

Uma breve introdução sobre o que é Big Data
Com o advento da internet, o volume de dados gerados ao redor do mundo cresceu de forma inesperada conforme os anos foram se passando. A utilização em larga escala de dispositivos móveis ampliou ainda mais a quantidade de dados gerados diariamente.
Os métodos tradicionais para armazenamento e processamento de dados em grandes empresas começaram a não ser suficientes, gerando problemas e gastos cada vez maiores para suprir suas necessidades.
Devido a esses acontecimentos, surgiu o conceito de Big Data, uma área do conhecimento com o intuito de estudar maneiras de tratar, analisar e gerar conhecimento através de grandes conjuntos de dados que não conseguem ser trabalhados em sistemas tradicionais.

Big Data: Conceito
Para entender melhor o que é o Big Data, podemos pensar na forma como esse sistema tradicional de armazenamento e processamento de dados é realizado. Perceba que falamos no presente, porque os processos de trabalho com o Big Data não excluem a forma de trabalhar no sistema tradicional, em grande parte dos casos.
Isso porque muitas empresas não necessitam da utilização de ferramentas do Big Data para manipular os dados, e mesmo as grandes empresas utilizam um sistema híbrido. Dessa forma, as duas maneiras de trabalhar com os dados coexistem.
O sistema tradicional utiliza os famosos SGBDs, ou sistemas gerenciais de banco de dados, que guardam informações de forma estruturada, no formato de tabelas, com linhas e colunas. Utilizam máquinas com grande capacidade de armazenamento e processamento. Quando há a necessidade de expandir a capacidade dessas máquinas, é necessário introduzir novos componentes de hardware, para que tenham mais memória e processamento.
Os problemas que começam a aparecer quando se alcança um grande volume de dados usando esse sistema tradicional são relacionados à escalabilidade, disponibilidade e flexibilidade. Como exemplos, podemos mencionar que é muito custoso o aprimoramento dessas máquinas de maneira vertical a cada vez que é necessário realizar um upgrade, corriqueiramente nesse momento o sistema fica indisponível, já que a máquina está em processo de manutenção.
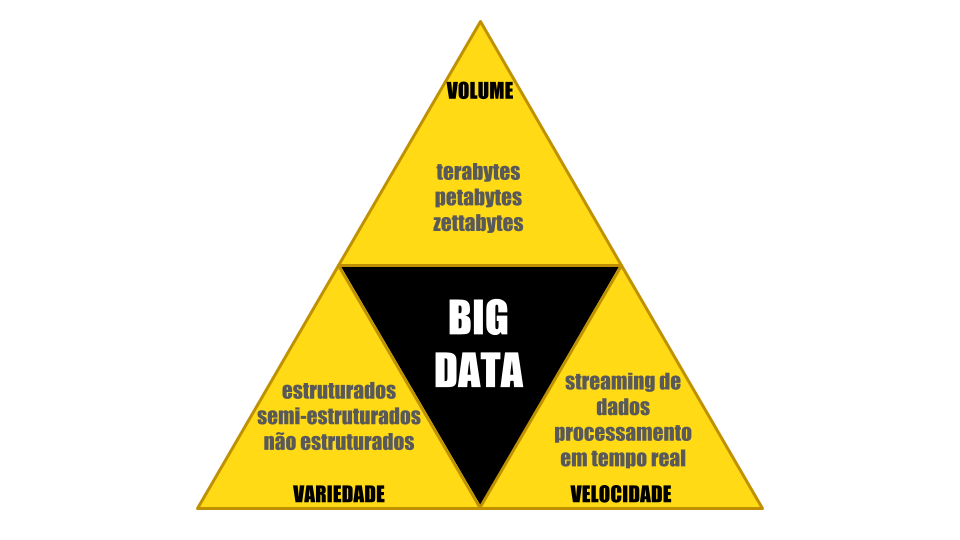
De forma a compreender a definição de Big Data, é necessário introduzir os conceitos dos V’s do Big Data. Inicialmente, a definição era composta por 3 V’s, mas hoje podemos encontrar definições expandidas com 5, 7 ou mais V’s. Os 7 V’s são: volume, variedade, velocidade, valor, veracidade, variabilidade e visualização.
Mas, vamos concentrar aqui os principais dentre os 7 mencionados anteriormente, conhecidos como os três Vs do big data:
- Volume;
- Variedade;
- Velocidade;
Volume
O volume é a principal característica quando pensamos a respeito de Big Data. Ele diz respeito a uma grande quantidade de dados para serem armazenados e processados, na casa de terabytes, petabytes ou mesmo zettabytes.
