Machine Learning parte 1: otimização de modelos através de hiperparâmetros
Hiperparâmetros, overfit e otimização copy 5 - Introdução
Bem vindo ao curso "Machine Learning: Otimização de modelos através de hiperparâmetros". Como pré-requisito, você deve ter feito alguns cursos de Machine Learning, como o curso de classificação e o curso de validação cruzada - dois conceitos que utilizaremos na otimização de parâmetros dos nossos estimadores.
Nos outros cursos, nós já estudamos uma árvore de decisão e aprendemos que é possível estabelecer uma profundidade máxima para essa árvore. Por exemplo, uma árvore de decisão padrão do SKLearn pode ter max_depth = 2, ou seja, a árvore fará duas perguntas antes de tomar a decisão de qual classificação será aplicada a determinados dados.
Com isso, podemos ter um bom resultado. Se fizermos max_depth = 3, a árvore criada será mais complexa, e podemos ter um resultado ainda melhor.
Isso significa que, antes de treinarmos o modelo, o algoritmo que irá aprender e gerar a árvore de decisão tem um parâmetro - por exemplo, max_depth. A medida que esse parâmetro é fixado, podemos treiná-lo e testá-lo para verificar quão bons são os resultados. Mas se max_depth = 3 é melhor do que max_depth = 2, por que não utilizamos logo max_depth = 10? Ou até mesmo max depth = 64?
Suponha que estamos tentando resolver um problema de classificação com accuracy. No primeiro teste, com uma árvore de decisão de max_depth = 2, temos um índice de 75% de acerto. Já com max_depth = 3, esse índice sobe para 78%. Como esse número aumentou, uma conclusão lógica seria que, quanto maior o max_depth, melhor será o nosso índice de acerto. Mas será que isso é verdade?
Nesse mesmo problema, utilizamos max_depth = 64 e o resultado foi um índice menor, de 72%. Isso significa que o treino da árvore é claramente influenciado pelo max_depth. Apesar dos treinos cada vez melhores, veremos que, em determinado momento, os testes começam a ficar cada vez piores.
Ao longo desse curso aprenderemos sobre um tipo de situação chamada de overfitting: quando o nosso modelo fica "viciado" no treino e ruim para os testes.
Até o momento, estamos explorando um único parâmetro e em uma única dimensão - nesse caso, uma dimensão discreta (1, 2, 3, 4, (...), 64, ou valores até maiores).
Devemos tomar cuidado, pois se cada um dos valores desse hiperparâmetro levar 5 minutos para ser rodado, um hiperparâmetro com 64 parâmetros levará 5 horas e meia para terminar sua execução. Nesses casos, existem várias opções, como paralelizar ou rodar apenas um trecho do hiperparâmetro - e algumas dessas opções nós testaremos aqui, como explorar o grid pedaço por pedaço. É uma estratégia possível, mas que não necessariamente garante que encontraremos o melhor estimador/modelo possível.
Além disso, nesse curso, abordaremos árvores de decisão com mais parâmetros (dois, três e até mesmo quatro). A partir de dois parâmetros (max_depth e min_samples_leaf, por exemplo), será realmente gerado um grid para explorarmos.
Aprendendo a importância de explorar o espaço de parâmetros e como eles podem influenciar a qualidade do nosso modelo de acordo com a métrica escolhida (no nosso exemplo, accuracy, pois estamos trabalhando com classificação padrão), passaremos a usar o próprio SKLearn com GridSearchCV e tirando proveito de validação cruzada. Nós iremos discutir também as limitações do SKLearn (geradas por limites de features ou por features que serão implementadas no futuro).
Com tudo isso, entenderemos como escolher o melhor modelo para nossos dados.
Hiperparâmetros, overfit e otimização copy 5 - Entendendo o que é um parâmetro
O projeto que utilizaremos neste curso é uma continuação do projeto no qual trabalhos no curso de validação cruzada (Cross-validation). Mesmo que você tenha feito o curso, é recomendável utilizar o projeto disponibilizado pelo instrutor, pois foram feitos alguns ajustes para simplificá-lo de acordo com o que será necessário.
