradas, aplicar os pesos, realizar a ativação e gerar uma saída. Todos os neurônios estão interconectados, formando a rede neural.
Temos, portanto, diversas camadas ocultas, compostas por neurônios interligados entre si. Nas camadas ocultas, as funções de ativação costumam ser as mesmas, ou seja, utilizamos a mesma função de ativação para os neurônios de todas essas camadas.
Após o processamento das entradas e pesos pelos neurônios da camada oculta, o próximo passo é a camada de saída, que constitui a última camada da rede. Esta camada terá um número específico de neurônios — no exemplo apresentado, há apenas um neurônio.
Esse neurônio processa as informações provenientes da última camada oculta e gera um valor de saída, que corresponde à solução do problema proposto. No caso em questão, esse valor indicará se a nota fiscal é autêntica ou não. Com isso, obtemos a saída do modelo.
A rede neural chega ao resultado por meio de um processo de aprendizado em uma MLP. As informações seguem da camada de entrada, passam pelas camadas ocultas e chegam à camada de saída. Esse processo é chamado de aprendizado feedforward ("alimentação direta" ou "propagação para frente"), no qual as entradas avançam até a saída, sendo processadas por diversos neurônios ao longo do caminho.
Neste momento, uma seta apontando para a direita, em direção à camada de saída, é exibida acima da rede neural.
Após realizar esse processo pela primeira vez, ao enviar as entradas e obter uma saída, calcula-se um valor de perda, o loss. Esse valor quantifica o erro da previsão da rede em relação ao valor desejado.
O valor de perda, ou loss, representa o quão impreciso foi o primeiro envio de dados, indicando o erro do resultado obtido. O ideal é que esse valor seja o menor possível, o mais próximo de zero.
No entanto, após enviar os dados apenas uma vez, passando pelos neurônios, o valor de perda geralmente é alto. Isso não é desejável, pois significa que a rede não aprendeu adequadamente.
É necessário então enviar esse valor de perda de volta para os neurônios, para que eles possam perceber que o peso atribuído a essa entrada talvez não seja o mais adequado, sugerindo a necessidade de alteração.
É nesse ponto que entra o backpropagation ("retropropagação"), que consiste no retorno da perda para a rede neural, permitindo que o aprendizado seja ajustado. Nesse processo, cada peso é atualizado com base no erro calculado.
Neste momento, uma seta apontando para a esquerda, em direção à camada de entrada, é exibida na tela, juntamente com a indicação "Perda (loss)" abaixo.
Além disso, utilizamos uma função de otimização, que tem a função de ajustar a rede neural, analisando seu valor de perda e buscando minimizá-lo ao máximo. Dessa forma, após a retropropagação, a rede neural melhora, pois seus pesos são ajustados para gerar resultados mais precisos.
No entanto, apenas uma rodada desse aprendizado, que envolve tanto o feedforward quanto o backpropagation, não será suficiente para que a rede neural realmente aprenda.
Essa foi apenas uma atualização, e a rede neural teve contato com os dados uma única vez. Ela ainda não conseguiu identificar os padrões necessários para fazer previsões precisas. Por isso, é necessário realizar várias rodadas, ou, como chamamos, várias épocas.
As épocas correspondem a novas rodadas de aprendizado, nas quais a rede neural passa novamente pelos dados para ajustar seus pesos e melhorar suas previsões.
Na animação exibida em tela, ilustramos o processo: o aprendizado feedforward, seguido de backpropagation, repetido diversas vezes de acordo com o número de épocas que definirmos.
Na animação, a seta de backpropagation aparece indo para a esquerda, enquanto a seta de feedforward segue para a direita, representando os dois processos que se alternam durante o aprendizado da rede neural.
O processo continua a se repetir, mas é importante entender que ele não vai ocorrer indefinidamente. Precisamos especificar quantas vezes esse ciclo de aprendizado deve se repetir, para garantir que a rede neural tenha tempo suficiente para aprender. Caso esse processo aconteça apenas uma vez, a rede não será capaz de aprender de forma eficaz.
