Olá! Eu sou a Ju Amoasei, instrutora de Javascript e Node da Alura.
Juliana é uma mulher branca, de olhos castanhos e cabelos curtos, lisos e pintados de azul. Em seu rosto, tem óculos com moldura fina e arredondada, na cor preta. Possui brincos e piercings nas duas orelhas e no nariz. Está de camiseta preta, a qual possui o logo da Alura acompanhado do texto “Escola de programação & DevOps”. Ao fundo, uma parede clara com iluminação roxa e um vaso de plantas à direita.
Recolheremos todo o conhecimento sobre Node que vimos anteriormente, como:
Vamos reuni-los com outras ferramentas usuais no dia-a-dia de um time de desenvolvimento. Com isso, pegaremos um projeto em andamento e trabalharemos nele, adicionando features, testes, novas ferramentas e assim por diante.
Pretendemos adquirir conhecimentos importantes para quando iniciamos o trabalho em um time de desenvolvimento, como, por exemplo:
Com isso, podemos integrar nosso código com aquele que já existe no nosso produto.
Este curso não é específico de Node, Docker, Github ou CI/CD (Integração e Entrega Contínuas), mas veremos um pouco de tudo. Simularemos uma situação de trabalho, onde temos um projeto pré-existente que possui sua própria stack, seus próprios ambientes e arquivos de configuração.
Conhecimentos em Node (disponíveis nas formações da plataforma)
Prática com API Rest
Manejo do Banco de Dados SQL e conexão com a API
PostgreSQL
SQLite
Biblioteca Kinex
Testes de unidade em Node
Princípios de Docker
Versionamento de código com Github
Caso esteja utilizando o Windows, é importante ter instalado em sua máquina e praticado com o WSL, um ambiente similar ao Linux que utilizamos dentro do Windows para executar alguns programas.
Sem ele, não podemos utilizar o Docker — a própria documentação da ferramenta recomenda o uso de WSL.
Para realizar os primeiros passos no Docker, consulte o curso sobre Docker, disponível na plataforma da Alura.
Caso queira saber como juntar o conteúdo dos cursos de Node e aprender sobre mais ferramentas de desenvolvimento utilizadas no dia-a-dia, este curso é para você.
Se já está no mercado de trabalho e faz parte de um time de desenvolvimento, já deve entender rotinas como criar branches, "mergear" o código, usar padrões de desenvolvimento e padrões de divisão de código.
Porém, apresentaremos ferramentas diferentes e bibliotecas para trabalharmos com Feature Flags, por exemplo.
É interessante conferir a ementa do curso e decidir se haverão novidades e se vale a pena seguir com ele.
No final deste curso, teremos praticado o ato de entrar num projeto em andamento e adicionar coisas nele. Vamos mergulhar no fluxo de trabalho do desenvolvimento e entender a base do seu funcionamento, que varia de acordo com cada time e cada empresa.
Com isso, você terá uma visão sobre possíveis melhoras que podem ser adicionadas no nosso projeto base.
Agora que alinhamos tudo, vamos começar a codar!
Este curso diferirá daqueles que compõem a formação de Node, pois não focaremos em codar uma API ou realizar uma tarefa específica. Em vez disso, juntaremos as partes que vimos até agora
Ao invés de começar um projeto do zero para ver uma ferramenta, aprenderemos a trabalhar em um projeto pronto. Aqui, leremos a documentação, entenderemos como o projeto funciona, instalar tudo que tiver nele e acrescentar coisas nele, tarefa comum no dia-a-dia do time de desenvolvimento.
Quando entramos em um time de desenvolvimento, na maioria das veze já temos um projeto no qual devemos criar funcionalidades e corrigir outras.
Antes de começar, certifique-se de conferir a atividade "Preparando o ambiente", onde deixamos todas as instruções para iniciar o projeto. É necessário que todas as instalações iniciais tenham sido feitas.
Como este projeto rodará num ambiente Docker, não precisamos de muitas instalações. Na teoria, nem a instalação do próprio Node é necessária, pois a criação do ambiente será feita por meio do Docker.
Neste momento, acessaremos o Github do nosso curso, onde adicionaremos um Fork para o nosso repositório pessoal. Para isso, clicaremos no botão "Fork", na região superior direita da página, abaixo da barra de tarefas principal.
Com o Fork gerado veremos, na região superior esquerda, a substituição do caminho "alura-cursos/2969-workflow-dev" pelo nome do seu repositório pessoal seguido de "/2969-workflow-dev".
Após essa etapa, criaremos uma cópia local do repositório na nossa máquina, clicando no botão "Code" e selecionando uma das três opções de formato: HTTPS, SSH ou Github CLI. Neste curso, utilizaremos o SSH, mas sinta-se livre para utilizar o HTTPS, se for o caso.
Copiaremos o link de repositório gerado pela opção selecionada. Acessaremos o terminal da máquina e navegaremos localmente até a pasta na qual queremos cloná-lo. Em seguida, rodaremos o comando git clone seguido do link de repositório copiado.
O atalho para colar no terminal é "Ctrl+Shift+V". O tradicional "Ctrl+C" não funciona nele.
Após o comando, o terminal clonará o repositório localmente. Com o repositório local pronto, concluímos a primeira etapa.
Antes de começar a trabalhar no código, voltaremos ao Github e acessaremos o arquivo README.md*, abaixo da lista de arquivos do projeto. Quando chegamos em um projeto, seja open source (código aberto) ou de uma empresa, esta é a primeira coisa que devemos fazer.
Isso é importante, pois parte do trabalho de desenvolvimento envolve a sua documentação. Sempre que adicionamos coisas novas, temos que documentá-las para as outras pessoas.
No "README" do nosso projeto, temos:
Na seção deste arquivo, temos uma pré-visualização dessa disposição de pastas e arquivos, na qual podemos ver a pasta "src" (por extenso, source), dentro da qual temos as pastas "controllers", "db", entre outras. Dentro de "db", temos as pastas "migrations" (migrações) e "seeds", o arquivos dbconfig (data base config), entre outros.
Por meio do nome dos arquivos e da estrutura de pastas, começamos a perceber como o projeto está estruturado. Caso você tenha feito o curso sobre a criação de APIs REST com Node, a estrutura de Controllers, Models e Rotas deve ser familiar, além da pasta "test", vista anteriormente nos cursos sobre Teste.
Ainda na estrutura de pastas, na pasta raiz temos arquivos de configuração, dentre os quais destacamos dois:
server.js que é o ponto de entrada do nosso projetopackage.json, o qual verificaremos posteriormenteAlém disso, o arquivo README.md carrega a seção "Instalação do projeto" com todas as instruções de instalação do projeto, em inglês ou português.
Caso você não tenha lido a seção "Instalação do projeto", recomendamos parar o vídeo agora mesmo, ler e executar os passos indicados para instalação (incluindo a instalação do Docker). Faremos isso na tela, mas é importante que você pratique a familiaridade com este processo.
Após a leitura do "README", voltaremos ao terminal, onde temos a cópia local do repositório. Nele, acessaremos o nosso repositório rodando o comando abaixo.
cd 2969-workflow-dev/Dica: Enquanto digitamos, podemos apertar "Tab" para que o terminal complete o comando.
Estamos dentro do diretório do projeto. Nele, rodaremos o comando abaixo, que abrirá o editor de código da nossa máquina (no nosso caso, o VS Code) direto na pasta do nosso projeto.
code .Traremos a tela do VS Code para frente, maximizando-a.
Dica: Para aumentar a fonte do editor, é possível digitar "Ctrl+," — o que abrirá a aba "Settings" ("Configurações") —, e digitar no campo intitulado "Editor: Font size" o tamanho de fonte desejado.
Acessaremos o explorador na lateral esquerda do VS Code, onde veremos a nossa estrutura de pastas. Na pasta raiz, acessaremos o arquivo package.json.
Caso precise revisitar as instruções do
README.md, acesse-o também pelo explorador, na pasta raiz.
Em um projeto que já existe, quais os primeiros itens a serem analisados no package.json?