Se você ainda não fez o curso de validação cruzada, não deixe de verificar se já conhece o conteúdo que, afinal trata-se de um pré-requisito para este curso.
Para escrevermos os códigos, usaremos o Google Colab, mas você também pode usar o Jupyter localmente. Na aba "Upload", subiremos o arquivo Introdução_a_Machine_Learning_Otimização.ipynb, o mesmo no qual estávamos trabalhando nos cursos anteriores.
Então, rodaremos o trecho do código que tenta ler o csv da internet para carregar os dados.
import pandas as pd
uri = "https://gist.githubusercontent.com/guilhermesilveira/e99a526b2e7ccc6c3b70f53db43a87d2/raw/1605fc74aa778066bf2e6695e24d53cf65f2f447/machine-learning-carros-simulacao.csv"
dados = pd.read_csv(uri).drop(columns=["Unnamed: 0"], axis=1)
dados.head()
Isso fará com que o seguinte trecho de tabela seja exibido:
| preco | vendido | idade_do_modelo | km_por_ano | |
|---|---|---|---|---|
| 0 | 30941.02 | 1 | 18 | 35085.22134 |
| 1 | 40557.96 | 1 | 20 | 12622.05362 |
| 2 | 89627.50 | 0 | 12 | 11440.79806 |
| 3 | 95276.14 | 0 | 3 | 43167.32682 |
| 4 | 117384.68 | 1 | 4 | 12770.11290 |
Cada linha dos dados representa um veículo à venda em um site fictício de vendas de automóveis. A primeira coluna representa o preço de cada veículo; a segunda, se ele foi vendido ou não; a terceira, quantos anos esse modelo tem; e a última, a média de KM esse carro rodou por ano.
Temos 3 colunas de informação (nossas features) e 1 coluna de classificação entre sim e não, que é a coluna relativa à venda do carro. Imagine que essa tabela foi gerada baseando-se no status de venda dos carros em um período de 6 meses após entrarem na plataforma, e queremos verificar se um modelo treinado é capaz de aprender isso.
Antes de treinarmos o modelo, nós tentamos, de propósito, ordenar os dados de uma maneira que não ajuda nesse treinamento. Nesse caso, eles foram ordenados de acordo com a coluna vendido - primeiro os veículos que não foram vendidos, e depois os que foram vendidos.
Isso instigou a necessidade de utilizarmos a validação cruzada.
# situação horrível de "azar" onde as classes estão ordenadas por padrão
dados_azar = dados.sort_values("vendido", ascending=True)
x_azar = dados_azar[["preco", "idade_do_modelo","km_por_ano"]]
y_azar = dados_azar["vendido"]
dados_azar.head()
| preco | vendido | idade_do_modelo | km_por_ano | |
|---|---|---|---|---|
| 4999 | 74023.29 | 0 | 12 | 24812.80412 |
| 5322 | 84843.49 | 0 | 13 | 23095.63834 |
| 5319 | 83100.27 | 0 | 19 | 36240.72746 |
| 5316 | 87932.13 | 0 | 16 | 32249.56426 |
| 5315 | 77937.01 | 0 | 15 | 28414.50704 |
Com esses dados ordenados, utilizamos o DummyClassifier() para obtermos uma linha de base - ou seja, quão bom bom um modelo é capaz de ser sem que precisássemos fazer muita coisa. O DummyClassifier() é uma boa alternativa nesses casos, principalmente pois, por padrão, ele já é estratificado, utilizando a proporção de 0 e 1 que aparecem nos dados para tentar fazer um julgamento - se aparecem muitos 0, ele vai tentar muitos 0; se aparecem muitos 1, tentará muitos 1.
Esse código já foi atualizado para usar cross_validate() (validação cruzada).
from sklearn.model_selection import cross_validate
from sklearn.dummy import DummyClassifier
import numpy as np
SEED = 301
np.random.seed(SEED)
modelo = DummyClassifier(strategy='stratified')
results = cross_validate(modelo, x_azar, y_azar, cv = 10, return_train_score=False)
media = results['test_score'].mean()
desvio_padrao = results['test_score'].std()
print("Accuracy com dummy stratified, 10 = [%.2f, %.2f]" % ((media - 2 * desvio_padrao)*100, (media + 2 * desvio_padrao) * 100))
Não se esqueça de adicionar a linha
import numpy as np, do contrário o código retornará um erro!
