LlamaIndex: criando um assistente virtual para consulta de banco de dados
Consultando o banco de dados com um assistente - Apresentação
Boas-vindas ao Curso de Llama Index: Criando um assistente virtual para consulta de dados estruturados! Me chamo Mirla Costa e sou instrutora da Alura.
Audiodescrição: Mirla se declara uma mulher de pele clara, com cabelos cacheados e pretos, que estão presos. Ela usa óculos de grau com armação redonda e veste uma camisa preta. Ao fundo, estantes flutuantes com livros e decorações, além de uma iluminação em degradê na cor verde e azul.
Serei a pessoa que acompanhará você durante todo este projeto!
Criando um assistente SQL com Llama Index
Você já pensou em desenvolver algo semelhante a um chat? Isto é, uma interface que possibilite conversarmos com um assistente SQL.
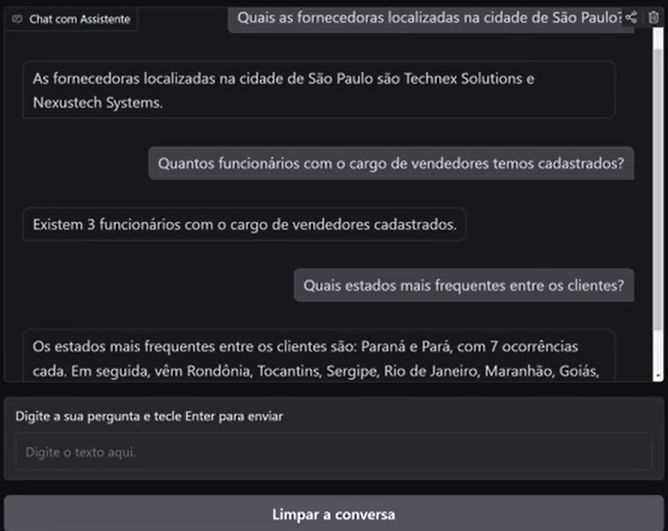
Esse assistente, a partir do momento em que enviamos uma mensagem para tirar uma dúvida sobre um banco de dados, retorna as informações sobre esses dados. Essas informações são obtidas através de consultas que o próprio assistente realiza dentro do nosso banco de dados.
Neste curso, você irá aprender a utilizar o Llama Index para criar um assistente de consultas em banco de dados.
O que vamos aprender?
Neste curso, trabalhamos como pessoas cientistas de dados na Zoop. Precisamos desenvolver um assistente para que pessoas sem conhecimento sólido em SQL e Python consigam consultar o banco de dados da empresa e obter informações que ajudarão em seu trabalho.
Durante todo o desenvolvimento do nosso projeto, utilizaremos Python e bibliotecas como sqlalchemy, llama-index e gradio, que nos permitirão conectar ao banco de dados, realizar consultas e construir essa interface.
Pré-requisitos
Para que você aproveite bem este curso, recomendamos fortemente que tenha um sólido conhecimento em Python e também um conhecimento básico sobre Llama Index e LLMs (modelos de linguagem ampla).
Vamos começar!
Consultando o banco de dados com um assistente - Conectando o banco de dados ao ambiente
Trabalhamos como pessoas cientistas de dados na Zoop Megastore, onde armazenamos informações sobre nossos clientes, funcionários e fornecedores em nosso banco de dados.
Descrevendo o desafio de consulta a banco de dados
Muitas pessoas que precisam das informações contidas no nosso banco de dados não sabem utilizar comandos SQL para fazer consultas e, assim, ajudar em suas pesquisas. Isso acaba consumindo bastante tempo de quem tem esse conhecimento técnico para poder ajudá-los nessa tarefa.
Propondo uma solução com interface em linguagem natural
Para resolver esse problema, construiremos uma interface que, ao receber um comando em linguagem natural, ou seja, a mesma que utilizamos para nos comunicar, realiza uma consulta SQL de forma inteligente e retorna a resposta.