A stack — ou seja, o conjunto de dependências, bibliotecas e pacotes que este projeto utiliza —, possui alguns itens já vistos em outros cursos, como o express, o knex e o pg (Postgres para Node).
"dependencies": {
"dotenv": "16.0.3",
"express": "4.18.1",
"knex": "^2.1.0",
"pg": "8.9.0"
}Abaixo das "dependencies", temos as "devDependencies" (dependências de desenvolvimento), dentre as quais veremos:
jest e o chai (bibliotecas de teste).sqlite (nosso banco de testes)eslint (biblioteca de linter ou organização de código que faz a primeira camada de teste estático) "devDependencies": {
"@jest/globals": "28.1.2",
"chai": "4.3.7",
"chai-http": "4.3.0",
"eslint": "8.32.0",
"eslint-config-airbnb-base": "15.0.0",
"eslint-plugin-import": "2.26.0",
"jest": "29.4.1",
"mocha": "10.2.0",
"nodemon": "2.0.16",
"sqlite": "4.1.1",
"sqlite3": "5.0.8"
}Os scripts servem para automatizar comandos. Temos como exemplo aqueles que automatizam comandos de teste para o Node.
Podemos criá-los conforme a nossa necessidade. Neste código, temos:
"drop-test-db", "test:mocha", "test:jest" e "test", que são executados em sequência"lint" para realizar o lint"dev" para subir o ambiente de desenvolvimento"migrate", "unmigrate" e "seed", relacionados a criar migrações do banco de dados para o banco de desenvolvimento e criar o seed (primeiros registros no banco). Ambas as tarefas têm relação com subir o ambiente de desenvolvimento. "scripts": {
"migrate": "npx knex --knexfile=./src/db/knexfile.js migrate:latest",
"unmigrate": "npx knex --knexfile=./src/db/knexfile.js migrate:rollback",
"seed": "npx knex --knexfile=./src/db/knexfile.js seed:run",
"dev": "npm install && npm run migrate && npm run seed && nodemon server.js",
"lint": "eslint --ignore-path .gitignore .",
"prepare-test-db": "sqlite3 ./src/test/livraria.sqlite < populate.sql",
"drop-test-db": "rm -f ./src/test/livraria.sqlite",
"test:mocha": "mocha ./src/test/routes/*.test.js",
"test:jest": "node --experimental-vm-modules node_modules/jest/bin/jest.js ./src/test/models/*.test.js --verbose",
"test": "npm rebuild && npm run drop-test-db && export NODE_ENV=test && npm run prepare-test-db && npm run test:mocha && npm run test:jest"
},Trabalhamos muito com os scripts "migrate", "unmigrate" e "seed" nos cursos de API REST com Sequelize.
Sabemos que o projeto utiliza uma estrutura de Model, Controler e Rota, familiar de outros cursos. Sabemos quais as bibliotecas e dependências utilizadas e também como instalar e executar o projeto através do "README".
Antes de continuar, vamos acessar o terminal para instalar o projeto e rodá-lo para ver se funciona.
Lembrando que este projeto será executado no ambiente Docker que estará na versão correta do Node. Desta forma, não será necessário instalar bancos de dados e seus drivers.
No terminal, já estamos acessando a pasta correta (nome do repositório + "/2969-workflow-dev"). Ali, rodaremos o comando sudo docker-compose up seguido do serviço desejado.
Para encontrar este serviço, voltaremos ao VS Code e buscaremos no explorador o arquivo de configuração docker-compose.yaml. Em seu interior, temos o bloco de serviços denominado services, dentro do qual temos os ambiente dev, seguido de outros.
Código completo do ambiente dev:
services:
dev:
build: .
container_name: livraria_api_dev
command: npm run dev
working_dir: /app
ports:
- "3000:3000"
volumes:
- ./:/app:cached
depends_on:
- db
- unleash
# Código omitidoVamos subi-lo, pois com isso subiremos também o db que é nosso banco de dados de desenvolvimento (Postgres).
O docker-compose.yaml é sucinto e nos informa tudo o que vai acontecer. Em dev, veremos que será dado o comando npm run dev, o qual também poderá ser encontrado na lista de scripts do arquivo package.json.
