Olá a todos! Meu nome é Guilherme Silveira, sou instrutor e co-fundador da Alura, e serei seu instrutor nesta jornada!
Audiodescrição: Guilherme se descreve como uma pessoa branca, de cabelos curtos e grisalhos, e olhos castanhos. Veste uma camiseta vermelha e está em um estúdio de gravação iluminado em tons de azul e roxo. À direita, uma estante com itens decorativos; à esquerda, uma planta.
Neste curso, faremos uma introdução sobre aprendizado de máquina, abordando tanto aspectos práticos quanto teóricos. Vamos observar o processo em ação, fazer a máquina aprender e entender por que chamamos isso de aprendizado de máquina. Por que afirmamos que a máquina está aprendendo algo? Qual é a base dessa afirmação? O que está acontecendo nos bastidores? Embora a máquina não aprenda da mesma forma que um ser humano, faremos analogias com o aprendizado humano. O que realmente importa é se a máquina será capaz de nos auxiliar com os modelos computacionais que criamos para atingir nossos objetivos.
Para isso, utilizaremos uma das bibliotecas mais importantes do aprendizado de máquina na computação atualmente, o Scikit Learn, em Python. Vamos explorar quatro projetos distintos dentro da área de aprendizado de máquina supervisionado.
Nesse contexto, passaremos por todas as etapas: desde o carregamento dos dados, limpeza, tratamento, análise, treinamento do modelo, avaliação do que funciona e do que não funciona, aprimoramento do modelo e compreensão das decisões tomadas pelo modelo. Além disso, exploraremos diferentes tipos de modelos computacionais para entender as particularidades de cada um.
Nosso objetivo aqui não será aprofundar em cada uma dessas áreas, mas sim entender o processo na totalidade para você seja capaz de aplicá-lo. Assim, ao encontrar dificuldades, você poderá se aprofundar nas áreas específicas que precisar.
Por exemplo, se em um projeto você tiver dificuldades devido ao grande volume de dados, poderá se especializar em lidar com grandes volumes de dados. Se o desafio for uma série temporal, poderá se aprofundar em séries temporais. Assim, você se especializará conforme as necessidades do seu dia a dia.
Para começar, precisamos entender o funcionamento do pipeline, ou seja, o processo completo do aprendizado de máquina. Vamos nessa?
Olá, pessoal! Vamos começar?
A ideia que queremos apresentar aqui é um exemplo de inteligência artificial com aprendizado de máquina. Para isso, vamos primeiro refletir sobre uma das formas como nós, seres humanos, aprendemos, para depois abordarmos o aprendizado de máquina.
Vamos observar esta imagem:

Ao observá-la, uma pessoa geralmente nota que há um porco. Isso, porque, em algum momento, aprendemos que esse animal é um porco. Como aprendemos, como seres humanos, que esse animal é um porco? Vamos refletir sobre isso.
Quando meu filho tinha 4 anos e viu um porco pela primeira vez, dissemos a ele que se tratava de um porquinho, que costuma emitir o som "óinc, óinc". Quando ele viu o mesmo porquinho novamente, não se lembrou imediatamente. Então mais uma vez dissemos a ele que se tratava de um porquinho, que costuma emitir o som "óinc, óinc".
Na terceira vez que avistou o animal, ele mesmo disse: "óinc, óinc!", em analogia ao som que o animal costuma fazer. Então, à medida que continuamos mostrando porquinhos para o meu filho, ele começou a associar o som "óinc, óinc" ao animal porco. Assim, toda vez que ele vê um porquinho, diz "porquinho, óinc, óinc". Ou seja, ele associou as características desse animal.
Quando meu filho viu um cachorro pela primeira vez, ele já tinha visto muitos porquinhos. Então, ao ver o cachorro, ele disse: "porquinho, óinc, óinc!". Afinal, ele ainda não conhecia a palavra "cachorro", "cão", "cadela" ou "au-au". Nós dissemos a ele que não era um porquinho, mas um cachorro, que faz "au-au". Ele então repetiu: "au-au". Assim, ao ver um cachorro pela terceira vez, ele disse "au-au", pois começou a entender o padrão.
