até
 % OFF
% OFF
% OFF
% OFFOlá, boas-vindas a mais este curso. Meu nome é Vinicios Neves, sou conhecido como o desenvolvedor careca e barbudo que você mais gosta aqui na Alura. Estou preparado para seguirmos juntos nesta jornada.
Audiodescrição: Vinicios se identifica como um homem branco. Tem sobrancelhas grossas e olhos escuros. É careca e tem barba e bigode espessos e escuros. No rosto, usa um óculos quadrado de armação preta. No corpo, usa uma camiseta azul-escura. Está sentado em uma cadeira gamer. Ao fundo, há uma parede lisa, iluminada em tons de azul e rosa.
Entenderemos o que é um BFF (Back-end for Front-end), como o GraphQL se conecta a esse tipo de arquitetura e como implementamos tudo isso utilizando React, Nest e Docker.
Será uma jornada muito interessante. Neste curso, faremos algo muito semelhante ao que ocorre na vida de uma pessoa desenvolvedora no mercado. Vamos entender as necessidades de um projeto, trabalhar nas decisões arquiteturais relacionadas ao que precisamos desenvolver e, claro, escrever muito código.
Aguardamos você no próximo vídeo!
Vamos falar sobre BFF e GraphQL. Para entender como essas peças se encaixam e o nosso processo de pensamento, precisamos começar falando do HTTP.
Utilizamos muito o HTTP no dia a dia, seja acessando a web ou desenvolvendo algo, mas não sabemos como ele funciona. Basicamente, ele é o protocolo que trafega dados. Solicitamos algo que passa pela rede (fibra ótica ou Wi-Fi), até chegar ao servidor, que processa e devolve uma resposta. O papel principal do protocolo é trafegar dados de acordo com o que foi solicitado, seja um website da Alura ou até mesmo o primeiro website criado, na década de 90.
Nas primeiras versões do HTTP, como a 0.9, o cabeçalho das requisições era bem limitado, ou seja, havia restrições sobre o que podia ser transmitido. Com o lançamento da versão 1.0 do HTTP, em 1996, ele ganhou mais funcionalidades, permitindo o uso de cabeçalhos para identificar o que está sendo devolvido e trafegado de forma mais poderosa.
Nos primórdios, surgiu a ideia de trafegar arquivos XML. Este tipo de arquivo é uma forma de organizar estruturas de dados com tags alinhadas que identificam recursos. Um dos primeiros servidores web usava XML - RPC, que trafegava XML de um lado para o outro, e o servidor processava e devolvia a resposta. O HTTP passou a trafegar XML, além de HTML.
O conceito de XML - RPC deu origem ao SOAP, acrônimo para Simple Object Access Protocol. Apesar do nome, não é fácil serializar e desserializar XML, especialmente entre diferentes linguagens ou versões, tornando o processo caótico.
O SOAP utilizava XML para comunicação entre servidores web. Depois do SOAP, surgiu o REST. A diferença fundamental entre SOAP e REST é que, enquanto o SOAP trabalha com XML, o REST trafega JSON, tornando-o mais simples. O REST possui seis princípios:
Vamos desmistificar esses princípios. Uma API REST deve ser cliente-servidor, ou seja, a entidade cliente faz uma solicitação e o servidor devolve a resposta. Além disso, deve ser stateless, sem manter estado entre requisições. Cada requisição deve conter todos os dados necessários para execução no servidor.
Ela também deve ser cacheável, permitindo o armazenamento de respostas para reutilização. O sistema deve ser em camadas para passar por várias etapas até chegar ao servidor. Já o princípio do código sob demanda permite solicitar arquivos JavaScript conforme necessário.
A interface uniforme é um dos pilares do REST, permitindo identificar e manipular recursos através de suas representações (ou seja, dos JSON). Ela define que as mensagens devem ser autodescritivas e utilizar HATEOAS (Hypermedia as the Engine of Application State), orientando o núcleo da API à hipermídia (disponibilizando links).
Essa questão da hipermídia nos leva ao modelo de maturidade de Richardson, que possui três níveis:
/videos);GET e POST, como PUT e DELETE;Uma API RESTful deve atender a todos esses princípios para atingir a "Glória do REST" ("Glory of REST").
Apesar disso, não há problema ter uma API que não é RESTful. Isso significa que ela não segue os princípios do padrão REST.
Agora, vamos fazer um estudo de caso. No canal do YouTube da Alura, teríamos recursos RESTful para entregar dados. Por exemplo, /channels para listar canais, /channels/id para um canal específico, /channels/id/playlist para playlists, e assim por diante. Isso gera muitos pedidos diferentes para montar uma tela, e é aí que entra o GraphQL.