"dev": "npm install && npm run migrate && npm run seed && nodemon server.js",Portanto, este script rodará dentro do ambiente dev.
O dev ainda exporá a porta localhost:3000 para realizarmos testes.
ports:
- "3000:3000"Fora isso, ele possui o serviço db atrelado a si, que subirá outra imagem, como se fosse um servidor de banco de dados Postgres. Este executará e exporá a porta padrão do Postgres: 5432.
db:
image: postgres
container_name: livraria_db
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=admin123
- POSTGRES_DB=livraria_db
ports:
- "5432:5432"
# Código omitidoPortanto, o serviço desejado, no nosso caso, é o dev. Vamos adicioná-lo ao comando sudo docker-compose up e pressionar "Enter".
sudo docker-compose devApós isso, o terminal pedirá a nossa senha, já que estamos utilizando o sudo para ter todas as permissões que o Docker solicita. Vamos digitá-la e pressionar "Enter".
Neste momento, o Docker irá buildar (construir) o ambiente pelo terminal, realizando as instalações necessárias e recuperando o Node de um repositório do Docker na internet.
Ele também rodará os comandos atrelados ao script npm run dev e subirá no servidor utilizando o nodemon, recurso que já conhecemos em nossos estudos sobre APIs REST.
Por fim, ele exporá na porta "localhost:3000".
Servidor escutando em http://localhost:3000
Acessaremos o cliente que realizará os testes em API — neste caso, o Postman. Além deste, poderíamos utilizar o Insomnia, a extensão Thunder Client do VS Code ou qualquer outro que faça a mesma tarefa.
No Postman, podemos acessar os endpoints na rota localhost:300. Eles estão listados no arquivo "README", por isso retornaremos ao VS Code para acessá-lo.
Em seu interior, buscaremos a seção "Endpoints", na qual são listados todos os endpoints disponíveis para acesso com a nossa API.
### Endpoints
A API expõe os seguintes *endpoints* a partir da *base URL* `localhost:3000`:
`/livros`
* `GET /livros`
* `GET /livros/:id`
* `POST /livros`
* `PUT /livros/:id`
* `DELETE /livros/:id`
`/autores`
* `GET /autores`
* `GET /autores/:id`
* `GET /autores/:id/livros`
* `POST /autores`
* `PUT /autores/:id`
* `DELETE /autores/:id`
`/editoras`
* `GET /editoras`
* `GET /editoras/:id`
* `GET /editoras/:id/livros`
* `POST /editoras`
* `PUT /editoras/:id`
* `DELETE /editoras/:id`Nessa lista, temos três endpoints: /livros, /autores e /editoras. Todos realizam o CRUD (GET, POST, PUT e DELETE).
Voltando ao Postman, acessaremos o endpoints de autores, dando um GET no endereço abaixo.
localhost:3000/autores/Após clicarmos em "Send", ele nos retorna uma lista com os três nomes populados com a migração e com o seed. Isso prova que tudo funciona e que o Postgres está ativo e integrado com nossa API, que por sua vez expôs na porta 3000.
Visto que integramos um time de desenvolvimento, após este primeiro contato com o projeto, podemos seguir em frente e realizar nossas contribuições. Vamos lá.
Já temos o projeto rodando, por isso falaremos sobre a forma com que empresas se organizam para manter a padronização e a comunicação entre várias partes do produto.
A parte de organização varia de empresa para empresa, dependendo inclusive da arquitetura usada.
No que diz respeito à parte interna do projeto, como se garante que todos "falem a mesma língua", ou seja, utilizem os mesmos padrões de sintaxe, de organização do código, entre outros detalhes?
Vamos abordar o que chamamos de Continuous Integration/ Continuous Delivery, ou simplesmente CI/ CD (Integração e Entrega Contínuas). Vamos entender a esteira de Integração Contínua e como ela ajuda na padronização do código.
Veremos três diagramas que mostram como funciona a Integração Contínua. Apesar de serem diferentes, notaremos que eles se referem mais ou menos à mesma coisa.