Rodando o código, o console retornará "Accuracy com dummy stratified, 10 = [49.79, 53.45]" - ou seja, tivemos um intervalo entre aproximadamente 49 e 53.
Em seguida, rodamos os mesmos dados (com x_azar, y_azar e cross_validate()) no DecisionTreeClassifier(). Na prática, às vezes utilizamos um DummyClassifier() como linha de base, e às vezes escolhemos um algoritimo simples para essa mesma função. Pode ser preferível rodar os dois, tanto um dummy quanto um algoritmo mais inteligente, pois existem situações em que o algoritmo mais inteligente realmente não se encaixa com aquele modelo.
from sklearn.model_selection import cross_validate
from sklearn.tree import DecisionTreeClassifier
SEED = 301
np.random.seed(SEED)
modelo = DecisionTreeClassifier(max_depth=2)
results = cross_validate(modelo, x_azar, y_azar, cv = 10, return_train_score=False)
media = results['test_score'].mean()
desvio_padrao = results['test_score'].std()
print("Accuracy com cross validation, 10 = [%.2f, %.2f]" % ((media - 2 * desvio_padrao)*100, (media + 2 * desvio_padrao) * 100))
Rodando esse código, retornamos uma taxa bem melhor, entre 73 e 77.
Accuracy com cross validation, 10 = [73.83, 77.73]
No segundo curso de Machine Learning, uma das formas que trabalhamos foi agrupando os carros por modelos. Como os dados são fictícios, nós criamos juntos o modelo do carro. Utilizamos um código para geração aleatória de informações (mas de maneira replicável) para definirmos a coluna "modelo".
# gerando dados aleatórios de modelo de carro para simulação de agrupamento ao usar nosso estimador
np.random.seed(SEED)
dados['modelo'] = dados.idade_do_modelo + np.random.randint(-2, 3, size=10000)
dados.modelo = dados.modelo + abs(dados.modelo.min()) + 1
dados.head()
| preco | vendido | idade_do_modelo | km_por_ano | modelo | |
|---|---|---|---|---|---|
| 0 | 30941.02 | 1 | 18 | 35085.22134 | 18 |
| 1 | 40557.96 | 1 | 20 | 12622.05362 | 24 |
| 2 | 89627.50 | 0 | 12 | 11440.79806 | 14 |
| 3 | 95276.14 | 0 | 3 | 43167.32682 | 6 |
| 4 | 117384.68 | 1 | 4 | 12770.11290 | 5 |
A coluna "modelo" indica qual é o modelo de cada carro - uma variável categoria, na qual os elementos da amostra não possuem relação entre si. O modelo não foi utilizado para tentarmos prever o valor do carro, mas sim para verificar, dado que treinamos o algoritmo em diversos modelos de carro, quão bom ele seria em prever novos modelos de carros.
Ou seja, a coluna "modelo" não é utilizada como uma feature (no nosso x, que continua sendo x_azar), mas para agrupar os nossos dados.
Criamos uma função de resultados:
def imprime_resultados(results):
media = results['test_score'].mean() * 100
desvio = results['test_score'].std() * 100
print("Accuracy médio %.2f" % media)
print("Intervalo [%.2f, %.2f]" % (media - 2 * desvio, media + 2 * desvio))
E rodamos uma validação cruzada que agrupa pelo modelo do carro. Em seguida, rodamos o DecisionTreeClassifier().
# GroupKFold para analisar como o modelo se comporta com novos grupos
from sklearn.model_selection import GroupKFold
SEED = 301
np.random.seed(SEED)
cv = GroupKFold(n_splits = 10)
modelo = DecisionTreeClassifier(max_depth=2)
results = cross_validate(modelo, x_azar, y_azar, cv = cv, groups = dados.modelo, return_train_score=False)
imprime_resultados(results)
Como resultado, obtemos Accuracy médio 75.78 e Intervalo [73.67, 77.90], o que quer dizer que o algoritmo generalizou bem, assim como se não fosse um modelo novo.