O GraphQL resolve problemas de overfetching (trazer mais dados do que necessário) e underfetching (trazer menos dados do que necessário). Ele também reduz o excesso de roundtrip, ou seja, a quantidade de vezes que precisamos solicitar dados à API.
Com o GraphQL, fazemos uma única solicitação detalhada, que ele entrega sob medida. Por exemplo, podemos solicitar canais, playlists e vídeos em uma única consulta, e o GraphQL cuida de buscar todos os dados necessários.
A nível de arquitetura, o GraphQL difere da API RESTful. Ao invés de realizar múltiplas requisições HTTP nos moldes https://site/canal/playlist/video, ele utiliza uma sintaxe específica conforme o exemplo abaixo:
{
chanels(username: "alura") {
name,
subscribers,
playlists {
name,
videos {
title,
views
}
}
}
}
Nesse exemplo, pedimos as seguintes informações do canal cujo nome de pessoa usuária é "alura":
O pedido é feito uma vez só nesse modelo e o GraphQL recuperará todos os dados necessários. Para omitir alguma informação, basta removê-la da consulta.
O BFF (Back-end for Front-end) é um back-end feito especificamente para um front-end. Ele serve dados sob medida para o front-end, e por isso, pode ser combinado com os poderes do GraphQL.
O BFF atua como uma camada entre o navegador e a fonte de dados, servindo o que o front-end precisa. Combinando essas tecnologias, temos um back-end e uma API sob medida para montar telas ou múltiplas telas, trafegando apenas os campos necessários.
Com esses conceitos em mente, podemos começar a montar o BFF. Entre as atividades desta aula, estão os passos para montar o BFF para o front-end.
Nos veremos no próximo vídeo!
Agora que já entendemos, de maneira fundamental, as diferenças entre uma API RESTful e o GraphQL, além de como esses conceitos se integram no desenvolvimento de um back-end específico para um front-end, é o momento de explorarmos a implementação do lado do servidor. Precisamos analisar quais tecnologias serão utilizadas para construir um servidor GraphQL eficaz.
Utilizaremos duas tecnologias que funcionam bem juntas: o Nest, um framework back-end, que será familiar para quem vem do ecossistema Angular, pois é modular e lembra a implementação de componentes antes dos componentes independentes do Angular. Isto é, é um framework para nosso back-end.
E o Apollo, que é a camada do GraphQL, responsável por entregar o serviço. Implementamos os serviços utilizando o Apollo, e escrevemos o código e o Nest. O Apollo cuida de tudo o que é necessário para o GraphQL funcionar.
Falando sobre GraphQL, é fundamental compreender o que é o schema.
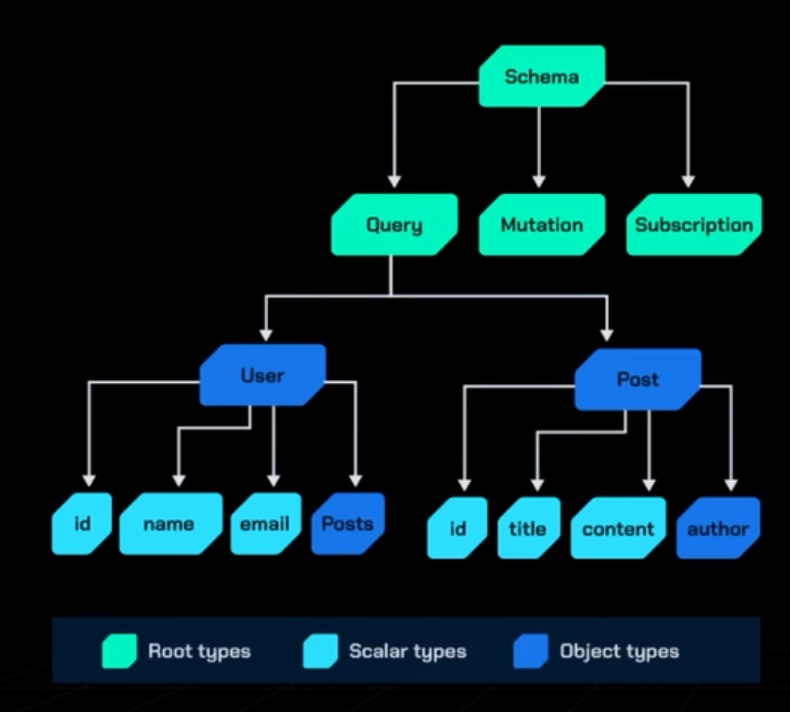
O schema é uma documentação de baixo nível que facilita a comunicação entre a linguagem do GraphQL e a linguagem que estamos utilizando. Embora possamos ler o schema diretamente no arquivo, o mais importante é entender que o papel do schema é definir todas as operações que podem ser realizadas dentro do nosso servidor GraphQL.
Definimos os nossos modelos, o que enviamos, o que podemos solicitar, a possibilidade de aplicar filtros, o formato dos dados (tipos) e até mesmo o suporte a real-time por meio da camada de subscriptions do GraphQL.
O schema desempenha um papel central no GraphQL, pois documenta de forma clara o que pode ser realizado e o que é transmitido entre os diferentes pontos da comunicação.
No cenário em que desejamos solicitar playlists e vídeos de um canal, é no schema que fica definida aquilo que podemos pedir e o que cada campo representa.
Ao criarmos um servidor GraphQL, devemos escolher entre duas abordagens para a definição do schema:
Code -> Schema -> Client
Podemos gerar o schema a partir do código, utilizando frameworks como Nest ou Apollo (o schema é um arquivo com todas essas informações), ou criar o schema de forma antecipada e, em seguida, desenvolver o código com base nele. Cada cenário possui suas próprias vantagens e desvantagens.
Ao desenvolvermos um BFF (back-end for front-end), podemos focar na escrita do código, na definição dos nossos modelos, em como eles irão trafegar e na estruturação lógica da hierarquia de informações entre os modelos.
Ao terminarmos de codar, o GraphQL, juntamente com o Nest ou Apollo, gera o schema automaticamente. Esse processo assegura que o código fonte seja a única fonte de verdade.
Se optarmos por criar o schema primeiro, nossa intenção provavelmente será ser agnósticos em relação à tecnologia, ou seja, sem nos preocuparmos com a linguagem de programação utilizada, e sim focando principalmente na documentação. Essa abordagem é especialmente útil em cenários com múltiplas equipes e domínios de informação distintos, onde pode ser vantajoso estabelecer um schema bem definido antes de iniciar o desenvolvimento.
Essa estratégia pode até facilitar o processo de desenvolvimento, pois ao entregar o schema para uma equipe de front-end, é possível que o back-end e o front-end sejam desenvolvidos em paralelo, com um contrato já estabelecido entre as partes.
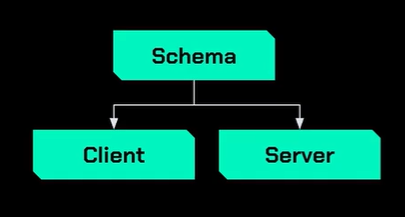
Usaremos code-first para aproveitar o TypeScript e o Nest.js
No nosso cenário, em que estamos construindo um BFF para o front-end, podemos optar pela abordagem Code-First. Nesse caso, focamos no desenvolvimento do código e delegamos a geração do schema para o Nest e Apollo. A partir daí, começamos a implementar os resolvers.
No schema da seção "O papel central do schema no GraphQL", temos a camada de query, que define as consultas disponíveis. O que define cada consulta e o que pode ser solicitado em cada uma delas, é o resolver.
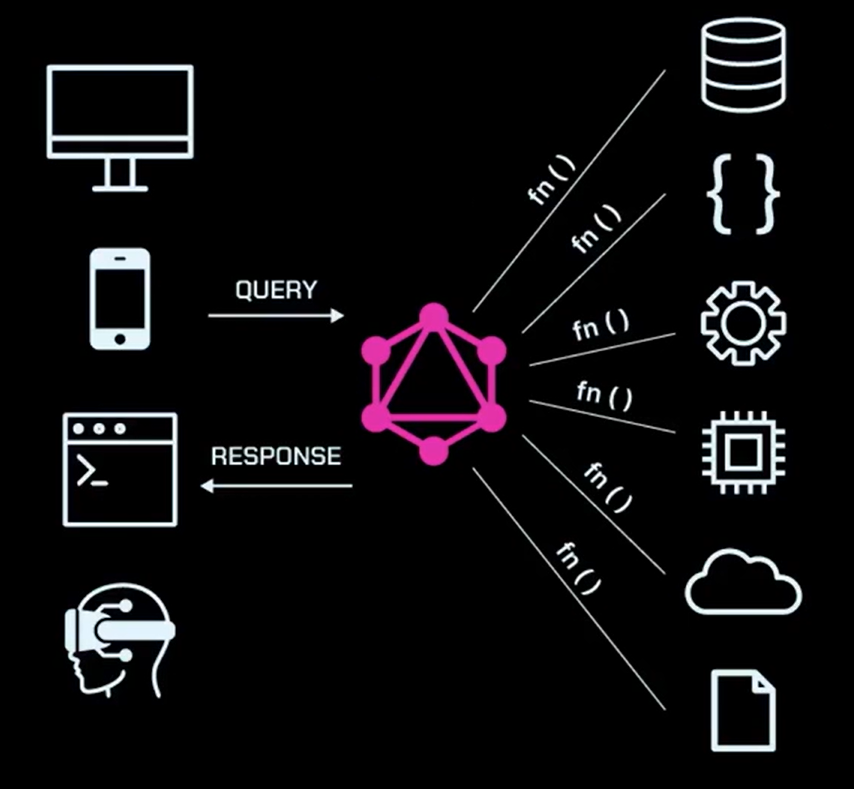
O resolver, por sua vez, é uma função que pode receber argumentos para aplicar filtros aos recursos. Por exemplo, no caso de channels, podemos escolher se incluímos o username como argumento. Se o username for fornecido, o filtro é aplicado, trazendo apenas os canais correspondentes; caso contrário, todos os canais são retornados. Em suma, o resolver é uma função.
Um ponto importante do GraphQL mais próximo da implementação está no resolver buscar os dados, independentemente de sua origem (banco de dados, arquivo JSON ou de configuração), encapsulando o processo de obtenção dessas informações na função.
Ao implementar essa funcionalidade no Nest utilizando o Apollo, definimos um objeto, que no exemplo é de categoria, que inclui campos como id, displayName e ícone:
@ObjectType()
export class Category {
@Field(() => ID)
id: string;
@Field()
displayName: string;
@Field()
icon: string;
}
Iniciamos definindo o modelo, sendo que desejamos entregar uma categoria.
Na implementação do resolver, informamos ao Next e ao Apollo que a classe se trata de um resolver de categoria. A partir dessa definição, ela será responsável por fornecer as informações relacionadas a esse tipo específico de dado. Esse conhecimento deve ser utilizado durante a geração do schema, para que possamos identificar corretamente as ações necessárias e os tipos possíveis para os campos de uma categoria.
Analisaremos o exemplo:
@Resolver(() => Category)
export class CategoryResolver {
@Query(() => [Category])
async categories(): Promise<Category[]> {
return [
{
id: 'camisetas',
displayName: 'Camisetas',
icon: 'https://raw.content.com/icon.png',
},
];
}
}
Criamos um resolver para categoria, o qual define uma query responsável por retornar uma lista de categorias. Com isso, retornamos a lista. No nosso exemplo, buscamos uma única categoria, no caso, a de camisetas, mas o processo é flexível, permitindo que a busca seja realizada a partir de qualquer fonte de dados necessária.
Para o nosso cenário específico, estabelecemos a conexão com o super base como a fonte de dados.
Temos um resolver que retorna categorias, mas, no caso de um produto com categoria associada, por algum motivo, não queremos retornar a categoria completa. Em vez disso, desejamos encapsular essa informação e retornar apenas o que é relevante para a pessoa usuária, como o displayName.
Conseguimos desenvolver essa lógica utilizando o resolve field:
@Resolver('Product')
export class ProductResolver {
@Query(() => [Product])
async getProducts(): Promise<Product[]> {
return [
{
name: 'Tênis Esportivo',
price: 199.99,
seller: 'Loja XYZ',
image: 'image-url',
category: { id: '1', displayName: 'Calçados' },
},
];
}
@ResolveField(() => String)
async categoryName(@Parent() product: Product): Promise<string> {
return product.category.displayName;
}
}
Podemos criar um resolve field para tratar campos específicos de um produto, retornando apenas as informações relevantes para a pessoa usuária ao solicitar a categoria de um produto, como, por exemplo, o nome (displayName).
Ao seguir esses três passos, implementamos resolvers dentro do ecossistema do NestJS utilizando o Apollo. No contexto do nosso modelo de negócio, trabalhamos com o resolver, e, quando necessário, podemos incluir resolvers específicos para campos ("resolver fields").
Ao implementarmos utilizando o Next e o Apollo como servidor GraphQL, fazemos isso utilizando anotações como @Resolver e @Object. O Apollo nos oferece uma interface de playground, que funciona como uma documentação interativa, similar ao Swagger em APIs RESTful. Esse playground permite que escrevamos consultas, selecione os campos desejados e testemos as respostas, facilitando o desenvolvimento e a compreensão do que está sendo enviado e retornado.
Com a implementação dos resolvers, conseguimos expandir e aprimorar nossa API GraphQL, que desenvolveremos para o front-end.
Lembre-se de que estamos criando um back-end sob medida, um BFF (back-end for front-end). Se surgir qualquer dúvida durante a implementação, podemos contar com o Discord, o fórum ou a colaboração da comunidade.
Agora, é o momento de focarmos na construção da camada do servidor, pois o próximo passo será conectar o front-end ao servidor. Nos encontramos na próxima aula!
O curso React e Nest: implementando um Backend for Front-end possui 66 minutos de vídeos, em um total de 26 atividades. Gostou? Conheça nossos outros cursos de React em Front-end, ou leia nossos artigos de Front-end.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:

O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