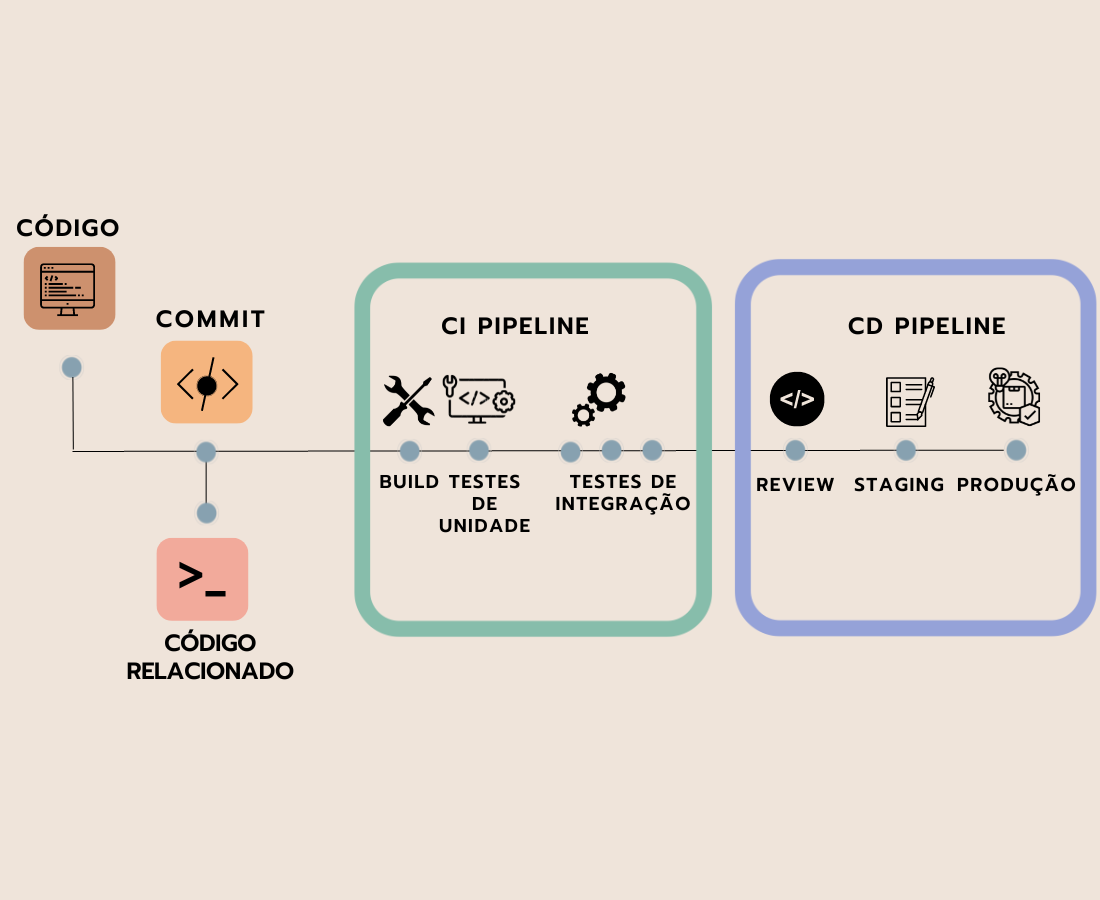
No primeiro, temos o código, depois o Commit que "empurra" (a partir do push) as alterações de código do repositório local para o Github.
A partir do momento que "empurramos" o código, existem processos automatizados que podemos colocar nele para garantir que esteja padronizado, testado e de acordo com o que se espera para sua integração ao código existente. Neste contexto, ele pode ser um código em desenvolvimento ou um código em produção — veremos os dois casos.
Na fase de Integração Contínua, fazemos:
Observação: O sentido de “build” varia um pouco para cada projeto, mas basicamente significa pegar um código de desenvolvimento e montar o código final, compilando, transformando e recolhendo o que for necessário.
Esta etapa garante que tenhamos testes e que eles funcionem, além de outras padronizações que veremos posteriormente. Desta, passamos para a esteira de Entrega.
Na fase de Entrega Contínua, podemos ter:
Disponibilizaremos um material sobre ambientes — entre eles o de Staging — nas atividades deste curso.