Há afirmações de que a quantidade de dados dobra a cada dois anos. Além disso, a quantidade de dados gerada por dia e acumulada ao longo dos anos é tão grande, que não seria interessante a colocação de valores aqui, uma vez que no momento em que você estiver lendo esse artigo esses valores já terão se alterado.
No Worldometers, é possível ter uma ideia da quantidade de dados gerados diariamente e a rapidez com que esses números estão crescendo a cada segundo. Alguns dados impactam bastante por se tratarem de valores em um intervalo de apenas 24 horas.
Já nesse vídeo denominado “Size of internet: bytes perspective”, são comparados os dados com uma escala física, mostrando a diferença entre a quantidade de dados existente na internet em 2001 e 2020.
Variedade
Quais os três tipos de dados em Big Data? Outra característica importante no Big Data é a variedade dos dados que são armazenados e processados. Além dos famosos dados estruturados, o conceito de Big Data trabalha com dados semi-estruturados e não estruturados.
Os dados estruturados são os dados com estrutura rígida em formato tabular, com linhas e colunas.
Os dados semi-estruturados possuem certo tipo de estrutura, mas são mais flexíveis. Os arquivos do tipo XML e JSON são exemplos de dados semi-estruturados.
Já os dados não estruturados são dados sem nenhuma estrutura pré-definida, correspondendo à maior parcela dos dados circulantes no mundo atualmente, em uma proporção bem maior do que os demais tipos. Arquivos de texto, de áudio, vídeo e imagens, são exemplos de dados não estruturados.
Velocidade
A velocidade se refere à rapidez com que os dados são gerados. A todo instante, e-mails, mensagens de texto e áudio são enviados, tweets são publicados, registros em bancos de dados são inseridos e atualizados. Tudo isso em uma escala global.
Não podemos nos esquecer dos dados gerados por máquinas a cada instante, através de sensores e de serviços de streaming que enviam e recebem dados em uma velocidade surpreendente.
A solução encontrada: como o Big Data é aplicado
Para que fosse possível resolver os problemas que surgiram, foi necessário criar novas ferramentas para suprir todas as necessidades. A escalabilidade vertical, no qual aprimoramos uma máquina adicionando mais recursos, como memória e processamento, não garante uma efetividade quando se trata de Big Data.
Para contornar os problemas, grandes empresas pesquisaram um novo sistema que fosse escalável, surgindo então o Hadoop, uma forma de armazenamento e processamento distribuído. A ideia é utilizar cluster de máquinas ou agrupamento de computadores. De forma isolada, um único computador nesse cluster não tem um poder de processamento muito poderoso, mas, em conjunto, conseguem fornecer poder de processamento e armazenamento capazes de suprir as necessidades.
Nesse cluster, existe uma máquina principal conhecida como Name Node que é responsável por gerenciar o restante das outras máquinas, conhecidas como Data Nodes. Os dados possuem réplicas em Data Nodes diferentes para que, caso uma máquina venha a falhar, os dados não serão perdidos e estarão sempre disponíveis. Esse conceito é conhecido em Big Data como disponibilidade.
O mais interessante é que no momento em que necessite ampliar as capacidades, novas máquinas podem ser integradas ao cluster, crescendo de maneira indefinida. Essa é a escalabilidade horizontal, a solução encontrada para os problemas de Big Data.

A partir do surgimento do Hadoop, diversas outras tecnologias foram sendo desenvolvidas em paralelo, criando assim um ecossistema de ferramentas que se expande a cada dia. Dando destaque para a utilização de bancos de dados NoSQL para trabalhar com dados não estruturados.

Quais são as 6 fases que compõem o ciclo de vida de um Big Data?
O ciclo de vida em problemas com grandes volumes de dados é um processo que pode ser cíclico. O processo envolve diferentes etapas para gerenciar e extrair valor dos dados. A nomenclatura das fases pode variar, mas, geralmente, são adotadas as etapas de:
*Coleta;
- Armazenamento;
- Processamento;
- Análise;
- Visualização;
- Ação.
Além disso, ao final do processo pode ser necessária a exclusão dos dados com a finalidade de manter questões como a privacidade das informações.
Quais as 4 análises possíveis no Big Data?
O objetivo na coleta e manutenção de uma grande quantidade de dados é a geração de valor. Por isso, são realizadas análises com objetivos específicos.
Análise descritiva: nesse tipo de análise os dados são usados para descrever o que aconteceu no passado. Assim, podem ser identificados padrões, tendências e anomalias nos dados.
Análise diagnóstica: aqui, a análise é usada para entender por que algo aconteceu. Neste caso, estamos interessados em identificar as causas de problemas que já foram notados.
Análise preditiva: na análise preditiva estamos fazendo uma projeção do que irá acontecer no futuro com base em experiências passadas.
