Olá! Você já pensou como o reconhecimento de áudio pode auxiliar em diversos problemas, como situações relacionadas à acessibilidade ou segurança?
Meu nome é Allan Spadini e vou acompanhar você neste curso de TensorFlow voltado para a classificação de diferentes tipos de áudio.
Audiodescrição: Allan Spadini se identifica como um homem branco. Possui olhos castanhos, sobrancelhas grossas e cabelos curtos, também castanhos. Usa uma camiseta preta. Ao fundo, os estúdios da Alura, onde há uma parede lisa e uma estante com quadros e estátuas, e livros à direita. A parede está iluminada em tons de azul e verde.
Neste curso, vamos aprender a construir um modelo de inteligência artificial capaz de realizar o reconhecimento de diversos tipos de áudio.
Vamos trabalhar especificamente em dois casos:
Para acompanhar este curso, é necessário ser capaz de utilizar o TensorFlow para a classificação de dados tabulares e também para a classificação de imagens.
Esperamos ver você nos próximos vídeos deste curso!
Nós trabalhamos para uma empresa de Inteligência Artificial (IA) voltada para áreas de acessibilidade e segurança. Essa empresa constrói modelos de IA voltados para essas áreas.
Nesse contexto, surgiu um novo problema: temos que construir um modelo de reconhecimento de comandos de áudio para as pessoas conseguirem, por exemplo, controlar um computador através de reconhecimento de áudio.
Para resolver esse problema, temos um dataset com diversos arquivos de áudio contendo gravações desses comandos. Esse dataset é o arquivo dataset_commands.gz.
Neste curso, utilizaremos a plataforma Lightning AI. Em seu interior, acessamos um ambiente de VS Code e ativamos a GPU A10G para rodar os conteúdos do curso.
Para ativar a GPU, acessamos a barra de ícones na lateral direita e clicamos no botão "Studio environment" e selecionamos a opção GPU na janela suspensa exibida.
Você pode utilizar a Lightning AI ou o Google Colab para acompanhar esse curso. No Google Colab, você deverá ativar as TPUs para rodar o conteúdo do curso.
Nosso primeiro desafio será descompactar o arquivo e visualizar um arquivo de áudio para entender melhor o problema de construção de um modelo de classificação de áudio.
Clicaremos no botão "Explorer" na barra de ícones da lateral esquerda para abrir o explorador de arquivoa. Em seu interior, clicando com o botão direito no arquivo dataset_commands.gz, selecionaremos "Copy Path" para copiar o caminho desse arquivo.
Acessando o arquivo do notebook gravacao.ipynb e minimizando o explorador lateral, criaremos uma variável gz_path que vai guardar esse caminho dos arquivos de áudio. Ela receberá o caminho copiado.
gz_path = '/teamspace/studios/this_studio/dataset_commands.gz'
Agora vamos fazer a importação da biblioteca TensorFlow. Se você não a tiver instalada no seu ambiente, é possível instalá-la com o comando abaixo.
!pip install tensorflow
Na próxima célula, importaremos as bibliotecas necessárias, adicionando os comandos abaixo e pressionando "Shift + Enter".
import tensorflow as tf
import pathlib
import gzip
import shutil
import numpy as np
Na célula seguinte, definiremos uma função que utiliza essas bibliotecas para fazer a leitura dos arquivos. Para isso, criaremos a função le_arquivos(), dois pontos, e passar entre parênteses o gz_path, o caminho do arquivo.
Dentro da função, na linha seguinte, adicionaremos a variável extracted_path que será igual ao '/tmp/dataset_commands'.
def le_arquivos(gz_path):
extracted_path = '/tmp/dataset_commands'
Pulando uma linha, abriremos o arquivo compactado e o leremos como um arquivo de entrada, com o comando with gzip.open() as f_in. Entre parênteses, adicionaremos gz_path, 'rb' para ler um arquivo binário com a biblioteca gzip.
Como arquivo de entrada, precisaremos escrever o arquivo que extraímos em algum lugar. Vamos fazer isso dentro desse with, na linha seguinte, adicionando um with open(extracted_path+'.tar','wb') as f_out:, onde extrairemos o .tar do arquivo .gz para um arquivo binário dentro da pasta "wb".
Dentro do novo with, na linha seguinte, adicionaremos o shutil.copyfileobj() e entre parênteses, f_in, f_out.
def le_arquivos(gz_path):
extracted_path = '/tmp/dataset_commands'
with gzip.open(gz_path, 'rb') as f_in:
with open(extracted_path + '.tar', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
Agora temos o que precisamos para extrair os arquivos. Pulando uma linha e regredindo dois níveis na indentação, descompactaremos o arquivo .tar, outro arquivo compactado.
Para não nos estendermos muito, colaremos um comando da biblioteca shutil para manipular o arquivo.
def le_arquivos(gz_path):
extracted_path = '/tmp/dataset_commands'
with gzip.open(gz_path, 'rb') as f_in:
with open(extracted_path + '.tar', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
# Extrair o arquivo .tar resultante
shutil.unpack_archive(extracted_path + '.tar', extracted_path)
Pulando mais uma linha, coletaremos o diretório dos arquivos extraídos com data_dir igual a pathlib.Path(), utilizando a biblioteca pathlib. Entre parênteses, coletaremos o extracted_path.
def le_arquivos(gz_path):
extracted_path = '/tmp/dataset_commands'
with gzip.open(gz_path, 'rb') as f_in:
with open(extracted_path + '.tar', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
# Extrair o arquivo .tar resultante
shutil.unpack_archive(extracted_path + '.tar', extracted_path)
data_dir = pathlib.Path(extracted_path)
Também queremos coletar o caminho de todos os arquivos, além das labels (classes) com as quais estamos trabalhando.
Se abrirmos o arquivo .gz no computador, veremos que ele é uma pasta cheia de outras pastas, e cada uma delas tem diversos arquivos de áudio. O nome de cada pasta representa as classes nas quais queremos classificar esses arquivos de áudio.
Para coletar esses caminhos, pularemos uma linha e adicionaremos um all_audio_paths igual a list(data_dir.glob('*/**/*.wav')).
Na linha seguinte, coletaremos essas all_labels, ou seja, todas as classes. all_labels será igual ao comando [path.parent.name for path in all_audio_paths], no qual coletaremos o nome das pastas dentro dos caminhos dos arquivos de áudio.
def le_arquivos(gz_path):
extracted_path = '/tmp/dataset_commands'
with gzip.open(gz_path, 'rb') as f_in:
with open(extracted_path + '.tar', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
# Extrair o arquivo .tar resultante
shutil.unpack_archive(extracted_path + '.tar', extracted_path)
data_dir = pathlib.Path(extracted_path)
all_audio_paths = list(data_dir.glob('*/**/*.wav'))
all_labels = [path.parent.name for path in all_audio_paths]
Pulando uma linha, converteremos os caminhos dos arquivos de áudio para strings por meio de um for, colando o comando pronto all_audio_paths = [str(path) for path in all_audio_paths].
Por fim, pularemos outra linha e retornaremos esses all_audio_paths e all_labels.
def le_arquivos(gz_path):
extracted_path = '/tmp/dataset_commands'
with gzip.open(gz_path, 'rb') as f_in:
with open(extracted_path + '.tar', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
# Extrair o arquivo .tar resultante
shutil.unpack_archive(extracted_path + '.tar', extracted_path)
data_dir = pathlib.Path(extracted_path)
all_audio_paths = list(data_dir.glob('*/**/*.wav'))
all_labels = [path.parent.name for path in all_audio_paths]
# Converter caminhos para strings
all_audio_paths = [str(path) for path in all_audio_paths]
return all_audio_paths, all_labels
Após executar a célula acima, teremos a função construída.
Na célula seguinte, chamaremos a função le_arquivos(gz_path) e retornaremos esses all_audio_paths e all_labels, adicionando-os à esquerda da função, com um sinal de igual.
all_audio_paths, all_labels = le_arquivos(gz_path)
Ao executar a célula, esse processo demorará para ser finalizado, mas após isso, teremos todos os arquivos.
Enquanto o processo é executado, acessaremos a célula seguinte e imprimiremos as classes com as quais estamos trabalhando. Vamos utilizar a biblioteca NumPy, que já importamos, por meio do comando np.unique(all_labels).
