TensorFlow: implementando um perceptron de múltiplas camadas (MLP)
Conhecendo e preparando os dados - Apresentação
Olá! Boas-vidas a este curso sobre TensorFlow, onde vamos aprender a criar perceptrons com múltiplas camadas. Eu sou a Valquíria Alencar, instrutora na escola de Dados, e vou te acompanhar neste curso, onde utilizaremos dados da área da saúde para classificar se um paciente tem ou não doença cardíaca.
Audiodescrição: Valquíria se descreve como uma mulher branca, de olhos castanhos e cabelos castanhos e lisos na altura abaixo dos ombros. Ela tem piercing no septo, tatuagens nos dois braços e veste uma blusa preta. Está sentada em uma cadeira preta nos estúdios da Alura, com um fundo iluminado em gradiente de verde e azul, e uma estante preta à esquerda da instrutora com enfeites e iluminações amarelas.
O que vamos aprender?
Faremos essa classificação utilizando o TensorFlow para criar um perceptron do zero e, a partir disso, entender vários conceitos no decorrer das aulas.
Vamos falar sobre gradiente descendente, sobre funções de ativação e, ao longo das aulas, vamos incrementar a nossa rede neural, adicionando camadas ocultas, até atingir um resultado final bem interessante.
Pré-requisitos
Para que você consiga acompanhar este curso adequadamente, recomendamos que tenha conhecimentos em Python e também em machine learning, especialmente em classificação.
Vamos começar?
Conhecendo e preparando os dados - Importando os dados
Vamos começar a desenvolver nosso projeto?
Trabalharemos com dados da área da saúde e teremos informações de pacientes, envolvendo dados demográficos e informações sobre exames que as pessoas realizaram, para conseguirmos classificar se o paciente tem ou não uma doença cardíaca.
Os dados que vamos usar para trabalhar com isso são do UCI Machine Learning Repository, um repositório voltado para machine learning, onde temos vários datasets que podem ser utilizados.
Um desses datasets é o de Heart Disease (doença cardíaca), onde temos várias informações sobre as colunas e os dados existentes. A ideia é importar esse dataset para o Google Colab e começar a trabalhar.
Importando os dados
Se olharmos para o link desse dataset, temos uma informação de ID, que é o número 45. Por meio desse ID, conseguiremos fazer a importação necessária. Vamos começar a fazer isso?
Instalando o repositório
Com o Google Colab aberto, começaremos instalando o repositório do UCI. Para fazer isso, vamos colocar na primeira célula de código uma exclamação seguida do seguinte comando:
!pip install ucimlrepo
Ao executar este código, a instalação será realizada.
Obtendo os dados
Agora a ideia é fazer uma importação dessa instalação que foi feita para conseguirmos obter os dados. Para isso, vamos adicionar em uma nova célula o comando from ucimlrepo import fetch_ucirepo.
Na próxima linha de código, já podemos obter os dados de fato. Precisaremos armazenar em uma variável para conseguirmos visualizar as informações, então vamos criar uma variável chamada doenca_cardiaca.
Feito isso, atribuiremos a ela o método fetch_ucirepo(), onde vamos passar o ID do conjunto de dados que estava no site da UCI, ou seja, id=45. Com isso, vamos conseguir exibir as informações existentes.
Podemos até usar print() para adicionar um título antes de visualizar as informações, então vamos digitar print('Variáveis disponíveis no dataset de doenças cardíacas da UCI:'). Por fim, na próxima linha de código, para exibir as informações das variáveis, passaremos doenca_cardiaca.variables.
from ucimlrepo import fetch_ucirepo
doenca_cardiaca = fetch_ucirepo(id=45)
print('Variáveis disponíveis no dataset de doenças cardíacas da UCI:')
doenca_cardiaca.variables
Variáveis disponíveis no dataset de doenças cardíacas da UCI:
| - | name | role | type | demographic | description | units | missing_values |
|---|---|---|---|---|---|---|---|
| 0 | age | Feature | Integer | Age | None | years | no |
| 1 | sex | Feature | Categorical | Sex | None | None | no |
| 2 | cp | Feature | Categorical | None | None | None | no |
| 3 | trestbps | Feature | Integer | None | resting blood pressure (on admission to the ho... | mm Hg | no |
| 4 | chol | Feature | Integer | None | serum cholestoral | mg/dl | no |
| 5 | fbs | Feature | Categorical | None | fasting blood sugar > 120 mg/dl | None | no |
| 6 | restecg | Feature | Categorical | None | None | None | no |
| 7 | thalach | Feature | Integer | None | maximum heart rate achieved | None | no |
| 8 | exang | Feature | Categorical | None | exercise induced angina | None | no |
| 9 | oldpeak | Feature | Integer | None | ST depression induced by exercise relative to ... | None | no |
| 10 | slope | Feature | Categorical | None | None | None | no |
| 11 | ca | Feature | Integer | None | number of major vessels (0-3) colored by flour... | None | yes |
| 12 | thal | Feature | Categorical | None | None | None | yes |
| 13 | num | Target | Integer | None | diagnosis of heart disease | None | no |
Após executar a célula, temos como resultado uma tabela que contém, na primeira coluna (name), o nome da variável, por exemplo, age (idade), sex (sexo biológico), cp (tipo de dor que a pessoa sente no peito), e assim por diante.