Análise prescritiva: nesse caso, o foco é recomendar ações específicas a serem tomadas. Podemos usar os resultados da análise para melhorar a eficiência, a eficácia e a produtividade das empresas.
É importante observar que a escolha do tipo de análise a ser aplicada depende tanto do problema quanto dos dados disponíveis. Diferentes cenários podem exigir mais de um tipo de análise.
O que é preciso para trabalhar com Big Data?
Assim como na Ciência de Dados, são necessárias desde habilidades técnicas até habilidades de comunicação e pensamento crítico. No quesito técnico, as ferramentas de Big Data são muitas e podem deixar dúvidas de por onde a pessoa deve começar a estudar. Confira a seguir, alguns elementos indispensáveis:
O/a profissional terá que aprender pelo menos uma linguagem de programação como Python, R, Java ou Scala. Além disso, terá que estar familiarizado com frameworks como o Apache Hadoop e Spark.
Em se tratando de Bancos de Dados, são necessários conhecimentos tanto de bancos relacionais quanto de NoSQL. Nesse caso, se torna necessário também o conhecimento de sistemas de armazenamento distribuído.
O Hadoop é um dos principais frameworks para processamento de Big Data. Assim, torna-se vantajoso conhecer o ecossistema do Hadoop com as ferramentas MapReduce, Hive, Pig e HBase.
Por outro lado, existem diversas plataformas na nuvem como o Google Cloud, Azure e AWS que tendem a facilitar esse processo, além de permitir o armazenamento e processamento veloz de grandes volumes de dados. A plataforma DataBricks abstrai muito do trabalho com Big Data e com as plataformas de nuvem, sendo um ótimo caminho para um primeiro contato de quem está iniciando no Big Data e já conhece alguma das linguagens de programação citadas.
Qual o grande desafio do Big Data?
O Big Data apresenta diversos desafios, mas o maior deles está relacionado ao gerenciamento do problema. Além disso, o processamento e análise de grandes volumes de dados faz com que seja necessário escolher plataformas ideais. Só assim, é possível assegurar questões como a escalabilidade e integração de informações.
O custo e infraestrutura devem ser bem analisados, pois lidar com Big Data pode ser caro, tanto em termos de infraestrutura quanto de recursos humanos. Investir em tecnologias avançadas e profissionais qualificados também é necessário para obter sucesso nessa área.
Superar esses desafios exige uma combinação de habilidades técnicas e abordagens inovadoras. Além disso, as soluções para esses desafios continuam a evoluir à medida que a tecnologia e as práticas relacionadas ao Big Data avançam.
Como aplicar o Big Data na sua empresa?
O processo de aplicação do Big Data pode variar de caso a caso. Isso porque ele envolve um processo cuidadoso e estratégico para aproveitar o potencial dos dados para impulsionar a tomada de decisões e otimizar processos. Confira abaixo algumas etapas importantes para a aplicação do Big Data na sua empresa:
De forma geral, no primeiro passo devemos definir objetivos e metas. Isso envolve identificar se o objetivo final envolve melhorar a eficiência operacional, aumentar a satisfação dos clientes ou mesmo se o foco será desenvolver produtos ou serviços mais personalizados.
Posteriormente, deve ser avaliada a infraestrutura existente, se a empresa possui um banco de dados local ou na nuvem. Além disso, é necessário avaliar se a capacidade computacional disponível irá comportar o processamento dos dados. Na análise dos dados o processamento envolve muito mais do que o exigido por simples requisições a um banco de dados.
Após a avaliação da capacidade de infraestrutura deve-se criar uma estratégia de dados. Verificar se a empresa já possui os dados necessários ou se será necessário adquirir informações para a solução do problema proposto. Com a conclusão dessa etapa já é possível aplicar as análises adequadas.
Durante todo o processo é necessário garantir a segurança e privacidade dos dados.
Além disso, em problemas de Big Data os dados não costumam ser estáticos, eles mudam com o tempo. Imagine que os seus dados envolvam a interação de clientes com uma plataforma de vendas. Os clientes irão continuar interagindo mesmo depois da data que os dados foram coletados. Por isso, é necessário monitorar e iterar sobre o mesmo problema conforme necessário.
Conclusão
Diante de tudo que foi apresentado, foi possível compreender a importância e os conceitos iniciais, além da definição de Big Data. As soluções e ferramentas criadas foram essenciais para que o mundo atual esteja em constante evolução. Por se tratar de uma área muito ampla, muitos conceitos ficaram de fora desse artigo. Caso queira expandir ainda mais os conhecimentos, a internet tem um volume muito grande de conteúdos, você pode encontrá-los em uma variedade de formatos e você vai encontrar em uma velocidade muito rápida.
Deixo aqui uma indicação de leitura do livro que dá uma ideia geral a respeito do assunto:
