LlamaIndex: criando um chatbot com a técnica RAG
Preparando os dados - Apresentação
Já ouviu falar sobre RAG, uma técnica amplamente utilizada na construção de chatbots, que nos permite recuperar e gerar textos a partir de informações relevantes contidas em um banco de dados? Este curso abordará exatamente esse tema.
Estou bastante animada para começar, mas, antes de tudo, permitam-me apresentar. Meu nome é Valquíria, sou instrutora na Escola de Dados da Escola de IA.
Audiodescrição: Valquíria se identifica como uma mulher branca. Possui olhos castanhos, cabelos loiros e ondulados, com comprimento abaixo dos ombros. Possui um piercing no septo e veste uma blusa bege. Ao fundo, uma parede lisa iluminada em tons de verde e azul, um vaso de plantas à esquerda e uma estante decorada à direita.
Estou aqui para acompanhar vocês neste curso, no qual vamos criar um chatbot utilizando essa técnica.
Conhecendo o projeto
Vamos desenvolver um projeto para uma loja online de cafés especiais. Trata-se de um site que vende grãos de cafés especiais, no qual a clientela deseja incluir um chatbot na página para que as pessoas que desejam comprar café possam esclarecer dúvidas sobre qual grão escolher, a forma de preparo ou outras informações.
Abaixo, temos o resultado após essa implementação:
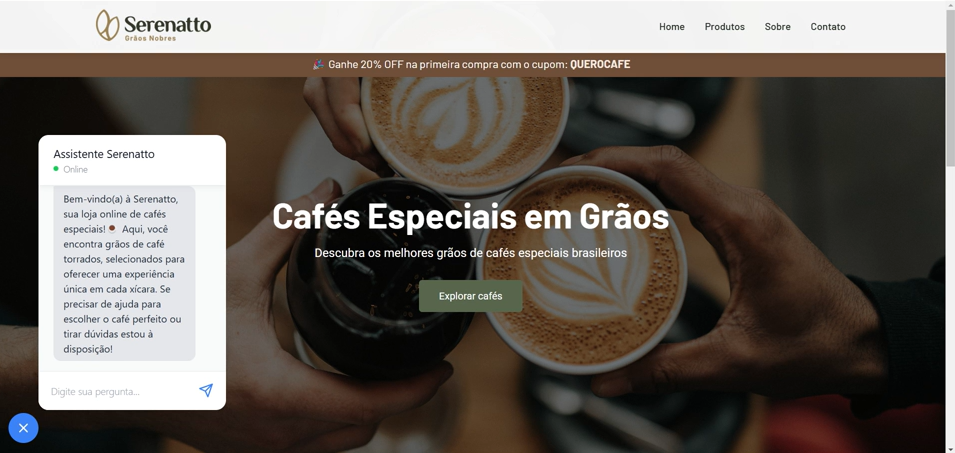
Temos o chatbot na página, junto com os grãos que são vendidos. A ideia é que, ao iniciar a interação, o chatbot já nos receba com uma mensagem de boas-vindas, como:
"Bem-vindo(a) à Serenatto, sua loja online de cafés especiais. Aqui você encontra grãos torrados e pode tirar dúvidas comigo."
Vamos começar testando como está funcionando. Podemos perguntar, por exemplo:
Gostaria de um café mais doce e suave, qual você recomenda?
Ao rodar o sistema, ele começará a processar a resposta e logo nos fornecerá uma recomendação:
Para quem busca sabores suaves, eu recomendaria o Bourbon Vermelho. Ele possui doçura intensa, corpo encorpado e notas de chocolate. Além disso, a acidez é baixa e o amargor é leve, o que o torna uma ótima opção para quem procura um café mais doce e suave.
Podemos também perguntar sobre métodos de preparo. Por exemplo:
Como preparo café gelado?
Após um momento de processamento, recebemos uma receita com uma técnica e etapas para preparar o café.
O que aprenderemos?
Para construir essa ferramenta incrível, utilizaremos algumas ferramentas. Vamos aprender a processar um arquivo contendo informações sobre a Serenatto e os grãos de café que eles vendem. A partir desse arquivo, criaremos um banco de dados, transformando textos em números e armazenando-os. Posteriormente, entenderemos como recuperar informações e construir um chatbot.