Temos também qual é o papel dessa variável (role). Podemos verificar que todas as primeiras são Feature, ou seja, variáveis de entrada para um modelo de machine learning, e no final, na posição 13 da tabela, temos o Target, isto é, o que vamos prever, que é algo muito importante para nós.
Além disso, temos a coluna type, que contém o tipo de informação: se é um número inteiro, se é uma variável categórica, e assim por diante.
Também há uma coluna chamada demographic, indicando se aquela informação é demográfica. Por exemplo: nesse conjunto de dados, só temos duas informações demográficas, que são a idade (Age) e o sexo biológico (Sex). Caso não haja nenhuma informação, preenchemos com None.
Na sequência, há uma coluna com a descrição do que é cada variável (description). Algumas não têm informação nenhuma (None), mas no repositório, encontramos mais detalhes sobre as informações.
Depois temos qual é a unidade, na coluna units. Por exemplo: a idade é medida em anos (years). A variável chol, por exemplo, é o colesterol. Estamos com essa informação em miligramas por decilitro (mg/dl). Por fim, temos uma coluna sobre valores faltantes (missing_values), indicando se a respectiva variável tem dados nulos ou não.
Criando a variável X
O que podemos fazer para começar? O ideal é criar uma variável que consiga armazenar as features que usaremos para o nosso modelo. No nosso caso, podemos usar só algumas em vez de trabalhar com todas. Vamos escolher três e começar a criar o nosso modelo com isso.
A ideia é fazer, por exemplo, com a variável age, que representa a idade; com a variável cp, que é o tipo de dor no peito; e com a variável do colesterol (chol). Caso queira, você pode testar com outras variáveis posteriormente e adicionar mais informações.
Essa nova variável que irá armazenar os dados de entrada se chamará X, com letra maiúscula. Em machine learning, sempre costumamos chamar a matriz de entrada de X.
Em seguida, vamos definir o que colocaremos nessa variável. Podemos chamar primeiro a variável doenca_cardiaca, onde armazenamos a informações, seguida de .data.features.
Na próxima linha de código, vamos passar novamente a variável X, mas agora selecionaremos as variáveis desejadas, que nesse caso são age, chol e cp.
X = doenca_cardiaca.data.features
X = X[['age', 'chol', 'cp']]
Após executar esta célula, vamos visualizar o que temos como resultado. Para isso, podemos executar o comando abaixo e retornar a visualização das 5 primeiras linhas do DataFrame gerado:
X.head()
| - | age | chol | cp |
|---|---|---|---|
| 0 | 63 | 233 | 1 |
| 1 | 67 | 286 | 4 |
| 2 | 67 | 229 | 4 |
| 3 | 37 | 250 | 3 |
| 4 | 41 | 204 | 2 |
Criando a variável target
Agora falta separar o target, ou seja, a variável-alvo, o que queremos prever. Para fazer isso, vamos digitar declarar target igual a doenca_cardiaca.data.targets.
Na próxima linha, colocaremos target.head() para visualizar o que temos.
target = doenca_cardiaca.data.targets
target.head()
| - | num |
|---|---|
| 0 | 0 |
| 1 | 2 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
Observe que há uma única coluna chamada num, contendo os valores de saída. Podemos checar se temos outros valores além de 0, 2 e 1. Para isso, utilizaremos o seguinte comando com a função unique():
target['num'].unique()
Retorno da célula:
array([0, 2, 1, 3, 4])
Talvez você esteja se perguntando o seguinte: se estamos trabalhando com o problema de classificação, onde queremos saber se a pessoa tem ou não doença cardíaca, por que temos vários números?
Transformando os valores da variável
Nesse conjunto de dados em específico, os números acima de 1 indicam a gravidade da doença. No nosso caso, queremos algo mais simples, queremos classificar se tem ou não tem a doença, então podemos transformar todos os valores que estão acima de 0 em 1.
Para fazer isso, podemos executar a seguinte célula:
target = (target > 0) * 1
target.head()
Com isso, indicamos o seguinte: se target for maior que 0, será retornado o booleano true; caso contrário, esse booleano será false. Em seguida, multiplicamos por 1. A partir desse momento, tudo o que for true, se transformará no número 1. Assim, conseguimos a classificação esperada:
| - | num |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
Conclusão
Estamos com os dados preparados. No próximo vídeo, vamos explorar esses dados e criar alguns gráficos!
Conhecendo e preparando os dados - Explorando os dados
Neste vídeo, vamos explorar os dados que temos e criar alguns gráficos.
Explorando os dados
O ideal é criar um DataFrame que contenha as três colunas que colocamos na variável X, bem como a coluna do target, para conseguirmos analisar de forma mais ampla e comparar as informações em relação ao target.
Criando um DataFrame
Para começar, vamos criar um novo DataFrame chamado df. Ele será igual a uma cópia de X, então vamos usar o método X.copy(). Na próxima linha, vamos adicionar o y que foi criado no target.
Portanto, após df, criaremos a coluna y, então abrimos colchetes e colocamos y dentro, o que será igual à variável target. Assim, teremos um DataFrame que contém as colunas que estavam em X, mais uma coluna chamada y, que é o nosso target. Ao final, podemos usar df.read() para visualizar.
df = X.copy()
df['y'] = target
df.head()
| - | age | chol | cp | y |
|---|---|---|---|---|
| 0 | 63 | 233 | 1 | 0 |
| 1 | 67 | 286 | 4 | 1 |
| 2 | 67 | 229 | 4 | 1 |
| 3 | 37 | 250 | 3 | 0 |
| 4 | 41 | 204 | 2 | 0 |
Como retorno, temos justamente o que queríamos: a idade (age), o colesterol (chol), o tipo de dor no peito (cp), e por último, a variável y.
Importando bibliotecas
Para criar gráficos e entender a relação dessas variáveis com o y, precisaremos importar duas bibliotecas utilizadas para visualização de dados: seaborn e matplotlib. Importaremos seaborn com o apelido sns e, em seguida, matplotlib.pyplot com o apelido plt.
import seaborn as sns
import matplotlib.pyplot as plt
Criando um gráfico boxplot
A ideia é analisar a variável da idade (age) em relação ao nosso target. Será que a idade tem alguma relação com uma pessoa desenvolver ou não uma doença cardíaca?
Podemos criar um gráfico conhecido como boxplot (diagrama de caixa), onde conseguimos fazer uma distribuição para cada uma das classes e verificar se há alguma influência em relação à mediana.
Para criar esse gráfico, vamos digitar em uma nova célula sns.boxplot() e passar entre parênteses as informações para criar esse gráfico.
Começaremos definindo o x como o nosso target, porque podemos ter um boxplot para o y que for igual a 0, e outro boxplot para o que for igual a 1. Sendo assim, vamos definir x igual a y, e além disso, precisamos definir o y, que será no caso a idade (y='age').
Há um parâmetro muito útil na biblioteca seaborn chamado hue, que consegue distinguir as informações através de cores, de acordo com algum dado que passamos. Podemos passar para hue o y, pois, assim, ele irá distinguir deixando uma cor para a classe 0 e outra para a classe 1.
Na sequência, precisamos passar quais são os dados, então vamos colocar data igual a df, DataFrame criado anteriormente. Podemos também colocar um título usando a biblioteca matplotlib. Para isso, vamos usar plt.title() e passar entre parênteses "Idade X Doença cardíaca".
O ideal é que o gráfico comece com o eixo Y entre 0 e vá até 100, então vamos adicionar na linha abaixo o método plt.ylim() e definir que o mínimo do y será 0 e o máximo será 100.
Por fim, podemos usar o método plt.show() para exibir o gráfico.
sns.boxplot(x='y', y='age', hue='y', data=df)
plt.title('Idade X Doença cardíaca')
plt.ylim(0, 100)
plt.show()
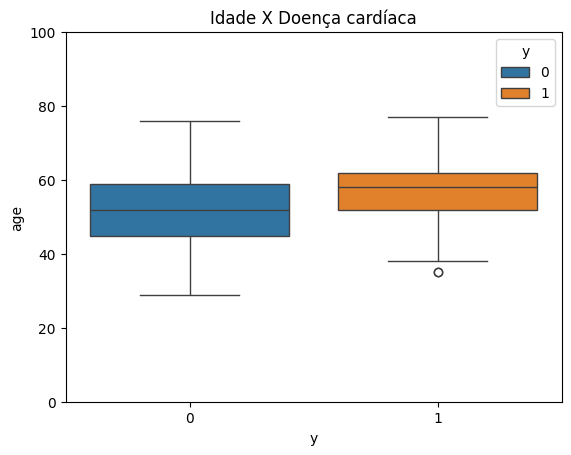
Analisando o gráfico
Vamos entender o que temos no gráfico? Do lado esquerdo, em azul, temos o boxplot para a classe 0, que são as pessoas sem doença cardíaca. À direita, em laranja, temos o boxplot para a classe 1, que são as pessoas que têm doença cardíaca. Conseguimos analisar quais são os limites inferior e superior dessas caixas, e dentro da caixa, sempre temos uma linha que é a mediana.
Se observarmos a mediana das pessoas que não têm doença cardíaca, ela está entre 40 e 60 anos. Por outro lado, a mediana das pessoas que têm doença cardíaca está um pouco mais para cima, próxima de 60 anos. A partir disso, podemos pensar que, sim, há uma relação entre a idade, ou seja, pessoas mais idosas podem estar associadas à presença de doença cardíaca nesse caso.
Criando um segundo gráfico boxplot
A ideia é fazer o mesmo para o colesterol e verificar se conseguimos descobrir algo em relação a isso. Portanto, vamos plotar o mesmo boxplot de antes, porém, para o colesterol.
Para começar, colocamos sns.boxplot() em uma nova célula e passamos os parâmetros entre parênteses. O x será a variável y, enquanto o y será o colesterol (chol).
Também vamos passar o parâmetro hue como a variável y, e por fim, colocaremos data igual a df. Além disso, colocaremos um título com plt.title() ("Colesterol X Doença cardíaca").
É interessante delimitar o eixo y, então vamos colocar plt.ylim() e passar o valor de colesterol entre 0 e 600. Por fim, vamos usar o método plt.show() para exibir esse gráfico.
sns.boxplot(x='y', y='chol', hue='y', data=df)
plt.title('Colesterol X Doença cardíaca')
plt.ylim(0,600)
plt.show()
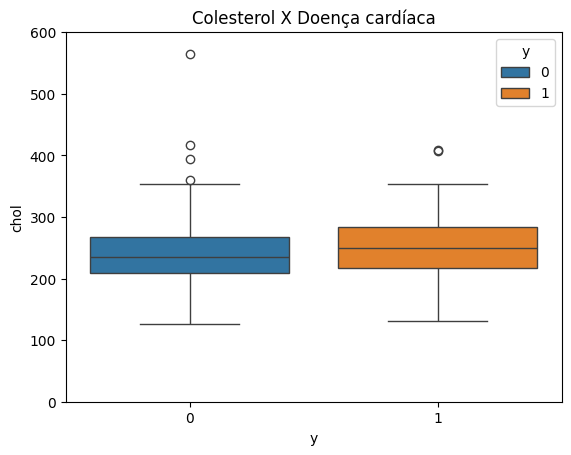
Analisando o segundo gráfico
O que conseguimos visualizar a partir do gráfico? Os valores no eixo Y vão de 0 a 600, conforme definido no código, e à esquerda, representado pelo boxplot azul, temos as pessoas sem doença cardíaca, com a mediana um pouco acima de 200. Por outro lado, quando falamos das pessoas que têm doença cardíaca, a mediana está mais acima, mais próxima de 300, então pode ser que haja uma relação.
Para verificar se há de fato correlação entre idade e colesterol com o target, podemos obter os valores entre essas variáveis. Para fazer isso, vamos digitar df em uma nova célula, abrir colchetes e aspas simples, e passar as colunas de interesse, que são age, chol e y (que é o target).
Por fim, vamos adicionar . e usar o método corr() para obter a correlação.
df[['age', 'chol', 'y']].corr()
| - | age | chol | y |
|---|---|---|---|
| age | 1.00000 | 0.208950 | 0.223120 |
| chol | 0.20895 | 1.000000 | 0.085164 |
| y | 0.22312 | 0.085164 | 1.000000 |
A correlação do target com a idade é de 0.22, ou seja, uma correlação positiva, não muito alta, mas que existe. Em relação ao colesterol, temos uma correlação bem mais baixa, de 0.85.
Conclusão
Agora que já analisamos as variáveis em relação ao target e já preparamos o x e o y, falta preparar os dados para colocá-los para funcionar na nossa rede neural. Para isso, precisamos tratar uma dessas colunas, o que faremos no próximo vídeo. Te esperamos lá!
Sobre o curso TensorFlow: implementando um perceptron de múltiplas camadas (MLP)
O curso TensorFlow: implementando um perceptron de múltiplas camadas (MLP) possui 215 minutos de vídeos, em um total de 59 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Conhecendo e preparando os dados
- Construindo um perceptron
- Construindo o modelo
- Separando os dados em treino e teste
- Adicionando uma camada oculta
- Implementando múltiplas camadas