Olá! Boas-vindas a este curso de regressão, no qual preveremos o futuro utilizando uma biblioteca incrível e intuitiva chamada Prophet.
Eu sou Valquíria, instrutora na Escola de Dados, e te acompanharei neste curso.
Audiodescrição: Valquíria Alencar se identifica como uma mulher branca. Possui cabelos castanho-claros e lisos, abaixo dos ombros, e olhos castanho-escuros. No nariz, possui um piercing de argola no septo. No corpo, usa uma camiseta preta com o logotipo da Escola de Dados, na cor verde. Está sentada em uma cadeira gamer preta. Ao fundo, o estúdio da Alura, iluminado por luzes verdes, azuis e roxas. Há uma parede lisa, um vaso de plantas à esquerda e uma estante à direita com vasos de plantas, estátuas e uma máquina de escrever.
Neste curso, desenvolveremos um projeto para uma empresa de consultoria ambiental que deseja ter um modelo capaz de prever os valores de um poluente atmosférico nos próximos meses. Além de criar e validar um modelo, criaremos uma aplicação web que permitirá à pessoa usuária fazer uma previsão com esse modelo.
A aplicação servirá para prever os níveis de ozônio utilizando a biblioteca Prophet. Na página inicial dela, temos uma descrição do projeto, de como ele foi feito e qual é o erro do modelo, além de um campo para inserir o número de dias para fazer a previsão.
Para adicionar um período de previsão de 60 dias, inserimos esse número no campo, e pressionamos um botão abaixo dele para realizar a previsão. Após clicar nesse botão, o modelo vai trabalhar internamente e criar a previsão.
O resultado será um gráfico interativo que contém a série temporal e os novos valores previstos pelo modelo. Além desse gráfico interativo, também conseguiremos acessar uma tabela que contém os valores de previsão - neste caso, para 60 dias.
A tabela contém a data, o dia, o mês, o ano e a concentração do ozônio em microgramas por metros cúbicos. Inclusive, é possível baixá-la no formato CSV, clicando em um botão abaixo dela.
Ao clicar no botão, o download será feito automaticamente no computador. Com essa tabela, podemos fazer análises futuras, tomar decisões, construir relatórios, entre outras coisas.
Mal podemos esperar para realizar esse projeto e construir essa aplicação. Vamos começar?
Vamos iniciar o projeto?
Para contextualizar, trabalharemos com poluentes atmosféricos, um grande problema, tanto para a saúde física quanto para o meio ambiente. Um desses poluentes é o ozônio atmosférico, formado a partir de poluentes secundários, que são emitidos pela fumaça dos carros e das indústrias, em conjunto com a radiação solar.
Este poluente pode ser prejudicial para a saúde física - especialmente para o sistema respiratório - e para a produção agrícola. Portanto, a ideia é pensar em como resolver esse problema ambiental e em políticas ambientais para melhorar essa situação.
Para isso, precisamos entender como está a concentração de ozônio ao longo do tempo. Uma empresa de consultoria ambiental nos contratou, como cientistas de dados, para criar um modelo preditivo que consiga prever a quantidade de ozônio que será liberada e qual será a concentração diária nos próximos meses, para nos antecipar e nos preparar em relação ao futuro.
Além disso, essa empresa solicitou que criássemos uma aplicação web, na qual poderemos inserir o número de dias para os quais queremos fazer a previsão do ozônio diário, e essa previsão é feita. Teremos um gráfico mostrando esses valores de ozônio diários e uma tabela que mostrará o valor de ozônio para os próximos meses. Ainda poderemos fazer o download dessa tabela e usá-la para análises futuras e tomada de decisões.
Para realizar esse projeto, usaremos duas bibliotecas muito conhecidas em Python:
Prophet, para criar o modelo preditivo;Streamlit, para criar a aplicação web.Antes de começar a desenvolver esse projeto, precisamos dos dados. Vamos coletá-los do GitHub e carregá-los no Google Colab.
Acessando esse link, copiaremos o endereço na barra de URL do navegador e voltaremos ao Google Colab.
Na primeira célula, começaremos importando a biblioteca Pandas para carregar esses dados.
import pandas as pd
Após executar a célula, carregaremos os dados. Para isso, na célula seguinte, criaremos uma variável chamada df para armazenar esses dados. Nela, chamaremos pd.read_csv() para fazer a leitura do arquivo. Entre os parênteses, abriremos aspas simples e colaremos o endereço entre elas.
df = pd.read_csv('https://raw.githubusercontent.com/alura-cursos/series_temporais_prophet/main/Dados/poluentes.csv')
Depois de executar a célula, chamaremos o df para ver as informações que temos.
df
Como resultado, temos um dataframe com algumas colunas.
| # | Data | PM2.5 | PM10 | SO2 | NO2 | CO | O3 | TEMP |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-03-01 | 7.0 | 11.0 | 12.0 | 23.0 | 429.0 | 64.0 | 1.0 |
| 1 | 2020-03-02 | 31.0 | 42.0 | 37.0 | 67.0 | 825.0 | 30.0 | 1.0 |
| 2 | 2020-03-03 | 77.0 | 121.0 | 61.0 | 81.0 | 1621.0 | 19.0 | 6.0 |
| 3 | 2020-03-04 | 23.0 | 45.0 | 23.0 | 46.0 | 606.0 | 54.0 | 10.0 |
| 4 | 2020-03-05 | 149.0 | 184.0 | 94.0 | 133.0 | 2358.0 | 68.0 | 6.0 |
| … | … | … | … | … | … | … | … | … |
| 1455 | 2024-02-24 | 22.0 | 33.0 | 17.0 | 59.0 | 575.0 | 51.0 | 5.0 |
| 1456 | 2024-02-25 | 11.0 | 20.0 | 7.0 | 43.0 | 421.0 | 64.0 | 6.0 |
| 1457 | 2024-02-26 | 28.0 | 41.0 | 10.0 | 65.0 | 721.0 | 49.0 | 7.0 |
| 1458 | 2024-02-27 | 75.0 | 97.0 | 21.0 | 98.0 | 1427.0 | 37.0 | 8.0 |
| 1459 | 2024-02-28 | 13.0 | 23.0 | 9.0 | 38.0 | 421.0 | 82.0 | 11.0 |
A primeira coluna se chama "Data" e contém a data em que cada poluente foi quantificado. Temos informações sobre vários poluentes, mas o foco será a penúltima coluna, do ozônio, representada por "O3".
Para cada linha, temos a concentração diária desse ozônio, que está em microgramas por metro cúbico. A ideia é entender como isso está ao longo do tempo para, depois, fazer a previsão.
Podemos começar criando um gráfico para analisar o ozônio ao longo do tempo. Antes disso, é importante que a coluna "Data" esteja no formato de data, pois, geralmente, ela vem como formato do tipo objeto.
Para convertê-la, usaremos a biblioteca Pandas. Na próxima célula, chamaremos o df, passando entre colchetes e aspas simples a coluna Data, um sinal de igual, e chamar o Pandas com pd.to_datetime() para converter no formato de data.
Entre os parênteses, chamaremos`df['Data'].
df['Data'] = pd.to_datetime(df['Data'])
Após a execução da célula, podemos plotar o primeiro gráfico.
Para facilitar o processo, podemos criar um gráfico interativo com a biblioteca Plotly, que facilita a visualização.
import plotly.express as px
O gráfico ideal para analisar um dado ao longo do tempo é o de linhas. Portanto, pularemos duas linhas e criaremos uma figura com a variável fig que será igual à chamada do px, representando o PlotlyExpress, e um .line() para plotar o gráfico de linhas.
Entre os parênteses, adicionaremos o dataframe df e definiremos o x como 'Data' e o y como o ozônio ('O3').
Por fim, desceremos uma linha e adicionaremos o fig.show() para exibir o gráfico.
import plotly.express as px
fig = px.line(df, x='Data', y='O3')
fig.show()
Ao executar a célula e analisar o gráfico, notamos que parece haver um padrão.
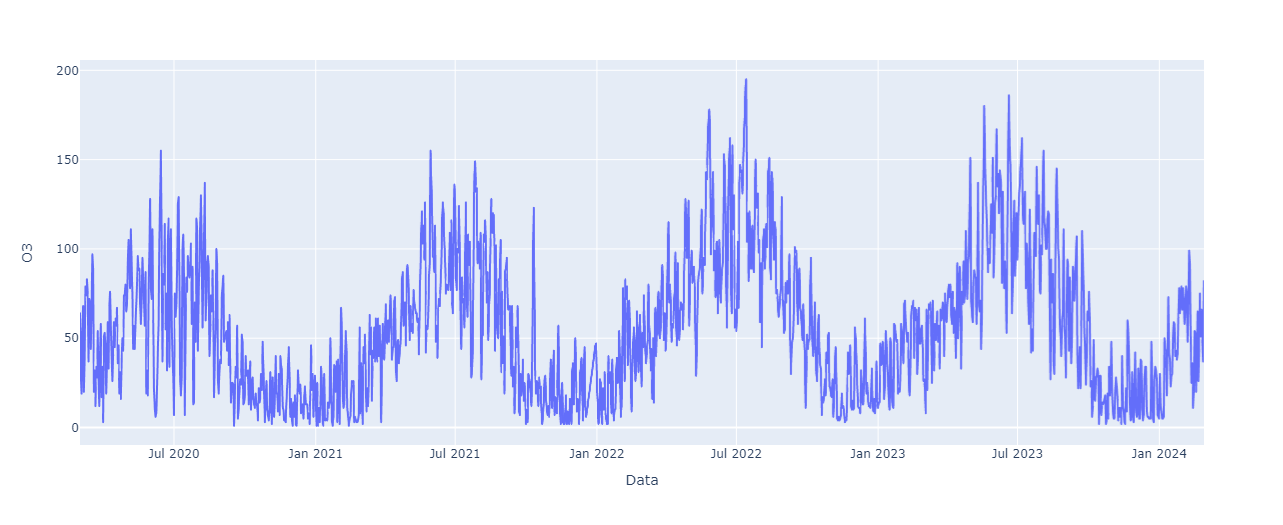
Aparentemente, no começo do ano, os níveis de O³ são mais baixos, vão aumentando no meio do ano e depois, caindo de novo. Esse padrão se repete ao longo do gráfico.
Quando temos um padrão repetitivo, chamamos isso de sazonalidade em uma série temporal. Podemos confirmar isso plotando um gráfico de barras que mostre a média de ozônio em cada mês de um ano específico.
Na próxima célula vazia, abaixo do gráfico, filtraremos os dados por algum ano - por exemplo, 2022. Criaremos um dataframe só de 2022 com df_2022, um sinal de igual, um df[] e escrever entre colchetes a coluna da qual queremos o ano - no caso, df['Data'] acrescentando um .dt.year == 2022 após os colchetes para determinar o ano específico de 2022.
df_2022 = df[df['Data'].dt.year == 2022]
Pulando uma linha, agruparemos os valores de cada mês, recolhendo a média do ozônio por mês. Para fazer isso, criaremos um df_2022_mensal, adicionar um sinal de igual, chamar o df_2022 criando acima e usar a função groupby() da biblioteca Pandas, que consegue agrupar colunas e pegar valores de média.
Entre os parênteses dela, adicionaremos o df_2022 e chamar entre colchetes e aspas simples a Data. Para especificar o mês, adicionaremos um .dt.month após os colchetes.
Para solicitar a média do ozônio, sairemos dos parênteses do groupby() e adicionaremos um ['03'], mencionando a coluna do ozônio "03".
À direita dos colchetes, chamaremos .mean() para obter a média e também "resetaremos" (reiniciaremos) o índice com .reset_index(), porque, ao calcular a média, ele pode ser alterado. Isso manterá tudo organizado.
df_2022 = df[df['Data'].dt.year == 2022]
df_2022_mensal = df_2022.groupby(df_2022['Data'].dt.month)['O3'].mean().reset_index()
Feito isso, antes de criar o gráfico, podemos mostrar o nome abreviado de cada mês, em vez de apenas 1 até 12. Para obter a abreviatura de cada mês, importaremos o módulo chamado calendar, adicionando um import calendar.
df_2022 = df[df['Data'].dt.year == 2022]
df_2022_mensal = df_2022.groupby(df_2022['Data'].dt.month)['O3'].mean().reset_index()
import calendar
Colocaremos essa abreviatura no lugar do número do mês criando uma coluna do mês. Para isso, pularemos uma linha e adicionaremos um df_2022_mensal['Mês']. Ele receberá a chamada de df_2022_mensal['Data'] e após os colchetes, usaremos a função .apply() da biblioteca Pandas. Essa função mapeia valores e faz substituições.
Para facilitar o processo, podemos usar uma função lambda entre os parênteses, chamando lambda x: e informar que a função recolherá a abreviatura do mês por meio de um calendar.month_abbr[x]. Fazendo isso, teremos a substituição de cada valor que estiver no mês pela abreviatura.
df_2022 = df[df['Data'].dt.year == 2022]
df_2022_mensal = df_2022.groupby(df_2022['Data'].dt.month)['O3'].mean().reset_index()
import calendar
df_2022_mensal['Mês'] = df_2022_mensal['Data'].apply(lambda x: calendar.month_abbr[x])
Feito isso, criaremos o gráfico de barras, mostrando a média de ozônio para cada mês. Pulando uma linha, criaremos uma variável chamada fig, adicionar um igual e chamar o Plotly Express (px). Em seguida, adicionaremos um px.bar(), pois será um gráfico de barra em vez de linha.
Entre os parênteses, informaremos o df_2022_mensal e definiremos o x como o mês, por meio de um x='Mês', e o y como o ozônio, o O₃, por meio de um y='O3'.
Também daremos um título para esse gráfico, tornando-o mais informativo. Após o valor de y, podemos chamar o title='Média de O₃ em ug/m³ por mês em 2022'.
Por fim, descendo para a próxima linha, inseriremos um fig.show() para exibir esse gráfico.
df_2022 = df[df['Data'].dt.year == 2022]
df_2022_mensal = df_2022.groupby(df_2022['Data'].dt.month)['O3'].mean().reset_index()
import calendar
df_2022_mensal['Mês'] = df_2022_mensal['Data'].apply(lambda x: calendar.month_abbr[x])
fig = px.bar(df_2022_mensal, x='Mês', y='O3', title='Média de O3 ug/m3 por mês em 2022')
fig.show()
Após executar essa célula, temos gráfico mostrando a média de ozônio em cada um dos meses, especificamente para o ano de 2022, que foi o que escolhemos para exemplificar.
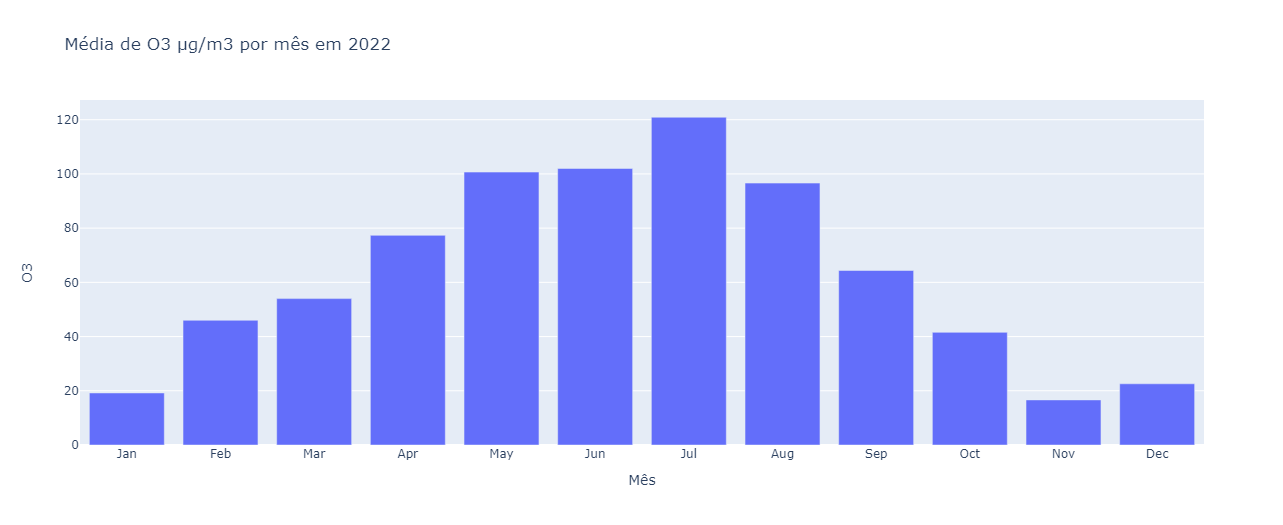
Notaremos que, em janeiro, há uma quantidade bem baixa de ozônio, com média de 19. Em fevereiro, a média é de 46, e nos outros meses, vai aumentando até chegar no meio do ano.
Os meses cujos níveis de ozônio são mais altos são maio, junho, julho e agosto, especialmente julho, que está com 120 de média. Já em agosto, a média vai diminuindo até chegar no final do ano com os menores níveis.
Isso confirma que o padrão pensado quando verificamos o gráfico de linhas é real. Temos uma sazonalidade anual bem evidente.
Portanto, a partir desses gráficos, descobrimos essa informação.
Há um detalhe importante nesses dados: estamos usando dados de uma cidade do Hemisfério Norte. Conforme comentado anteriormente, o ozônio é formado com a radiação solar. Portanto, quanto mais alta for a temperatura, maior a formação de ozônio.
Isso explica porque a formação de ozônio é maior nos meses de verão no Hemisfério Norte. Faz todo sentido.
Temos os dados indo até fevereiro de 2024. A ideia agora é criar um modelo que consiga prever os valores futuros, para que a empresa de consultoria consiga usá-los para elaborar medidas preventivas e políticas ambientais.
A partir do próximo vídeo, começaremos a construir esse modelo com a biblioteca Prophet.
Já carregamos os dados e criamos alguns gráficos para entender as questões sazonais. Agora, chegou o momento de fazer a previsão.
Para isso, vamos usar uma biblioteca bem famosa na área de séries temporais, a biblioteca Prophet.
Acessaremos o site da documentação do Prophet pelo navegador. Recomendamos que ela seja consultada e estudada mais profundamente.
No topo da página inicial, há um link chamado "Get Started in Python" (Comece em Python), no qual clicaremos.
Na página exibida, há uma série de informações da documentação que são extremamente relevantes para nos aprofundarmos nos parâmetros e noutros detalhes. Portanto, é importante analisá-la para se aprofundar nesse assunto.
Voltando ao Colab, vamos implementar essa biblioteca nele. Começaremos importando-a numa nova célula, digitando from prophet import Prophet, sendo esta a classe que fará as precisões, escrita com inicial maiúscula.
Em seguida, executaremos a célula.
from prophet import Prophet
A partir disso, a ideia é começar a criar a previsão. Mas antes de fazer isso, precisamos criar um dataframe específico para o Prophet, no qual teremos duas colunas: uma que conterá a data e outra que conterá o valor Y que queremos prever.
Criaremos esse dataframe chamando-o de df_prophet. Para criar o dataframe, vamos digitar o sinal de igual e um pd.DataFrame(), com "D" e "F" maiúsculos.
df_prophet = pd.DataFrame()
Em seguida, nomearemos as colunas de forma que o Prophet consiga entendê-las. A coluna de data vai se chamar ds, em minúsculas. Então, pularemos uma linha e criaremos um df_prophet['ds'] = df['Data'].
df_prophet = pd.DataFrame()
df_prophet['ds'] = df['Data']
A próxima coluna que esse dataframe precisa ter é a chamada Y, que corresponde ao ozônio. Para isso, na linha seguinte, colocaremos um df_prophet['y'] = df['O3'].
Por fim, executaremos a célula.
df_prophet = pd.DataFrame()
df_prophet['ds'] = df['Data']
df_prophet['y'] = df['O3']
Na célula seguinte, podemos chamar o df_prophet para verificar se está tudo certo. Ao executá-lo, temos como resultado 1.460 linhas e 2 colunas.
| # | ds | y |
|---|---|---|
| 0 | 2020-03-01 | 64.0 |
| 1 | 2020-03-02 | 30.0 |
| 2 | 2020-03-03 | 19.0 |
| 3 | 2020-03-04 | 54.0 |
| 4 | 2020-03-05 | 68.0 |
| … | … | … |
| 1455 | 2024-02-24 | 51.0 |
| 1456 | 2024-02-25 | 66.0 |
| 1457 | 2024-02-26 | 49.0 |
| 1458 | 2024-02-27 | 37.0 |
| 1459 | 2024-02-28 | 82.0 |
A coluna "ds" contém a data, e a coluna "y" contém o valor de concentração do ozônio.
A seguir, treinaremos o modelo com esses dados e faremos uma previsão.
Na próxima célula vazia, começaremos definindo uma semente aleatória. Mas o que é isso?
Para reproduzir o resultado e garantir que ele seja o mesmo em todos os computadores, é importante definir um número aleatório para garantir a reprodutibilidade do resultado. Fazemos isso com a biblioteca NumPy. Vamos importá-la com um import numpy as np.
Pulando uma linha, definiremos essa semente aleatória com o código np.random.seed(4587), onde random é semente, seed é aleatória e o número 4587 foi definido aleatoriamente.
Você deve adicionar o mesmo número no seu computador para que o resultado seja igual ao do vídeo. Isso serve para garantir que o resultado seja reprodutível.
import numpy as np
np.random.seed(4587)
Pulando uma linha, começaremos o código com o Prophet para criar o modelo. Criaremos uma variável chamada modelo e instanciaremos a classe Prophet(), que importamos anteriormente.
import numpy as np
np.random.seed(4587)
modelo = Prophet()
Na próxima linha, treinaremos esse modelo com o fit(), passando os dados de df_prophet. Para isso, faremos o comando modelo.fit(df_prophet).
import numpy as np
np.random.seed(4587)
modelo = Prophet()
modelo.fit(df_prophet)
Por fim, pulando uma linha, criaremos o futuro, porque queremos prever algo que ocorrerá futuramente. A ideia é criar um dataframe chamado futuro, chamando o modelo, a partir do qual acessaremos a função make_future_dataframe() para fazer um dataframe do futuro.
Entre os parênteses, especificaremos o período de um ano, com periods=365, sobre o qual esse dataframe será criado. Para especificar que esse valor será em dias, adicionaremos também o atributo freq com o valor D entre aspas simples.
Com isso, criaremos uma previsão que abrangerá os 365 dias após o dia do último dado que temos, 28 de fevereiro de 2024.
import numpy as np
np.random.seed(4587)
modelo = Prophet()
modelo.fit(df_prophet)
futuro = modelo.make_future_dataframe(periods=365, freq='D')
Além disso, precisamos fazer a previsão. Para isso, desceremos para a próxima linha e criaremos uma variável chamada previsao, que será igual a modelo.predict(), com o futuro criado anteriormente entre seus parênteses.
import numpy as np
np.random.seed(4587)
modelo = Prophet()
modelo.fit(df_prophet)
futuro = modelo.make_future_dataframe(periods=365, freq='D')
previsao = modelo.predict(futuro)
Ao executar essa célula, serão retornadas as informações sobre o processamento do modelo. Após a conclusão desse processo, podemos visualizar o resultado por meio de um gráfico interativo.
Para criar um gráfico interativo, importaremos uma função do Plotly na célula seguinte, adicionando o comando from prophet.plot import plot_plotly.
from prophet.plot import plot_plotly
Observação: O Prophet consegue exibir gráficos usando o Plotly internamente. Por isso, teremos o mesmo tipo de interação ao criar gráficos interativos com ambas as bibliotecas.
Pulando uma linha, também criaremos uma figura fig, que receberá o plot_plotly(modelo, previsao). Por fim, para exibir esse gráfico, adicionaremos um fig.show() em outra linha.
from prophet.plot import plot_plotly
fig = plot_plotly(modelo, previsao)
fig.show()
Após executar a célula, será gerado um gráfico diferente.
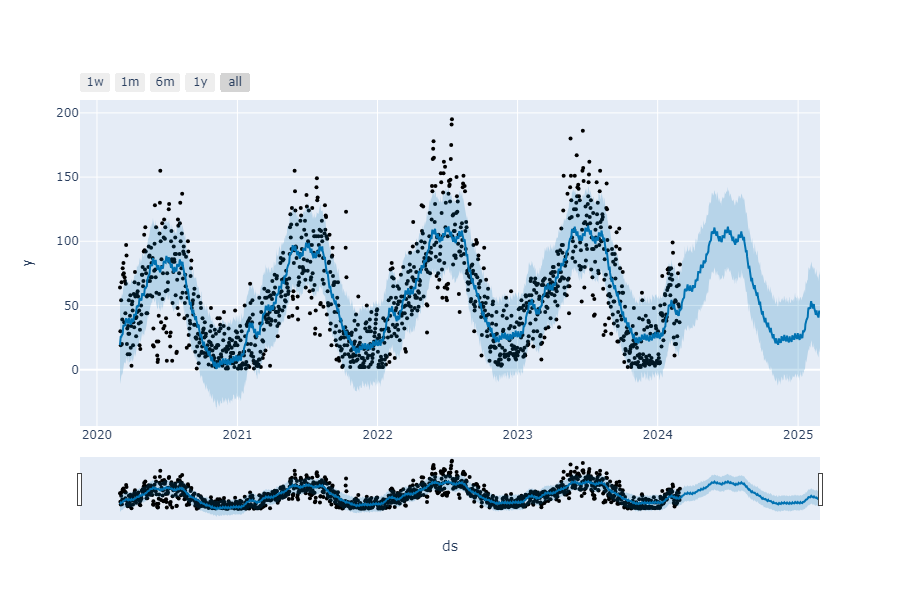
Esse gráfico, no qual temos o gráfico da previsão na parte superior, contendo o período no eixo x, que está indo de 2020 a 2025. Os pontos em preto espalhados são os valores reais de Y que temos no dataframe. A linha em azul no meio é a previsão.
Os pontos pretos devem ficar cada vez mais próximos a essa linha para indicar que o modelo funciona corretamente. Entretanto, há muitos pontos longe dessa linha no momento.
A faixa em azul-claro entre a previsão e os pontos é o intervalo de confiança. O ideal é que os pontos também estejam dentro dela.
Acessando a parte superior esquerda do gráfico, temos botões com cinco modos de visualização: "1w" (1 semana), "1m" (1 mês), "6m" (6 meses), "1y" (1 ano) e "all" (todos).
Abaixo do gráfico, por sua vez, há uma barra com a miniatura dele. Arrastando as alças nas laterais dessa barra, podemos alterar o intervalo de dados que o gráfico principal exibe, sendo possível ampliá-lo ou diminuí-lo.
Além disso, ao passar o mouse pela linha azul, veremos caixas com valores de previsão. De onde essas informações vieram?
Anteriormente, criamos o dataframe previsao que contém a previsão. Vamos consultá-lo para entendê-lo melhor.
Na próxima célula, adicionaremos e executaremos o previsao.
previsao
Como resultado, teremos uma série de informações utilizadas pelo Prophet para criar a previsão, entre as quais há vários componentes. Analisaremos somente as informações mais relevantes para compreender como a figura foi feita.
Na próxima célula, executaremos o comando previsao[['ds', 'yhat', 'yhat_lower', 'yhat_upper']], no qual temos as colunas a serem exploradas entre colchetes.
previsao[['ds', 'yhat', 'yhat_lower', '`yhat_upper`']]
Como resultado, temos a seguinte tabela:
| # | ds | yhat | yhat_lower | yhat_upper |
|---|---|---|---|---|
| 0 | 2020-03-01 | 19.138290 | -11.423571 | 49.879511 |
| 1 | 2020-03-02 | 23.271165 | -6.297502 | 54.194609 |
| 2 | 2020-03-03 | 26.149390 | -7.189955 | 56.245281 |
| 3 | 2020-03-04 | 24.995749 | -5.920884 | 55.542039 |
| 4 | 2020-03-05 | 26.295848 | -3.379147 | 56.557718 |
| … | … | … | … | … |
| 1820 | 2025-02-23 | 40.569606 | 9.516483 | 69.112572 |
| 1821 | 2025-02-24 | 43.831442 | 13.974234 | 73.743592 |
| 1822 | 2025-02-25 | 45.915345 | 16.612816 | 76.757365 |
| 1823 | 2025-02-26 | 44.061285 | 13.276886 | 73.417160 |
| 1824 | 2025-02-27 | 44.769458 | 14.266831 | 74.754275 |
Na previsão, temos a data e o yhat. Esse indicador representa o y que está sendo previsto.
Voltando ao resultado da execução de df_prophet, temos o y real - o valor de ozônio que já tínhamos -, mas também o valor que o modelo está prevendo. Portanto, temos uma diferença entre o real e o previsto.
Além disso, nosso último resultado também exibe um yhat_lower que corresponde ao intervalo de confiança inferior, representado no gráfico pela parte inferior da faixa azul-clara. Por fim, temos o yhat_upper, que representa o intervalo de confiança superior.
Conseguimos entender o que está representado neste gráfico e como a previsão é realizada. No entanto, existem componentes usados para criar a previsão de fato.
Vamos explorar isso com mais detalhes no próximo vídeo.
O curso Regressão: prevendo séries temporais com Prophet possui 153 minutos de vídeos, em um total de 49 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