Iniciaremos utilizando as bibliotecas LlamaIndex e Gradio para criar um protótipo do chatbot. Em seguida, avançaremos utilizando a ferramenta Langflow para construir um fluxo completo, gerando o chatbot final. Integraremos o chatbot na página HTML da Serenatto e realizaremos o deploy da página para testes em um ambiente real.
Pré-requisitos
Será um trabalho extenso e maravilhoso. Para acompanhar bem o curso, recomendamos que já possuam conhecimentos em Python e na biblioteca LlamaIndex.
Vamos começar!
Preparando os dados - Carregando os documentos
Vamos dar início ao nosso projeto. Atuaremos para a loja Serenatto, que anteriormente era um bistrô e café físico. Eles decidiram expandir os negócios e criar uma página para vender cafés especiais torrados.
Ao verificar a página deles, notaremos que eles vendem alguns grãos especiais, como Bourbon Vermelho, Bourbon Amarelo, um blend especial, Catuaí Amarelo, Geisha e YirgaCheffe.
Identificando o problema da clientela
O problema que a loja enfrenta é que a clientela têm relatado dificuldade para escolher o grão ideal e efetuar a compra. Especialmente quem está começando a conhecer cafés especiais, muitas vezes não sabe como preparar o café e têm dúvidas em geral.
Perguntas como "O que é cada grão?", "Qual é a diferença entre eles?" e "O que é perfil sensorial?" são comuns. Essas dúvidas podem levar a clientela a desistir da compra, pois não consegue decidir o que comprar.
A ideia é implementar um chatbot na página da Serenatto. Assim, a pessoa poderá clicar no chatbot e perguntar sobre os grãos, métodos de preparo e informações sobre a Serenatto. O chatbot fornecerá respostas imediatas, facilitando a interação da clientela e ajudando-a a efetuar a compra.
Utilizando a técnica RAG para gerar respostas precisas
Para criar esse chatbot, utilizaremos uma técnica famosa em inteligência artificial chamada RAG, que significa Retrieval Augmented Generation (Geração Aumentada por Recuperação). Essa técnica possui duas etapas principais:
- Recuperação
- Geração
Na recuperação, a pessoa abre o chatbot e faz uma pergunta, como "vocês vendem algum café descafeinado?". Precisamos recuperar essa informação de uma base de conhecimento.
Após a recuperação, vem a etapa de geração, onde um modelo de linguagem contextualiza a informação recuperada e responde à pessoa. Um exemplo de resposta é "não temos grão descafeinado, mas temos outras opções."
Criando uma base de conhecimento para o chatbot
A vantagem dessa técnica é que não geramos informações genéricas; fornecemos informações verdadeiras e específicas da Serenatto. Para isso, precisamos criar uma base de conhecimento.
Podemos ter um arquivo contendo as informações que queremos que a pessoa saiba sobre o site. Esse arquivo pode ser em diferentes formatos, como uma planilha ou um arquivo CSV, mas também pode ser um arquivo PDF. Vamos estruturar todas as informações da Serenatto em um arquivo PDF, que servirá como nossa base de conhecimento.
Também é possível combinar arquivos PDF com CSV ou criar uma pasta com diferentes tipos de arquivos, mas focaremos em um arquivo PDF.
Explorando o conteúdo do arquivo PDF
Realizamos vários testes para obter resultados mais interessantes e confiáveis. Esse processo gerou um arquivo PDF que visualizaremos juntos.
Esse PDF contém informações da Serenatto, começando com perguntas e respostas gerais. Por exemplo:
P: Quais produtos são vendidos no site da Serenatto?
R: A Serenatto é uma loja online especializada na venda de grãos de cafés especiais, oferecendo grãos torrados, provenientes de fazendas selecionadas de Minas Gerais. Todos os nossos cafés possuem nota SCA acima de 80, garantindo alta qualidade e perfis sensoriais excepcionais.
Outras perguntas incluem a origem dos grãos, quantidade vendida, variedades disponíveis e preços.
Na página seguinte, há mais informações gerais sobre a loja, como prazo de envio, destinos, métodos de pagamento, cursos ou workshops sobre cafés, serviço de assinatura e contatos para dúvidas, como WhatsApp e e-mail.
Estruturando o arquivo por temas
Dividimos o conteúdo por temas. Nas duas primeiras páginas, temos informações gerais. Na terceira página, começamos com informações sobre as variedades dos grãos.
Se alguém quiser mais detalhes sobre o Bourbon Vermelho, por exemplo, encontrará informações sobre doçura, sensação, corpo do café, acidez, etc. Há perguntas sobre todos os tipos de café, variedades, e dúvidas sobre a nota SCA, usada para avaliar a qualidade do café.
Também incluímos informações sobre a produção dos cafés, como a torra e a altitude de cultivo afetam o sabor. Há recomendações de métodos de preparo, como o café coado, com receita e dicas para preparar café gelado, além de outros métodos como espresso e French press. Incluímos dúvidas sobre moagem dos cafés, armazenamento e validade.
Preparando o ambiente no Google Colab
Este arquivo está disponível acima e na atividade de preparação do ambiente desta aula, que precede este vídeo. É necessário fazer o download no computador.
Vamos acessar o Google Colab para carregar este arquivo e começar a processá-lo, preparando nossa base de conhecimento.
No Google Colab, com o ambiente já conectado, acessaremos o menu lateral esquerdo e clicaremos no ícone de pasta. Na aba exibida, criaremos uma nova pasta clicando com o botão direito do mouse e selecionando "Nova pasta". Nomearemos a pasta como "documentos".
Em seguida, abriremos a pasta clicando nela e inseriremos um arquivo PDF que está no computador. Para isso, clicaremos no ícone de "Fazer upload", localizaremos o arquivo na janela do explorador de arquivos do computador e o abriremos.
Na janela de aviso exibida, clicaremos em "OK". Por fim, arrastaremos o arquivo para a pasta "documentos".
- documentos
serenatto_cafes_especiais.pdf
Instalando e utilizando a biblioteca LlamaIndex
Para ler e processar este arquivo, utilizaremos a biblioteca LlamaIndex. Primeiramente, precisamos instalá-la no Colab. Na primeira célula de código, executaremos o comando abaixo, onde -q evita a exibição de muitas informações durante a instalação.
!pip install -q llama-index
Após alguns segundos, a instalação é concluída e podemos prosseguir.
Seguiremos com a importação de uma classe que permite ler uma pasta e carregar os arquivos contidos nela. Na cálula seguinte, utilizaremos o comando abaixo:
from llama_index.core import SimpleDirectoryReader
Executaremos o comando e, em seguida, criaremos uma variável chamada documentos, que corresponde ao nome da pasta. Chamaremos a classe SimpleDirectoryReader() e passaremos o parâmetro input_dir='documentos'.
documentos = SimpleDirectoryReader(input_dir='documentos')
Carregando e verificando os arquivos
Após executar a célula, verificaremos quais arquivos foram carregados. Utilizaremos documentos.input_files para visualizar que o documento PDF serenatto_cafes_especiais.pdf foi carregado corretamente.
documentos.input_files
Retorno:
[PosixPath('/content/documentos/serenatto_cafes_especiais.pdf')]
Agora, carregaremos o arquivo PDF criando uma nova variável chamada docs. Chamaremos documentos.load_data() para carregar o conteúdo.
docs = documentos.load_data()
Podemos conferir o conteúdo de docs:
docs
Essa variável apresenta um resultado extenso devido às várias páginas do PDF. Cada página possui um id e o conteúdo é exibido em text, com quebras de linha indicadas por \n.
Retorno:
[Document(… text='Serenatto – Loja online de cafés especiais Informações gerais P: Quais produtos são vendidos no site da Serenatto? R: A Serenatto é uma loja online especializada na venda de grãos de cafés especiais,…)]
Extraindo metadados do documento
Para verificar o número de páginas, utilizaremos o comando len(docs), que confirma a presença de 10 páginas.
len(docs)
Retorno:
10
Podemos também obter os metadados do documento. Usaremos o print() abaixo para visualizar informações como o número da página, nome do arquivo, caminho, data de criação e modificação, e tamanho do arquivo.
print(docs[0].get_metadata_str())
Retorno:
page_label: 1
file_name: serenatto_cafes_especiais.pdf
file_path: /content/documentos/serenatto_cafes_especiais.pdf
file_type: application/pdf
file_size: 133957
creation_date: 2025-02-17
last_modified_date: 2025-02-17
Para acessar mais informações, digitaremos docs[0].__dict__, que retorna um dicionário com detalhes sobre a primeira página, incluindo ID, nome, caminho, criação e o texto da página. Como não há imagens, áudio ou vídeo, esses campos aparecem como None.
docs[0].__dict__
Retorno:
{'id_': '23d1536a-08af-46ba-82c0-c565f1d3a838',
'embedding': None,
'metadata': {'page_label': '1',
'file_name': 'serenatto_cafes_especiais.pdf',
'file_path': '/content/documentos/serenatto_cafes_especiais.pdf',
'file_type': 'application/pdf',
'file_size': 133957,
'creation_date': '2025-02-17',
'last_modified_date': '2025-02-17'},
'excluded_embed_metadata_keys': ['file_name',
'file_type',
'file_size',
'creation_date',
'last_modified_date',
'last_accessed_date'],
'excluded_llm_metadata_keys': ['file_name',
'file_type',
'file_size',
'creation_date',
'last_modified_date',
'last_accessed_date'],
'relationships': {},
'metadata_template': '{key}: {value}',
'metadata_separator': '\n',
'text_resource': MediaResource(embeddings=None, data=None, text='Serenatto – Loja online de cafés especiais …', path=None, url=None, mimetype=None),
'image_resource': None,
'audio_resource': None,
'video_resource': None,
'text_template': '{metadata_str}\n\n{content}'}
Próximos passos
Com o arquivo estruturado na biblioteca LlamaIndex, temos um documento de 10 páginas, cada uma com um ID e suas informações. O próximo passo é preparar este arquivo para inseri-lo na nossa base de dados.
Preparando os dados - Organizando os documentos em partes menores
Iniciamos o projeto carregando os dados da Serenatto, que contêm informações sobre os cafés e seu preparo. O problema que enfrentamos é que temos um documento repleto de texto e informações.
Se uma pessoa cliente fizer uma pergunta, como "Quero mais detalhes sobre o Bourbon Amarelo", nossa inteligência artificial teria que percorrer todo o documento para encontrar a informação desejada, o que seria demorado e difícil.
Facilitando a busca com a divisão do documento
A ideia do RAG é pegar esse documento e, antes de colocá-lo no banco de dados, separá-lo em partes menores. Isso facilita o processo, pois a IA pode procurar em blocos específicos e fornecer a resposta de forma mais prática.
Para criar esses blocos menores, utilizaremos uma ferramenta do LlamaIndex. Na próxima célula de código, importaremos a classe SentenceSplitter e criaremos um objeto chamado node_parser para separar o texto em chunks (blocos) baseados em um número de caracteres (chunk_size).
Neste caso, definiremos o valor de 1200 caracteres.
from llama_index.core.node_parser import SentenceSplitter
node_parser = SentenceSplitter(chunk_size=)
Ao definir o parâmetro chunk_size, devemos ajustar o número de caracteres de cada bloco. O valor ideal depende do documento, e testes são necessários para garantir que nenhuma informação seja perdida. Se o corte ocorrer no meio de uma resposta, a IA pode fornecer informações incompletas.
Fizemos testes com o arquivo da Serenatto e identificamos que um chunk size de 1.200 caracteres funciona bem. Esse valor permite uma separação adequada sem comprometer a integridade do conteúdo.