Agora que entendemos como funciona o MLP, podemos proceder para criar um MLP utilizando o TensorFlow Keras!
Então, vou subir a visualização e pressionar F11 para preencher a tela inteira, porque agora podemos, de fato, começar a construir nosso projeto de rede neural. Os dados sobre notas fiscais estão salvos em uma URL, no arquivo CSV, ao qual você também possui acesso.
Em uma nova célula, começamos a escrever url = ''. Dentro das aspas simples, colamos URL de acesso aos dados. Feito isso executamos a célula.
Criaremos outra célula, pois agora vamos importar os dados. Lembra que mencionamos que seria interessante ter conhecimento em Python e também nas bibliotecas relacionadas à Ciência de Dados? Pandas é uma delas, com a qual vamos manipular os dados. Então, vamos escrever import pandas as pd.
Pressionamos "Enter" para pular de linha e escrevemos df = pd.read_csv(url). Por fim, na linha seguinte passamos df referente ao dataframe e executamos.
import pandas as pd
df = pd.read_csv(url)
df
Ao executar temos o seguinte retorno:
| Variância | Assimetria | Curtose | Entropia | Classe | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8.66610 | -2.8073 | -0.44699 | 0 |
| 1 | 4.54590 | 8.16740 | -2.4586 | -1.46210 | 0 |
| 2 | 3.86600 | -2.63830 | 1.9242 | 0.10645 | 0 |
| 3 | 3.45660 | 9.52280 | -4.0112 | -3.59440 | 0 |
| 4 | 0.32924 | -4.45520 | 4.5718 | -0.98880 | 0 |
| ... | ... | ... | ... | ... | ... |
| 1365 | 0.40614 | 1.34920 | -1.4501 | -0.55949 | 1 |
| 1366 | -1.38870 | -4.87730 | 6.4774 | 0.34179 | 1 |
| 1367 | -3.75030 | -13.45860 | 17.5932 | -2.77710 | 1 |
| 1368 | -3.56370 | -8.38270 | 12.3930 | -1.28230 | 1 |
| 1369 | -2.54190 | -0.65804 | 2.6842 | 1.19520 | 1 |
Temos quatro colunas que se referem às características de notas fiscais. Essas características foram extraídas de imagens de notas fiscais e, a partir dos valores de variância, simetria, curtose e entropia, podemos dizer se essa nota fiscal foi manipulada, se ela é falsa. Assim, teremos nossas classes, que vão indicar se a nota é autêntica ou não.
Inclusive, podemos observar quais são as classes que temos. Para isso, em uma nova célula, escrevemos df.Classe.unique() e executar com "Shift + Enter".
df.Classe.unique()
O retorno é o seguinte:
array([0, 1])
Nisso, percebemos que, realmente, os únicos valores que temos na coluna classe são 0 e 1. Nosso problema é binário.
Agora que já visualizamos nossos dados, podemos começar a tratá-los para serem enviados para um modelo neural. Os tratamentos que precisamos fazer são, basicamente, separar esse conjunto em um conjunto de treino e outro conjunto de teste, para podermos fazer as avaliações, e também aplicar uma normalização, que vai facilitar muito o aprendizado da nossa rede neural.
Para podermos separar esse conjunto em treino e teste, precisamos separar as características da categoria, ou seja, vamos separar as colunas de variância e entropia da coluna classe.
Para isso, criaremos um um DataFrame que vai receber todos esses valores das características e será chamado de X, que será igual a df.drop('Classe', axis=1).values. Assim, vou descartar apenas a coluna classe. Além disso, a categoria, que representa cada uma dessas características, também vamos armazenar. Então, na linha seguinte, chamamosY, que será igual ao df.Classe.values e executamos.
X = df.drop('Classe',axis=1).values
y = df.Classe.values
Agora, podemos começar o processo de separação desse conjunto em treino e teste. Faremos essa separação, pois um conjunto de treino vai permitir que treinemos nosso modelo, que o modelo entenda o padrão dos nossos dados e, assim, consiga prever esses valores. O conjunto de teste vai servir para verificarmos se esse modelo realmente aprendeu a partir dos dados de treino, e não apenas decorou os dados e só sabe replicar o que viu dentro do treinamento. Ou seja, o conjunto de teste vai garantir que esse modelo aprendeu de verdade.