Como seres humanos, classificamos animais como porcos ou cachorros com base em suas características. Temos, então, um problema de classificação com duas categorias, ou classes: porco e cachorro. Aprendemos a fazer essa distinção porque, desde cedo, alguém nos ensinou: "Isso é um porquinho, isso é um cachorro". Esse aprendizado supervisionado nos ajudou a diferenciar entre as duas classes.
Esse problema de classificar porcos e cachorros é um exemplo de classificação binária, onde temos dois valores possíveis, como 0 ou 1. Da mesma forma, podemos classificar e-mails como "spam" ou "não spam", que também é um problema de classificação binária.
Neste curso, vamos abordar vários problemas de classificação binária para aprender os diversos processos envolvidos no aprendizado de máquina supervisionado. Um exemplo de problema de classificação binária é: "Recebi uma mensagem no WhatsApp dizendo que meu filho mudou o número de telefone, é golpe ou não é golpe?". Todos esses são problemas de classificação binária, e vamos explorar esses tipos de problemas para entender todo o processo.
Vamos ver como a máquina pode começar a fazer isso, assim como nós aprendemos a fazer?

Temos uma lista de vários animais e sabemos identificar que os três primeiros são porcos e os três últimos são cachorros. Isso, porque, somos nós que estamos ensinando. No aprendizado supervisionado, quem supervisiona o aprendizado conhece as classes dos elementos que estão sendo usados para ensinar. Neste caso, vamos treinar a máquina.
Cada uma dessas fotos, ou cada um desses animais, possui características, conhecidas como features. Por exemplo, um porco tem certas características. Uma delas pode ser o comprimento do pelo: é longo ou curto?
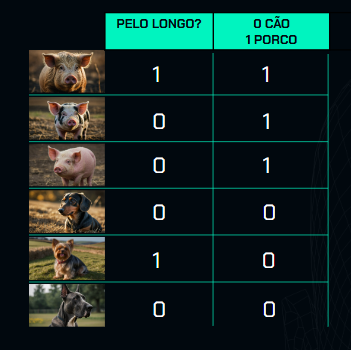
Se o primeiro porco tem pelo longo, marcamos 1 para indicar "sim". Se o segundo porco não tem pelo longo, marcamos 0 para indicar "não". Fazemos o mesmo para o terceiro porco e para os cachorros. Assim, usamos 0 ou 1 para indicar se uma característica está presente ou não em cada animal. Além disso, temos uma coluna que nos diz se o animal é um cão ou um porco.
Portanto, o aprendizado supervisionado envolve características como o comprimento do pelo e uma classificação, como "cão" ou "porco", em um problema de classificação.
Vamos adicionar outra característica: perna curta.
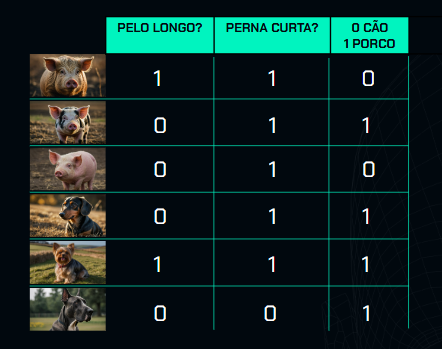
Observe que, nas fotos desses animais, quase todos têm perna curta, então marcamos 1 para todos, exceto para o último cachorro, que tem pernas longas, então marcamos 0 para ele. Assim, cada animal agora tem duas características e sua classificação.
Vamos adicionar mais uma característica: faz au-au.