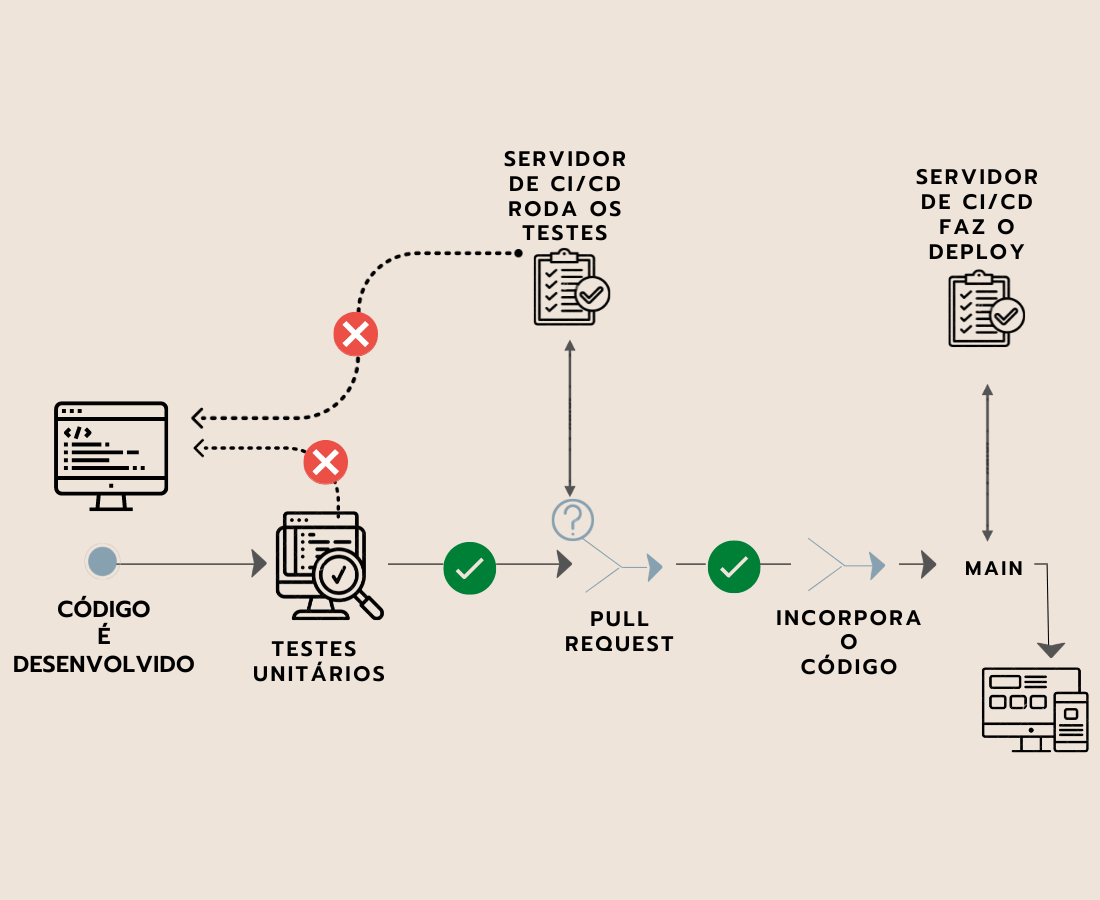
No segundo diagrama, temos outra representação da esteira de Integração.
Nela, realizamos os passos abaixo:
Neste ponto, a esteira sofrerá uma bifurcação de decisão. O caminho a seguir depende dos resultados dos testes:
Nos casos em que os testes não forem bem sucedidos, o código retorna à esteira de Integração (CI).