Além disso, podemos ajustar o chunk overlap (sobreposição de pedaços) para evitar perda de informações, mas falaremos disso posteriormente.
from llama_index.core.node_parser import SentenceSplitter
node_parser = SentenceSplitter(chunk_size=1200)
A divisão correta do documento permite que cada página seja transformada em um nó separado. Após executar a célula acima, criaremos a variável nodes e utilizaremos o método get_nodes_from_documents() com o parâmetro show_progress=True para acompanhar a execução. O resultado confirma a separação em 10 nós, correspondendo às 10 páginas do PDF.
nodes = node_parser.get_nodes_from_documents(docs, show_progress=True)
Retorno:
Parsing nodes: 100% 10/10 [00:00<?, 198.87/s]
Conferindo os blocos gerados
Para validar a separação, verificaremos a quantidade de nós gerados, que corresponde à quantidade de páginas do PDF:
len(nodes)
Retorno:
10
Verificaremos o primeiro nó, nodes[0], que contém o ID, os metadados e o texto inicial do documento até o preço do último café da página.
nodes[0]
Retorno:
TextNode(id_='32d5ba7b-2aa6-4a37-8ff2-f70dcd2bed68', embedding=None, metadata={'page_label': '1', 'file_name': 'serenatto_cafes_especiais.pdf', 'file_path': '/content/documentos/serenatto_cafes_especiais.pdf', 'file_type': 'application/pdf', 'file_size': 133957, 'creation_date': '2025-02-17', 'last_modified_date': '2025-02-17'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='23d1536a-08af-46ba-82c0-c565f1d3a838', node_type=<ObjectType.DOCUMENT: '4'>, metadata={'page_label': '1', 'file_name': 'serenatto_cafes_especiais.pdf', 'file_path': '/content/documentos/serenatto_cafes_especiais.pdf', 'file_type': 'application/pdf', 'file_size': 133957, 'creation_date': '2025-02-17', 'last_modified_date': '2025-02-17'}, hash='820b277edf233136c5afd69d8b63f74658d9de4c25893c4e5d205bcb010e8b2e')}, metadata_template='{key}: {value}', metadata_separator='\n', text='… R: Trabalhamos com as seguintes variedades de café em grãos: ● Bourbon vermelho ● Bourbon amarelo ● Blend especial (Mistura de Bourbon amarelo e vermelho) ● Catuaí amarelo ● Geisha ● Yirgacheffe P: Quais são os preços de cada variedade de café? R: Os preços sãos os seguintes: ● Bourbon vermelho: R$ 41,00 ● Bourbon amarelo: R$ 43,00 ● Blend especial: R$ 37,50 ● Catuaí amarelo: R$ 55,00 ● Geisha: R$ 105,00 ● Yirgacheffe: R$ 110,00', mimetype='text/plain', start_char_idx=0, end_char_idx=1515, metadata_seperator='\n', text_template='{metadata_str}\n\n{content}')
Já o último nó, nodes[9], inclui informações sobre armazenamento e validade, correspondendo à última página do PDF.
nodes[9]
Retorno:
TextNode(… {value}', metadata_separator='\n', text='… \nNo\n \nentanto,\n \ndepois\n \nde\n \naberto,\n \no\n \nconsumo\n \ndeve\n \nser,\n \nde\n \npreferência,\n \nentre\n \nduas\n \n(quando\n \nestiver\n \nmoído)\n \na\n \nquatro\n \nsemanas\n \n(em\n \ngrãos)\n \nda\n \ndata\n \nda\n \ntorra.', mimetype='text/plain', start_char_idx=0, end_char_idx=884, metadata_seperator='\n', text_template='{metadata_str}\n\n{content}')
Isso confirma que o conteúdo foi segmentado corretamente. Se alguém perguntar sobre armazenamento, por exemplo, a IA acessará diretamente o nó correspondente, otimizando a busca.
Próximos passos
Com os blocos definidos, podemos armazenar o conteúdo em um banco de dados. Isso permitirá que a IA recupere informações de forma eficiente.
Sobre o curso LlamaIndex: criando um chatbot com a técnica RAG
O curso LlamaIndex: criando um chatbot com a técnica RAG possui 163 minutos de vídeos, em um total de 53 atividades. Gostou? Conheça nossos outros cursos de IA para Dados em Inteligência Artificial, ou leia nossos artigos de Inteligência Artificial.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Preparando os dados
- Criando a base de dados vetorial
- Recuperando as informações
- Criando fluxos RAG com Langflow
- Finalizando e publicando o projeto