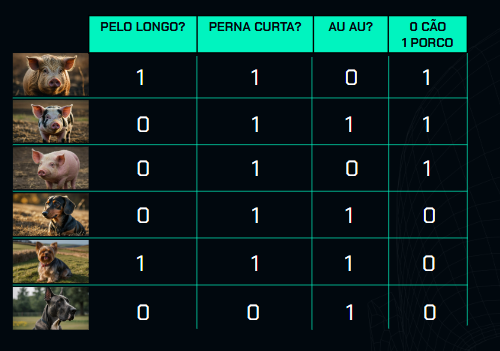
O primeiro porquinho não faz au-au, então marcamos 0. O segundo porquinho faz au-au, então marcamos 1. Pode ser que haja um porquinho que faça au-au, ou talvez a pessoa que preencheu os dados tenha cometido um erro, mas vamos assumir que havia um porquinho que fazia au-au para complicar nosso sistema. O terceiro porquinho não faz au-au, então marcamos 0. Os três cachorros fazem au-au, então marcamos 1 para cada um deles.
Portanto, para cada animal, temos três características: pelo longo, perna curta e se faz au-au. E temos a classificação desses animais, pois estamos trabalhando com problemas de classificação em aprendizado supervisionado.
Os problemas de inteligência artificial e aprendizado de máquina podem incluir muitos outros tipos de problemas. Estamos abordando esses exemplos para aprender o processo geral.
Vamos considerar outro exemplo. Se mostrarmos a vocês um animal que não tem pelo longo, ou seja, tem pelo curto, e também tem pernas curtas, e não faz "au-au", o que seria? Um porco ou um cachorro? Nós, seres humanos, seríamos capazes de estimar se esse animal é um porco ou um cachorro.
Provavelmente, estimaríamos com 70% de certeza que é um porco, porque a maioria dos cachorros faz "au-au". Assim, diríamos que há 70% de chance de ser um porco e 30% de chance de ser um cachorro. E acertaríamos! 4
Nosso cérebro e a máquina são treinados para estimar a probabilidade de uma classificação. As características (features) determinam a classificação através de um estimador. Na computação, chamamos de estimador o mecanismo que faz essa estimativa.
Portanto, temos nossa tabela organizada e, embora não tenhamos certeza absoluta, temos uma estimativa. Utilizamos essas estimativas para prever resultados em diversas áreas baseadas em classificação.
Neste curso, vamos explorar várias funcionalidades. Por exemplo, "pelo longo", "perna curta" e "faz au-au" são características, ou features. Vamos também identificar os itens, que é cada um dos animais, ou seja, cada linha da nossa tabela.
Também precisamos testar. Assim como queremos testar se alguém aprendeu as cores, no aprendizado de máquina, queremos testar se a máquina conseguiu aprender os padrões. Precisamos medir a qualidade do aprendizado da máquina. Aplicamos uma prova e atribuímos uma nota para avaliar se a máquina está atendendo às nossas expectativas.
Além disso, precisamos otimizar, ou seja, escolher o melhor estimador. Por exemplo, se queremos estimar se alguém tem câncer, escolhemos o estimador que mais acerta, de acordo com a métrica que desejamos.
Com isso, seremos capazes de prever várias coisas, como a classificação de itens. Para isso, usaremos Python e diversas outras ferramentas!
Continuando o curso, a ideia agora é implementar o primeiro estimador. Vamos treinar e demonstrar o aprendizado de máquina em ação.
Para isso, utilizaremos o Google Colab, um ambiente onde é possível escrever código em Python sem a necessidade de instalação local.
Acessando o site do Colab pelo navegador, uma janela modal será exibida, na qual é possível criar um novo notebook (caderno), onde serão feitas anotações em Python. Esse notebook permitirá a escrita de código e texto.
Ao criar um novo notebook clicando no botão "Novo notebook", será gerado um espaço, chamado célula, para escrever códigos em Python.
Nela, podemos declarar a seguinte variável como exemplo:
porco1 = 15
Para executar uma célula de código, basta pressionar "Shift + Enter" ou clicar no botão de play à esquerda de cada célula. O código será executado na nuvem do Google, que se conectará a uma máquina virtual.
Após executar a célula de exemplo, outra será gerada abaixo dela. Nesse momento, voltaremos à primeira para definir os itens.
Cada item é uma linha que será utilizada para treinamento e aprendizado. O porco1 possui três características que adicionaremos numa lista ou array, representado por um par de colchetes:
porco1 = [0, 1, 0]
Isso indica que o primeiro porco não tem pelo longo (0), tem perna curta (1) e não faz "au, au" (0). Da mesma forma, definiremos porco2 e porco3 nas linhas seguintes, ainda na primeira célula:
porco1 = [0, 1, 0]
porco2 = [0, 1, 1]
porco3 = [1, 1, 0]
As features (características) são: pelo longo, perna curta e faz "au, au", onde 1 significa sim e 0 significa não. Vamos adicioná-las acima das variáveis dos porcos, em formato de comentário.
Para criar um comentário, basta adicionar uma cerquilha (
#) no início da linha.
# features [1 sim, 0 nao]
# pelo longo?
# perna curta?
# faz auau?
porco1 = [0, 1, 0]
porco2 = [0, 1, 1]
porco3 = [1, 1, 0]
Abaixo dos porcos, também definimos os três cachorros:
# features [1 sim, 0 nao]
# pelo longo?
# perna curta?
# faz auau?
porco1 = [0, 1, 0]
porco2 = [0, 1, 1]
porco3 = [1, 1, 0]
cachorro1 = [0, 1, 1]
cachorro2 = [1, 0, 1]
cachorro3 = [1, 1, 1]
Abaixo dos porcos e cachorros, ainda na mesma célula, os dados (que são os seis animais) serão armazenados em uma lista:
dados = [porco1, porco2, porco3, cachorro1, cachorro2, cachorro3]
Para o aprendizado supervisionado, é necessário definir as classes. Nesse caso, 1 representará porco e 0, cachorro.
# 1 -> porco, 0 -> cachorro
dados = [porco1, porco2, porco3, cachorro1, cachorro2, cachorro3]
classes = [1, 1, 1, 0, 0, 0]
A célula completa pode ser consultada abaixo:
# features [1 sim, 0 nao]
# pelo longo?
# perna curta?
# faz auau?
porco1 = [0, 1, 0]
porco2 = [0, 1, 1]
porco3 = [1, 1, 0]
cachorro1 = [0, 1, 1]
cachorro2 = [1, 0, 1]
cachorro3 = [1, 1, 1]
# 1 -> porco, 0 -> cachorro
dados = [porco1, porco2, porco3, cachorro1, cachorro2, cachorro3]
classes = [1, 1, 1, 0, 0, 0]
Vamos rodá-la com "Shift + Enter". Na linha seguinte, podemos executar a dados para consultar essa lista:
dados
Retorno:
[[0, 1, 0], [0, 1, 1], [1, 1, 0], [0, 1, 1], [1, 0, 1], [1, 1, 1]]
Em seguida, eliminaremos essa célula de consulta, clicando no ícone de lixeira chamado "Excluir célula", à sua direita.
Para ensinar a máquina, precisaremos de um estimador — ou seja, um modelo de máquina com algoritmos matemáticos que nunca calculou nada. Para isso, acessaremos a próxima célula e adicionaremos o modelo.
Para esse modelo, escolheremos um tipo de modelo de aprendizagem de máquina — no caso, o LinearSVC().
Precisamos importar esse modelo da biblioteca sklearn (scikit-learn). Para isso, escreveremos from sklearn.svm import LinearSVC acima do modelo.
from sklearn.svm import LinearSVC
modelo = LinearSVC()
Essa biblioteca já vem instalada no Google Colab. Caso queira instalá-lo na sua máquina, basta acessar o link abaixo:
Se rodarmos essa célula, nada ocorrerá. Abaixo do modelo, na mesma célula, temos que pedir ao modelo que treine com um .fit(dados), encaixando os dados no modelo de animal que ela possui.
Por ser um aprendizado supervisionado, também precisamos encaixar as classes às quais os animais são correspondentes. Com isso, solicitamos um treinamento com base nos dados e classes informadas.
from sklearn.svm import LinearSVC
modelo = LinearSVC()
modelo.fit(dados, classes)
Após rodar o treinamento com "Shift + Enter", o modelo terá conhecido alguns animais. Após isso, podemos realizar previsões.
Por exemplo, para um animal misterioso com características [0, 1, 1], pediremos que o modelo preveja se é um cachorro ou um porco com o predict(). Como queremos somente um animal, informaremos entre os parênteses uma lista que terá somente o animal misterioso:
animal_misterioso = [0, 1, 1]
previsao = modelo.predict([animal_misterioso])
Após executar essa célula, o modelo prevê que este animal de pelos curtos, pernas curtas e que faz "au, au" é um cachorro (0).
Conseguimos treinar o modelo nos dados e classes, de forma supervisionada e realizar o primeiro teste. Contudo, um único teste não é o suficiente: precisamos de uma nota para saber se o algoritmo está bem treinado ou não.
Numa prova, calculamos a nota fornecendo exercícios e contando o percentual de acertos. Aplicaremos esse cálculo no modelo
Para calcular a acurácia, criaremos três animais de teste que terão uma lista de características. Em seguida, adicionaremos os animais em uma lista.
Por fim, pediremos ao modelo que faça previsões, por meio de um modelo.predict() dos testes.
misterio1 = [1, 1, 1]
misterio2 = [1, 1, 0]
misterio3 = [0, 1, 1]
testes = [misterio1, misterio2, misterio3]
previsoes = modelo.predict(testes)
Após rodar a célula, informaremos na célula seguinte que as classes reais para os testes são 0, 1 e 1 (cachorro, porco e porco). Antes disso, o modelo não sabia essas classes e tentou prever.
testes_classes = [0, 1, 1]
Após executar essa célula, conferiremos as estimativas do modelo antes de saber as respostas:
previsoes
array([0, 1, 0])
Ele errou uma classe de três. Ou seja, a taxa de acerto, que chamamos de acurácia, está em 66,6%.
Para chegar a esse número, tentaremos comparar cada elemento de previsoes com testes_classes.
previsoes == testes_classes
Retorno:
array([True, True, False])
A partir desse retorno, contaremos o total de respostas verdadeiras, somando o previsoes == testes_classes.
(previsoes == testes_classes).sum()
Retorno
2
O resultado é dois, pois verdadeiros valem 1 e falsos valem 0. Ou seja, este comando equivale aos corretos.
corretos = (previsoes == testes_classes).sum()
total = len(testes)
previsoes = modelo.predict(testes)
O total é a quantidade de testes — ou seja, len(testes). Já a taxa_de_acerto (acurácia) equivale ao corretos dividido pelo total e multiplicado por 100.
Por fim, imprimiremos a acurácia digitando taxa_de_acerto.
previsoes = modelo.predict(testes)
len(testes)
taxa_de_acerto = corretos / total * 100
taxa_de_acerto
Retorno:
66.6666666666666
Para imprimir melhor, substituiremos o taxa_de_acerto por um print(f"Acurácia: {taxa_de_acerto:.2f}%"), onde f informa que usamos uma variável dentro do texto, e :.2f informa que queremos o resultado com duas casas decimais.
previsoes = modelo.predict(testes)
len(testes)
taxa_de_acerto = corretos / total * 100
print(f"Acurácia: {taxa_de_acerto:.2f}%")
Retorno:
Acurácia: 66.67%
Conseguimos treinar um modelo com alguns itens e prever sua acurácia, o que é fundamental para algoritmos de aprendizado supervisionado. A seguir, vamos melhorar e explorar outros exemplos.
O curso Machine Learning: classificação com SKLearn possui 133 minutos de vídeos, em um total de 43 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