Para fazer isso, podemos importar uma função da biblioteca sklearn. Essa, é uma biblioteca que oferece muito suporte para preparação de dados e construção de modelos de Machine Learning. Então, na célula escrevemos from sklearn.model_selection import train_test_split. Pressionamos "Shift + Enter" para executar, e agora podemos rodar essa função.
from sklearn.model_selection import train_test_split
A partir do momento que enviarmos o valor de x e de y, essa função retornará quatro conjuntos, sendo: características de treino e teste e o conjunto de categorias, o conjunto alvo de treino e teste. Portanto, precisamos criar as variáveis para receber esses dados.
Para isso, escrevemos X_treino, X_teste, y_treino, y_teste = train_test_split(X, y). Também precisamos definir, proporcionalmente, quanto do nosso dataframe DF será um conjunto de teste. Nesse caso, podemos definir um valor de 20%, pois já temos um conjunto total pequeno, com 1.300 amostras. Portanto, podemos pensar em um conjunto que seja de 20% dedicado para o teste. Os 80% restantes desse conjunto de dados serão para o conjunto de treino.
Para fazer isso, ainda nos parênteses, adicionamos vírgula e escrevemos test_size=0,2. Por fim, para tornar esse código mais replicável, vamos definir uma semente randômica, pois a separação de dados do train_test_split é aleatória, ele escolhe aleatoriamente os dados e separa. Então, vamos inserir vírgula, seguido de random_state = 42 e executamos.
X_treino, X_teste, y_treino, y_teste = train_test_split(X,y,test_size=0.2, random_state=42)
Agora que já separamos esse conjunto de dados em treino e teste, também podemos aplicar a normalização, que deixará os dados de uma maneira mais fácil e mais simples para o modelo aprender. A normalização que podemos aplicar é a standard scaler, que colocará todo o conjunto de dados com uma média igual a zero e o desvio padrão igual a 1. Isso fará uma centralização dos dados, tornando mais simples para o modelo.
Para importar a função que executará isso, novamente, vamos utilizar a biblioteca sklearn. Então, vamos inserir from sklearn.preprocessing import StandardScaler e executamos.
from sklearn.preprocessing import StandardScaler
Criaremos agora um objeto que será o objeto scaler. Escrevemos scaler = StandardScaler(). Na linha abaixo, podemos aplicar a normalização no conjunto de treino. Na verdade, podemos treinar esse objeto, o normalizador, através do nosso conjunto de treino, e já aplicar a normalização.
Vamos considerar o conjunto de treino como o principal foco da normalização, para também podermos aplicar essa mesma normalização no nosso conjunto de teste.
Você pode se perguntar, por que não aplicar a normalização logo no conjunto de dados como um todo, o dataframe, no geral? Isso permitiria que o modelo tivesse dados vazados em relação ao conjunto original dele, que queremos testar os dados a partir da divisão.
Então, vamos aplicar a escala normalização no conjunto de treino, evitando que dados sejam vazados para o modelo e ele possa roubar dentro do teste.
Escrevemos X_treino = scaler.fit_transform(X_treino). Essa função já vai treinar esse objeto com esse conjunto de dados de treino, e também já vai transformá-lo, ou seja, vai normalizá-lo.
O conjunto de teste não vamos treinar esse objeto, nós vamos apenas transformá-lo. Então, colocamos X_teste = scaler.transform(X_teste). Executamos com "Shift + Enter".
scaler = StandardScaler()
X_treino = scaler.fit_transform(X_treino)
X_teste = scaler.transform(X_teste)
Após aplicarmos essa normalização, você pode estar se perguntando: "Por que vamos utilizar esses dados para um modelo neural, para uma Multilayer Perceptron (MLP)? Será que um Perceptron resolveria o problema desse conjunto de dados? Por que eu teria que fazer uma rede neural, uma MLP em si?"