Mais tarde, também fizemos classificação com base no SVC (Support Vector Machine).
# GroupKFold em um pipeline com StandardScaler e SVC
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
SEED = 301
np.random.seed(SEED)
scaler = StandardScaler()
modelo = SVC()
pipeline = Pipeline([('transformacao',scaler), ('estimador',modelo)])
cv = GroupKFold(n_splits = 10)
results = cross_validate(pipeline, x_azar, y_azar, cv = cv, groups = dados.modelo, return_train_score=False)
imprime_resultados(results)
Nós utilizamos duas vezes o desvio padrão da nossa validação de 10 folds. Como resultado, tivemos:
Accuracy médio 76.68
Intervalo [74.28, 79.08]
No próximo passo, vamos utilizar o DecisionTreeClassifier(). Vamos jogar a célula referente a esse código para baixo e rodá-lo novamente, obtendo a variável modelo, que é justamente o nosso DecisionTreeClassifier().
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
Agora queremos visualizar essa árvore. Para isso, utilizaremos o Graphviz (import graphviz), uma biblioteca que já utilizamos no passado. Também importaremos o export_graphviz de sklearn.tree.
Chamaremos o export_graphviz() para o nosso modelo, definindo que não queremos jogar nenhum arquivo (out_file=None), queremos preencher os retângulos de visualização da árvore de decisão (filled=True), queremos arredondá-los (rounded=True), queremos que os nomes das classes sejam "não" e "sim" (class_names=["não","sim"], de "não foi vendido" e "sim, foi vendido") e queremos que os nomes das features sejam os nomes das colunas de x na nossa tabela (feature names = features e features = x_azar.columns).
Exportar a visualização devolve dados chamados de dot_data. Finalmente, queremos que o Graphviz utilize dot_data como fonte (graphviz.Source()) e imprima esse gráfico, o que é feito chamando o atributo graph.
from sklearn.tree import export_graphviz
import graphviz
features = x_azar.columns
dot_data = export_graphviz(modelo, out_file=None, filled=True, rounded=True,
class_names=["não", "sim"],
feature_names = features)
graph = graphviz.Source(dot_data)
graph
Para utilizarmos o Graphviz, precisamos primeiro instalá-lo no início do nosso código. Para isso, usaremos !pip install graphviz=0.9. Também usaremos !pip install pydot. Por fim, o Graphviz também precisa ser instalado com !apt-get install graphviz.
!pip install graphviz==0.9
!pip install pydot
!apt-get install grapviz
Da primeira vez que rodarmos esse código, será necessário baixar e instalar tanto os pacotes do Python quanto os pacotes nativos do apt-get, portanto isso levará algum tempo.
Agora, quando rodarmos o código para imprimir a visualização da nossa árvore de decisão... teremos um erro dizendo que nossa árvore de decisão ainda não foi treinada.
NotFittedError: This DecisionTreeClassifier instance is not fitted yet. Call 'fit' with appropriate arguments before using this method.
Porém, nós fizemos a validação cruzada desse modelo, certo? Na verdade, quando fazemos 10 vezes a validação cruzada, resultamos em 10 modelos diferentes. E qual desses 10 modelos queremos usar? Essa é uma pergunta delicada, e a resposta é que não queremos utilizar nenhum deles. Na validação cruzada, nós treinamos o algoritmo 10 vezes para termos uma estimativa de quão bem esse modelo funcionaria no mundo real. Agora queremos o modelo propriamente dito para utilizarmos na vida real.
Portanto, vamos pegar nosso modelo e treiná-lo com x_azar e y_azar.
from sklearn.tree import export_graphviz
import graphviz
modelo.fit(x_azar, y_azar)
features = x_azar.columns
dot_data = export_graphviz(modelo, out_file=None, filled=True, rounded=True,
class_names=["não", "sim"],
feature_names = features)
graph = graphviz.Source(dot_data)
graph
Assim, finalmente teremos a visualização da nossa árvore de decisão.
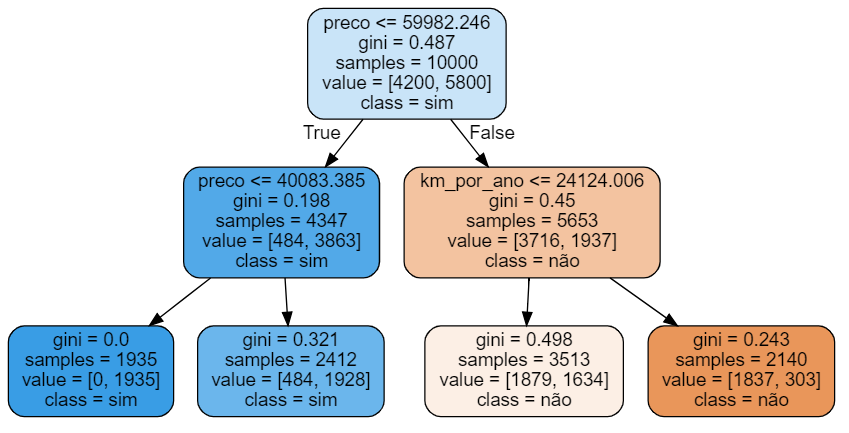
Mas repare que essa árvore não é muito profunda, já que possui apenas duas decisões. E se colocássemos três níveis de profundidade? A profundidade máxima é justamente um dos parâmetros que um classifier, como DecisionTreeClassifier(), pode receber. Para testarmos isso, vamos rodar novamente nosso classifier, dessa vez com max_depth=3.
from sklearn.model_selection import GroupKFold
SEED = 301
np.random.seed(SEED)
cv = GroupKFold(n_splits = 10)
modelo = DecisionTreeClassifier(max_depth=3)
results = cross_validate(modelo, x_azar, y_azar, cv = cv, groups = dados.modelo, return_train_score=False)
imprime_resultados(results)
Dessa vez, nosso resultado será:
Accuracy médio 78.67
Intervalo [76.40, 80.94]
Exportando novamente a visualização, teremos uma árvore com até 3 níveis de comparações e a decisão final. Além disso, nosso resultado foi ainda melhor.
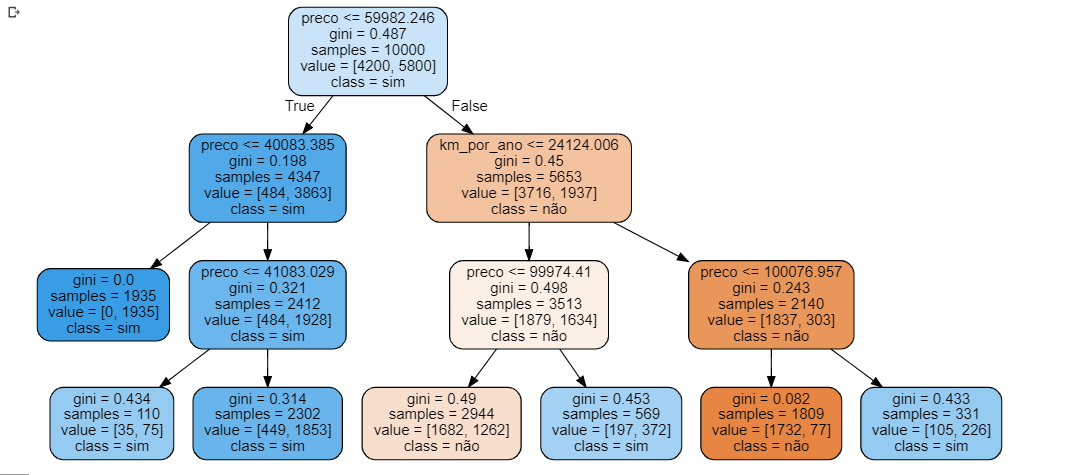
Será então que, quanto maior o max_depth, melhores serão os resultados? Para testar isso, vamos repetir o processo, dessa vez com max_depth=10.
Nosso resultado dessa vez será:
Accuracy médio 77.19
Intervalo [75.26, 79.13]
Ou seja, obtemos valores piores do que os que tínhamos conseguido anteriormente, e a visualização gerada é tão grande que mal cabe na tela do computador.
O ponto é: na documentação do SkLearn DecisionTreeClassifier encontramos a informação de que ele tem um parâmetro, chamado max_depth, que pode ser setado para o número que quisermos. Mas como escolhemos esse número, que influencia em quão bem o nosso algorítimo irá rodar?
Outros classificadores, como o SVC, também possuem parâmetros que interferem nos resultados do algorítimo. O nosso objetivo nesse curso é entendermos como escolher esses parâmetros para otimizar o nosso estimador. Vamos lá?
Hiperparâmetros, overfit e otimização copy 5 - Quanto mais complexa a árvore, melhor?
Anteriormente, aprendemos que podemos fornecer parâmetros para nossos estimadores/classificadores (como max_depth) antes de eles serem treinados. Parâmetros que são definidos antes do treino são chamados de hiperparâmetros, e são diferentes de valores internos do modelo que vão sendo alterados de acordo com o que o modelo está aprendendo.
Em nosso exemplo, utilizamos a profundidade máxima de uma árvore de decisão padrão do SkLearn. E qual valor escolheremos para ela? Antes de decidirmos, vamos testar diversos valores e prestar atenção no que acontece. Para isso, rodaremos o DecisionTreeClassifier() várias vezes, de 1 até 32.
Criaremos uma função roda_arvore_de_decisao() que roda a árvore de decisão para uma profundidade específica. Essa função será usada como parâmetro de max_depth.
Com isso, se chamarmos a árvore de decisão com 10, essa árvore será chamada até o máximo 10, e assim sucessivamente. Portanto, podemos fazer um for i in range() passando o intervalo 1,33 - ou seja, de 1 até 32, excluindo 33, e passar i como max_depth da função.
Também precisaremos mudar a função que exibe os resultados, pois imprime_resultados() não trará uma resposta facilmente legível e que ainda contém informações desnecessárias.
Nesse instante, vamos imprimir somente o tamanho do max_depth e a média do test_score:
from sklearn.model_selection import GroupKFold
def roda_arvore_de_decisao(max_depth):
SEED = 301
np.random.seed(SEED)
cv = GroupKFold(n_splits = 10)
modelo = DecisionTreeClassifier(max_depth=max_depth)
results = cross_validate(modelo, x_azar, y_azar, cv = cv, groups = dados.modelo, return_train_score=False)
print("max_depth = %d, media =%.2f" % (max_depth, results['test_score'].mean() * 100))
for i in range (1, 33):
roda_arvore_de_decisao(i)
Como resultado, teremos:
max_depth = 1, media =75.78
max_depth = 2, media =75.78
max_depth = 3, media =78.67
max_depth = 4, media =78.63
max_depth = 5, media =78.56
max_depth = 6, media =78.12
max_depth = 7, media =77.96
max_depth = 8, media =77.86
max_depth = 9, media =77.38
max_depth = 10, media =77.19
max_depth = 11, media =76.97
max_depth = 12, media =76.49
max_depth = 13, media =75.81
(...)
O que esperaríamos é que, quanto maior fosse a profundidade da árvore, mais decisões ela precisaria tomar e mais perfeito seria o seu treinamento em relação aos nossos testes. Porém, a partir de max_depth=3, que possui uma média 78.67, temos uma queda constante até max_depth = 32, que possui a média mais baixa, 72.52.
Isso acontece porque, quando treinamos a nossa árvore, ela aprende e cria as suas ramificações. Com profundidades muito grandes, a árvore se torna tão perfeita para os dados de treino que falha nos dados de teste - quase como se ela tivesse memorizado o teste.
Vamos verificar se é isso mesmo que está acontecendo?
Sobre o curso Machine Learning parte 1: otimização de modelos através de hiperparâmetros
O curso Machine Learning parte 1: otimização de modelos através de hiperparâmetros possui 104 minutos de vídeos, em um total de 34 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Hiperparâmetros, overfit e otimização
- Explorando 2 dimensões de hiperparâmetros
- Trabalhando com 3 ou mais dimensões
- Busca de parâmetros com o GridSearchCV
- Nested cross validation e validando o modelo escolhido