Após o comando anterior terminar sua execução, executaremos este para obter todos os labels.
np.unique(all_labels)
Na próxima célula, também verificaremos quantas classes temos. Para isso, adicionaremos o mesmo comando np.unique(all_labels) e adicionar um .shape após os parênteses para imprimir a quantidade de classes com as quais estamos trabalhando.
np.unique(all_labels).shape
Após o comando mais longo, executaremos a célula np.unique(all_labels) e obteremos os labels abaixo.
array(['_background_noise_', 'backward', 'bed', 'bird', 'cat', 'dog',
'down', 'eight', 'five', 'follow', 'forward', 'four', 'go',
'happy', 'house', 'learn', 'left', 'marvin', 'nine', 'no', 'off',
'on', 'one', 'right', 'seven', 'sheila', 'six', 'stop', 'three',
'tree', 'two', 'up', 'visual', 'wow', 'yes', 'zero'], dtype='<U18')
Dentro dessas classes temos direções, como left, yes, up, e números, como one, two e three. Podemos interpretar isso como comandos.
Também temos outras classes que não representam comandos, mas podem ser equivalentes a palavras aleatórias que seriam ditas e não deveriam ser interpretadas pelo software, como cat, dog, bird e assim por diante.
Por fim, executaremos a célula np.unique(all_labels).shape que mostrará que temos 36 classes ao todo, nas quais estamos trabalhando.
(36,)
Na próxima célula, faremos o plot de um desses arquivos de áudio. Para isso, faremos o import do matplotlib.pyplot as plt e rodaremos com "Shift + Enter".
import matplotlib.pyplot as plt
Em outra célula, coletaremos um arquivo de exemplo com example_audio_path, igual ao primeiro arquivo de áudio, all_audio_paths[0].
example_audio_path = all_audio_paths[0]
Após executar a célula, plotaremos esse arquivo. Para isso, precisamos carregá-lo, porque obtivemos somente o caminho dos arquivos, sem os carregar efetivamente.
Portanto, utilizaremos a TensorFlow para ler esse arquivo de áudio. Faremos um audio_binary igual a tf.io.read_file(example_audio_path), com o qual teremos o arquivo binário de áudio.
audio_binary = tf.io.read_file(example_audio_path)
Além disso, precisamos decodificar esse arquivo de áudio. Descendo uma linha, adicionaremos um audio, _ = tf.audio.decode_wave(audio_binary).
audio_binary = tf.io.read_file(example_audio_path)
audio, _ = tf.audio.decode_wav(audio_binary)
Por fim, transformaremos esse áudio em uma sequência de números. Na linha seguinte, utilizaremos outra função do TensorFlow, a tf.squeeze. Portanto, escreveremos audio = tf.squeeze(audio, axis=-1).
audio_binary = tf.io.read_file(example_audio_path)
audio, _ = tf.audio.decode_wav(audio_binary)
audio = tf.squeeze(audio, axis=-1)
Após executar essa célula, teremos como resultado uma sequência de números, com a qual faremos o plot.
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1723206607.635407 2460 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723206607.866953 2460 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723206607.867239 2460 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
(Retorno omitido)
Para fazer o plot do arquivo com a amostra de matplotlib, colaremos o comando abaixo, no qual passamos audio.numpy para interpretar o arquivo de áudio.
# Plotar a forma de onda
plt.figure(figsize=(10, 6))
plt.plot(audio.numpy())
plt.title(f'Forma de onda para {example_audio_path}')
plt.xlabel('Amostras')
plt.ylabel('Amplitude')
plt.show()
Como resultado, temos um gráfico em forma de onda com uma sequência de aproximadamente 16 mil amostras de áudio coletadas no tempo.