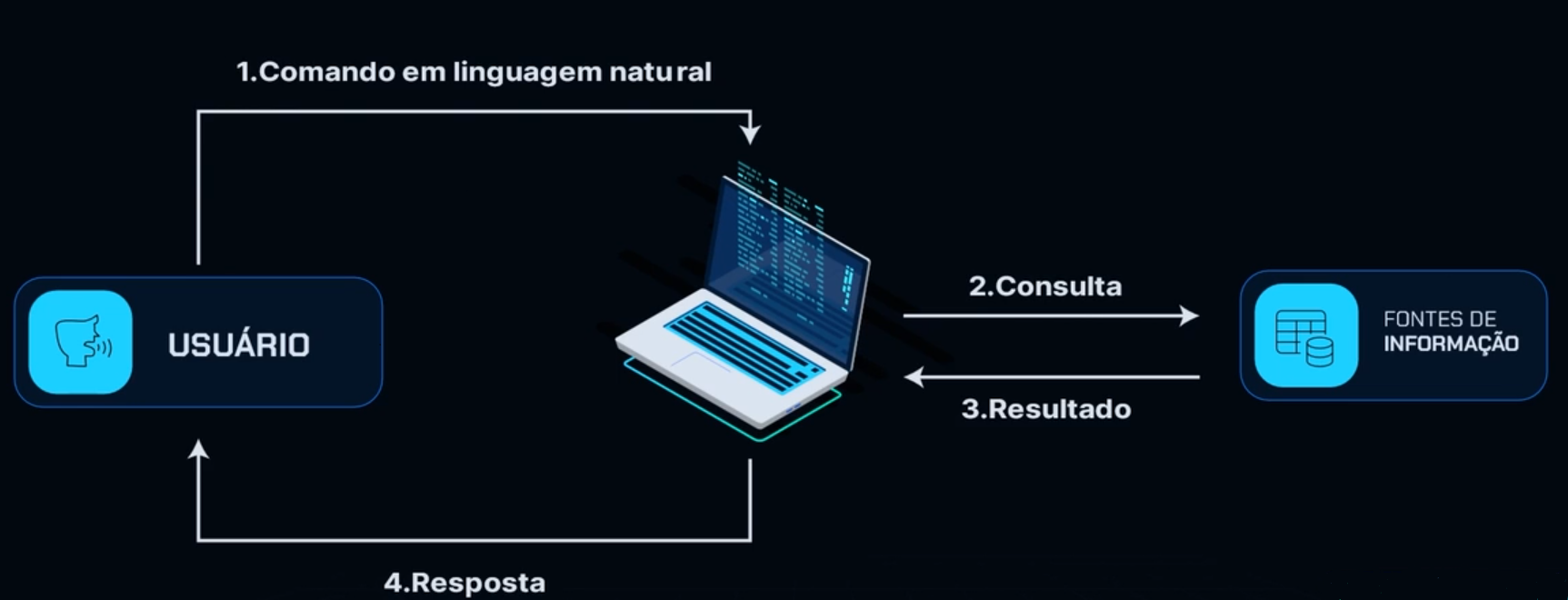
Dessa forma, eliminamos parte da necessidade de conhecimento de SQL para obter informações sobre as tabelas dentro do banco de dados da Zoop.
Conhecendo as características do banco de dados
Para fazer isso, precisamos utilizar dados LLMs, mas, para saber qual ferramenta utilizar, precisamos primeiro conhecer nossos bancos de dados e entender suas características para saber que tipo de ferramenta vamos utilizar para resolver nosso problema.
Vamos para o nosso Colab, que é o ambiente onde desenvolveremos este projeto. Já estamos dentro do Colab, conectados, e utilizaremos o notebook durante todo o projeto. Ele contém links de referência e algumas explicações para nos ajudar a desenvolver isso juntos.
O notebook está disponível para download, assim como os dados que utilizaremos durante este curso, que são os dados de e-commerce da Zoop. Vá até as atividades desta aula e baixe esses dois arquivos para que possamos seguir neste projeto juntos.
A primeira coisa que faremos é importar esses arquivos para dentro do ambiente Colab. Para isso, consultamos a barra do canto esquerdo da tela do Colab, clicando em "arquivos". Em seguida, clicamos no primeiro botão de fazer upload abaixo do título de "Arquivos" na parte superior esquerda. Já estamos com a aba aberta, que contém o dado de "ecommerce". Clicamos no botão "Abrir" na parte inferior direita, e o carregamento é feito.
sample_dataecommerce.db
Logo em seguida, já temos o arquivo ecommerce.db salvo dentro do nosso ambiente.
Atentem-se que ele tem o final
.db, que é database, um tipo de arquivo de banco de dados.
Importando os dados para o ambiente Colab
Agora faremos a importação desses dados para termos acesso a eles. Para importar e acessar esses dados, precisamos nos conectar a um banco de dados, sendo ele o ecommerce.db. Para isso, utilizamos o SQLite com o suporte da biblioteca SQL Alchemy. Vamos criar um engine que permita o acesso a um banco de dados localizado na memória, que é o e-commerce, e também podemos extrair algumas informações que estão dentro desse banco de dados, que ainda nem sabemos quais são, com o MetaData.
Vamos importar as funções create_engine e MetaData, que na verdade é uma classe. Em uma célula, digitamos:
from sqlalchemy import create_engine, MetaData
Em seguida, na mesma célula, salvamos o caminho do nosso arquivo, que é o ecommerce.db. Vamos chamar esse arquivo de url, que será igual a caminho do arquivo entre aspas simples. Por enquanto, temos:
from sqlalchemy import create_engine, MetaData
url = ''
Para coletar esse caminho, voltamos aos nossos arquivos clicando no botão de arquivos à esquerda, à direita do arquivo ecommerce.db clicamos nos três pontos e copiamos o caminho selecionando a opção "Copiar caminho". Fechamos os arquivos novamente e, dentro das aspas simples do nosso url, colamos o caminho:
from sqlalchemy import create_engine, MetaData
url = '/content/ecommerce.db'
Na mesma célula, criamos a engine de acesso a esse banco de dados. Chamaremos de engine, que será igual a create_engine(f'sqlite:///{url}'), sendo o que está dentro dos parênteses o nosso caminho. Com o suporte do SQLite, criamos uma string utilizando o SQLite, mas nos dirigindo ao banco de dados da nossa memória.
from sqlalchemy import create_engine, MetaData
url = '/content/ecommerce.db'
engine = create_engine(f'sqlite:///{url}')
Executamos o comando com "Shift + Enter" e já temos a engine.
Explorando as tabelas disponíveis no banco de dados
Verificaremos que tipos de tabelas temos dentro desse arquivo. Para isso, criaremos um objeto de metadados com o metadata.
Metadados são as informações sobre essas tabelas.
Em uma nova célula, chamaremos de metadata_obj e colocaremos MetaData() para criar o objeto. Esse objeto irá coletar as informações da engine. Para isso, na mesma célula, utilizamos o comando metadata_obj.reflect(engine):
metadata_obj = MetaData()
metadata_obj.reflect(engine)
Feito isso, conseguimos acessar os nomes das nossas tabelas. Para acessar, na mesma célula, utilizamos metadata_obj.tables.keys():
metadata_obj = MetaData()
metadata_obj.reflect(engine)
metadata_obj.tables.keys()
dict_keys(['Clientes', 'Fornecedores', 'Funcionarios'])
Executamos o comando e temos um dicionário com todos os nomes das nossas tabelas: clientes, fornecedores e funcionários.
Visualizando os dados das tabelas
Observaremos o que há em cada uma dessas tabelas para entender melhor os dados que estamos recebendo. Para uma visualização bonita e acessível, em formato tabelar, utilizaremos o pandas. Neste momento, utilizaremos o pandas, mas durante o projeto, quase não utilizaremos dataframes, apenas para ações pontuais como esta.
Faremos um import do pandas como pd e utilizaremos o comando pd.read_sql_table(). Entre parênteses, digitamos o nome da tabela que desejamos consultar. No caso, vamos consultar Clientes (entre aspas simples) e, na sequência, digitamos vírgula engine:
import pandas as pd
pd.read_sql_table('Clientes', engine)
Executamos com "Shift + Enter" e obtemos:
A tabela abaixo foi parcialmente transcrita:
- ID_Cliente Nome Rua_Numero Estado Valor_gasto 0 1 lucas moura lucas.moura@email.com sitio de cardoso, 49 sao paulo 29017 1 2 julia andrade julia.andrade@email.com trecho mariane teixeira, 90 tocantins 7834 2 3 rafael dias rafael.dias@email.com setor de duarte, 114 paraiba 4071 3 4 carla souza carla.souza@email.com recanto ana livia lopes, 53 para 17512 4 5 felipe neto felipe.neto@email.com jardim de monteiro, 11 sao paulo 24307
Temos o id, o nome dos nossos clientes, e-mail e algumas informações sobre eles, sendo cada linha um cliente específico.
Copiamos o comando pd.read_sql_table('Clientes', engine), pois desejamos verificar também a tabela fornecedores. Ao invés de clientes, colocamos fornecedores:
pd.read_sql_table('Fornecedores', engine)
A tabela abaixo foi parcialmente transcrita:
- ID_Fornecedores Nome Contato Telefone Rua Bairro Cidade Estado CEP 0 1 technex solutions lucas martins 11912345678 info@technexsolutions.com rua das inovacoes, 123 centro sao paulo sp 1000000 1 2 quantum devices isabela oliveira 11923456789 contact@quantumdevices.net avenida tecnologica, 456 jardim futuro guarulhos sp 20000000 2 3 innovatetech corporation rafael pereira 11934567890 support@innovatetechcorp.com alameda do progresso, 789 centro das inovacoes santo andre sp 30000000
Temos também nossos fornecedores, onde cada linha se refere a um, com informações sobre eles. Falta apenas a tabela Funcionarios. Vamos novamente colocar o nosso read_sql_table() e, ao invés de Clientes, utilizamos Funcionarios:
pd.read_sql_table('Funcionarios', engine)
Obtemos uma tabela com as colunas "ID_Fornecedor", "Nome", "Contato", "Telefone", "Email", "Rua", "Bairro", "Cidade", "Estado" e "cep".
O mesmo padrão se aplica. Cada linha é uma informação específica sobre uma pessoa funcionária. Temos cargos e, entre as pessoas fornecedoras, até as localidades de cada pessoa fornecedora, o que é muito interessante.
Percebemos que temos dados estruturados. Um LLM muito simples não nos ajudará tanto a resolver nosso problema. Precisamos de uma ferramenta que permita o acesso a esses bancos de dados para fazer as consultas SQL.
Próximo passo
A ferramenta em questão é o Llama Index, e iniciaremos seu uso no próximo vídeo!
Consultando o banco de dados com um assistente - Definindo configurações essenciais
Agora que conhecemos nossos dados, entendemos que é necessário utilizar uma ferramenta específica para realizar consultas no nosso banco de dados e, principalmente, para acessá-lo de forma eficiente. A ferramenta responsável por essa tarefa é o Llama Index, que permite realizar essas operações de maneira eficaz.
O que é o Llama Index e como podemos utilizá-lo
O Llama Index é uma ferramenta que nos permite conectar os dados que temos a modelos de linguagem natural.
Assim, conseguimos enviar uma requisição em linguagem natural e fazer com que esse modelo busque, dentro dos nossos dados, uma resposta equivalente à pergunta que fizemos, sem a necessidade de estarmos diretamente consultando o banco de dados.
Para utilizarmos o Llama Index, seguimos alguns passos. O primeiro é a instalação dos pacotes no ambiente Colab, pois o Colab não possui esses pacotes nativamente. Também precisaremos coletar uma chave API do groq para ter acesso aos modelos de linguagem natural. Além disso, precisamos configurar o Llama Index para que ele utilize o modelo LLM do groq e um modelo de embeddings que aceite nosso modelo groq.
Vamos para o nosso notebook para começar o primeiro passo.
Configurando o Llama Index
Dentro do notebook, na parte de "Configurando o Llama Index", já temos uma lista com um pip install dos pacotes que utilizaremos durante todo o projeto. Esses pacotes envolvem o Llama Index e, mais adiante, o gradio, que nos permitirá construir nossa interface.
!pip install llama-index llama-index-llms-groq llama-index-experimental llama-index-embeddings-huggingface llama-index-postprocessor-cohere-rerank gradio
Collecting llama-index
Downloading llama_index-0.12.2-py3-none-any.whl.metadata (11 kB)
Collecting llama-index-llms-groq …
Executamos a célula para instalar os pacotes no ambiente Colab.
Coletando a chave da API do grop
O segundo passo é coletar a chave da API do groq, o que nos permite utilizar os modelos LLMs e outros recursos do Llama para construir nossa interface. Como já fizemos a instalação, para não ficarmos com texto do retorno do comando anterior, podemos realizar algumas ações para a saída da célula de código.
Clicamos no botão abaixo do ícone de play (de executar a célula) à esquerda do comando e selecionamos a opção de "Mostrar/Ocultar saída", para não termos um texto muito extenso com a saída do pip install.
Voltando ao segundo passo, em uma nova célula, já deixamos um código pronto para coletar essa chave da groq API:
from google.colab import userdata
key = userdata.get('GROQ_API')
Como chegamos no código acima?
À esquerda, clicamos no botão representado por uma chave, identificado como "Secrets" ("segredos") dentro do notebook. Ao clicar nessa chave, encontramos a cheva groq armazenada e nomeada como GROQ_API, com acesso ao notebook.