Vamos visualizar um pouco das características dos nossos dados. Faremos isso utilizando bibliotecas de visualização de dados, que são o Matplotlib e o Seaborn. Vamos importar essas bibliotecas para visualizar esses dados passando import matplotlib.pyplot as plt.
import matplotlib.pyplot as plt
Após, passamos import seaborn as sns.
import seaborn as sns
Podemos observar, dentro de um plano 2D, como as características se relacionam com as categorias dos dados. Para fazer isso, podemos escolher duas características, mesmo tendo 4, pois não temos um plano 4D para visualizar toda a dispersão dos dados. Sendo assi, teremos que nos limitar a um plano 2D. Escolhemos a variância e a assimetria.
Para fazer esse gráfico, vamos, primeiro, criar a figura com plt.figure(), nos parênteses, passamos figsize=(8,6), que já é um tamanho bom para a nossa figura.
Na linha abaixo, usaremos a biblioteca Seaborn, então, escrevemos sns.scatterplot(), para fazer um gráfico de dispersão. Dentro dos parênteses, podemos definir como x=df['Variância']. Fora dos colchetes, adicionamos vírgula e passamos y=df['Assimetria'].
Por fim, vamos pedir para esse scatterplot categorizar esses dados de acordo com as classes. Para isso, vamos utilizar um novo parâmetro, chamado hue=df['Classe'].
Na linha seguinte, passamos plt.legend(title='Classe') seguido de plt.show(). Feito isso executamos. O código fica da seguinte forma:
plt.figure(figsize=(8,6))
sns.scatterplot(x=df['Variância'],y=df['Assimetria'], hue=df['Classe'])
plt.legend(title='Classe')
plt.show()
Temos a seguint imagem como retorno:
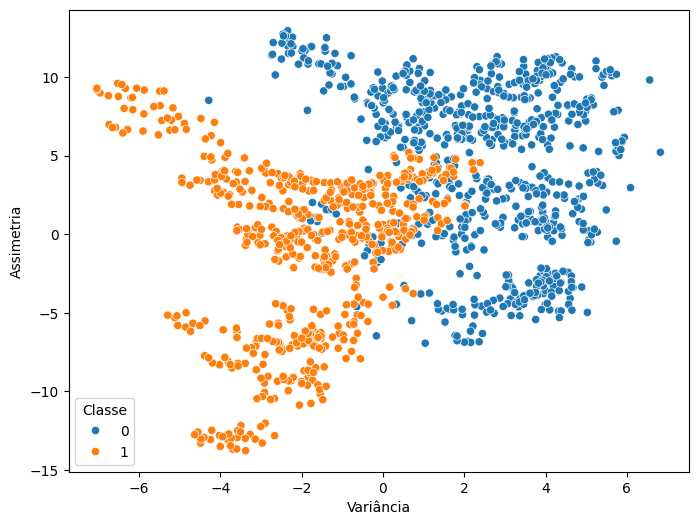
Lembra da estrutura gráfica que mostramos, com os dados que não poderiam ser separados através de uma reta dentro da nossa aplicação? Aqui temos o mesmo problema, é impossível traçar uma reta que separe esse conjunto de dados. Embora tenha alguns dados que estão como falsos, da classe zero, sejam notas fiscais falsas, também temos que considerar que estamos olhando um plano 2D. Então, tem muito mais dimensões envolvidas e que uma rede neural vai conseguir captar essas dimensões e vai conseguir separar bem o que é a nota fiscal falsa da verdadeira, criando esses planos.
Sabendo disso, já temos uma ideia do motivo pelo qual vamos utilizar o modelo neural. Agora, podemos realmente construí-lo.
Até breve!
O curso Live Coding: construindo uma rede neural com Tensorflow Keras possui 60 minutos de vídeos, em um total de 10 atividades. Gostou? Conheça nossos outros cursos de IA para Dados em Inteligência Artificial, ou leia nossos artigos de Inteligência Artificial.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