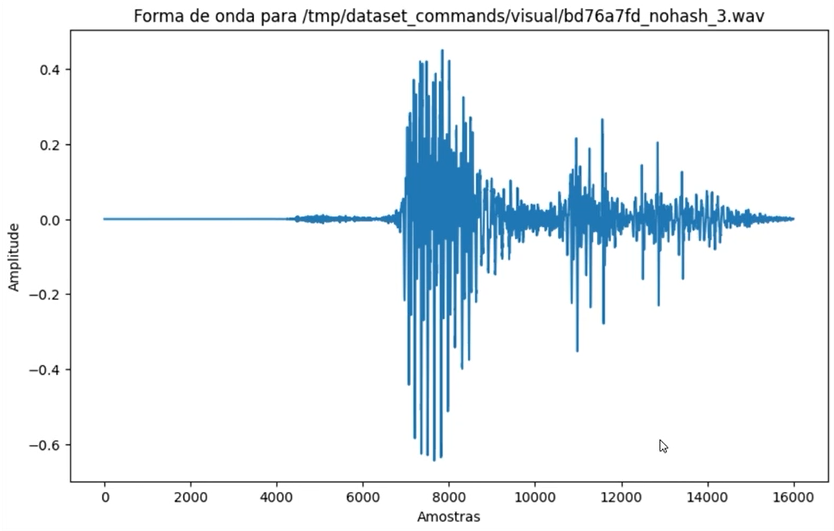
Temos a amplitude desse arquivo de áudio que representa um arquivo visualizado ao utilizar um software de gravação de áudio, por exemplo. É com esse tipo de arquivo que estamos lidando e que enviaremos para uma rede neural, permitindo que esta aprenda com diversos exemplos.
Depois que a rede neural aprender, utilizaremos esse modelo treinado para fazer a classificação de arquivos de áudio.
No próximo vídeo, entenderemos que tipo de pré-processamento precisamos aplicar nesses arquivos de áudio para enviá-los à rede neural.
Já entendemos, mais ou menos, como são os arquivos de áudio que precisamos enviar para a rede neural. No entanto, temos diversos arquivos de áudio e eles precisam seguir um padrão para serem enviados.
Dentro do problema de classificação, diversas pessoas diferentes, com diversos equipamentos diferentes, gravaram arquivos de áudio. Os arquivos podem ter tempos ou número de amostras diferentes, por exemplo. Portanto, precisamos padronizar cada um desses arquivos.
Para isso, construiremos uma função que realizará esse processo de padronização para fazer o carregamento de áudios padronizado, permitindo passá-los efetivamente para a rede neural. Caso contrário, a rede neural não conseguirá nem iniciar o processo.
Criaremos uma função que lida com cada caminho de arquivo. Na célula seguinte, criaremos a função path_and_labels_to_dataset(). Vamos transformar esses caminhos labels para um dataset.
Entre seus parênteses, adicionaremos audio_paths, vírgula, labels. Após os parênteses, adicionaremos dois pontos, e dentro da função, recolheremos a path_ds (o caminho dos dados), que será igual a tf.data.Dataset.from_tensor_slices().
Entre os parênteses, por sua vez, obteremos os audio_paths.
Na linha seguinte, também obteremos o label_ds, que será igual ao tf.data.Dataset.from_tensor_slices(), passando entre parênteses as labels.
Assim, transformaremos os caminhos de áudio e os labels para formatos que o TensorFlow compreenderá.
Feito isso, agruparemos a informação num único conjunto. Na linha seguinte, utilizaremos o audio_label_ds, variável na qual colocaremos toda a informação. Elsa será igual ao tf.data.Dataset.zip(). Entre os parênteses, adicionaremos outro bloco de parênteses, e entre eles, adicionar path_ds, vírgula, e label_ds.
Por fim, retornaremos essas informações, adicionando, na próxima linha, o return audio_label_ds.
def paths_and_labels_to_dataset(audio_paths, labels):
path_ds = tf.data.Dataset.from_tensor_slices(audio_paths)
label_ds = tf.data.Dataset.from_tensor_slices(labels)
audio_label_ds = tf.data.Dataset.zip((path_ds, label_ds))
return audio_label_ds
Além disso, precisamos fazer o pré-processamento mencionado por meio da função process_path() que ainda não criamos.
Com essa função, faremos um mapeamento dos arquivos de áudio que temos. Portanto, à direita do return audio_label_ds, faremos um map(), e entre seus parênteses, um process_path, vírgula, num_parallel_calls, igual a tf.data.AUTOTUNE.
def paths_and_labels_to_dataset(audio_paths, labels):
path_ds = tf.data.Dataset.from_tensor_slices(audio_paths)
label_ds = tf.data.Dataset.from_tensor_slices(labels)
audio_label_ds = tf.data.Dataset.zip((path_ds, label_ds))
return audio_label_ds.map(process_path, num_parallel_calls=tf.data.AUTOTUNE)
Nessa linha, realizaremos um mapeamento processando os arquivos, dado o caminho, e utilizaremos um processamento paralelo com o TensorFlow para agilizar o processamento total. Afinal, o simples processo de coletar o caminho dos arquivos é demorado, e essa demora pode ser ainda maior ao carregar os arquivos efetivamente.
Pressionaremos "Shift + Enter" nessa célula e teremos a função paths_and_labels_to_dataset() construída.
Acima da função criada, adicionaremos uma nova célula e construiremos a função process_path(), que é relativamente simples. Vamos colar seu conteúdo conforme abaixo.
def process_path(file_path, label):
audio = load_and_process_audio(file_path)
return audio, label
Essa função chamará outra que ainda vamos criar, retornando o áudio e a label. A função chamada será mais trabalhosa, e se chamará load_and_process_audio() (carrega e processa áudio).
Pressionaremos "Shift + Enter" para executar a função process_path() e em seguida, adicionaremos uma nova célula acima dela para criar a função load_and_process_audio().
Na nova célula, criaremos o def load_and_process_audio(), pressionar "Shift + Enter" para selecioná-la na lista de sugestões da IDE, e entre seus parênteses, informar o filename e a max length igual a 16.000.
def load_and_process_audio(filename, max_length=16000):
Esse 16.000 é o número de amostras que esperamos ter em cada arquivo. Vimos que o arquivo visualizado tem mais ou menos esse número de amostras, e queremos padronizar isso. Portanto, assumiremos que todos os nossos arquivos têm mais ou menos essa quantidade de amostras.
Caso ele tenha mais do que isso, cortaremos o arquivo. Caso ele tenha menos, adicionaremos zeros na frente do arquivo. Assim conseguiremos realizar essa padronização.
Dentro dessa função, precisaremos reamostrar também os arquivos de áudio, caso eles tenham sido mostrados de maneira diferente. Para isso, utilizaremos a função resample da biblioteca SciPy.
Para isso, criaremos uma nova célula acima da atual, na qual adicionaremos um from scipy.signal import resample, e a executaremos.
from scipy.signal import resample
Com isso, voltando ao interior da função load_and_process_audio(), poderemos coletar os arquivos de áudio e realizar um processamento similar ao que fizemos para carregar um arquivo de áudio.
Utilizaremos o comando tf.io.read_file(), copiado da célula de carregamento, adicionando entre os parênteses um filename. Colocaremos essa informação dentro de um file_contents.
E vamos pegar e decodificar também esse áudio e realizar o processo de squeeze, que é exatamente o mesmo processo que fizemos no vídeo anterior, para passar os dados ali na hora do carregamento com o TensorFlow.
def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
Descendo uma linha, faremos o processo de squeeze(), assim como feito no vídeo anterior para informar os dados no momento do carregamento com o TensorFlow.
def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(file_contents, desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
Pulando uma linha, chamaremos finalmente a função da SciPy para realizar a reamostragem. Para isso, criaremos a função scipy_resample() com a SciPy, dentro da função atual, por meio de um def scipy_resample().
Entre os parênteses, passaremos o wav — o arquivo de áudio carregado — e o sample_rate — a taxa de amostragem. Finalizaremos a chamada da função com dois pontos, como sempre.
def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(file_contents, desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
def scipy_resample(wav, sample_rate):
Dentro da nova função, adicionaremos um if que realizará o processamento somente se o arquivo não tiver o comprimento de 16 mil amostras. Ele conterá o wav reamostrado, que será igual à chamada da função resample(), importada da SciPy.
Já entre os parênteses de resample(), coletaremos o wav, e o comando int(16000 / sample_rate * len(wav)) para realizar a reamostragem.
def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(file_contents, desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
def scipy_resample(wav, sample_rate):
if sample_rate != 16000:
wav = resample(wav, int(16000 / sample_rate * len(wav)))
Vamos tentar entender melhor o comando de reamostragem: ele deverá ser um número inteiro, coletaremos o total de 16 mil amostras, e dividiremos esse valor pela taxa de amostragem vezes o comprimento do arquivo de áudio. Isso realizará uma reamostragem caso tenhamos adicionado ou retirado amostras do arquivo de áudio.
Ou seja, estamos readaptando o arquivo de áudio para não ficar com sons mais graves ou mais agudos, por exemplo, no caso da adicão de mais amostras a ele no decorrer do processamento.
Feito isso, realizaremos o return dessa informação, com return wav.
def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(file_contents, desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
def scipy_resample(wav, sample_rate):
if sample_rate != 16000:
wav = resample(wav, int(16000 / sample_rate * len(wav)))
return wav
Temos a função criada. Contudo, para o TensorFlow rodá-la, vamos alocá-la dentro de um py_function do TensorFlow, permitindo que ele entenda que se trata de uma função do Python e a chame.
Pulando uma linha e recuando o cursor para o mesmo nível de indentação da função scipy_resample(), chamaremos o wav, que será igual ao tf.py_function(). Entre seus parênteses, informaremos:
scipy resample;wav e sample_rate) entre colchetes:tf.float32 dos valores.def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(file_contents, desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
def scipy_resample(wav, sample_rate):
if sample_rate != 16000:
wav = resample(wav, int(16000 / sample_rate * len(wav)))
return wav
wav = tf.py_function(scipy_resample, [wav, sample_rate], tf.float32)
Encapsulamos essa função. Graças a isso, conseguiremos realizar o processo mencionado anteriormente: adicionar um padding e zeros na frente de arquivos menores, e um corte caso o arquivo seja maior do que 16 mil amostras.
Pulando uma linha, criaremos o audio_length, que será igual ao tf.shape(wav). Após os parênteses, adicionaremos um [0] para coletar a dimensão na qual temos o comprimento do arquivo de áudio.
Na linha seguinte, adicionaremos um if com o qual coletaremos o audio_length, que será maior que o max_length — ou seja, se o comprimento do arquivo de áudio for maior que o maior comprimento permitido (16 mil), faremos algo — no caso, cortaremos o arquivo.
def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(file_contents, desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
def scipy_resample(wav, sample_rate):
if sample_rate != 16000:
wav = resample(wav, int(16000 / sample_rate * len(wav)))
return wav
wav = tf.py_function(scipy_resample, [wav, sample_rate], tf.float32)
audio_length = tf.shape(wav)[0]
if audio_length > max_length:
No interior do if, adicionaremos um wav igual ao wav[:max_length]. Na linha seguinte, faremos o else, com dois pontos, dentro do qual informaremos o pad_length.
Caso o arquivo seja menor, adicionaremos um comprimento de zeros ao arquivo, por meio desse pad_length. Portanto, ele será igual a max_length menos o audio_length.
Tendo o pad_length, adicionaremos na linha seguinte os paddings, que receberão um [[0, pad_length]]. Em seguida, passaremos um wav igual a tf.pad(), e entre seus parênteses adicionaremos um wav, um paddings e um CONSTANT, entre aspas simples.
Por fim, pulando uma linha, passaremos o return tf.reshape(wav, [max length]).
def load_and_process_audio(filename, max_length=16000):
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(file_contents, desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
def scipy_resample(wav, sample_rate):
if sample_rate != 16000:
wav = resample(wav, int(16000 / sample_rate * len(wav)))
return wav
wav = tf.py_function(scipy_resample, [wav, sample_rate], tf.float32)
audio_length = tf.shape(wav)[0]
if audio_length > max_length:
wav = wav[:max_length]
else:
pad_length = max_length - audio_length
paddings = [[0, pad_length]]
wav = tf.pad(wav, paddings, 'CONSTANT')
return tf.reshape(wav, [max_length])
Ao executar a célula acima, teremos todas as funções construídas para realizar o processamento.
Após o pré-processamento, dividiremos os dados em treino e validação.
O curso TensorFlow Keras: Decodificando Áudio com IA possui 159 minutos de vídeos, em um total de 50 atividades. Gostou? Conheça nossos outros cursos de IA para Dados em Inteligência Artificial, ou leia nossos artigos de Inteligência Artificial.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