Disponibilizamos um passo a passo na atividade "Preparando o ambiente" que orienta como chegar até este ponto.
O código fornecido pelo Colab na parte inferior é copiado e colado na célula, o que gerou a key, correspondente à chave do groq API, armazenada no secret. A próxima etapa consiste em executar esta célula para obter a nossa key, concluindo assim o segundo passo.
Configurando o Llama Index para utilizar o modelo groq em consultas
O terceiro passo consiste em configurar o Llama Index para que ele compreenda que, ao realizar uma consulta utilizando a ferramenta, deve-se utilizar o modelo groq, em vez do modelo padrão do Llama Index, que é da OpenAI.
Como o modelo da OpenAI não é o desejado, é necessário ajustar as configurações do Llama Index para que ele utilize as LLMs fornecidas pela groq. Outro aspecto importante é que, por ser necessário usar embeddings e criar índices vetoriais, é preciso também configurar qual modelo de embedding o Llama Index irá utilizar, visto que o modelo padrão do Llama também está relacionado à OpenAI.
Esses dois modelos, tanto o LLM quanto o embedding, já estão armazenados no nosso notebook. O modelo LLM é o llama-3.1-70b-versatile, e o modelo de embedding é o BAAI/bge-m3 do Hugging Face.
Se acontecer erros nessa versão no Llama você pode usar a versão
llama-3.3-70b-versatile.
Caso queira mais informações sobre esses modelos, é possível acessar os links correspondentes dos modelos disponíveis no notebook.
modelo="llama-3.1-70b-versatile"
modelo_hf_emb="BAAI/bge-m3"
Executamos a célula para salvar os nomes.
Configurando o Llama Index para utilizar o LLM e o Embedding
Agora, vamos configurar o Llama Index para utilizar tanto o LLM quanto o embedding.
Essa configuração será feita através da classe Settings dentro do Llama Index. Para utilizá-la, precisamos importá-la no nosso ambiente. Vamos digitar na célula:
from llama_index.core import Settings
Essa classe Settings que nos permitirá fazer as configurações. Teclamos "Enter" para pular uma linha e agora vamos importar a classe do groq dentro do Llama Index para utilizá-la:
from llama_index.core import Settings
from llama_index.llms.groq import Groq
Por fim, na mesma célula, também faremos um import do Hugging Face Embedding para utilizar o modelo de embedding do Hugging Face:
from llama_index.core import Settings
from llama_index.llms.groq import Groq
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
Com isso, importamos todas as classes necessárias e podemos definir as configurações.
Definindo as configurações
Na mesma célula, a primeira configuração será as LLMs que o Llama utilizará. Para isso, colocamos: Settings.llm = Groq(model=modelo, api_key = key). Dentro dos parênteses do Groq() estamos especificando o modelo e a chave.
Assim, ficamos com:
from llama_index.core import Settings
from llama_index.llms.groq import Groq
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
Settings.llm = Groq(model=modelo, api_key = key)
Configurando o modelo embedding
Por fim, ainda na mesma célula, configuramos o modelo de embedding com Settings.embed_model = HuggingFaceEmbedding(model_name = modelo_hf_emb), sendo o modelo_hf_emb da mesma forma que criamos na célula anterior.
from llama_index.core import Settings
from llama_index.llms.groq import Groq
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
Settings.llm = Groq(model=modelo, api_key = key)
Settings.embed_model = HuggingFaceEmbedding(model_name = modelo_hf_emb)
Pressionamos "Shift + Enter" para criar as configurações e importar esses modelos para o nosso ambiente.
Próximos passos
Com isso, todas as configurações foram feitas! Com tudo configurado, podemos estruturar nosso banco de dados no Llama Index para que o modelo tenha acesso e faça suas consultas. Isso será abordado no próximo vídeo!
Sobre o curso LlamaIndex: criando um assistente virtual para consulta de banco de dados
O curso LlamaIndex: criando um assistente virtual para consulta de banco de dados possui 156 minutos de vídeos, em um total de 48 atividades. Gostou? Conheça nossos outros cursos de IA para Dados em Inteligência Artificial, ou leia nossos artigos de Inteligência Artificial.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Consultando o banco de dados com um assistente
- Contextualizando o modelo
- Iniciando a personalização de prompts
- Construindo a cadeia de ações
- Criando um chat com a IA