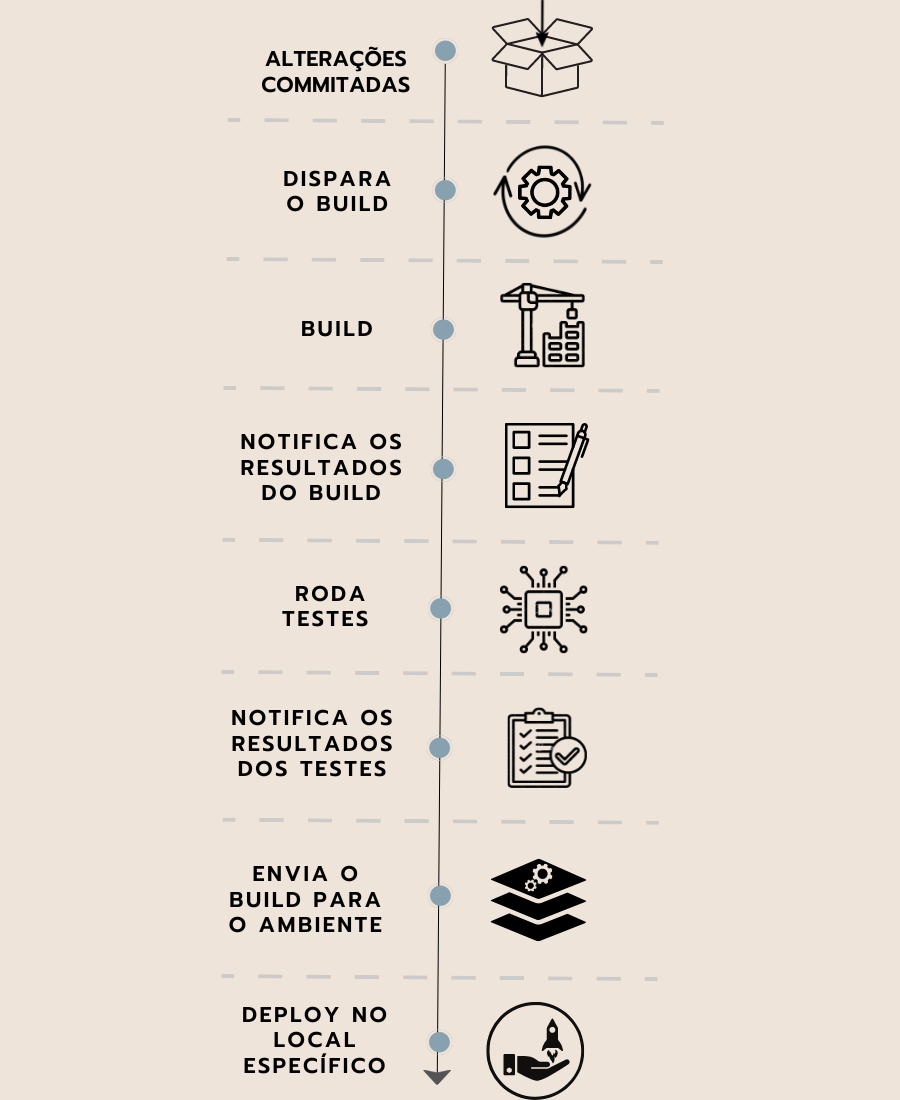
O terceiro diagrama trabalha com a mesma ideia dos outros dois. Nele, temos os seguintes passos:
Neste ponto, teremos uma bifurcação de decisão. O caminho a seguir depende dos resultados.
Caso os testes não passem:
Se os testes passarem:
Não abordaremos o Deploy neste curso, contudo disponibilizaremos nas atividades alguns materiais sobre esse assunto.
Após estes processos, temos o resultado final, que pode ser:
É importante lembrar que cada empresa possui seus padrões e sua própria esteira de CI/CD. Além disso, cada uma possui seu próprio Onboarding que familiarizará todas as pessoas do time com o projeto.
O objetivo deste vídeo é entender o conceito inicial do que é uma esteira de Integração, compreendendo os aspectos importantes e o motivo de sua existência.
A seguir, analisaremos o código que cria as ações dessa esteira e a faz funcionar. Vamos lá.
O curso Node.JS: melhorando o fluxo de desenvolvimento e integração de sua equipe possui 215 minutos de vídeos, em um total de 52 atividades. Gostou? Conheça nossos outros cursos de Node.JS em Programação, ou leia nossos artigos de Programação.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






